") 開源與閉源之爭:最新的開源模型到底還落后多少?
開源與閉源之爭:最新的開源模型到底還落后多少?
一,引言
隨著人工智能(AI)技術(shù)的迅猛發(fā)展,大模型已經(jīng)成為推動科技進步的重要力量。然而,超大規(guī)模模型在帶來高性能的同時,也面臨著資源消耗大、部署困難等問題。本文將探討AI大模型未來的發(fā)展方向。
開放性一直是人工智能研究領(lǐng)域的常態(tài),促進了該領(lǐng)域的合作。然而,人工智能的快速發(fā)展引發(fā)了關(guān)于發(fā)布最強大模型可能帶來的后果的擔憂。此外,像ChatGPT這樣的模型的銷售企業(yè)有保持模型私有的商業(yè)動機。
行業(yè)AI實驗室以多種方式回應(yīng)了這些發(fā)展:
未發(fā)布模型:例如,谷歌DeepMind的Chinchilla模型尚未發(fā)布。
結(jié)構(gòu)化訪問控制:像GPT-4這樣的模型有結(jié)構(gòu)化的訪問控制,控制用戶如何與模型交互。
有限制的開源模型:Meta的Llama模型的權(quán)重可以下載,但使用條款有限制。
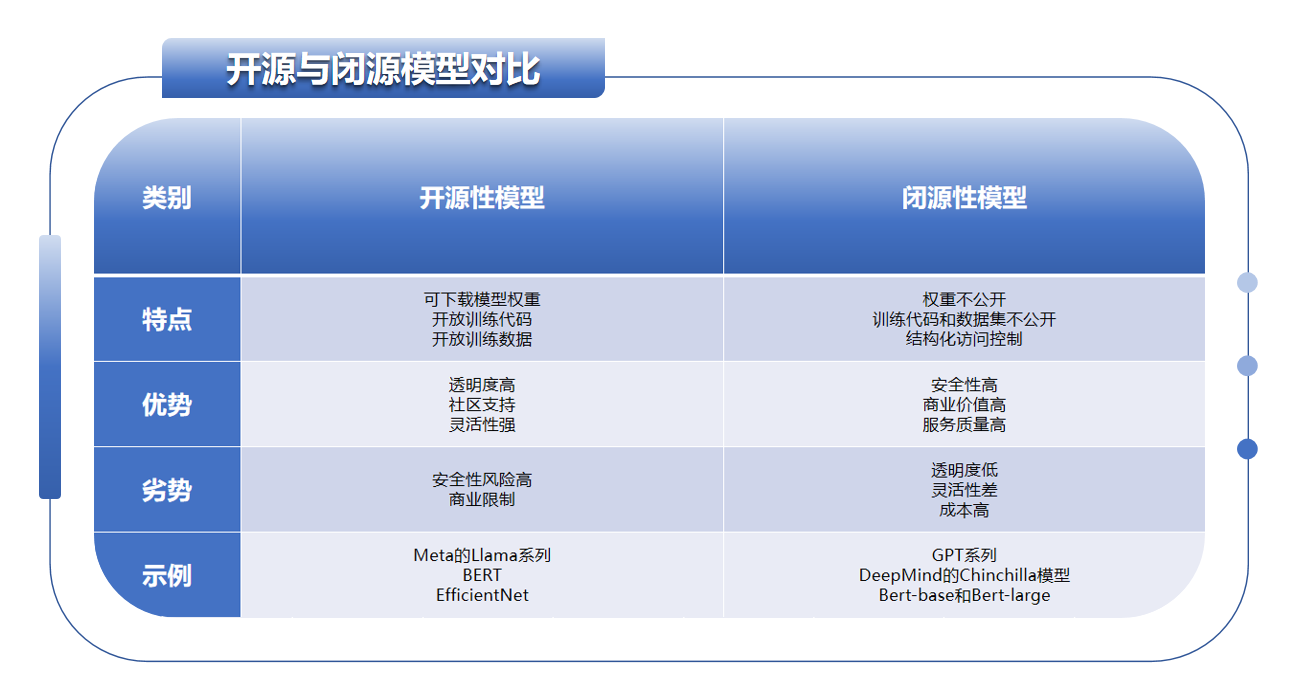
二,開源與閉源模型的對比
1,爭議
發(fā)布模型、代碼和數(shù)據(jù)集能夠促進創(chuàng)新和外部審查,但這也是不可逆的,并且如果模型的安全措施被繞過,就有被濫用的風險。關(guān)于這種權(quán)衡是否可接受或可避免,存在持續(xù)的爭論。開源AI的支持者認為,開放性通過開放社區(qū)開發(fā)的創(chuàng)新和工具,對社會以及模型開發(fā)者都有益。甚至有人認為,更多的閉源AI開發(fā)者已經(jīng)被開源社區(qū)超越,保持封閉變得毫無意義。
2,二者用戶基數(shù)對比
ChatGPT(封閉模型):每月大約有3.5億用戶。
Meta AI助手(開放模型):每月有近5億用戶。
3,性能和訓練計算方面的差距
為了系統(tǒng)地比較開放和封閉AI模型隨時間的能力,我們收集了自2018年以來發(fā)布的數(shù)百個著名AI模型的權(quán)重和訓練代碼的可訪問性數(shù)據(jù)。以下是主要發(fā)現(xiàn):
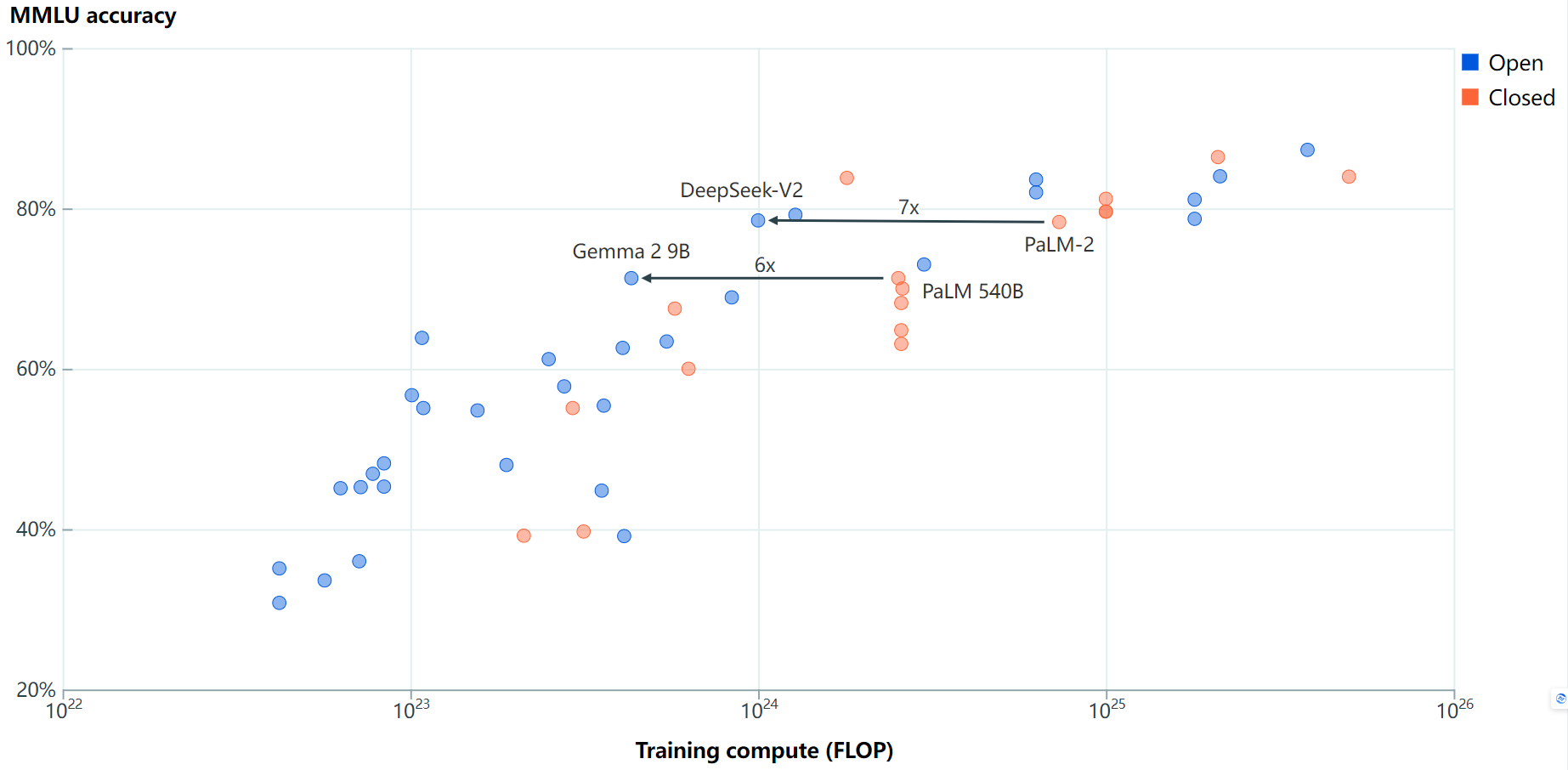
基準性能:
最好的開源大型語言模型(LLMs)在多個基準測試上落后于最好的閉源LLMs5到22個月。Meta的Llama 3.1 405B是最新的一個在多個基準上縮小差距的開源模型。即使不考慮Meta的Llama模型,結(jié)果也類似。
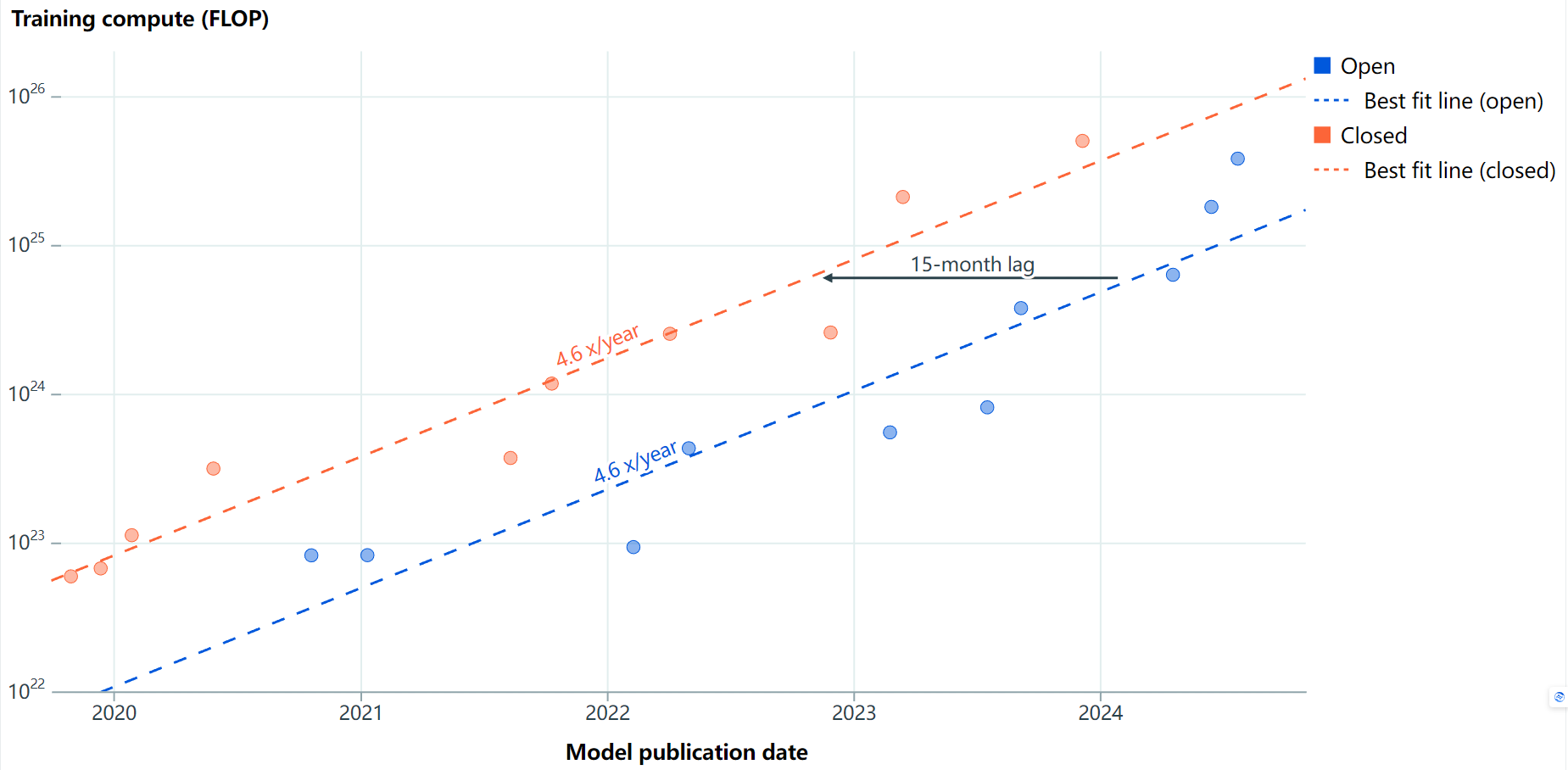
訓練計算:
在訓練計算方面,最大的開源模型落后于最大的閉源模型大約15個月。
Llama 3.1 405B相對于GPT-4的發(fā)布,差距為16個月。由于我們尚未看到比GPT-4規(guī)模更大的閉源模型,Llama 3.1 405B已經(jīng)在縮小訓練計算的差距。
訓練效率:
盡管開源LLMs在達到與閉源LLMs相似的基準性能后,通常使用較少的訓練計算,但新模型通常更高效。因此,我們?nèi)狈ν瑯痈咝У男麻]源模型的數(shù)據(jù)。
訓練數(shù)據(jù)污染和“為排行榜而學習”也可能導致更高的分數(shù)。
三,總結(jié)
開源與閉源AI模型之間的競爭和差距反映了AI領(lǐng)域的多樣性和復(fù)雜性。盡管開源模型在某些方面落后于閉源模型,但它們在促進創(chuàng)新和安全性研究方面具有獨特的優(yōu)勢。未來的發(fā)展將是結(jié)合兩者的優(yōu)點,開發(fā)能力優(yōu)秀、規(guī)模適中、邊緣友好的AI模型,以滿足多樣化的應(yīng)用需求。當然也取決于技術(shù)進步、市場需求和政策監(jiān)管的綜合影響。
這兩種模型你更看好哪一個呢?歡迎評論留言討論。
更多精彩內(nèi)容請關(guān)注“算力魔方?”!
審核編輯 黃宇
-
開源
+關(guān)注
關(guān)注
3文章
3381瀏覽量
42604 -
模型
+關(guān)注
關(guān)注
1文章
3279瀏覽量
48974
發(fā)布評論請先 登錄
相關(guān)推薦
開源大模型在多個業(yè)務(wù)場景的應(yīng)用案例
云知聲山海大模型多項評測名列前茅
開源AI模型庫是干嘛的
Meta AI高管批評OpenAI閉源模式
阿里通義千問代碼模型全系列開源
科技云報到:假開源真噱頭?開源大模型和你想的不一樣!
Llama 3 與開源AI模型的關(guān)系
人民郵電報:“開源”到底是什么?為啥熱度越來越高?

浪潮信息重磅發(fā)布“源2.0-M32”開源大模型
浪潮信息發(fā)布源2.0-M32開源大模型,模算效率大幅提升
浪潮信息發(fā)布“源2.0-M32”開源大模型
智源研究院揭曉大模型測評結(jié)果,豆包與百川智能大模型表現(xiàn)優(yōu)異
HDMI論壇出手,AMD開源HDMI 2.1驅(qū)動被拒
機器人基于開源的多模態(tài)語言視覺大模型






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論