 車載大模型分析揭示:存儲帶寬對性能影響遠超算力
車載大模型分析揭示:存儲帶寬對性能影響遠超算力
車載大模型的定義尚無,傳統大模型即LLM的參數一般在70億至2000億之間,而早期的CNN模型參數通常不到1000萬,CNN模型目前大多做骨干網使用,參數飛速增加。特斯拉使用META的RegNet,參數為8400萬,消耗運算資源很少,得分82.9也算不低;小米UniOcc使用META的ConvNeXt-B,參數8900萬,消耗運算資源最少,得分83.8;華為RadOcc使用微軟的Swin-B,參數8800萬。相對于早期的CNN模型,這些都可以叫大模型,但要與真正意義上的ChatGPT之類的LLM大模型比,這些是小模型都稱不上,只能叫微模型。
不過,端到端的出現改變了這一現狀,端到端實際上是內嵌了一個小型LLM,隨著喂養數據的增加,這個大模型的參數會越來越大,最初階段的模型大小大概是100億參數,不斷迭代,最終會達到1000億以上。非安全類的大模型應用基本不用考慮計算問題,所以只要是個手機都敢說能跑數百億的大模型,實際很多算力不如手機的電腦也能跑,因為延遲多幾秒幾十秒也沒有問題,但自動駕駛必須將延遲降低到幾十毫秒內。但你要以為這對算力要求更高了,那就大錯特錯了,存儲帶寬遠比算力重要千倍。
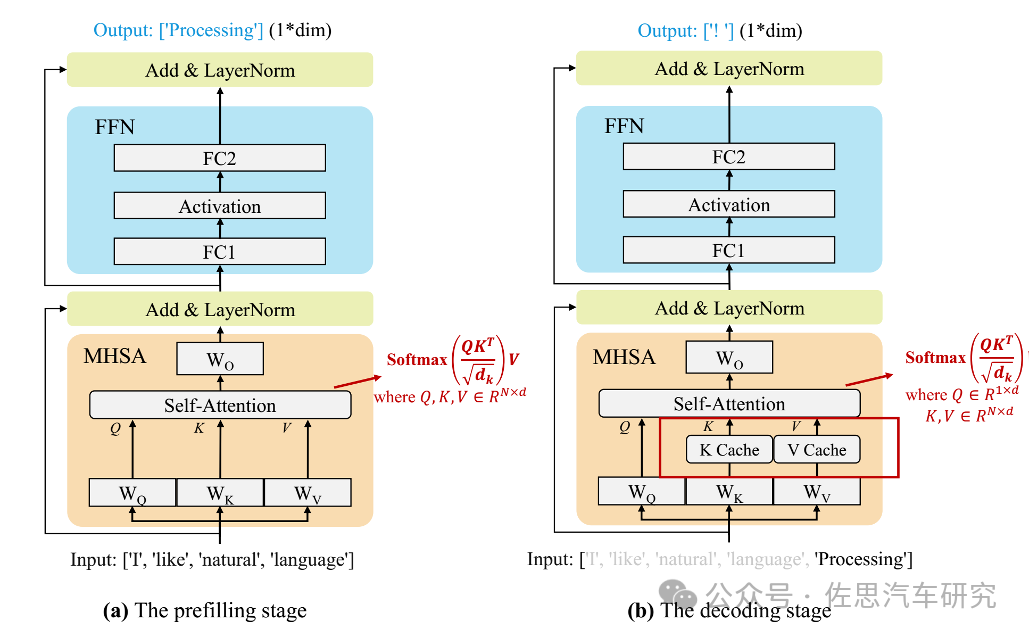
當前的主流 LLM 基本都是Decoder Only的Transformer模型,其推理過程可分為兩個階段:
圖片來源:論文 A Survey on Efficient Inference for Large Language Models
Prefill:根據輸入Tokens(Recite, the, first, law, of, robotics) 生成第一個輸出 Token(A),通過一次Forward就可以完成,在Forward中,輸入Tokens間可以并行執行(類似 Bert這些Encoder模型),因此執行效率很高。
Decoding:從生成第一個Token(A)之后開始,采用自回歸方式一次生成一個Token,直到生成一個特殊的Stop Token(或者滿足用戶的某個條件,比如超過特定長度)才會結束,假設輸出總共有N個Token,則Decoding階段需要執行N-1次Forward,這N-1次Forward 只能串行執行,效率很低。另外,在生成過程中,需要關注的Token越來越多(每個Token 的生成都需要Attention之前的Token),計算量也會適當增大。
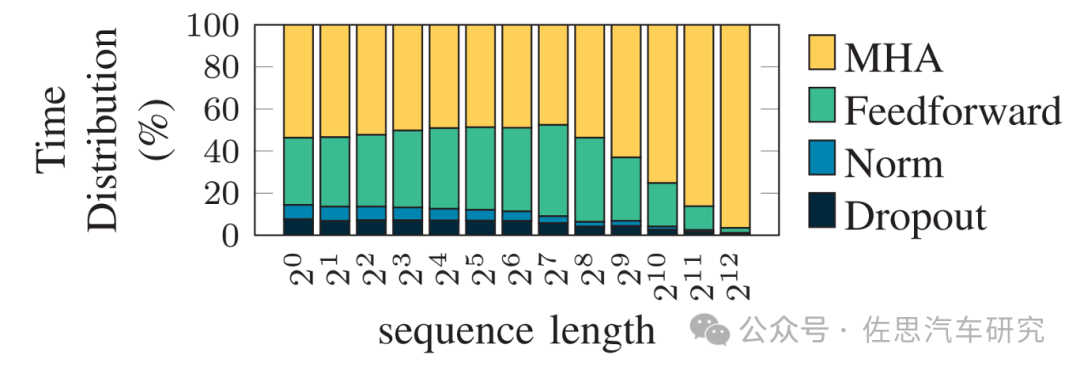
LLM推理計算過程時間分布
圖片來源:論文Memory Is All You Need: An Overview of Compute-in-Memory Architectures for Accelerating Large Language Model Inference
在車載自動駕駛應用場合,序列長度基本可等同于攝像頭的像素數量和激光雷達的點云密度。
圖片來源:論文Memory Is All You Need: An Overview of Compute-in-Memory Architectures for Accelerating Large Language Model Inference
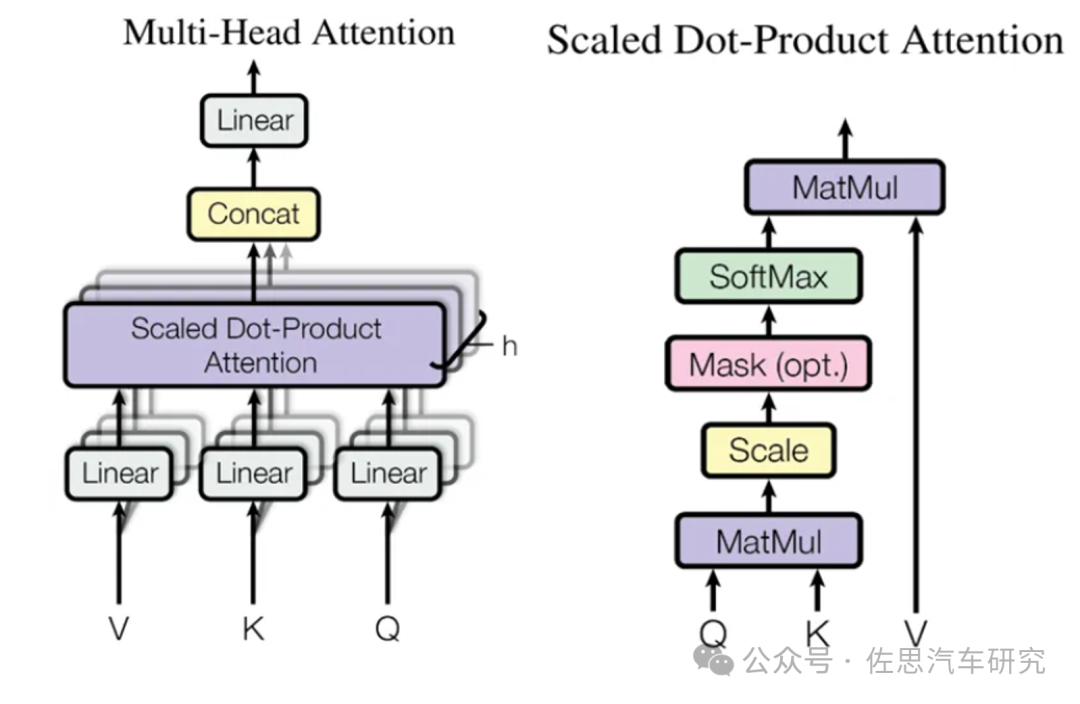
在 LLM 推理中最關鍵的就是上圖中的Multi-Head Attention(MHA),其主要的計算集中在左圖中灰色的 Linear(矩陣乘)和Scaled Dot-Product Attention中的MatMul 矩陣乘法。
圖中的Mask是一個下三角矩陣,也是因為這個下三角矩陣實現了LLM Decoder的主要特性,每個Token都只能看到當前位置及之前的Token。其中的QKV可以理解為一個相關性矩陣,4個Token對應4 個Step,其中:
Step 2依賴Step 1的結果,相關性矩陣的第1行不用重復計算。
Step 3依賴Step 1和Step 2的結果,相關性矩陣的第1行和第2行不用重復計算。
Step 4依賴Step 1、Step 2和Step 3的結果,相關性矩陣的第1行、第2行和第3行不用重復計算。
在Decoding階段Token是逐個生成的,上述的計算過程中每次都會依賴之前的結果,換句話說這是串行計算,而非GPU擅長的并行計算,GPU大部分時候都在等待數據搬運。加速的辦法是計算當前Token時直接從KV Cache中讀取而不是重新計算,對于通用LLM,應用場景是要考慮多個并發客戶使用,即Batch Size遠大于1,KV Cache的緩存量會隨著Batch Size暴增,但在車里用戶只有一個,就是自動駕駛端到端大模型,即Batch Size為1。
因為Decoding階段Token逐個處理,使用KV Cache之后,上面介紹的Multi-Head Attention 里的矩陣乘矩陣操作全部降級為矩陣乘向量即GEMV。此外,Transformer模型中的另一個關鍵組件FFN 中主要也包含兩個矩陣乘法操作,但 Token之間不會交叉融合,也就是任何一個Token都可以獨立計算,因此在Decoding階段不用Cache之前的結果,但同樣會出現矩陣乘矩陣操作降級為矩陣乘向量。Prefill階段則是GEMM,矩陣與矩陣的乘法。
矩陣乘向量操作是明顯的訪存bound,而以上操作是LLM推理中最主要的部分,這也就導致LLM推理是訪存bound類型。
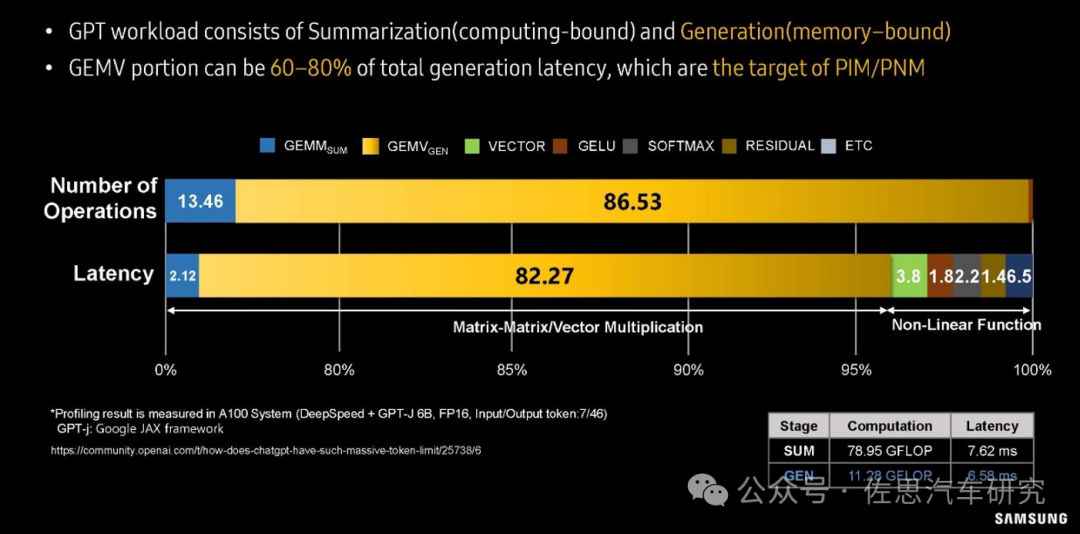
三星對GPT大模型workload分析
圖片來源:SAMSUNG
上圖是三星對GPT大模型workload分析。在運算操作數量上,GEMV所占的比例高達86.53%;在大模型運算延遲分析上,82.27%的延遲都來自GEMV,GEMM所占只有2.12%,非線性運算也就是神經元激活部分占的比例也遠高于GEMM。
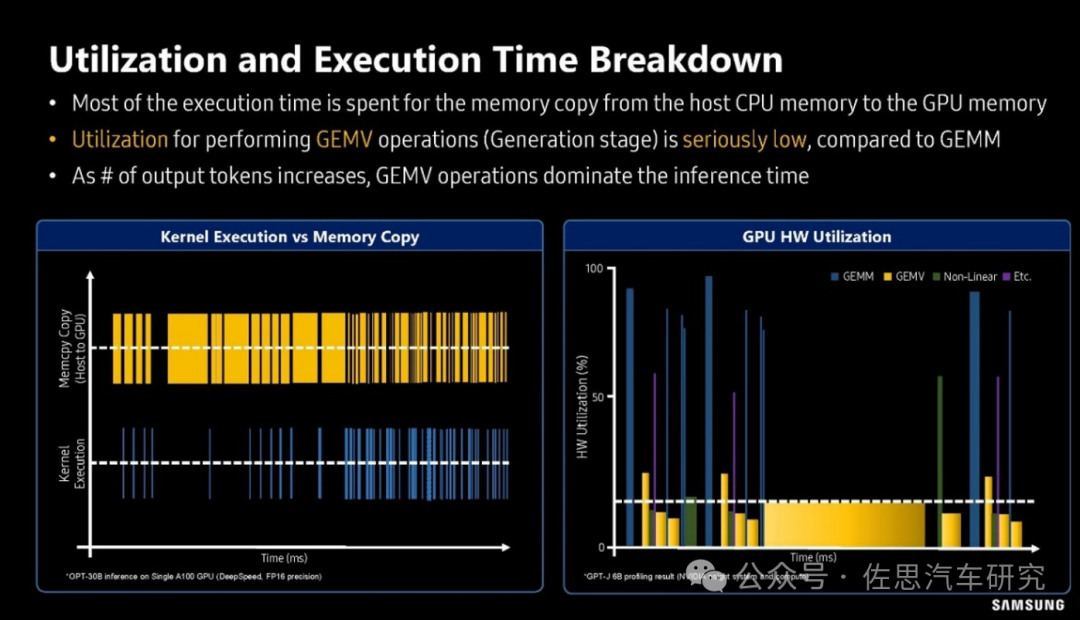
三星對GPU利用率的分析
圖片來源:SAMSUNG
上圖是三星對GPU利用率的分析,可以看出在GEMV算子時,GPU的利用率很低,一般不超過20%,換句話說80%的時間GPU都是在等待存儲數據的搬運。還有如矩陣反轉,嚴格地說沒有任何運算,只是存儲行列對調,完全是存儲器和CPU在忙活。解決辦法很簡單且只有一個,就是用HBM高寬帶內存。
與傳統LLM最大不同就是車載的Batch Size是1,導致GPU運算效率暴跌,傳統LLM的Batch Size通常遠大于1,這讓GPU效率增加。
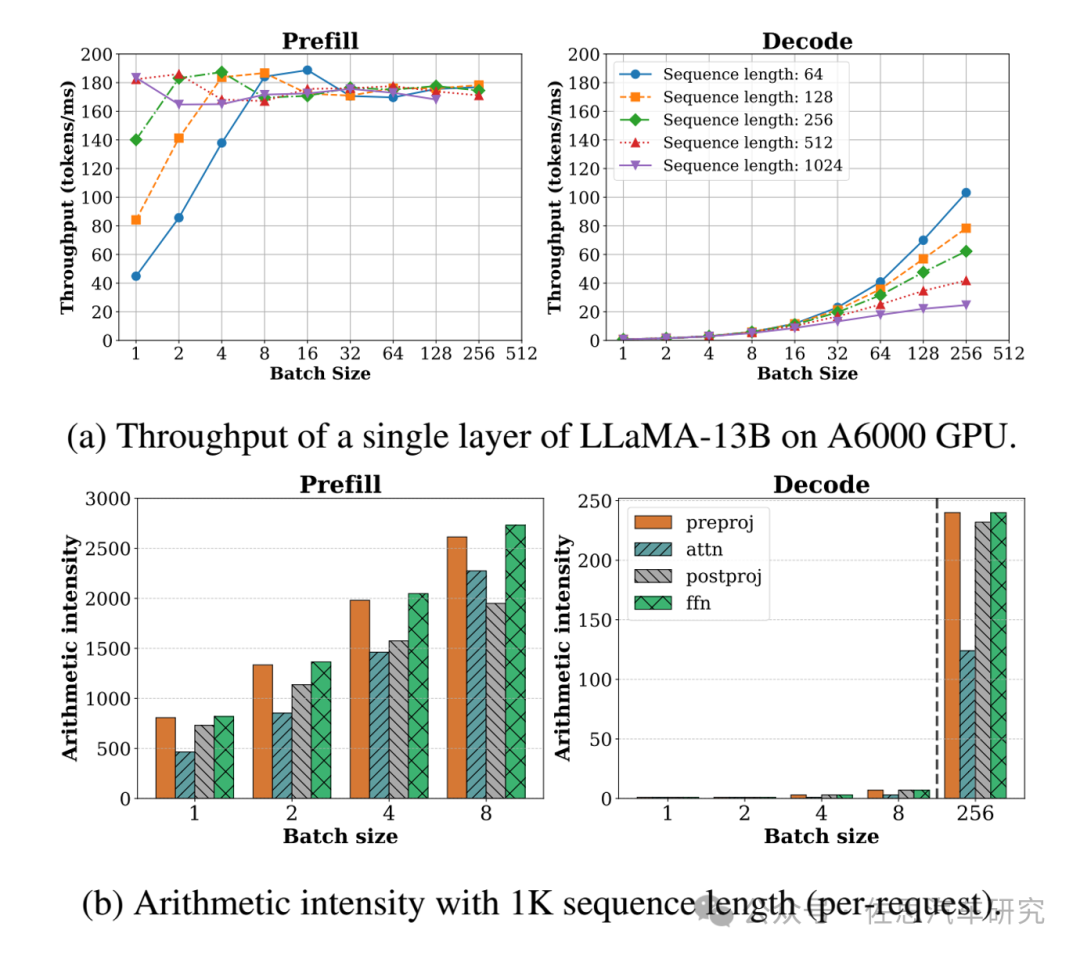
圖片來源:論文SARATHI: Effcient LLM Inference by Piggybacking Decodes with Chunked Preflls
圖上不難看出,Batch Size越大,推理速度反而越快,但KV Cache容量會暴增;車載的Batch Size是1,推理速度反而很慢,好處是根本不用考慮KV Cache的容量。
最終我們可以得出結論,存儲帶寬決定了推理計算速度的上限。假設一個大模型參數為70億,按照車載的INT8精度,它所占的存儲是7GB,如果是英偉達的RTX4090,它的顯存帶寬是1008GB/s,也就是每7毫秒生成一個token,這個就是RTX4090的理論速度上限。特斯拉第一代FSD芯片的存儲帶寬是63.5GB/s,即每110毫秒生成一個token,幀率不到10Hz,自動駕駛領域一般圖像幀率是30Hz;英偉達的Orin存儲帶寬是204.5GB/s,即每34毫秒生成一個token,勉強可以達到30Hz,注意這只是計算的數據搬運所需要的時間,數據計算的時間都完全忽略了,實際速度要遠低于這個數據。并且一個token也不夠用,至少需要兩個token,端到端的最終輸出結果用語言描述就是一段軌跡,比如直行,直行需要有個限制條件,至少有個速度的限制條件,多的可能需要5個以上token,簡單計算即可得出存儲帶寬需要1TB/s以上。
實際情況遠比這個復雜的多。車載領域不是傳統LLM使用CPU和GPU分離形式,車載領域的計算SoC都是將CPU和AI運算部分合二為一,AI運算部分通常是GPU或加速器是和CPU共享內存的。而在非車載領域,GPU或AI運算部分有獨立的存儲,即顯存。車載領域共享內存一般是LPDDR,它主要是為CPU設計的,注重速度即頻率而非帶寬。不像顯存,一般是GDDR或HBM,注重帶寬,不看重頻率高低。上述所有理論都是基于顯存的,在車載領域共享LPDDR,其性能遠遠低于單獨配置的顯存,無論是速度還是容量,共享存儲都必須遠比單獨的顯存要高才能做到大模型推理計算。
理想用英偉達Orin做了測試,純端到端模式延遲高達1.5秒。

圖片來源:論文DRIVEVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
所以車載領域存儲比算力重要很多,最好的解決辦法是HBM,但太貴了,32GB HBM2最低成本也得2000美元,汽車領域對價格還是比較敏感的,退而求其次,就是GDDR了。GDDR6的成本遠低于HBM,32GB GDDR6大概只要180美元或更低。
幾代GDDR的性能對比
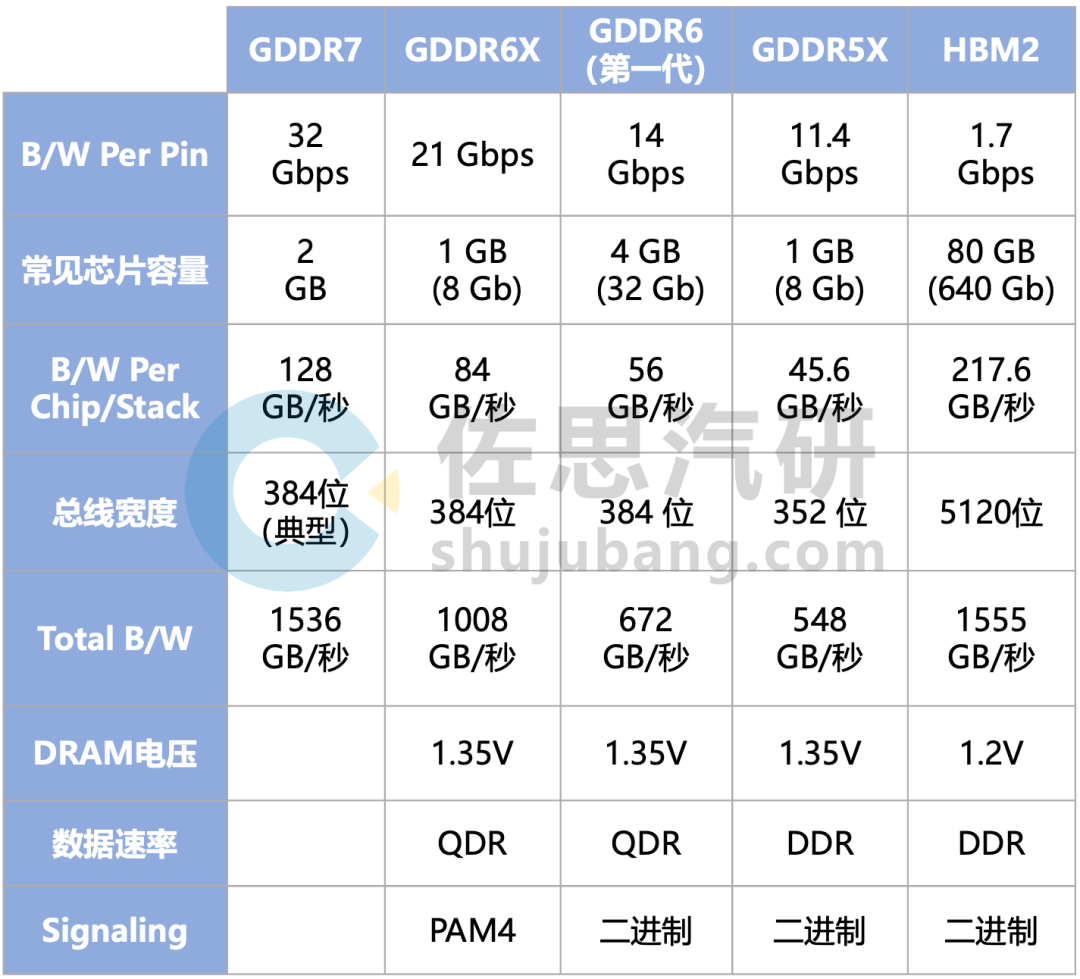
整理:佐思汽研
基本上GDDR6的理論上限就是672GB/s,特斯拉第二代FSD芯片就支持第一代GDDR6,HW4.0上的GDDR6容量為32GB,型號為MT61M512M32KPA-14,頻率1750MHz(LPDDR5最低也是3200MHz之上),是第一代GDDR6,速度較低。即使用了GDDR6,要流暢運行百億級別的大模型,還是無法實現,不過已經是目前最好的了。
GDDR7正式標準在2024年3月公布,不過三星在2023年7月就發布了全球首款GDDR7,目前SK Hynix和美光也都有GDRR7產品推出。有些人會說,換上GDDR7顯存不就行了,當然沒那么容易,GDDR需要特殊的物理層和控制器,芯片必須內置GDDR的物理層和控制器才能用上GDDR,Rambus和新思科技都有相關IP出售。
圖片來源:網絡
在芯片領域,GDDR7增加的成本和LPDDR5X一樣的。
特斯拉的HW4.0過了一年半毫無動作,筆者認為特斯拉的第二代FSD芯片顯然是落伍了,特斯拉也不打算大規模用了,特斯拉的第三代FSD芯片應該正在開發中,可能2025年底就完成開發,至少支持GDDR6X。
大模型時代,Attention Is All You Need,同樣大模型時代 Memory Is All You Need。
-
存儲
+關注
關注
13文章
4337瀏覽量
85994 -
帶寬
+關注
關注
3文章
941瀏覽量
40991 -
LLM
+關注
關注
0文章
296瀏覽量
356
原文標題:車載大模型計算分析:存儲帶寬遠比算力重要
文章出處:【微信號:zuosiqiche,微信公眾號:佐思汽車研究】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
浪潮信息與智源研究院攜手共建大模型多元算力生態
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--了解算力芯片CPU
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--全書概覽
名單公布!【書籍評測活動NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架構分析
名單公布!【書籍評測活動NO.41】大模型時代的基礎架構:大模型算力中心建設指南
IaaS+on+DPU(IoD)+下一代高性能算力底座技術白皮書
中國算力中心市場持續增長,智能算力規模快速崛起
算力系列基礎篇——算力與計算機性能:解鎖超能力的神秘力量!

2024多樣性算力產業峰會:江波龍解碼AI存儲方案的未來之路


液冷是大模型對算力需求的必然選擇?|英偉達 GTC 2024六大亮點

智能算力規模超通用算力,大模型對智能算力提出高要求






 工商網監
工商網監
評論