 spark和hadoop的區別
spark和hadoop的區別
SPARK
Apache Spark 是專為大規模數據處理而設計的快速通用的計算引擎。Spark是UC Berkeley AMP lab (加州大學伯克利分校的AMP實驗室)所開源的類Hadoop MapReduce的通用并行框架,Spark,擁有Hadoop MapReduce所具有的優點;但不同于MapReduce的是——Job中間輸出結果可以保存在內存中,從而不再需要讀寫HDFS,因此Spark能更好地適用于數據挖掘與機器學習等需要迭代的MapReduce的算法。
Spark 是一種與 Hadoop 相似的開源集群計算環境,但是兩者之間還存在一些不同之處,這些有用的不同之處使 Spark 在某些工作負載方面表現得更加優越,換句話說,Spark 啟用了內存分布數據集,除了能夠提供交互式查詢外,它還可以優化迭代工作負載。
Spark 是在 Scala 語言中實現的,它將 Scala 用作其應用程序框架。與 Hadoop 不同,Spark 和 Scala 能夠緊密集成,其中的 Scala 可以像操作本地集合對象一樣輕松地操作分布式數據集。
盡管創建 Spark 是為了支持分布式數據集上的迭代作業,但是實際上它是對 Hadoop 的補充,可以在 Hadoop 文件系統中并行運行。通過名為 Mesos 的第三方集群框架可以支持此行為。Spark 由加州大學伯克利分校 AMP 實驗室 (Algorithms, Machines, and People Lab) 開發,可用來構建大型的、低延遲的數據分析應用程序。
Hadoop
Hadoop是一個由Apache基金會所開發的分布式系統基礎架構。
用戶可以在不了解分布式底層細節的情況下,開發分布式程序。充分利用集群的威力進行高速運算和存儲。
Hadoop實現了一個分布式文件系統(Hadoop Distributed File System),簡稱HDFS。HDFS有高容錯性的特點,并且設計用來部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)來訪問應用程序的數據,適合那些有著超大數據集(large data set)的應用程序。HDFS放寬了(relax)POSIX的要求,可以以流的形式訪問(streaming access)文件系統中的數據。
Hadoop的框架最核心的設計就是:HDFS和MapReduce。HDFS為海量的數據提供了存儲,則MapReduce為海量的數據提供了計算。
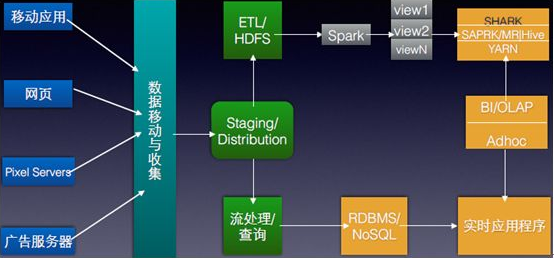
spark和hadoop的區別
解決問題的層面不一樣
首先,Hadoop和Apache Spark兩者都是大數據框架,但是各自存在的目的不盡相同。Hadoop實質上更多是一個分布式數據基礎設施: 它將巨大的數據集分派到一個由普通計算機組成的集群中的多個節點進行存儲,意味著您不需要購買和維護昂貴的服務器硬件。
同時,Hadoop還會索引和跟蹤這些數據,讓大數據處理和分析效率達到前所未有的高度。Spark,則是那么一個專門用來對那些分布式存儲的大數據進行處理的工具,它并不會進行分布式數據的存儲。
兩者可合可分
Hadoop除了提供為大家所共識的HDFS分布式數據存儲功能之外,還提供了叫做MapReduce的數據處理功能。所以這里我們完全可以拋開Spark,使用Hadoop自身的MapReduce來完成數據的處理。
相反,Spark也不是非要依附在Hadoop身上才能生存。但如上所述,畢竟它沒有提供文件管理系統,所以,它必須和其他的分布式文件系統進行集成才能運作。這里我們可以選擇Hadoop的HDFS,也可以選擇其他的基于云的數據系統平臺。但Spark默認來說還是被用在Hadoop上面的,畢竟,大家都認為它們的結合是最好的。
以下是從網上摘錄的對MapReduce的最簡潔明了的解析:
我們要數圖書館中的所有書。你數1號書架,我數2號書架。這就是“Map”。我們人越多,數書就更快。
現在我們到一起,把所有人的統計數加在一起。這就是“Reduce”。
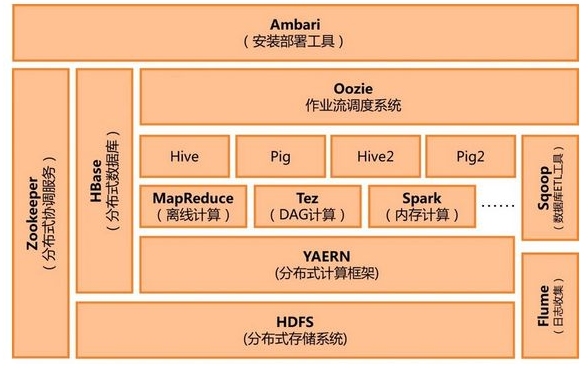
Spark數據處理速度秒殺MapReduce
Spark因為其處理數據的方式不一樣,會比MapReduce快上很多。MapReduce是分步對數據進行處理的: ”從集群中讀取數據,進行一次處理,將結果寫到集群,從集群中讀取更新后的數據,進行下一次的處理,將結果寫到集群,等等…“ Booz Allen Hamilton的數據科學家Kirk Borne如此解析。
反觀Spark,它會在內存中以接近“實時”的時間完成所有的數據分析:“從集群中讀取數據,完成所有必須的分析處理,將結果寫回集群,完成,” Born說道。Spark的批處理速度比MapReduce快近10倍,內存中的數據分析速度則快近100倍。
如果需要處理的數據和結果需求大部分情況下是靜態的,且你也有耐心等待批處理的完成的話,MapReduce的處理方式也是完全可以接受的。
但如果你需要對流數據進行分析,比如那些來自于工廠的傳感器收集回來的數據,又或者說你的應用是需要多重數據處理的,那么你也許更應該使用Spark進行處理。
大部分機器學習算法都是需要多重數據處理的。此外,通常會用到Spark的應用場景有以下方面:實時的市場活動,在線產品推薦,網絡安全分析,機器日記監控等。
災難恢復
兩者的災難恢復方式迥異,但是都很不錯。因為Hadoop將每次處理后的數據都寫入到磁盤上,所以其天生就能很有彈性的對系統錯誤進行處理。
Spark的數據對象存儲在分布于數據集群中的叫做彈性分布式數據集(RDD: Resilient Distributed Dataset)中。“這些數據對象既可以放在內存,也可以放在磁盤,所以RDD同樣也可以提供完成的災難恢復功能,”Borne指出。
-
數據分析
+關注
關注
2文章
1449瀏覽量
34060 -
Hadoop
+關注
關注
1文章
90瀏覽量
15985 -
SPARK
+關注
關注
1文章
105瀏覽量
19910
發布評論請先 登錄
相關推薦
大數據分析中Spark,Hadoop,Hive框架該用哪種開源分布式系統
如何將Hadoop部署在低廉的硬件上
山西嵌入式系統課程| Spark與Hadoop計算模型之Spark比Hadoop更...
Hadoop的整體框架組成
Spark入門及安裝與配置
hadoop發行版本之間的區別
hadoop框架結構的說明介紹
hadoop和spark的區別
大數據hadoop入門之hadoop家族產品詳解
如何使用Apache Spark 2.0
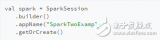
什么是Hadoop? Spark和Hadoop對比
快速學習Spark和Hadoop的架構的方法
未來大數據時代,Hadoop會被Spark取代?





 工商網監
工商網監
評論