 初探AI測試分析
初探AI測試分析
在人工智能中,算法不只是用代碼敲出來這么簡單的,而是由訓練數據、標簽和神經網絡的結合產生的,這是機器學習的本質。算法本身沒有直接洞察力,也不能直接像缺陷一樣被修復:它屬于“黑盒開發”。
人工智能系統需要具備應用于不同數據和不同應用場景的能力。訓練數據和標簽的選擇會引起偏差和透明度的風險,可能對真實情況產生重大影響。測試人工智能的重點在于這些風險。人工智能測試需要道德、社會和意識,以突出用戶、預期,并將這些預期轉化為可重復運行和自動化的測試用例。人工智能測試包括設置指標,將測試結果轉化為對系統的有意義和可量化的評估,以便開發人員優化系統。
1. 介紹
毫無疑問,未來屬于人工智能。它已經進入了我們的日常生活,并被世界各地的大公司所使用。人工智能的適用性似乎無窮無盡。然而,仍然存在許多疑慮和擔憂。例如,在自動駕駛汽車的情況下:事故責任、不穩定的物體識別以及與不可預測的人類交通參與者的復雜互動阻礙了它的廣泛推廣。人工智能的一些可能令人恐懼的影響已經顯現出來。人工智能算法可以制造和擴大偏差。例如,在緬甸的種族清洗中,數以萬計的羅興亞人被殺害,100萬人流離失所。Facebook算法支持了已經存在的種族緊張局勢,這偏差觀點得到強化,因為它被優化為點擊成功則被獎勵。負面信息在搜索結果中越來越多地出現。每個AI軟件開發人員都在與這些疑慮和風險作斗爭。AI測試,什么是缺陷,如何修復它?如何確保系統在各種輸入做正確的事情?如何獲得正確率的信心?結果對所有相關方公平嗎?當前的發展、觀點和價值觀是否反映在算法中?從測試的角度來看,AI的最大風險是什么,如何處理這些風險?
2. 介紹
2.1. AI 屬于黑盒開發
在人工智能中,算法、系統在標準、決策和行動方面的行為,并沒有明確地體現在代碼中。在非人工智能開發中,代碼直接表達了算法。在人工智能中,算法是訓練數據、參數化、標簽和神經網絡選擇的產物,而且無法在代碼中體現。代碼、神經網絡只是通過訓練產生算法的系統的一個組成部分,這是機器學習的本質。
2.2. 機器學習和神經網絡
機器學習和人類學習之間有很強的相似性。以一個孩子第一次學習使用一個概念為例。這個孩子被告知,它抱著的毛茸茸的生物是一只“貓”。現在,這個孩子開始用自己的神經網絡工作。貓的概念與不是貓的物體(如“爸爸”)進行比較。神經網絡的工作方式是找到一種配置自己的方法,如果它看到貓,它會將其歸類為貓,而不是爸爸。它通過找到差異、標準(如皮毛、胡須、四條腿等)來做到這一點。但我們不知道這些標準到底是什么。它們也可能是“捉老鼠”、“呼嚕聲”或“白色”。我們無法在大腦中找到貓的概念及其標準,也無法直接在大腦中糾正它。
神經網絡由許多代碼塊(“節點”)組成,這些代碼塊按層排列,每個節點層都連接到其上下層。節點沒有被預先編程以執行特定任務。節點只是小型的計算器,處理頂層呈現給它們的部分并返回計算結果。給定兩張圖片,一張是貓,一張是爸爸,它將嘗試不同的配置,以找到一種配置,將一個樣本識別為貓,另一個樣本識別為爸爸。它將找出差異,以便其配置將在下一次給出正確的分類。
2.3. 算法=數據+編碼+標簽
因此,該系統產生的算法由從樣本中衍生出的模型組成,因此它可以對輸入進行分類和識別,并給它們打標簽。該算法是神經網絡的產物,但主要基于訓練數據和標簽。因此,算法不是代碼,而是代碼+訓練數據+標簽。
2.4. 模糊邏輯和數學
雖然整個系統所做的只是計算,產生數字,但這些數字不會產生布爾結果:例如:“這是爸爸”或“這是一只貓”。結果將是從節點和層中計算的所有數字的總和,每個數字都表示根據每個給定的標簽滿足標準的程度。這幾乎不可能(在0-1區間)達到1。其次,它還會給樣本給出評分。因此,呈現給系統的新圖片可能會將“貓性”評為0.87,將“爸爸性”評為0.13。結論是,樣本是一只貓,但它不是100%的貓,也不是0%的爸爸。因此,人工智能的最終產品是計算、概率,而不是100%的確定性。
2.5. 開發與糾錯
神經網絡的開發包括開發神經網絡本身,但大多數開發人員使用現成的神經網絡。接下來,他們需要配置神經網絡,使其能夠接收手工的輸入并配置標簽。最后,神經網絡的層可以參數化:計算結果可以加權,以便某些結果對最終結果的影響比其他結果更大。這些是開發人員擁有的主要調整工具。如果系統表現不令人滿意,則可以調整參數。這不是一個重點的缺陷修復,而是糾正一個缺陷決策的例子。參數化將影響結果,但每次調整都會對整體性能產生影響。在人工智能中,存在大量的“回歸”:對不打算改變的系統部分產生不必要和意想不到的影響。訓練數據和標簽也可能成為影響系統的候選因素。在人工智能的某些問題上,例如欠擬合,擴大訓練數據很可能會改善系統。欠擬合指的是模型無法很好地擬合訓練數據,無法捕捉到數據中的真實模式和關系。欠擬合可以比喻為一個學生連基本的知識都沒有掌握好,無論是老題還是新題都無法解答。這種情況下,模型過于簡單或者復雜度不足,無法充分學習數據中的特征和模式。
2.6. 整體評估和指標
當缺陷修正無法聚焦,每次微調都會導致大規模回歸時,大規模回歸測試是必要的。問題“我們是否修復了這個缺陷?”成為一個次要問題。我們想知道每次更改后的整體行為。我們想知道與其他版本相比,系統的整體性能如何。在整體評估中,我們需要考慮AI的輸出:計算結果既不是真也不是假。每個結果都是一個等級。因此,最終結果應該進行全面比較、權衡和合并,以便我們可以決定一個版本是否優于另一個版本,是否應該使用它。結果將是基于預期和它們相對重要性的輸出價值的度量。
3. AI風險
我們將在這里討論最重要的風險。這些風險是人工智能的典型風險,可能會對人工智能的質量、客戶、用戶、人們甚至世界產生嚴重影響。在開始測試之前,應該考慮這些風險,為測試人員提供重點提示。在分析測試結果時,應該考慮這些風險。
作為對意外結果的因果分析,這可以為優化系統提供線索。例如:欠擬合的系統最需要更多樣化的訓練數據,過擬合的系統需要簡化標簽。
3.1. 偏差
人工智能的主要風險是“偏差”的類型。在人類智能中,我們稱之為偏差。由于訓練數據和概念的限制,我們看待事物過于簡單(簡化)或存在(偏差)。概念的高粒度可能意味著系統無法充分概括,導致結果毫無用處。
3.1.1. 選擇偏差
如果訓練數據選擇遺漏了現實世界中的重要元素,這可能會導致選擇偏差。與實際結果相比,上次歐洲選舉的民意調查預測,荷蘭的歐洲懷疑黨將獲得比實際選舉高得多的勝利。民意調查沒有過濾人們是否真的會投票。歐洲懷疑論者被證明比其他選民更有可能不投票。
3.1.2. 固定偏差
急于驗證一個高度相信或投入的假設可能會導致選擇或過度重視證實該論點的數據,而忽視可能存在的缺陷。科學家、政客和產品開發者可能容易受到這種偏差的影響,即使他們有最好的意圖。一個醫療援助組織為了籌集更多資金,夸大了可能的糧食危機,顯示死亡人數上升,但沒有顯示與饑荒和總人口數無關的死亡人數。
3.1.3. 欠擬合
缺乏多樣性的訓練數據會導致欠擬合。學習過程將無法確定關鍵的判別標準。訓練軟件識別狼和狗,將哈士奇識別為狼,因為它沒有學到狗也可以在雪中看到。如果我們只在荷蘭獲得與毒品相關的新聞信息,會發生什么?
3.1.4. 過擬合
當標簽對于人工智能系統的目的來說過于多樣化和多樣化時,就會出現過度擬合。過擬合(Overfitting)指的是模型在訓練數據上表現得過于優秀,但在未見數據上表現較差。過擬合可以比喻為一個學生死記硬背了一本題庫的所有答案,但當遇到新的題目時無法正確回答。這種情況下,模型對于訓練數據中的噪聲和細節過于敏感,導致了過度擬合的現象。
3.1.5. 異常值
異常值是極端的例子,對算法有太大的影響。如果你的1歲大的孩子看到的第一只貓是無毛貓,這將對他對貓的概念產生重大影響,需要用多個正常貓的例子來糾正。
3.1.6. 混淆變量
模式識別和分析通常需要結合數據,特別是當尋找因果關系時。當不同數據模式因數據分析目的而相關聯而沒有實際因果關系時,混淆變量就會出現。人們通常認為,喝紅葡萄酒會引起偏頭痛發作,因為據報道,喝紅葡萄酒和偏頭痛是相繼發生的。新研究表明,偏頭痛發作是由食欲變化引起的,如對紅葡萄酒的渴望。喝紅葡萄酒是一種副作用,而不是偏頭痛的原因!
3.2. 可追溯性
對于非人工智能系統,算法就是代碼。對于人工智能系統,情況并非如此,因此我們不知道人工智能系統做出決策的確切標準。此外,很難監督訓練數據的總體情況,因此很難很好地了解人工智能系統將如何表現。因此,當結果明顯不正確時,很難確定原因并糾正。是訓練數據、參數、神經網絡還是標簽?可追溯性的缺乏導致過度自信和信心不足,并導致責任的不確定性(是軟件、數據、標簽還是上下文造成的?)以及缺乏可維護性。
4. 測試AI
減輕人工智能風險的關鍵是透明度。在偏差方面,我們需要了解訓練數據和標簽的代表性,但最重要的是,我們需要了解期望和結果對所有相關方的重要性如何反映在結果中。建立適當程度的信心和可追溯性也需要透明度。通過照亮代碼,將無法實現透明度。即使這是可能的,通過顯示代碼的熱圖,表明當分析對象的特定部分或產生層中的計算時,神經網絡的哪個部分是活躍的,這意味著幾乎什么都沒有。觀察大腦內部將永遠不會顯示思想或決定。它可以顯示哪個部分被激活,但所有的心理過程都涉及多個大腦部分,最重要的是過去的經驗。人工智能系統是黑盒子,因此我們應該像在黑盒測試中一樣測試它們:從外部,開發基于現實輸入的測試用例。從那里確定對輸出的期望。聽起來很傳統,很熟悉,不是嗎?測試人工智能的基本邏輯可能很熟悉,具體的任務和元素卻大不相同。
傳統上,需求和規格是預先確定的,測試人員在開始時就可以使用它們。在人工智能中,需求和規格是如此多樣化和動態,以至于不能期望它們在開始時完全和一次就確定。產品所有者和業務顧問應該交付需求,但測試人員需要采取主動,以他們需要的形式、粒度和現實性獲得需求。
4.1. 神經網絡、訓練數據和標簽
靜態測試可以及早發現缺陷。可以選擇神經網絡:有哪些替代方案?對于這項審查,需要對所有可能的神經網絡及其特定質量和缺點有廣泛的了解。訓練數據和標簽可以審查和評估風險敏感性:
1. 數據是否很好地反映了現實生活中的數據來源、用戶、視角和價值觀?是否有被忽視的相關數據來源?研究結果可能表明選擇偏差、確認偏差或不足。
2. 數據來源和數據類型是否平均分配?不同類型、不同組別的代表性如何?研究結果可能表明不足、選擇偏差、確認偏差或異常值。
3. 標簽是否公平地反映了現實生活中的群體或數據類型?標簽是否與系統應分析的現實情況或模式相匹配?研究結果可能表明過度擬合、不足或混淆變量。
4. 數據是否足夠?期望的刷新速率是多少?是否匹配?現實世界中是否有事件在數據中沒有得到充分反映?
4.2. 識別用戶
該系統的所有者并不是唯一有價值的視角!像搜索系統這樣的AI系統是其用戶世界的重要組成部分,也是那些被其“貼標簽”的人的重要組成部分。AI系統的質量可能具有道德、社會和政治方面的意義和影響,因此需要加以考慮。AI的用戶往往是多樣化的,很難知道。他們不是一組固定的訓練有素的用戶,他們不會聚集在一個房間里,他們的行為和期望是可以管理的。他們可能是整個世界,就像搜索引擎的情況一樣:一個訪問阿姆斯特丹的美國游客或一個經驗豐富的藝術愛好者在搜索“珍珠女孩”時,他們的需求和期望非常不同。
一個博物館的搜索引擎。游客想知道一張特定的圖片是否用于展示,藝術愛好者也想了解背景信息和草圖。接下來:隨著世界的變化,用戶和他們的期望可能會在一夜之間發生變化。想想巴黎圣母院的大火對那些搜索“巴黎圣母院”或“巴黎大火”的用戶可能有什么影響。AI在DNA序列中識別病毒應該考慮到不斷發生的可能突變。因此,測試AI首先要確定用戶或系統輸出將被使用的視角。這意味著研究系統使用的數據分析,采訪流程所有者或采訪真實用戶。
4.3. 分析用戶
識別用戶或數據組是一回事,確定他們想要什么、期望什么、需要什么、害怕什么或會如何表現是另一回事。測試人員需要的是用戶和視角的簡介:他們的背景是什么,他們想要什么,什么會讓他們反感或不安,他們有什么期望?一種創建簡介的技術是“Persona”。這種技術的關鍵是不要考慮整個用戶組,而是從該組中選擇一個人,并盡可能使其具體化。Persona的好處是,它讓用戶變得栩栩如生。這是一種從內到外考慮用戶視角的技術。例如:美國游客的Persona可以是喬,一個水管工,住在芝加哥,白人,45歲,已婚,有兩個孩子。他讀書不多,但喜歡色彩鮮艷、制作精良的繪畫。他的愛好是釣魚和翻新舊音響設備。
4.4. 創建測試用例
對于測試人員來說,這部分可能是大部分工作。根據每個用戶的個人資料,輸入和預期輸出被確定下來。良好的個人資料將提供一個良好的基礎,但可能需要來自研究和訪談的額外信息。識別測試用例永遠不會是完整的,也不會是決定性的:你不能測試一切,在人工智能領域也是如此。世界和用戶都在變化,因此需要在需求中反映出這一點。它從最重要的案例開始;它將不斷增長,需要永久維護。
4.5. 測試數據
使用哪些測試數據以及是否可以創建、發現或操作這些數據取決于上下文和生產數據的可用性。數據創建或操作(如圖像識別)是很難做到的,有時是無用的,甚至是適得其反的。使用工具來操作或創建圖像會帶來額外的變量,這可能會產生偏差!測試數據對現實世界圖片的代表性如何?如果算法在創建的數據中識別出只能在測試數據中找到的方面,測試的價值就會受到影響。AI測試人員從真實數據中創建測試數據集,并嚴格地將這些數據與訓練數據分開。由于AI系統是動態的,它所使用的世界是動態的,測試數據必須定期更新。
4.6. 度量
人工智能的輸出不是布爾值:它們是所有可能結果(標簽)的計算結果。要確定系統的性能,僅僅確定哪個標簽的得分最高是不夠的。指標是必要的。以圖像識別為例:我們想知道一張貓的圖片是否會被識別為貓。在實踐中,這意味著標簽“貓”的得分將高于“狗”。如果貓的得分是0.43,狗的得分是0.41,那么貓就贏了。但得分之間的微小差異可能表明故障概率。在搜索引擎中,我們想知道頂部的結果是否是用戶期望的前1名,但如果前1名的結果是列表中的第2名,聽起來就不對,但仍然比第3名要好。我們想知道所有相關結果是否都在前10名(這被稱為精確度),或者前10名中沒有冒犯性的結果。根據上下文,我們需要用指標來處理AI系統的輸出,對其性能進行評估。測試人員需要具備確定相關指標并將其納入測試的能力。
4.7. 權重和契約
對人工智能系統的總體評估還必須納入相對重要性。與任何測試一樣,一些結果比其他結果更重要。想想具有高度道德影響的結果,比如種族偏差。作為設計測試用例的一部分,它們對總體評估的權重應根據風險和對用戶的重要性來確定。測試人員需要對這些風險敏感,能夠識別它們,將其轉化為測試用例和指標。他們需要了解系統使用情況和用戶心理的背景。人工智能測試人員需要同理心和世界意識。
在電影《機械戰警》中,墨菲警官的系統中有一個“首要指令”程序:如果他試圖逮捕他所在公司的董事總經理,他的系統就會關閉。人工智能系統也可以有“首要指令”,或者出現無法接受的結果,比如冒犯性語言、色情網站或撞倒行人。我們稱之為“契約”:在測試結果中,這些可能不需要的結果應該被標簽為阻止問題,或者至少應該被給予很高的權重。
4.8. 測試自動化
人工智能測試需要大量的自動化。測試用例的數量要求它這樣做,并且需要對新版本進行重復測試。當人工智能系統不斷訓練時,測試是必要的,就像搜索引擎的情況一樣,其中存在來自實際數據的反饋回路。但是,即使當人工智能系統沒有不斷訓練并且系統版本穩定時,不斷變化的環境也需要不斷訓練。即使系統沒有改變,世界也會改變。測試自動化包括一個測試框架,測試用例將在人工智能系統上運行,并且人工智能系統的輸出將被處理。以下是一個測試框架的基本設置。
4.9. 整體評估和優化輸入
測試的結果不僅僅是一份需要修復的缺陷清單。如上文所述,如果沒有嚴重的回歸,缺陷是無法直接修復的。人工智能系統必須作為一個整體進行評估,因為隨著許多測試用例和回歸,沒有哪個版本是完美的。如果一個新版本比舊版本更好,程序員希望知道該采用哪個版本。因此,測試結果應該綜合成一個總結果:一個量化分數。為了給程序員提供如何調整(訓練數據、標簽、參數化)的指導,他們需要知道需要改進的領域。這是我們可以接近缺陷修復的地方。我們需要度量、權衡和契約來實現有意義的總體評分和優化線索。應該分析低分測試用例的原因:是過擬合、欠擬合還是其他風險領域?
4.10. AI測試示例
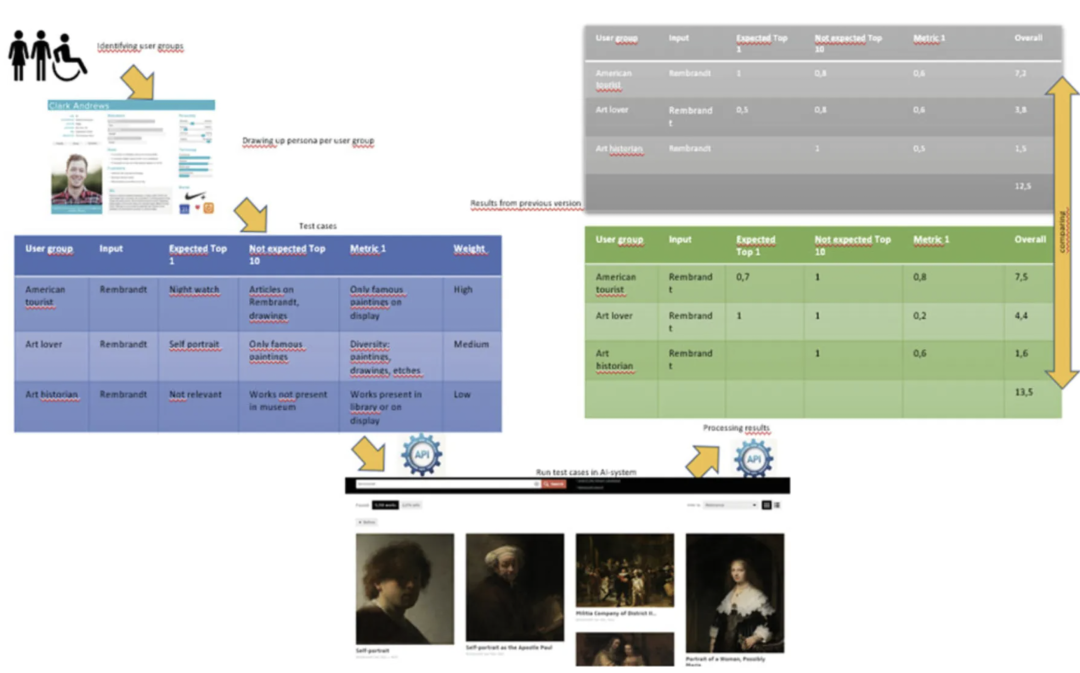
從左上到右下,然后從右上到左下:
1. 識別用戶群體
2. 為每個用戶群體創建角色
3. 寫測試用例:根據每個用戶組輸入的預期頂級結果、非預期結果、度量和權重,在AI系統中運行測試用例
4. 處理結果
5. 根據每個測試用例的總權重創建測試結果
6. 將結果與以前版本的結果進行比較
5. 總結
人工智能的世界非常動態:算法不等同于代碼,而是訓練數據和標簽的結果。隨著世界的變化,訓練數據將不斷更新。人工智能的輸出不是布爾值,而是所有標簽的計算結果,這些結果可能都是相關的。盡管存在低透明度和偏差風險,但人工智能正被用于決策,是人們世界的重要組成部分。測試人員必須通過確定用戶群體及其特定期望和需求,并展示系統如何反映這些期望和需求,在創建透明度方面發揮作用。為此,需要一個自動測試框架來比較人工智能系統的許多版本,不斷監測生產質量,并為優化提供指導。
-
測試
+關注
關注
8文章
5308瀏覽量
126691 -
AI
+關注
關注
87文章
30947瀏覽量
269213
原文標題:淺析AI測試
文章出處:【微信號:TestinChina,微信公眾號:Testin云測】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
MLCommons推出AI基準測試0.5版
智慧交通AI監控視頻分析應用方案






 工商網監
工商網監
評論