 智算中心網絡交換機需要什么樣的緩存架構
智算中心網絡交換機需要什么樣的緩存架構
?在交換機上,緩存就是數據交換的緩沖區,被交換機用來協調不同網絡設備之間的速度匹配問題,突發數據可以存儲在緩沖區內,直到被慢速設備處理為止。數據中心交換機應用在HPC/AI大模型訓練、分布式存儲等場景時,并非緩存越大越好,過大的緩存會導致更長的隊列、更高的時延和抖動、更高的成本,所以不能簡單地去擴大緩存,交換機避免丟包所需的緩存與此帶寬延遲積BDP直接相關,借助于帶寬時延積BDP可以確定合適的內存大小。
緩存架構分類
按照緩沖區的大小,以太網交換機通常分為深緩沖區交換機和淺緩沖區交換機,深緩沖區交換機緩沖區容量高達數GB,與淺緩沖區交換機的幾十MB形成鮮明對比。這種設計上的差異源于應用場景的差異,深緩沖區交換機(或路由器)主要面向路由和廣域網場景,RTT時間長,希望能夠容納更多的數據流量,對微突發流量不敏感,但也意味著更高的尾延遲和抖動,這一點與HPC/AI大模型訓練、分布式存儲等場景的低時延要求顯然是相違背的,淺緩沖區交換機在這種場景下更適合,以目前最高端的51.2Tbps(64個800G)的交換機為例,如果RTT時間是3~5微秒,緩存僅需33MB左右,這是交換機中所需的總緩存,那么這個總的緩存能否被每一個端口充分利用嗎?
這就取決于交換機(交換芯片)所采用緩存架構。交換芯片的緩存架構通常分為:完全共享緩存架構和分片報文緩存架構(也稱分割緩沖區結構)。
完全共享緩存架構:設備中的所有緩存都可用于動態分配到任何端口,意味著在所有輸入-輸出端口之間共享緩存而沒有任何限制,最大限度地提高了可用內存的效率。
分片報文緩存架構:由多片較小的緩存共同組成了芯片內部的緩存,所有的物理接口也被劃分成了不同的組,同一組內的物理接口共享對應的緩存單元。
不同緩存架構影響
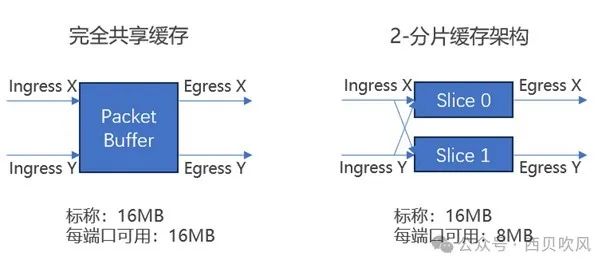
如下圖所示,同樣是16MB的緩存情況下,完全共享緩沖架構中的每個端口極限情況下(如多打一的Incast場景,)可以最大利用到16MB;如果是兩個分片的分組端口緩存架構下,每個端口極限情況下僅可以最大利用到8MB;而如果是四個分片的分組端口緩存架構下,每個端口極限情況下僅可以最大利用到4MB。
思科之前的文檔中也做過分析,分片報文緩存架構下,不同的流量模型對微突發流量吸收的影響或限制也不同,如下圖所示:
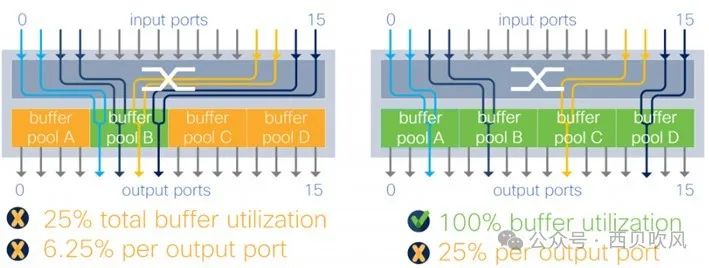
以圖中右側圖示情況為例,4個分片的架構下,如果四個輸出端口位于4個不同的分片上,最理想的情況可以達到100%的緩存利用,但是任意一個輸出端口最多僅可以消耗總內存的25%。在復雜的流量模式下,這種限制可能會更加痛苦,如圖中右側圖示為例,此情況下,一個輸出端口的緩存被限制為總緩沖區的1/16(6.25%),這種限制使得Incast下的緩沖行為不可預測。 在完全共享緩存架構中,設備中的所有數據包緩沖區都可用于動態分配到任意一個端口,這意味著在所有輸入輸出端口之間共享緩存而沒有任何限制,最大限度地提高了可用內存的效率,并且使微突發流量吸收能力可預測,與流量模型沒有任何關系。
完全共享緩存的優勢也體現在RoCEv2網絡中,RoCEv2是TCP/IP協議中UDP層實現,因為使用不需要確認的UDP協議,此時RTT不是緩沖區需求的直接驅動因素,但是RDMA的無損特性往往要依靠PFC來實現,PFC逐級反壓控制會導致擁塞蔓延,完全共享緩存通過在需要的時間和節點支持更多的緩存,有助于最大限度地減少觸發PFC流量控制的需要。
主流廠商實現當前市場上,大多數數據中心交換機都是使用商用交換芯片ASIC構建的,這些ASIC針對傳統的數據流量模式和數據包大小進行了成本優化,為了在實現帶寬目標的同時保持低成本,芯片供應商更多使用了分片緩存架構,犧牲了公平性,同時面臨不可預測性和微突發吸收的問題。
但是,當前幾個主要廠商51.2Tbps最高容量的交換芯片,由于應對場景以HPC/AI大模型訓練等為主,基本都采用完全共享緩存架構,相關的交換芯片或交換機如博通Tomahawk5、英偉達Spectrum-4、思科Silicon One G200都是宣傳采用完全共享緩存架構。
-
網絡交換機
+關注
關注
1文章
67瀏覽量
16040 -
緩存
+關注
關注
1文章
240瀏覽量
26678 -
智算中心
+關注
關注
0文章
68瀏覽量
1712
原文標題:智算中心網絡交換機需要什么樣的緩存架構?
文章出處:【微信號:SDNLAB,微信公眾號:SDNLAB】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
廣西南寧企業級綜合網關、網絡核心交換機等售后維修服務中心點深妙科技

24口全千兆交換機方案設計參考原理圖資料(資料可直接使用)
反射內存交換機與普通交換機的區別

網管型交換機和非網管型交換機的區別
園區交換機 VS 數據中心交換機






 工商網監
工商網監
評論