 PolarDB-MySQL引擎層的索引前綴壓縮能力的技術實現和效果
PolarDB-MySQL引擎層的索引前綴壓縮能力的技術實現和效果
在 PolarDB 中, 通過輕量級壓縮的實現, 可以實現減少數據大小的同時, 性能有一定程度的提升. 如何實現的呢?
背景
近幾年互聯網行業的降本增效浪潮愈演愈烈, 如數據壓縮、分級存儲等技術成為了數據庫產品(在技術層面上)實現降本的核心手段。作為一款云原生數據庫,PolarDB 會面向大量行業、場景、需求不同的云用戶,同樣有必要且已經支持了這些能力。PolarDB 在全鏈路多個層級上實現了并正逐步商業化數據壓縮能力, 如整形、字符串、BLOB 等數據格式類型的壓縮,數據列字典壓縮、二級索引前綴壓縮,存儲層的數據塊軟/硬件壓縮等。
首先要提到的必然是 MySQL 官方原生的兩種壓縮能力:表壓縮和透明頁壓縮。這兩種壓縮能力由于或這或那的各種原因,在實際線上業務中并沒有被廣泛仍可和使用。例如前者在 Buffer pool 中存在兩個版本數據且有較為復雜的融合邏輯,后者需要文件系統支持 punch hole 只能對帶寬壓縮而沒有優化 IOPS,兩者只采用限定的相對開銷較高的通用塊壓縮算法等。它們的實測表現也導致傳統 MySQL 用戶在印象里常覺得壓縮會犧牲不少性能并帶來較多復雜度。
事實上,在通用塊壓縮的基礎上,如果可以引入更細致的輕量級壓縮, 甚至在壓縮后的數據上直接進行計算, 那么可以在實現數據壓縮的同時又保證甚至提升性能。并且,在計存分離架構下,遠程 I/O 時延更長,如果可以通過壓縮減少數據大小, 從而減少 I/O, 壓縮帶來的收益相比于本地盤就更加明顯。
由 MySQL 向外擴展來看,針對:(1)動態(update-in-place)或靜態(append-only)數據;(2)行存或列存組織組織(數據同質性不同);(3)有序鏈或無序堆組織的數據(數據局部性不同)等不同情況,能適用的壓縮方法也是不同的,并且壓縮能獲得的效果會有很大差異。因此,對于 PolarDB-MySQL 來說,除了官方的兩種原生壓縮能力,通過輕量級壓縮方法實現頁內/行級壓縮(這也是 Oracle、SQL Server、DB2 等企業級數據庫的標準能力),也是重要發展路徑。
PolarDB 前綴壓縮
本文就主要介紹 PolarDB-MySQL 引擎層的索引前綴壓縮能力(Index Prefix Compression)的技術實現和效果。
通過建立索引結構可以提升數據檢索的性能,代價是額外的寫放大和維護索引結構的存儲空間。OLTP 中為了支持多種訪問路徑,比較常見的情況是在一個表上建立非常多的索引,這就導致索引在數據庫整體存儲空間中占了很大比例。索引存儲占到 50% 以上的實例并不少見,這些實例通常在單表會有幾十個二級索引。
由于索引的 key 部分數據存在有序性,因此對索引 key 部分進行前綴壓縮往往可以取得不錯的壓縮效果。如果用戶的數據表中存在較多的索引(如一些做sass的用戶),索引數據量相對整體數據量的占比不低,此時前綴壓縮的收益其實十分可觀。
我們先簡單了解一下 InnoDB 的索引結構,對于主鍵 record,首先是所有主鍵 key 的字段列、再是非 key 數據的字段列;而二級索引 record,則先是對應二級索引 key 的字段列、再是主鍵 key 的字段列。
值得一提的是,部分商業數據庫在實現 non-unique index 時,一般會將相同的二級索引對應的主鍵索引聚集存放, 這樣二級索引 key 部分的數據只需要存一份(Duplicate Key Removal)。而在 InnoDB 中的實現較為簡單, 每個二級索引 record 為重復的二級索引 key 字段加不同主鍵 key,這加劇了 InnoDB 索引數據膨脹的問題。
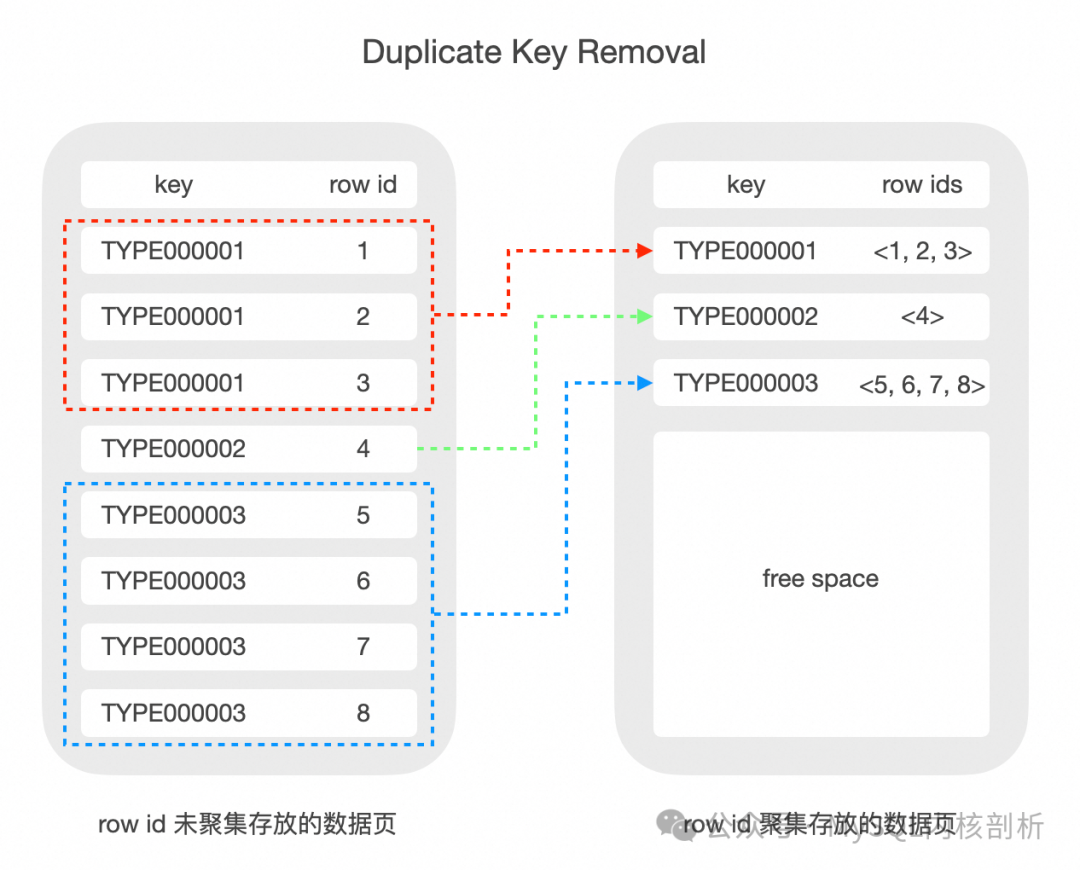
前綴壓縮設計原理
前綴壓縮其實有多種具體實現,比如同個 Page 的 record 前綴重復出現部分的直接壓縮,如前綴為 "aaaaa" 直接壓縮為 "a5";或相對前一記錄重復部分的壓縮,又或相對具體元素的前綴重復部分,提取 "aaaaa" 到公共區域作為前綴。
我們采用的方法是將 record 分為兩個部分:前綴部分在多個 record 之間共享,因此可以只存儲一份,從而實現數據壓縮;后綴部分由每個 record 單獨存儲。因此壓縮后的 record 中只存儲了前綴部分的指針 + 后綴部分的數據。
對數據頁內的 record 進行前綴壓縮效果:
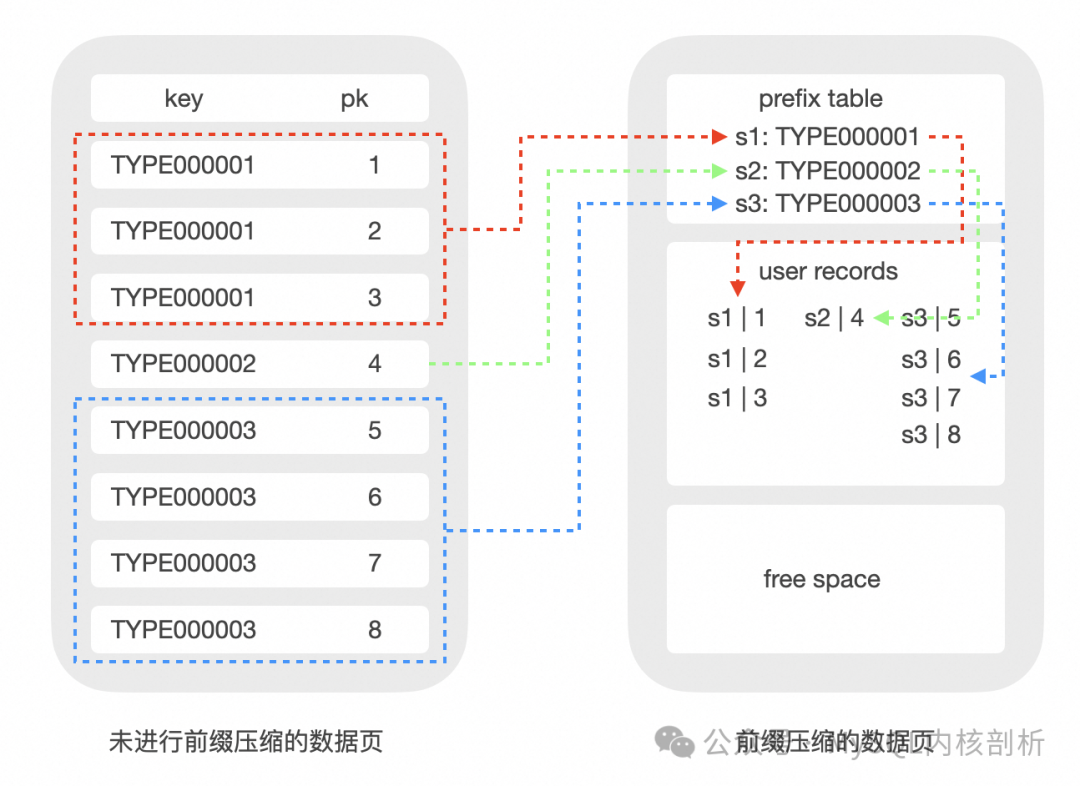
采用前綴壓縮,可以有效減少 btree 索引的節點數量:
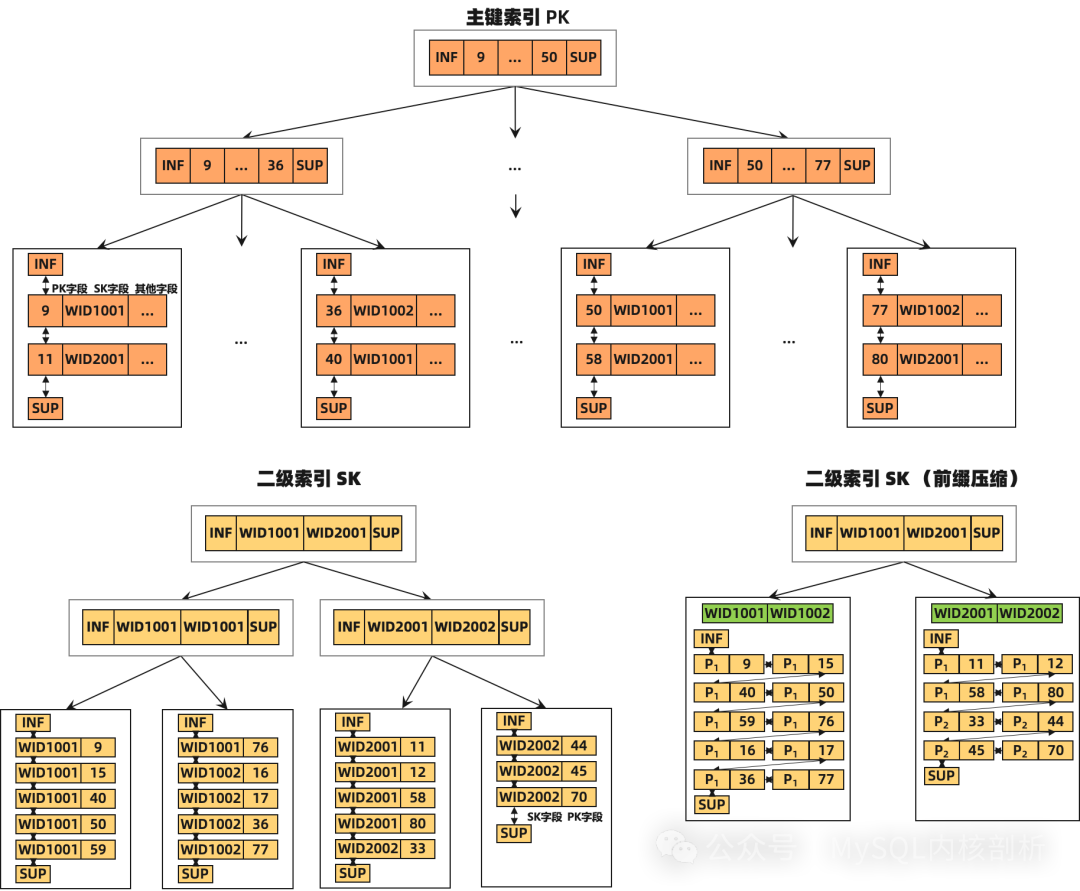
壓縮元數據的設計
對于InnoDB索引這樣有序的數據鏈,可以依賴前面的記錄作為前綴壓縮的 prefix base,也可以將 prefix base 額外存儲下來。但由于 InnoDB index 的 update-in-place 導致 record 是動態的,所以前者為動態 prefix base,而后者一般設計為(半)靜態 prefix base。對于前者,在 base record 變遷情況下,由于依賴的壓縮 record 可能膨脹,可能會進一步導致原來 optimistic 操作變成 pessimistic 的,引起明顯性能下降,并加劇代碼復雜性導致風險。因此,PolarDB 這里采用的是半靜態 prefix base 設計。
PolarDB 在 page 內部新建 symbol table 存放壓縮所需要的元信息,根據壓縮算法的不同,元信息可以是字典信息、前綴信息等等。
symbol table 放在 page 中,可以實現 page 自解析,避免讀取時額外的 IO,并且解壓 record 是開銷非常小的純內存操作。
symbol table 的物理位置在 system record 之后 user record 之前,也就是 page heap 的起始位置。一旦某個版本的 symbol table 確定之后,除非發生完整的 symbol table 更新,其內容是不會進行修改的,因此我們稱之為半靜態的。symbol table 內部有版本信息、元數據信息和元數據索引信息等等內容,用來實現 record 的快速壓縮和解壓。
數據的壓縮
以 insert 為例,當經過事務處理、記錄構建、索引定位等等操作后,最終會走到 btree 操作的底層函數中。這里會將獲取的 dtuple_t 轉換成 rec_t 選定(樂觀/悲觀)模式后插入數據,這時候應該要考慮壓縮邏輯了。我們此時已經拿了所需的 page 鎖,因此可以保證 page 內相關信息的獨占性,所有需要 page 中壓縮輔助信息內容的行壓縮可以在這一步實現。在這一過程中進行壓縮使得 rec_t 中的數據為壓縮數據,同時需要在 rec_t 保留相關的元信息。
對于前綴壓縮,我們采取壓縮的時機是 lazy 的,即新插入的 record 在 page 上保持非壓縮狀態,等到 page 容量觸發閾值時,再對 page 整體進行壓縮,這樣保證壓縮開銷被均攤到多次 DML 操作上,而不會每次操作都有壓縮開銷。
而觸發 encode 閾值是在 optimistic 路徑的 page 滿且判斷 reorganize 也無法騰出空間時觸發。原本會放鎖進入 SMO 流程,我們這里先嘗試 page 級別整體的encode。
不在 SMO 時做壓縮是因為其持有 index latch 和多個 page latch,對并發操作的影響范圍太大,其次 page 內部的壓縮不需要依賴其他信息。page 級別的壓縮會嘗試對所有記錄進行最優化選取前綴壓縮元信息,并判斷對應生成的新 symbol table 是否會有足夠收益,有則壓縮數據并更新。
我們在 record 的 Info bits 上拓展了一個 bit 來表征此記錄是否是壓縮格式,老版本記錄對應標志不會被設置從而完全兼容原有操作路徑。在一個 page 頁內可以同時存在壓縮和非壓縮兩種類型的記錄,根據對應標志位判斷處理模式。
數據的解壓
首先需要保證在所有 record 使用路徑上,解壓邏輯能夠全面覆蓋,讓用戶拿到原始記錄。其次,InnoDB 內部也存在 dtuple_t(內存記錄格式)和 rec_t(頁上物理記錄格式)兩種 record 格式類型的轉換與比較。當數據前綴壓縮后可能失去列屬性,因此 rec_get_offsets 等函數無法對壓縮后的 rec_t 直接解析,需要對應的改造相應函數獲取 rec_t 中的物理數據偏移。另外,InnoDB 記錄的比較是基于列的,offsets 本質是輔助解析 rec_t 至各列的結構,只要保證相應信息能將壓縮部分數據也能解析出來,就可以用壓縮 rec_t、壓縮元信息以及對應的 offsets,去和 dtuple_t 轉換或比較。總的來說,對于壓縮的 record,要么先完全解壓構建原來的 rec_t 數據走原來比較邏輯,要么用改造過的 offsets 或 dtuple_t 以及對應的列比較執行函數來做比較(可解釋壓縮計算)。PolarDB 目前在不同路徑上會根據環境條件從兩種方式中選擇之一。
前綴壓縮的典型應用
對于如 SaaS/電商場景等一些用戶,其數據表中存在較多的索引可以通過前綴壓縮的降低存儲成本。并且我們和客戶了解到很多情況下, 表數據中有大量的冗余重復數據, 雖然單表中總共有 1 億行, 但是某一行, 比如是品類只有 200 種左右, 這種是最常見的場景.
這種場景在 sysbench-toolkit 里面是 saas_multi_index 場景: https://github.com/baotiao/sysbench-toolkit
從下面的測試數據可以看到, 在 Saas/電商等典型場景里面, 前綴壓縮可以在獲得比較高的壓縮率同時提升整體讀寫性能。
IO Bound 場景
表結構如下
CREATE TABLE `prefix_off_saas_log_10w%d` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `saas_type` varchar(64) DEFAULT NULL, `saas_currency_code` varchar(3) DEFAULT NULL, `saas_amount` bigint(20) DEFAULT '0', `saas_direction` varchar(2) DEFAULT 'NA', `saas_status` varchar(64) DEFAULT NULL, `ewallet_ref` varchar(64) DEFAULT NULL, `merchant_ref` varchar(64) DEFAULT NULL, `third_party_ref` varchar(64) DEFAULT NULL, `created_date_time` datetime DEFAULT NULL, `updated_date_time` datetime DEFAULT NULL, `version` int(11) DEFAULT NULL, `saas_date_time` datetime DEFAULT NULL, `original_saas_ref` varchar(64) DEFAULT NULL, `source_of_fund` varchar(64) DEFAULT NULL, `external_saas_type` varchar(64) DEFAULT NULL, `user_id` varchar(64) DEFAULT NULL, `merchant_id` varchar(64) DEFAULT NULL, `merchant_id_ext` varchar(64) DEFAULT NULL, `mfg_no` varchar(64) DEFAULT NULL, `rfid_tag_no` varchar(64) DEFAULT NULL, `admin_fee` bigint(20) DEFAULT NULL, `ppu_type` varchar(64) DEFAULT NULL, PRIMARY KEY (`id`), KEY `saas_log_idx01` (`user_id`) USING BTREE, KEY `saas_log_idx02` (`saas_type`) USING BTREE, KEY `saas_log_idx03` (`saas_status`) USING BTREE, KEY `saas_log_idx04` (`merchant_ref`) USING BTREE, KEY `saas_log_idx05` (`third_party_ref`) USING BTREE, KEY `saas_log_idx08` (`mfg_no`) USING BTREE, KEY `saas_log_idx09` (`rfid_tag_no`) USING BTREE, KEY `saas_log_idx10` (`merchant_id`) ) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8
IO Bound 場景隨機讀,采用隨機 point read,128線程,4G Buffer Pool,二級索引大小 20G,壓縮后 3.5G。測得壓縮后 QPS 是 49w,非壓縮是 26w,壓縮是非壓縮的 1.88 倍。
可以看到再開啟了壓縮之后, 性能并沒有下降, 而是有一定程度的提升, 原因如下:
壓縮可以減少btree葉子節點的數量,在 IO bound 場景增加了 buffer pool 對葉子節點的覆蓋率,覆蓋更多的 page 意味著隨機讀場景更少的 page 換入換出,對 bp 的 hash table 和 lru list 訪問頻率更小,hash 鎖和 lru list 鎖競爭更少,此外,對文件系統的 IO 次數更少,用戶線程直接命中 BP 即可返回。
CPU Bound 場景
CPU Bound 場景隨機寫(index鎖沖突),256 線程,100G Buffer Pool 足夠大,單表,一個二級索引,為了效果更加明顯,將二級索引的行長設置為 500,insert 場景,測得壓縮 10w QPS,非壓縮 8w QPS,壓縮是非壓縮的 1.25 倍。
page 中 record 密度更大,減少了 page 分裂頻率,緩解了分裂對 index SX 鎖的爭搶,而且減少了正在分裂節點的父節點拿的 X 鎖數量,緩解了對其葉子節點的插入。此外,為了減少開啟壓縮后 SMO 時拿 index 鎖時間,壓縮路徑不覆蓋 SMO 過程。
CPU Bound場景隨機讀,壓縮和非壓縮性能差不多。
在 bp 足夠大時進行隨機讀取,那么壓縮并不會帶來性能提升,但訪問壓縮 record 會帶來一定解壓開銷,但解壓開銷很小(內存的隨機訪問),因此讀取性能差不多。
壓縮率
還有一個比較關心的問題就是壓縮效率,目前每個 page 有 symbol table,記錄了公共前綴,且一個 record 壓縮到最后是有一部分元數據的。所以并不是 record 越大,壓縮率就一定會更好的。假設公共前綴部分基本占據了整個 record,那么經過演算得到壓縮率隨 record size 的變化曲線是拋物線,由于默認 row 格式時 dynamic,其index key長度限制是 3072Bytes,相當于 1024 個 utf8 字符,這個值小于壓縮率取到極值的點。
測試結果:
測試二級索引大小對壓縮率的影響,探討壓縮的極限壓縮率。單線程順序insert 400w~800w條數據,datasize不超過128的插入800w行,datasize大于128的插入400w行。采用最大的重復率,即每個page里面只有幾種rec。data size是二級索引字段的大小,單位是utf8字符,data size為32相當于96Bytes,其未壓縮的索引大小是壓縮的2.92倍。注意,不同灌數據方式會導致不同的壓縮率,這里測的是單線程隨機插入,壓縮效率優于多線程并發插入,因為并發插入可能導致不必要的page分裂。
| data size | 32 | 64 | 128 | 256 | 512 |
| 壓縮率 | 2.92 | 5.04 | 8.28 | 15.11 | 27.36 |
-
壓縮
+關注
關注
2文章
102瀏覽量
19377 -
MySQL
+關注
關注
1文章
809瀏覽量
26564
原文標題:PolarDB 索引前綴壓縮
文章出處:【微信號:inf_storage,微信公眾號:數據庫和存儲】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
阿里國際推出全球首個B2B AI搜索引擎Accio
Meta開發新搜索引擎,減少對谷歌和必應的依賴
云容器引擎屬于saas層服務嗎?二者是什么關系
月訪問量超2億,增速113%!360AI搜索成為全球增速最快的AI搜索引擎
OpenAI推出SearchGPT原型,正式向Google搜索引擎發起挑戰
微軟計劃在搜索引擎Bing中引入AI摘要功能
一文了解MySQL索引機制

新火種AI|谷歌推出AI搜索引擎惹得出版商擔憂!新聞流量的至暗時刻要來了嗎?

OpenAI注冊新域名,準備推出結合AI技術的搜索引擎挑戰谷歌
OpenAI或將推出ChatGPT搜索引擎
MySQL的整體邏輯架構






 工商網監
工商網監
評論