 使用vLLM+OpenVINO加速大語言模型推理
使用vLLM+OpenVINO加速大語言模型推理
作者:
武卓 博士 英特爾 OpenVINO 布道師
隨著大語言模型的廣泛應用,模型的計算需求大幅提升,帶來推理時延高、資源消耗大等挑戰。vLLM 作為高效的大模型推理框架,通過 OpenVINO 的優化,vLLM 用戶不僅能夠更高效地部署大模型,還能提升吞吐量和處理能力,從而在成本、性能和易用性上獲得最佳平衡。這種優化對于需要快速響應和節省資源的云端或邊緣推理應用尤為重要。目前,OpenVINO 最新版本 OpenVINO 2024.4 中已經支持與 vLLM 框架的集成,只需要一步安裝,一步配置,就能夠以零代碼修改的方式,將 OpenVINO 作為推理后端,在運行 vLLM 對大語言模型的推理時獲得推理加速。
01vLLM 簡介
vLLM 是由加州大學伯克利分校開發的開源框架,專門用于高效實現大語言模型(LLMs)的推理和部署。它具有以下優勢:
高性能:相比 HuggingFace Transformers 庫,vLLM 能提升多達24倍的吞吐量。
易于使用:無需對模型架構進行任何修改即可實現高性能推理。
低成本:vLLM 的出現使得大模型的部署更加經濟實惠。
02一步安裝:搭建 vLLM+OpenVINO 阿里云ECS開發環境
下面我們以在阿里云的免費云服務器 ECS 上運行通義千問 Qwen2.5 模型為例,詳細介紹如何通過簡單的兩步,輕松實現 OpenVINO 對 vLLM 大語言模型推理服務的加速。
在阿里云上申請免費的云服務器 ECS 資源,并選擇 Ubuntu22.04 作為操作系統。
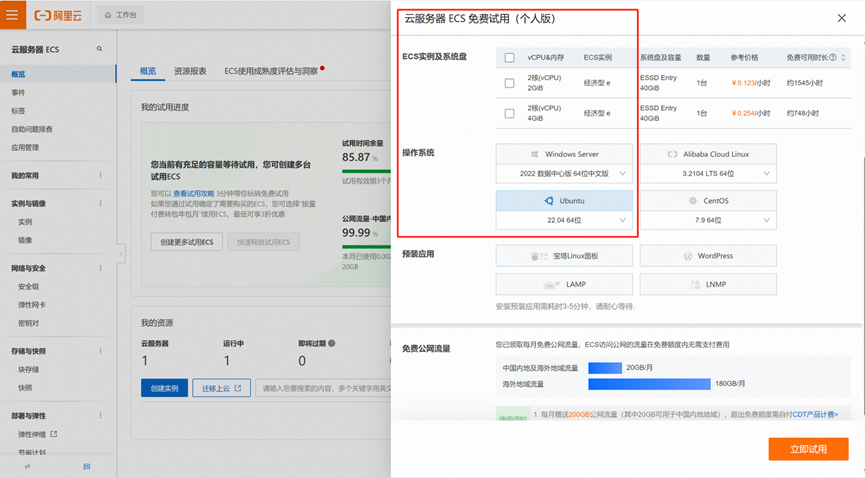
接著進行遠程連接后,登錄到終端操作界面。
請按照以下步驟配置開發環境:
1. 更新系統并安裝 Python 3 及虛擬環境:
sudo apt-get update -y sudo apt-get install python3 python3.10-venv -y
2. 建立并激活 Python 虛擬環境:
python3 -m venv vllm_env source vllm_env/bin/activate
3. 克隆 vLLM 代碼倉庫并安裝依賴項:
git clone https://github.com/vllm-project/vllm.git cd vllm pip install --upgrade pippip install -r requirements-build.txt --extra-index-url https://download.pytorch.org/whl/cpu
4. 安裝 vLLM 的 OpenVINO 后端:
PIP_EXTRA_INDEX_URL="https://download.pytorch.org/whl/cpu" VLLM_TARGET_DEVICE=openvino python -m pip install -v .
至此,環境搭建完畢。
03魔搭社區大語言模型下載
接下來,去魔搭社區下載最新的通義千問2.5系列大語言模型,這里以 Qwen2.5-0.5B-Instruct 模型的下載為例。
模型下載地址為:
https://www.modelscope.cn/models/Qwen/Qwen2.5-0.5B-Instruct
魔搭社區為開發者提供了多種模型下載的方式,這里我們以“命令行下載“方式為例。
首先用以下命令安裝 modelscope:
pip install modelscope
接著運行以下命令完成模型下載:
modelscope download --model Qwen/Qwen2.5-0.5B-Instruct
下載后的模型,默認存放在以下路徑中:
/root/.cache/modelscope/hub/Qwen/Qwen2___5-0___5B-Instruct
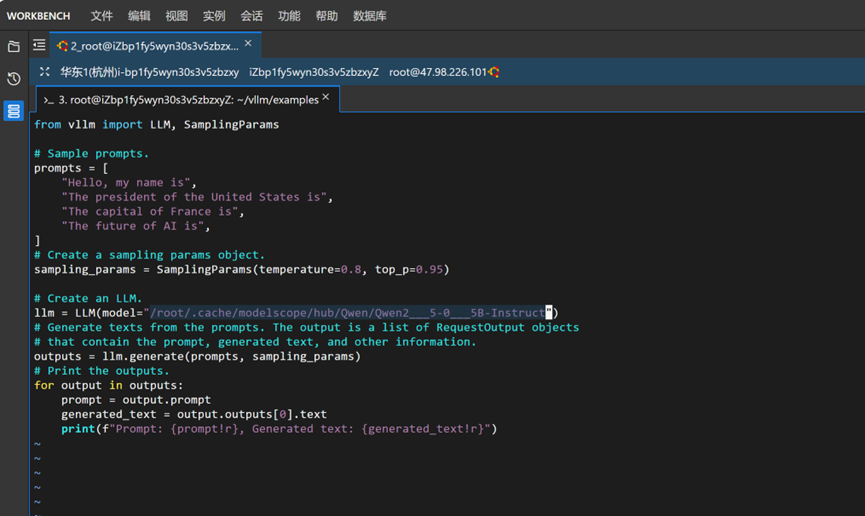
本次運行的推理腳本,我們以 vllm 倉庫中 examples 文件夾中的 offline_inference.py 推理腳本為例。由于 vLLM 默認的腳本是從 Hugging Face 平臺上直接下載模型,而由于網絡連接限制無法從該平臺直接下載模型,因此我們采用上面的方式將模型從魔搭社區中下載下來,接下來使用以下命令,修改腳本中第14行,將原腳本中的模型名稱“"facebook/opt-125m"”替換為下載后存放Qwen2.5模型的文件夾路徑”
/root/.cache/modelscope/hub/Qwen/Qwen2___5-0___5B-Instruct“即可,效果如下圖所示。
04一步配置:配置并運行推理腳本
接下來,在運行推理腳本,完成 LLMs 推理之前,我們再針對 OpenVINO 作為推理后端,進行一些優化的配置。使用如下命令進行配置:
export VLLM_OPENVINO_KVCACHE_SPACE=1 export VLLM_OPENVINO_CPU_KV_CACHE_PRECISION=u8 export VLLM_OPENVINO_ENABLE_QUANTIZED_WEIGHTS=ON
VLLM_OPENVINO_KVCACHE_SPACE:用于指定鍵值緩存(KV Cache)的大小(例如,VLLM_OPENVINO_KVCACHE_SPACE=100 表示為 KV 緩存分配 100 GB 空間)。較大的設置可以讓 vLLM 支持更多并發請求。由于本文運行在阿里云的免費 ECS 上空間有限,因此本次示例中我們將該值設置為1。實際使用中,該參數應根據用戶的硬件配置和內存管理方式進行設置。
VLLM_OPENVINO_CPU_KV_CACHE_PRECISION=u8:用于控制 KV 緩存的精度。默認情況下,會根據平臺選擇使用 FP16 或 BF16 精度。
VLLM_OPENVINO_ENABLE_QUANTIZED_WEIGHTS:用于啟用模型加載階段的 U8 權重壓縮。默認情況下,權重壓縮是關閉的。通過設置 VLLM_OPENVINO_ENABLE_QUANTIZED_WEIGHTS=ON 來開啟權重壓縮。
為了優化 TPOT(Token Processing Over Time)和 TTFT(Time To First Token)性能,可以使用 vLLM 的分塊預填充功能(--enable-chunked-prefill)。根據實驗結果,推薦的批處理大小為 256(--max-num-batched-tokens=256)。
最后,讓我們來看看 vLLM 使用 OpenVINO 后端運行大語言模型推理的效果,運行命令如下:
python offline_inference.py
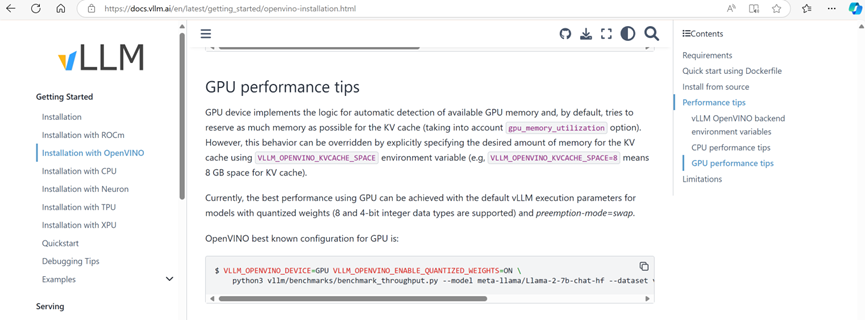
除了運行以上配置,可以利用 OpenVINO 在 CPU 上輕松實現 vLLM 對大語言模型推理加速外,也可以利用如下配置在英特爾集成顯卡和獨立顯卡等 GPU 設備上獲取 vLLM 對大語言模型推理加速。
export VLLM_OPENVINO_DEVICE=GPU export VLLM_OPENVINO_ENABLE_QUANTIZED_WEIGHTS=ON
05結論
通過在 vLLM 中集成 OpenVINO 優化,用戶能夠顯著提升大語言模型的推理效率,減少延遲并提高資源利用率。簡單的配置步驟即可實現推理加速,使得在阿里云等平臺上大規模并發請求的處理變得更加高效和經濟。OpenVINO 的優化讓用戶在保持高性能的同時降低部署成本,為 AI 模型的實時應用和擴展提供了強有力的支持。
-
英特爾
+關注
關注
61文章
9964瀏覽量
171765 -
大模型
+關注
關注
2文章
2448瀏覽量
2702 -
OpenVINO
+關注
關注
0文章
93瀏覽量
201
原文標題:開發者實戰|一步安裝,一步配置:用 vLLM + OpenVINO? 輕松加速大語言模型推理
文章出處:【微信號:英特爾物聯網,微信公眾號:英特爾物聯網】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
壓縮模型會加速推理嗎?
在AI愛克斯開發板上用OpenVINO?加速YOLOv8目標檢測模型

自訓練Pytorch模型使用OpenVINO?優化并部署在AI愛克斯開發板

AI愛克斯開發板上使用OpenVINO加速YOLOv8目標檢測模型

如何將Pytorch自訓練模型變成OpenVINO IR模型形式

用OpenVINO? C++ API編寫YOLOv8-Seg實例分割模型推理程序
在AI愛克斯開發板上用OpenVINO?加速YOLOv8-seg實例分割模型
主流大模型推理框架盤點解析
基于OpenVINO Python API部署RT-DETR模型
使用OpenVINO C++在哪吒開發板上推理Transformer模型

FPGA和ASIC在大模型推理加速中的應用

vLLM項目加入PyTorch生態系統,引領LLM推理新紀元






 工商網監
工商網監
評論