

在汽車(chē)軟件開(kāi)發(fā)領(lǐng)域,越來(lái)越多的大規(guī)模 AI 模型被集成到自動(dòng)駕駛汽車(chē)中,這些模型的范圍從視覺(jué) AI 模型到用于自動(dòng)駕駛的端到端 AI 模型。現(xiàn)在,汽車(chē)軟件開(kāi)發(fā)領(lǐng)域?qū)λ懔Φ男枨笳陲w速增長(zhǎng)。導(dǎo)致系統(tǒng)負(fù)載增加,對(duì)系統(tǒng)穩(wěn)定性和時(shí)延產(chǎn)生了負(fù)面影響。
為了解決這些難題,可以使用可編程視覺(jué)加速器(PVA)提高能效和整體系統(tǒng)性能。PVA 是 NVIDIA DRIVE SoC 上的一個(gè)低功耗、高效率的硬件引擎。通過(guò)使用 PVA,可以卸載通常由 GPU 或其他硬件引擎處理的任務(wù)到 PVA 上,從而降低它們的負(fù)載,使它們能夠更加高效地管理其他關(guān)鍵任務(wù)。
在本文中,我們簡(jiǎn)要介紹了 DRIVE 平臺(tái)上的 PVA 硬件引擎和 SDK。我們展示了 PVA 引擎在計(jì)算機(jī)視覺(jué)(CV)流水線(xiàn)中的典型用例,包括預(yù)處理、后處理和其他 CV 算法,重點(diǎn)介紹其效果和效率。最后,我們以蔚來(lái)為例,詳細(xì)介紹了蔚來(lái)如何在其數(shù)據(jù)流水線(xiàn)中使用 NVIDIA PVA 引擎和優(yōu)化算法來(lái)卸載 GPU 或視頻圖像合成器(VIC)任務(wù),并提高自動(dòng)駕駛汽車(chē)系統(tǒng)的整體性能。
PVA 硬件概述
PVA 引擎是一款先進(jìn)的超長(zhǎng)指令詞(VLIW)、單指令、多數(shù)據(jù)(SIMD)數(shù)字信號(hào)處理器,它針對(duì)圖像處理和計(jì)算機(jī)視覺(jué)算法加速任務(wù)進(jìn)行了優(yōu)化。PVA 具有出色的性能和極低的功耗。作為異構(gòu)計(jì)算流水線(xiàn)的一部分,PVA 可與 NVIDIA DRIVE 平臺(tái)上的 CPU、GPU 和其他加速器異步或并行使用。
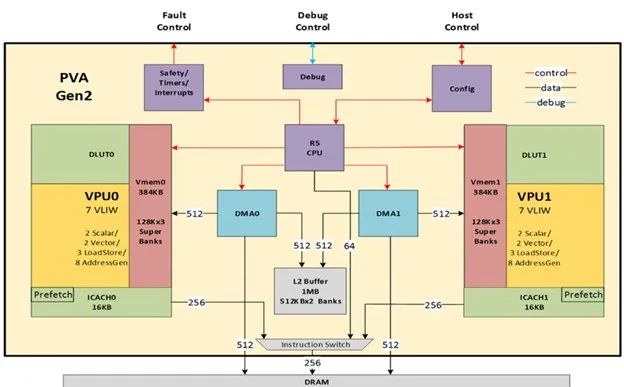
圖 1. PVA 硬件架構(gòu)
NVIDIA DRIVE Orin 上的 CV 集群中有一個(gè) PVA 實(shí)例,NVIDIA DRIVE Orin是一種高性能系統(tǒng)級(jí)芯片(SoC)專(zhuān)為先進(jìn)的 AI 應(yīng)用而設(shè)計(jì),尤其是自動(dòng)駕駛汽車(chē)和機(jī)器人領(lǐng)域。
在每個(gè) PVA 中,有兩個(gè)向量處理子系統(tǒng)(VPS)。每個(gè) VPS 包括以下內(nèi)容:
1 個(gè)矢量處理器(VPU)內(nèi)核
1 個(gè)解耦查找單元(DLUT)
1 個(gè)向量?jī)?nèi)存(VMEM)
1 個(gè)指令緩存(I-cache)
VPU 核是主處理單元。它是一個(gè)專(zhuān)為計(jì)算機(jī)視覺(jué)優(yōu)化的向量 SIMD VLIW DSP。它通過(guò)指令緩存獲取指令,并通過(guò) VMEM 訪(fǎng)問(wèn)數(shù)據(jù)。
DLUT 是專(zhuān)為提高并行查找操作效率而開(kāi)發(fā)的專(zhuān)用硬件組件。它通過(guò)與主處理器解耦的流水線(xiàn)中執(zhí)行此類(lèi)查找操作,實(shí)現(xiàn)了使用單個(gè)查找表副本進(jìn)行并行查找。通過(guò)這種方式,DLUT 可以最大限度地減少內(nèi)存占用并提高吞吐量,同時(shí)避免依賴(lài)數(shù)據(jù)的內(nèi)存庫(kù)沖突,最終提高系統(tǒng)整體性能。
VMEM 為 VPU 提供了本地?cái)?shù)據(jù)存儲(chǔ),實(shí)現(xiàn)了各種圖像處理和計(jì)算機(jī)視覺(jué)算法的高效執(zhí)行。它支持 VPS 以外的系統(tǒng)組件的訪(fǎng)問(wèn)(比如 DMA 和 R5),從而實(shí)現(xiàn)與 R5 及其他系統(tǒng)級(jí)組件的數(shù)據(jù)交換。
VPU(I-cache)可根據(jù)要求向 VPU 提供指令數(shù)據(jù)、從系統(tǒng)內(nèi)存中請(qǐng)求缺失的指令數(shù)據(jù)并維護(hù) VPU 的臨時(shí)指令存儲(chǔ)。
R5 為每個(gè) VPU 任務(wù)配置 DMA,選擇性地將 VPU 程序預(yù)取到 VPU 指令緩存中,并啟動(dòng)相應(yīng) VPU-DMA 的組合來(lái)處理任務(wù)。DRIVE Orin PVA 還包含 1 個(gè) L2 SRAM 內(nèi)存供兩組 VPS 和 DMA 共享。
兩個(gè) DMA 設(shè)備用于在外部?jī)?nèi)存、PVA L2 內(nèi)存、兩個(gè) VMEM(每個(gè) VPS 1 個(gè))、R5 緊密耦合內(nèi)存(TCM)、DMA 描述符內(nèi)存和 PVA 級(jí)配置寄存器之間移動(dòng)數(shù)據(jù)。
在低負(fù)載系統(tǒng)中,對(duì) DRAM 的兩個(gè)并行 DMA 訪(fǎng)問(wèn)最高可實(shí)現(xiàn) 15 GB/s 的讀/寫(xiě)帶寬。在高負(fù)載系統(tǒng)中,該帶寬最高可達(dá)到 10 GB/s。
在算力方面,INT8 GMACS(每秒十億次乘法累加運(yùn)算)為 2048,不包括 DLUT。每個(gè) PVA 實(shí)例的 FP32 GMACS 為 32。
PVA SDK 介紹
與 GPU 的 CUDA 工具包類(lèi)似,NVIDIA PVA SDK 專(zhuān)為打造利用 PVA 硬件功能的計(jì)算機(jī)視覺(jué)算法而設(shè)計(jì)。PVA SDK 為 CV 和 DL/ML 算法的開(kāi)發(fā)、部署和安全認(rèn)證提供了運(yùn)行時(shí) API、工具和教程。它提供了一個(gè)從構(gòu)建到部署的無(wú)縫框架,支持將代碼交叉編譯成 Tegra PVA 上的二進(jìn)制可執(zhí)行文件。
PVA SDK 通過(guò)多種資源支持軟件開(kāi)發(fā):
全面的入門(mén)指南。
x86 原生仿真器,可模擬真實(shí)的 VPU。支持在 x86-64 平臺(tái)上開(kāi)發(fā)和調(diào)試 VPU 內(nèi)核。
全套代碼生成工具,包括經(jīng)過(guò)優(yōu)化的 C/C++ 編譯器、調(diào)試器和集成開(kāi)發(fā)環(huán)境。
分析工具,例如用于視覺(jué)性能分析的 NVIDIA Nsight 系統(tǒng)和用于詳細(xì) VPU 代碼性能指標(biāo)的 API。
分步教程,該教程將逐一介紹 PVA 的概念,從基本示例到 VPU、DMA 的高級(jí)優(yōu)化以及與其他 Tegra 引擎的互通。
豐富的文檔和參考手冊(cè)提供了有關(guān) VPU 內(nèi)部函數(shù)的詳細(xì)信息,使用戶(hù)能夠編寫(xiě)優(yōu)化的代碼,同時(shí)抽象并降低 DMA 編程的復(fù)雜性。
PVA SDK 提供了大量現(xiàn)成的算法以支持自動(dòng)駕駛和機(jī)器人領(lǐng)域中的常見(jiàn)計(jì)算機(jī)視覺(jué)用例。用戶(hù)可以在其生產(chǎn)環(huán)境中直接使用這些算法(可訪(fǎng)問(wèn)源代碼)或者使用 PVA SDK 的功能自主開(kāi)發(fā)定制算法。
NVIDIA 根據(jù)常見(jiàn)的 CV 用例,基于 PVA SDK 預(yù)先開(kāi)發(fā)了許多算法。用戶(hù)可以在其產(chǎn)品中充分利用這些 PVA 算法并訪(fǎng)問(wèn)代碼,也可以將各種不同的算法作為參考,自主開(kāi)發(fā)有價(jià)值的算法。
典型 PVA 用例
許多自動(dòng)駕駛汽車(chē)開(kāi)發(fā)者都面臨著 SoC 計(jì)算資源不足的挑戰(zhàn),這導(dǎo)致 CPU、GPU、VIC 和 DLA 負(fù)載過(guò)高。為了解決這個(gè)問(wèn)題,人們正在考慮使用 PVA 硬件卸載 SoC 上使用率較高的硬件引擎的處理任務(wù)。
圖像處理:部分圖像處理和 CV 任務(wù)可以移植到 PVA 上,以卸載 GPU、CPU、VIC 甚至 DLA 的工作負(fù)載。
深度學(xué)習(xí)操作:在深度學(xué)習(xí)網(wǎng)絡(luò)中,可將某些層或計(jì)算密集型運(yùn)算符(例如 ROI 對(duì)齊)卸載到 PVA。在特定情況下,小型深度學(xué)習(xí)網(wǎng)絡(luò)可以完全移植到 PVA 上。
數(shù)學(xué)計(jì)算:作為一個(gè)向量 SIMD VLIW DSP,PVA 可以高效地處理數(shù)學(xué)計(jì)算,例如矩陣計(jì)算、FFT 等。
以下詳細(xì)介紹兩個(gè)用例,以供參考:
將 AI 流水線(xiàn)中的預(yù)處理和后處理卸載至 PVA
將純 CV 或受計(jì)算限制的流水線(xiàn)遷移至 PVA
將 AI 流水線(xiàn)中的
預(yù)處理和后處理卸載至 PVA

圖 2. AI 推理流水線(xiàn)
這是 CV 流水線(xiàn)的典型用例。輸入圖像來(lái)自實(shí)時(shí)場(chǎng)景中的實(shí)時(shí)攝像頭,或來(lái)自離線(xiàn)場(chǎng)景中的解碼器。該流水線(xiàn)包括三個(gè)階段:
預(yù)處理
AI 推理
后處理
PVA 硬件引擎在 CV 流水線(xiàn)的所有階段,從預(yù)處理到后處理,都能發(fā)揮關(guān)鍵作用,確保圖像處理和計(jì)算機(jī)視覺(jué)任務(wù)得到高效且有效的處理。
預(yù)處理
預(yù)處理涉及基本的 CV 任務(wù),以便對(duì)齊或規(guī)范化模型的輸入,其中包括重映射(去畸變)、裁剪、調(diào)整大小和顏色轉(zhuǎn)換(從 YUV 到 RGB)等操作。
在某些情況下,當(dāng)圖像來(lái)自 NVDEC(Tegra SoC 上的解碼器硬件引擎)時(shí),圖像布局為 block linear 格式。在這種情況下,在預(yù)處理階段需要執(zhí)行更多的步驟,將 block linear 格式轉(zhuǎn)換為 pitch linear 格式的圖像。
PVA 硬件引擎非常適合這些任務(wù)。然而,在內(nèi)存受限的情況下,應(yīng)考慮合并相鄰的 PVA 操作,以充分利用 PVA 的算力。
AI 推理
AI 推理以最先進(jìn)的 AI 模型為基礎(chǔ),執(zhí)行業(yè)務(wù)需求所需的核心 CV 任務(wù)。該步驟可在 GPU 或深度學(xué)習(xí)加速器(DLA)上執(zhí)行,以獲得更好的性能。
PVA 運(yùn)行時(shí) API 同時(shí)支持 NvSciSync 和原生 CUDA 流,能夠高效執(zhí)行涉及 GPU/DLA 的異構(gòu)流水線(xiàn),而不會(huì)產(chǎn)生恢復(fù)到 CPU 進(jìn)行調(diào)度相關(guān)的時(shí)延。
根據(jù)具體用例,該 AI 模型可以是用于物體檢測(cè)的 YOLO 或 R-CNN,也可以是用于分類(lèi)的邏輯回歸或 K-nearest neighbor(KNN),以及其他模型等。
后處理
后處理會(huì)優(yōu)化檢測(cè)結(jié)果。該步驟可能涉及使用中值濾波器去除異常值,進(jìn)行混合操作以融合不同的候選項(xiàng)或應(yīng)用非最大抑制(NMS)來(lái)選擇最佳目標(biāo)。PVA 硬件能夠有效處理這些任務(wù)。
將純 CV 或受計(jì)算限制的流水線(xiàn)遷移至 PVA

圖 3. 追蹤器流水線(xiàn)
這是一個(gè)更具體、更復(fù)雜的用例,所有步驟都可以在 PVA 上執(zhí)行。主要涉及檢測(cè)和追蹤輸入圖像中的特征點(diǎn),或在某些場(chǎng)景中計(jì)算稀疏光流:
圖像金字塔沿比例空間擴(kuò)展圖像。
特定的檢測(cè)算法可識(shí)別圖像中的特征點(diǎn)或角點(diǎn)。
跟蹤算法逐幀追蹤這些特征點(diǎn)。
與之前的用例相比,這個(gè)場(chǎng)景在關(guān)鍵方面有所不同:
計(jì)算受限處理:數(shù)據(jù)處理的每一步都受計(jì)算限制,并涉及到處理 2D 圖像。這些算法可以很好地向量化,并在 PVA 硬件上高效執(zhí)行。最重要的是,PVA 的算力得到了充分利用。
緊密耦合的步驟:有一個(gè)額外的數(shù)據(jù)循環(huán)將追蹤信息傳回之前的步驟,以完善后續(xù)的追蹤結(jié)果。這使得各步驟之間的耦合更加緊密。
純 CV 流水線(xiàn):該用例是不涉及機(jī)器學(xué)習(xí)網(wǎng)絡(luò)的純計(jì)算機(jī)視覺(jué)流水線(xiàn)。每個(gè)步驟都是可預(yù)測(cè)和可解釋的,只側(cè)重于傳統(tǒng)的 CV 算法。
通過(guò)使用 PVA 執(zhí)行這些任務(wù),用戶(hù)可以減輕 GPU、VIC、CPU 和 DLA 的負(fù)載,提高系統(tǒng)的穩(wěn)定性和效率。
蔚來(lái)汽車(chē)數(shù)據(jù)流水線(xiàn)優(yōu)化
蔚來(lái)汽車(chē)是一家知名的全球化汽車(chē)制造商,致力于高端智能電動(dòng)汽車(chē)的設(shè)計(jì)、開(kāi)發(fā)和生產(chǎn)。
以下是來(lái)自蔚來(lái)的數(shù)據(jù)處理流水線(xiàn),涉及使用專(zhuān)門(mén)的算法和技術(shù)對(duì)實(shí)時(shí)攝像頭或 H.264 視頻中的感興趣區(qū)域和對(duì)象進(jìn)行去識(shí)別、遮蔽或替換。
原始數(shù)據(jù)流水線(xiàn)方案
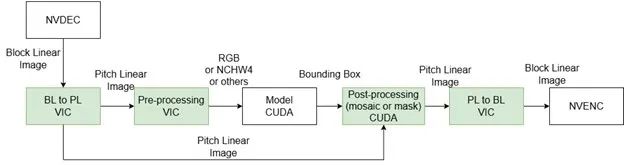
圖 4. 蔚來(lái)的數(shù)據(jù)流水線(xiàn)
圖 4 表示蔚來(lái)數(shù)據(jù)流水線(xiàn)的原始版本。NVDEC 用于解碼 H.264 視頻,生成 block linear 格式的 YUV 圖像。由于 block linear 是 NVIDIA 特有的內(nèi)部格式,因此外部用戶(hù)無(wú)法直接處理這些圖像。VIC 引擎被用于將 block linear 圖像轉(zhuǎn)換為 pitch linear 格式,以便進(jìn)一步處理。
接下來(lái),使用 VIC 引擎進(jìn)行色彩轉(zhuǎn)換(從 YUV 轉(zhuǎn)換為 RGB)以生成 RGB 圖像。然后,AI 模型會(huì)先對(duì)這些圖像進(jìn)行分析,以檢測(cè)感興趣的物體。在 AI 模型為物體生成邊界框后,使用 VIC 或 CUDA 的后處理步驟將馬賽克或蒙版應(yīng)用于原始 YUV pitch linear 圖像。
最后,使用 VIC 引擎將處理過(guò)的幀從 pitch linear 格式轉(zhuǎn)換回 block linear 格式,然后使用 NVENC 將其回編成 H.264 視頻。
使用 PVA 替換 CV 運(yùn)算
在蔚來(lái)的案例中,GPU 和 VIC 的負(fù)載都很重。該流水線(xiàn)涉及多個(gè) CV 運(yùn)算,包括以下方面:
block linear 和 pitch linear 格式之間的布局轉(zhuǎn)換
從 YUV 到 RGB 的顏色轉(zhuǎn)換
加馬賽克和加掩碼
這些運(yùn)算可以卸載到 PVA,以節(jié)省 GPU 和 VIC 的資源。
布局轉(zhuǎn)換和色彩轉(zhuǎn)換是 PVA 的內(nèi)存受限任務(wù),而 DMA 帶寬是瓶頸。可以使用 PVA 中的其他計(jì)算資源進(jìn)行基于邊界框和 YUV PL 圖像的加馬賽克和加掩碼。
為了進(jìn)一步加快執(zhí)行速度,還可以并行運(yùn)行 PVA 算法,由于每個(gè) PVA 實(shí)例都包含兩個(gè) VPU,每個(gè) VPU 都有一個(gè)獨(dú)立的 DMA 控制器,用于與 DRAM 交換數(shù)據(jù)。
在實(shí)施 PVA 內(nèi)核時(shí),還可以采用其他幾種技術(shù)來(lái)提高整體性能,包括 DLUT、基于硬件的循環(huán)地址生成(AGEN)、乒乓緩沖區(qū)、循環(huán)展開(kāi)等。
數(shù)據(jù)流水線(xiàn)優(yōu)化
傳統(tǒng)數(shù)據(jù)處理流水線(xiàn)中的時(shí)延可能來(lái)自?xún)蓚€(gè)方面:
在不同功能模塊或硬件加速器(例如本用例中的 PVA 和 DLA)之間復(fù)制數(shù)據(jù)會(huì)產(chǎn)生額外開(kāi)銷(xiāo)。
執(zhí)行和同步多個(gè)算法進(jìn)程所需的額外同步開(kāi)銷(xiāo)。
使用 NVIDIA DriveOS SDK 提供的 NvStreams 框架可以減少這些開(kāi)銷(xiāo)。而 PVA 硬件加速器可以利用 PVA SDK 中的 NvSci 互通性 API 與 NvStreams 高效配合,實(shí)現(xiàn)零拷貝數(shù)據(jù)轉(zhuǎn)換和異步任務(wù)提交,從而將開(kāi)銷(xiāo)降至最低。
零拷貝接口
不同硬件組件(例如 PVA 和 CPU)和應(yīng)用對(duì)內(nèi)存緩沖區(qū)有各自的訪(fǎng)問(wèn)限制或要求。為了實(shí)現(xiàn)零拷貝的目標(biāo),可采用統(tǒng)一的內(nèi)存架構(gòu),使加速器能夠與不同的應(yīng)用在 NVIDIA DRIVE SoC 上共享同一物理內(nèi)存。
在分配內(nèi)存緩沖區(qū)之前,應(yīng)收集和協(xié)調(diào)詳細(xì)的需求以確保所分配的內(nèi)存緩沖區(qū)可在必要的模塊之間共享。該功能是通過(guò) NvStreams API 實(shí)現(xiàn)的。
在成功分配可共享的內(nèi)存緩沖區(qū)后,就能以零拷貝的方式進(jìn)行不同硬件模塊或應(yīng)用之間的數(shù)據(jù)轉(zhuǎn)換。這種解決方案適用于涉及進(jìn)程間通信(IPC)或跨虛擬機(jī)(VM)的情況。如果是芯片間的數(shù)據(jù)傳輸,可在同一個(gè) NvStreams 框架下使用高速 PCIe。
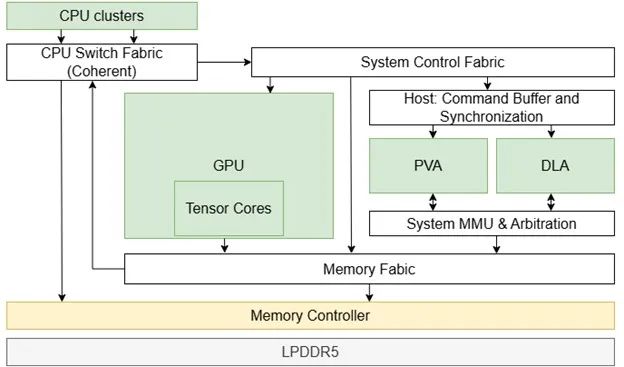
圖 5. NVIDIA DRIVE SoC(Orin)架構(gòu)
基于硬件加速器的調(diào)度
蔚來(lái)的數(shù)據(jù)流水線(xiàn)集成了多個(gè)硬件加速器,可以使用 NvSciSync 管理這些引擎之間的同步。NvSciSync 是 NVIDIA NvStreams 庫(kù)的一部分,通過(guò)管理同步對(duì)象來(lái)協(xié)調(diào)執(zhí)行各種硬件組件的操作。
首先,在加速器上運(yùn)行的任務(wù)之間插入同步點(diǎn)。當(dāng)任務(wù)開(kāi)始時(shí),后續(xù)硬件加速器會(huì)在同步點(diǎn)等待,直到前面的任務(wù)完成。任務(wù)完成后,相應(yīng)的硬件加速器會(huì)釋放同步點(diǎn),自動(dòng)觸發(fā)下一個(gè)加速器繼續(xù)執(zhí)行任務(wù)。這一過(guò)程盡可能減少了 CPU 的占用,只需進(jìn)行一些初始設(shè)置,并確保跨硬件引擎的高效同步。
基于 PVA 任務(wù)級(jí)別的調(diào)度
在原始流水線(xiàn)中,所有任務(wù)的提交和同步都由 CPU 逐個(gè)控制。這意味著 CPU 將任務(wù)提交給計(jì)算引擎,然后以同步的方式等待每個(gè)算法任務(wù)完成。
PVA 支持同時(shí)提交多個(gè)任務(wù),并只等待最后一個(gè)任務(wù)。所有提交的 PVA 任務(wù)都將同時(shí)按照指定順序進(jìn)行計(jì)算,直到所有任務(wù)完成。批量提交多個(gè)任務(wù)可減少與提交 PVA 任務(wù)相關(guān)的 CPU 負(fù)載,從而優(yōu)化性能。這樣就能解放 CPU 處理其他重要的任務(wù),并減少系統(tǒng)的整體時(shí)延。
借助 PVA SDK,用戶(hù)也可以為 PVA 算法指定調(diào)度策略以充分利用 PVA 實(shí)例上的兩個(gè) VPU。例如,用戶(hù)可以指定在單顆 VPU 上執(zhí)行某些算法。
同時(shí)使用兩個(gè) VPU 時(shí),如果任務(wù)之間有順序要求,可以在兩個(gè) VPU 上依次設(shè)置要執(zhí)行的任務(wù)。如果沒(méi)有順序要求,PVA 任務(wù)會(huì)在 VPU 空閑時(shí)立即執(zhí)行。這大大降低了多任務(wù)的執(zhí)行時(shí)延。
生產(chǎn)就緒
圖 6 顯示了蔚來(lái)使用 PVA 替換 CV 操作并將 DL 模型移植到 DLA 引擎后可用于生產(chǎn)的蔚來(lái)數(shù)據(jù)流水線(xiàn)。如需了解更多信息,請(qǐng)參閱《在 NVIDIA Jetson Orin 上部署 YOLOv5 與 cuDLA:量化感知訓(xùn)練到推理》。
https://developer.nvidia.com/zh-cn/blog/deploying-yolov5-on-nvidia-jetson-orin-with-cudla-quantization-aware-training-to-inference/

圖 6. 用于生產(chǎn)的數(shù)據(jù)流水線(xiàn)
在這個(gè)經(jīng)過(guò)優(yōu)化的流水線(xiàn)中,PVA 和 DLA 解決方案有效地滿(mǎn)足了業(yè)務(wù)需求。這種方法既可行又高效。從而使整體 GPU 資源利用率降低 10%,同時(shí)釋放 VIC 引擎用于系統(tǒng)內(nèi)的其他高優(yōu)先級(jí)任務(wù)。在 block linear 和 pitch linear 格式的轉(zhuǎn)換過(guò)程中,無(wú)需為臨時(shí)變量預(yù)先分配額外的內(nèi)存,從而大大節(jié)省了內(nèi)存。
根據(jù)蔚來(lái)的內(nèi)部評(píng)估,在系統(tǒng)中運(yùn)行該流水線(xiàn)時(shí),PVA 在 1 個(gè) VPU 實(shí)例上的負(fù)載約為 50%。由于 1 個(gè) PVA 包含兩個(gè) VPU,蔚來(lái)數(shù)據(jù)流水線(xiàn)中的 PVA 總負(fù)載約為 25%。這表明 PVA 仍有可用的算力處理該流水線(xiàn)中的其他任務(wù)。
進(jìn)一步優(yōu)化
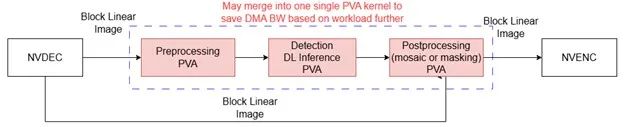
圖 7. 用于進(jìn)一步優(yōu)化的數(shù)據(jù)流水線(xiàn)
為了進(jìn)一步優(yōu)化該流水線(xiàn),可以采取以下步驟:
使用 PVA 將 DLA 替換為簡(jiǎn)單的深度學(xué)習(xí)模型,因?yàn)?PVA 目前僅有約 25% 的使用率。內(nèi)部測(cè)試表明,Yolo-Fastest 網(wǎng)絡(luò)可以成功移植到 PVA 上,并且其檢測(cè)對(duì)象的能力符合預(yù)期。
考慮將預(yù)處理、深度學(xué)習(xí)推理和后處理階段合并到單顆 PVA 內(nèi)核中,這樣就不需要在內(nèi)核之間進(jìn)行額外的 DMA 傳輸,從而降低 DMA 總帶寬。
結(jié)語(yǔ)
基于 PVA 的優(yōu)化解決方案顯著提高了蔚來(lái)的性能,并被廣泛應(yīng)用于蔚來(lái)的量產(chǎn)車(chē)型中。通過(guò)將任務(wù)卸載到 PVA,可以解放 GPU 計(jì)算資源,從而加速深度學(xué)習(xí)計(jì)算并使用戶(hù)能夠?qū)嵤└訌?fù)雜的深度學(xué)習(xí)網(wǎng)絡(luò)。
蔚來(lái)正在積極借助 PVA SDK 在 PVA 上開(kāi)發(fā)更高效的 PVA 算法,以便充分利用 NVIDIA DRIVE 平臺(tái)的額外算力,提高其產(chǎn)品的智能和競(jìng)爭(zhēng)力。
總之,PVA 提供了強(qiáng)大的工具來(lái)解決自動(dòng)駕駛汽車(chē)開(kāi)發(fā)中的計(jì)算問(wèn)題,從而能夠更高效、更有效地處理復(fù)雜的視覺(jué)任務(wù),并提高整體系統(tǒng)性能。
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5160瀏覽量
104910 -
PVA
+關(guān)注
關(guān)注
0文章
19瀏覽量
11864 -
汽車(chē)系統(tǒng)
+關(guān)注
關(guān)注
1文章
137瀏覽量
20005 -
SDK
+關(guān)注
關(guān)注
3文章
1054瀏覽量
46906 -
自動(dòng)駕駛
+關(guān)注
關(guān)注
788文章
14042瀏覽量
168165
原文標(biāo)題:使用 PVA 引擎優(yōu)化自動(dòng)駕駛汽車(chē) CV 開(kāi)發(fā)流水線(xiàn)
文章出處:【微信號(hào):NVIDIA-Enterprise,微信公眾號(hào):NVIDIA英偉達(dá)企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
谷歌的自動(dòng)駕駛汽車(chē)是醬紫實(shí)現(xiàn)的嗎?
汽車(chē)自動(dòng)駕駛技術(shù)
自動(dòng)駕駛汽車(chē)的處理能力怎么樣?
電能計(jì)量設(shè)備自動(dòng)檢定流水線(xiàn)調(diào)度優(yōu)化研究_方彥軍
淺談GPU的渲染流水線(xiàn)實(shí)現(xiàn)
如何利用樂(lè)高積木制作成自動(dòng)化流水線(xiàn)
各種流水線(xiàn)特點(diǎn)及常見(jiàn)流水線(xiàn)設(shè)計(jì)方式
如何選擇合適的LED生產(chǎn)流水線(xiàn)輸送方式
基于非常簡(jiǎn)單的Python代碼就能完成流水線(xiàn)開(kāi)發(fā)
什么是流水線(xiàn) Jenkins的流水線(xiàn)詳解

超級(jí)方便的輕量級(jí)Python流水線(xiàn)工具






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論