 Google Cloud如何守護大模型安全
Google Cloud如何守護大模型安全
以下文章來源于谷歌云服務,作者 Google Cloud
楊鵬
Google Cloud 安全專家
大模型就像神通廣大的 "哪吒",能寫文章、畫畫、編程,無所不能。但如果哪吒被惡意操控,后果不堪設想!而且,培養這樣的大模型需要大量投入,如果被 "黑化",損失也是巨大的。
這樣看,大模型的安全關系到每個人,Google Cloud 提供了安全工具和服務,能保護大模型不被壞人利用,避免 "黑化"。
想了解更多關于大模型安全和 Google Cloud 的相關知識?請繼續關注我們的系列文章!
大模型安全概要
生成式 AI 發展迅速,但也面臨安全風險。MITRE ATLAS、NIST AI RMF 和 OWASP AI Top 10 等安全標準組織,總結了生成式 AI 的主要安全威脅,主要包括:
●對抗性攻擊:攻擊者擾亂模型輸入或竊取模型信息,導致錯誤輸出或信息泄露。
●數據投毒:攻擊者污染訓練數據,使模型產生偏差或后門。
●模型竊取:攻擊者竊取模型結構和參數,用于復制或攻擊。
●濫用和惡意使用:模型被用于生成虛假信息、垃圾郵件等。
●隱私和安全:模型可能泄露用戶隱私或存在安全漏洞。
●模型篡改:攻擊者修改模型參數、邏輯或數據,改變模型行為。
此外,公眾還關注生成式 AI 的法律合規、治理、偏差、透明度、環境影響等問題。解決這些問題,才能確保生成式 AI 安全、可靠、負責任地發展。
在這當中,模型篡改 (Model Tampering,也可稱為模型投毒-Model Poisoning) 這類的威脅涵蓋了對模型的任何未經授權的修改,包括但不限于對模型訓練或者微調注入后門或降低性能,修改模型參數或代碼導致模型無法正常工作或產生錯誤結果。這類威脅對應的漏洞一般被認為利用難度比較高,因為攻擊者不僅要突破層層基礎安全縱深防御,還需要熟悉大模型訓練和優化,了解如何繞過代碼審計和各類監控且可以有效地影響到模型訓練工作。
但是,近期發生的一些模型投毒事故證明,熟悉流程和相關大模型技術的內部攻擊者可以放大這類風險,甚至可以使得投入數千萬美元的訓練工作毀于一旦。同時,隨著黑產灰產的不斷演進,未來這類威脅帶來的影響可能還會增大,上面說的讓模型 "黑化" 的風險并不是危言聳聽。
理解大模型訓練的安全風險
下圖是在 Google Cloud 上進行生成式 AI 訓練,部署和推理的典型架構。圖中畫紅框的部分是大模型訓練的范疇。
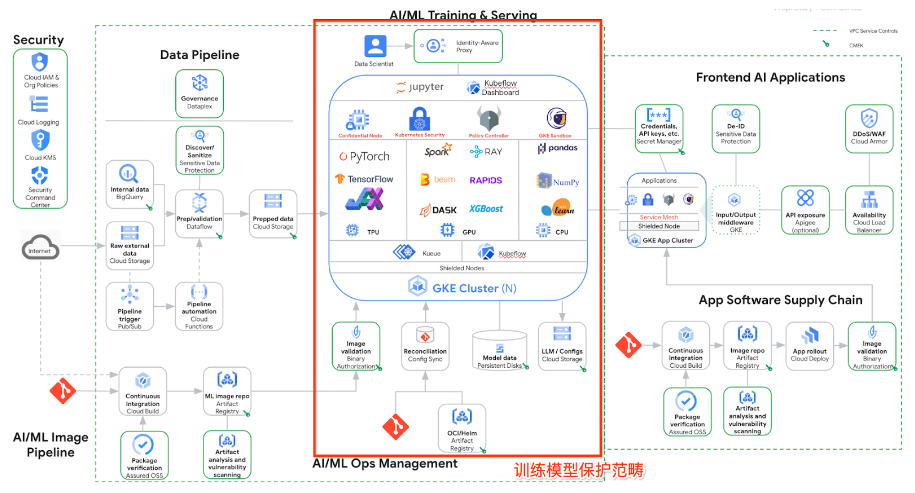
首先讓我們從基礎設施、工具鏈、供應鏈、模型代碼和配置等方面,拆解一下模型篡改可能面臨的風險類別:
基礎設施
● 未經授權的訪問:攻擊者可能入侵模型訓練或部署的服務器、云平臺等基礎設施,直接篡改模型文件或運行環境。這包括利用系統漏洞、弱口令、社會工程學等手段獲取訪問權限。
●惡意代碼注入:攻擊者可能在基礎設施中植入惡意代碼,例如后門程序、rootkit 等,用于監控模型行為、竊取數據或篡改模型輸出。
●拒絕服務攻擊:攻擊者可能對基礎設施發起 DDoS 攻擊,導致模型無法正常提供服務,影響用戶體驗和業務運營。
模型訓練工具鏈
●投毒的訓練框架:攻擊者可能篡改模型訓練所使用的框架或庫,例如 TensorFlow、PyTorch 等,注入惡意代碼或后門,影響模型訓練過程和結果。
●惡意的模型評估工具:攻擊者可能篡改模型評估工具,例如指標計算腳本、可視化工具等,導致模型評估結果失真,掩蓋模型存在的安全問題。
●不安全的模型部署工具:攻擊者可能利用模型部署工具中的漏洞,例如未經身份驗證的 API 接口、不安全的配置文件等,篡改模型參數或邏輯。
模型供應鏈
● 預訓練模型的風險:使用來自不可信來源的預訓練模型,可能存在被篡改的風險,例如模型中可能被植入后門或惡意代碼。
●第三方數據的風險:使用來自不可信來源的第三方數據進行模型訓練,可能存在數據投毒的風險,導致模型學習到錯誤的模式或產生偏差。
●依賴庫的風險:模型訓練和部署過程中使用的各種依賴庫,可能存在安全漏洞,攻擊者可能利用這些漏洞篡改模型或竊取數據。
模型代碼和配置
● 代碼注入:攻擊者可能直接修改模型代碼,注入惡意代碼或后門,改變模型的行為。
●配置錯誤:錯誤的模型配置可能導致安全漏洞,例如過低的訪問權限、未加密的敏感信息等,攻擊者可能利用這些漏洞篡改模型。
●版本控制問題:缺乏有效的版本控制機制,可能導致模型被意外修改或回滾到存在安全問題的版本。
發揮云原生的力量一起應對風險
經過多年的積累,Google 既是一個 AI 專家,又是一個安全專家,在應對類似的風險方面有豐富的經驗。在 Google Cloud 平臺上,有多種云原生的手段來幫助大家應對上面提到的大模型投毒的威脅。
要保護模型安全,需要多管齊下:加強基礎設施安全,例如做好訪問控制和入侵檢測;使用可信的工具鏈,并對預訓練模型、數據和依賴庫進行安全審查;同時,還要保護好模型代碼和配置,并進行持續的監控和檢測。
Ray on Vertex AI 提供了一個強大的平臺,可以幫助您更好地進行 LLMOps,在提高模型訓練的效率和有效性的同時,保護模型代碼和配置:
安全的環境
Vertex AI 提供了安全可靠的運行環境,并與 Google Cloud 的安全工具集成,例如 IAM 和 VPC Service Controls,可以有效地控制訪問權限和保護敏感數據。
可復現的流程
Ray 和 Vertex AI 的結合可以幫助您構建可復現的模型訓練和部署流程,通過版本控制和跟蹤實驗參數,確保模型代碼和配置的一致性。
持續監控和集成
您可以利用 Vertex AI 的監控工具和 Ray 的可擴展性,對模型進行持續監控和性能分析,及時發現異常情況并進行調整。
通過 Ray on Vertex AI,結合 Google Cloud 的權限管理、網絡隔離、威脅監控等手段,可以將模型代碼和配置納入到一個安全、可控、可復現的環境中,從而更好地保護模型的安全性和完整性。
Jupyter Notebook、Kubeflow 和 Ray 之類的大模型訓練工具也是需要保護的重點。需要從漏洞評估、用戶訪問控制、加密和網絡隔離等多個方面入手,確保訓練開發和測試工具的安全可靠。
漏洞評估
●使用 Artifact Analysis 掃描鏡像中的漏洞,并使用 Binary Authorization 根據掃描結果限制部署。
●對于運行中的工作負載,考慮使用 Advanced Vulnerability Insights 進行更深入的漏洞分析。
用戶訪問控制
● 通過 Cloud Load Balancer 和 Identity-Aware Proxy 對 Cloud Console 環境訪問進行代理、Kubeflow Central Dashboard 和 Ray dashboard UI 進行用戶身份驗證和授權。
加密
●使用 CMEK 對啟動磁盤和永久磁盤進行靜態加密。
●使用 HTTPS Load Balancing 對前端通信進行傳輸加密。
●可選: 支持 Ray TLS,但會影響性能。
網絡隔離
●根據 Jupyter Notebook、Kubeflow 和 Ray 的要求配置網絡策略和 Cloud Firewall 規則。
●Kubeflow 集成了 Istio 來控制集群內流量和用戶交互,還可以使用 Cloud Service Mesh 補充 AI/ML 運營環境的網絡安全。
Vertex AI Colab Enterprise 將 Colab 的易用性與 Google Cloud 的安全性和強大功能相結合,為數據科學家提供了一個理想的平臺,在安全、可擴展的環境中運行 Jupyter Notebook,同時輕松訪問 Google Cloud 的各種資源。
保障大模型訓練安全,需審查預訓練模型、第三方數據和依賴庫。選擇 Google Cloud 提供的預訓練模型,并使用 Artifact Analysis 等工具進行漏洞掃描和依賴分析,確保模型來源可靠且安全。
在管理依賴庫的安全風險方面,Google Cloud Assured OSS 可以發揮重要作用。它提供了一系列經過 Google 安全審查和維護的開源軟件包,例如 TensorFlow、Pandas 和 Scikit-learn 等常用的大模型訓練庫。
●可信來源:Assured OSS 的軟件包來自 Google 管理的安全可靠的 Artifact Registry,確保來源可信。
●漏洞修復:Google 會積極掃描和修復 Assured OSS 軟件包中的漏洞,并及時提供安全更新。
●軟件物料清單 (SBOM):Assured OSS 提供了標準格式的 SBOM,幫助您了解軟件包的組成成分和依賴關系,方便進行安全評估。
目前,業內大模型訓練使用最多的基礎設施平臺是 Kubernetes。Google Cloud 托管的 Kubernetes 平臺 GKE,提供高度安全、可擴展且易于管理的 Kubernetes 環境,讓開發者專注于模型開發和部署,無需擔心底層基礎設施的運維。下面是一些面向大模型訓練風險的 GKE 安全加固建議。
基礎的云原生安全加固和管控在 Google Cloud 上可以非常方便地使用,可以利用其提供的 Identity and Access Management (IAM) 服務精細化地控制對模型和數據的訪問權限,并使用 Security Command Center 進行入侵檢測和安全監控,及時發現并應對潛在威脅。此外,Google Cloud 還提供了一系列安全加固工具和服務,例如虛擬機安全、網絡安全、數據加密等,幫助您構建更加安全的生成式 AI 基礎設施。
生成式 AI 的安全及合規治理
不容忽視
生成式 AI 技術日新月異,其安全風險也隨之不斷演變。長期的生成式 AI 安全治理能夠幫助我們持續應對新的威脅,確保 AI 系統始終安全可靠,并適應不斷變化的法律法規和社會倫理要求,最終促進生成式 AI 技術的健康發展和應用。Google Cloud SAIF (Security AI Framework) 是一個旨在保障 AI 系統安全的概念框架。它借鑒了軟件開發中的安全最佳實踐,并結合了 Google 對 AI 系統 specific 的安全趨勢和風險的理解。
SAIF 的主要內容可以概括為以下四個方面:
安全開發 (Secure Development)
威脅建模:在 AI 系統的開發初期就進行威脅建模,識別潛在的安全風險。
安全編碼:采用安全的編碼實踐,防止代碼漏洞和安全缺陷。
供應鏈安全:確保 AI 系統的供應鏈安全,例如使用可信的第三方庫和數據。
安全部署 (Secure Deployment)
訪問控制:對 AI 系統進行訪問控制,防止未經授權的訪問和修改。
安全配置:對 AI 系統進行安全配置,例如配置防火墻規則和加密通信。
漏洞掃描:對 AI 系統進行漏洞掃描,及時發現和修復安全漏洞。
安全執行 (Secure Execution)
輸入驗證:對 AI 系統的輸入進行驗證,防止惡意輸入和攻擊。
異常檢測:對 AI 系統的運行狀態進行監控,及時發現異常行為。
模型保護:保護 AI 模型不被竊取或篡改。
安全監控 (Secure Monitoring)
日志記錄:記錄 AI 系統的運行日志,方便安全審計和事件調查。
安全評估:定期對 AI 系統進行安全評估,識別新的安全風險。
事件響應:建立事件響應機制,及時應對安全事件。
SAIF 的目標是幫助組織將安全措施融入到 AI 系統的整個生命周期中,確保 AI 系統的安全性和可靠性。它強調了以下幾個關鍵原則:
●默認安全:AI 系統應該默認安全,而不是事后補救。
●縱深防御:采用多層次的安全措施,防止單點故障。
●持續監控:持續監控 AI 系統的運行狀態,及時發現和應對安全威脅。
●持續改進:不斷改進 AI 系統的安全措施,以適應不斷變化的威脅環境。
行動從今天開始
我們深入探討了大模型安全的重要性、面臨的風險以及 Google Cloud 提供的安全工具和服務,涵蓋了基礎設施安全、模型安全、數據安全和供應鏈安全等方面。未來,就像我們一起努力保護 "小哪吒" 一樣,Google Cloud 會和大家一起,利用強大的安全工具和豐富的經驗,把大模型訓練的每個環節都保護好,讓 AI 技術安全可靠地為我們服務!
-
Google
+關注
關注
5文章
1765瀏覽量
57530 -
AI
+關注
關注
87文章
30894瀏覽量
269085 -
大模型
+關注
關注
2文章
2450瀏覽量
2706
原文標題:"與 Google Cloud 一起捍衛大模型安全" 之 "保護你的大模型訓練"
文章出處:【微信號:Google_Developers,微信公眾號:谷歌開發者】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Google Cloud發布兩款針對企業客戶的全新解決方案
OPPO與Google Cloud攜手開創AI手機新未來
電梯黑匣子:守護安全的智慧守護者
Google Cloud AI助力衛安智能推出機器人解決方案
NetApp與Google Cloud深化合作,強化分布式云存儲
梯云物聯 電梯應急救援終端:守護安全的智慧守護者!
Google Gemma 2模型的部署和Fine-Tune演示
Meta Llama 3.1系列模型可在Google Cloud上使用
螞蟻集團發布隱語Cloud大模型密算平臺
驍銳單邊安全光柵,守護安全新勢力






 工商網監
工商網監
評論