 超帶寬域成為業內技術探索新領域
超帶寬域成為業內技術探索新領域
AI大模型的迅猛發展,使得網絡基礎設施技術的進步速度超乎想象。產業鏈上的每一個環節都需緊密追蹤AI驅動的技術革新,并據此進行同步的創新升級。
AI網絡的Scale-up正在上演一場熱烈的軍備賽,業界正在呼喚更統一開放的GPU計算卡互聯標準,從而打破NVIDIA主導的NVLink以及其所構建的強大的HBD 網絡架構的護城河。NVLink 是一種“多節點無損網絡”的代表,由一個強大的軟件協議組成,通常通過印在計算機板上的多對導線實現,可以讓處理器以極高的速度收發共享內存池中的數據。NVLink 的主要設計目的,就是突破PCIe的屏障,達成GPU-GPU及CPU-GPU的片間高效數據交互。
(來源: NVIDIA)
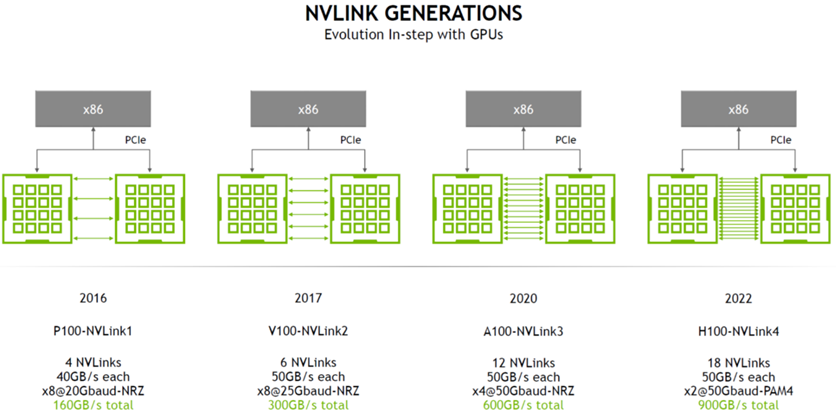
目前NVLink已經升級到5.0版本。第五代 NVLink 大幅提高了大型多 GPU 系統的可擴展性。單個 NVIDIA Blackwell Tensor Core GPU 支持多達 18 個 NVLink 100 GB/s 連接,總帶寬可達 1.8 TB/s,比上一代產品提高了兩倍,是 PCIe 5.0 帶寬的 14 倍之多。
如今討論Scale-up網絡已經不僅提及NVIDIA的NVLink,無論是國際還是國內,行業更多的是在找尋一種更加緊密連接的集群組網,這種緊密耦合所形成的計算系統將有助于推動以GPU為核心的AI網絡獲得極高的帶寬與極低的延遲。
01超帶寬域(HBD)成為
業內技術探索新領域
大模型時代,需要更大的模型并行規模,模型并行中Tensor并行或MOE類型的Expert并行都會在GPU之間產生大量的通信,當前典型一機8卡服務器限制了Tensor并行的規模或Expert并行通過機間網絡。由此業界開始探索一種以超帶寬(HB)互聯GPU-GPU的系統,又稱HBD(High Bandwidth Domain)。通過構建更大的HBD系統,以Scale-up方式提升系統算力是解決萬卡到十萬卡集群以上互聯挑戰的有效途徑之一。
于是NVIDIA的暴力美學再度彰顯,以其強大的計算能力繼續發揮著引領HBD技術趨勢的威力。NVIDIA將HB互聯擴展至GPU片間通信之外的領域,將其應用到GPU-CPU/Memory之間的超大帶寬互聯,例如GH200、GB200產品。借助NVLink-C2C技術的創新,為GPU提供一個超帶寬訪問CPU/Memory的能力。
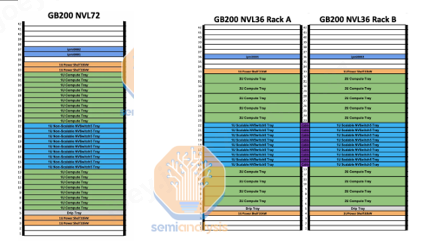
NVIDIA的GB200NVL72服務器產品體現了典型的超大HBD域系統,實現了36組GB200(36個Grace CPU,72個B200 GPU)之間的超高帶寬互聯。一個NVL72機架服務器內部共有18個Compute Tray和9個Switch Tray。
(來源:Semianalysis)
上圖右側是另外一種NVIDIA的Scale-up HBD 組網形態:GB200 NVL36 * 2,它把兩個并排的機架互聯在一起。大多數 GB200 機架都將使用此外形規格。每個機架包含 18 個 Grace CPU 和 36 個 Blackwell GPU。在 2 個機架之間,它仍然在 NVL72 中的所有 72 個 GPU 之間保持非阻塞全對全。每個Compute Tray(高度為2U )包含 2 個 Bianca 板。每個 NVSwitch Tray都有兩個 28.8Tb/s NVSwitch5 ASIC 芯片。
(來源:Semianalysis)
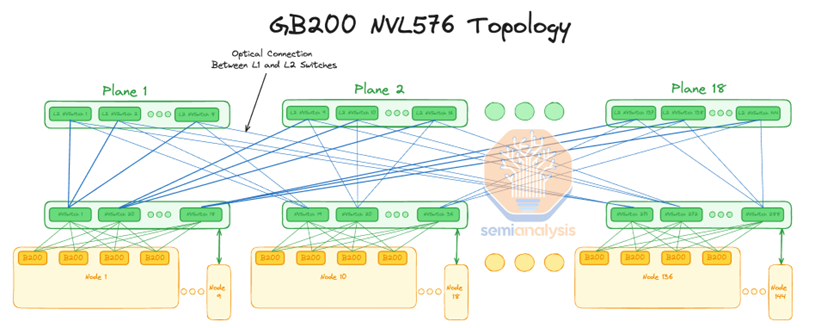
更夸張的是,黃仁勛表示GB200 NVLink 可以同時連接到 576 個 Blackwell GPU。據Semianalysis調研,該網絡系統使用具有 18 個平面的 2 層胖樹拓撲來完成。這意味著NVIDIA計劃讓 DGX H100 NVL256 連接 16 個 NVL36 機架。NVL576形成一個超級大的GPU HBD域,則包含288個GB200 GPU,576個B200 GPU。
據悉,該系統形態的互聯已經超過銅纜能夠實現的物理連接距離,必須使用光纖連接,這意味著需要花費相當昂貴的成本來實現極高的加速卡帶寬。
事實上,超帶寬域的穩定運行并非易事,其復雜性不僅體現在網絡和計算層面,還包括服務器機架的能耗管理、液冷散熱技術、以及機架間光模塊與光纜的通信效率等眾多挑戰。這些問題的解決非一家企業能夠獨立完成,它需要數據中心產業鏈的上下游運用集體的智慧來共同突破,以實現高達十萬個以上的加速卡的互聯。
02產業鏈集體對抗
英偉達的暴力美學
上個月底, AMD、AWS、Astera Labs、思科、谷歌、惠普企業 (HPE)、英特爾、Meta 和微軟等九大董事會成員聯合宣布,由其主導的UALink 聯盟宣布正式成立,目前已經對行業開放成員邀請。
Ultra Accelerator Link(UALink) 是一種用于GPU加速卡間通信的開放行業標準化互聯。UALink 聯盟是一個開放的行業標準組織,旨在制定Scale-up互聯技術規范,以促進 AI 加速卡(即 GPU)之間的高效互聯。該技術規范定義了一種創新的I/O架構,單通道可達200 Gbps傳輸速率,支持最多1024個AI加速卡互連。相比傳統以太網(Ethernet)架構,UALink在性能和GPU互聯規模上都具有優勢,互聯規模更是大幅超越NVIDIA NVLink技術。
UALink 1.0 規范可以利用開發和部署了各種加速卡和交換機的推廣者成員的經驗。
UALink 聯盟總裁 Willie Nelson 表示:“UALink 標準定義了數據中心內擴展 AI 系統的高速、低延遲通信。我們鼓勵有興趣的公司以貢獻者成員的身份加入,以支持我們的使命:為 AI 工作負載建立開放且高性能的加速卡互聯。”預計UALink 1.0規范將在2025年第一季度發布,這與UEC超以太聯盟1.0規范的發布節奏同步。
國內:AI網絡生態聯盟百花齊放
國內AI網絡生態圈高度關注Scale-up互聯領域的發展,在短短幾個月內,以中國移動、阿里云及騰訊云等巨頭電信運營商及云廠商分別引領的Scale-up互聯生態 OISA、ALink System以及ETH-X超節點等技術規范旨在推動國內智算中心互聯生態的快速發展。
OISA全向智感互聯
由中國移動引領的OISA主要包括四大設計理念,包括“大規模GPU對等互聯”、“極致報文格式”、“數據層流控和重傳”以及“高效物理傳輸”,核心思想是為GPU卡間互聯提供開放的高帶寬、低時延解決方案。此前在6月份的多樣性算力產業峰會上,中國移動重點展示了“OISA G1協議”并推出“OISA交換芯片原型”。
OISA G1的設計規格支持128張GPU通過8個Switch芯片互聯,任意卡間點對點帶寬達到800GB/s,每個Switch芯片支持128個端口,芯片總速率達到51.2T。奇異摩爾目前已經是OISA聯盟的成員,公司積極聯動運營商、GPU廠商、交換機及服務器領域的優秀生態伙伴、共同推進國內GPU卡間互聯標準的建立與實施。
ALink System 加速器互連系統
ALS產業生態是業界首個支持UALink成立的產業生態,旨在解決AI網絡縱向擴展(Scale-up)中的超高速、超大帶寬等技術難題,為下一代智算網絡打造開放的、統一的標準規范。在今年9月召開的2024 ODCC開放數據中心大會上, 阿里云聯合信通院、奇異摩爾等十多家業界合作伙伴發起了ALS(ALink System,加速器互連系統)開放生態系統。
依托于ODCC(開放數據中心委員會)下設的ALS工作組,生態成員們攜手聚焦解決GPU卡間互聯系統的行業發展和規范問題,推動Scale-up互連系統標準統一建設,打造下一代AI互連網絡軟硬件系統。目前,ALS已形成從協議到芯片、從硬件設備到軟件平臺的系統體系,在ALS-D數據面支持UALink,在ALS-M管控面提供統一接口規范和管控軟件平臺。
ETH-X超節點
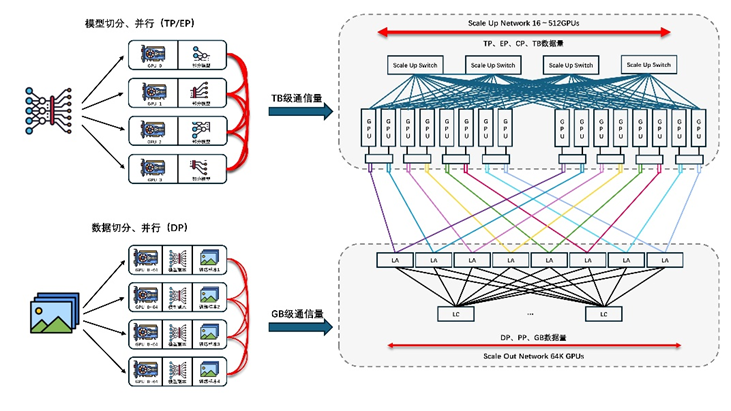
ETH-X超節點聯盟選擇以太網為基礎設施作為GPU超節點項目的首選原型方案。以太網技術(ETH)作為當前最成熟、最開放的網絡技術,具有最大交換芯片容量、最高速Serdes技術、200ns交換芯片、最多參與企業的特點,并且已經是當前眾多GPU廠商選擇的Scale-up接口技術。
據悉,超節點目前已完成Computer-Cable-Switch開放解偶架構設計,保證超節點系統的硬件可以由不同專業領域廠家獨立研發生產,并確保了各子系統硬件可集成互通。系統解偶后,各子系統均具有兼容多種GPU芯片、多種Switch芯片及其獨立演進的能力,由此充分保證了GPU超節點系統參與廠家的專業性、多樣性和開放性。
正如之前我們所提及的加速卡間HBD的挑戰,ETH-X以太超節點系統也面臨著集成測試、系統運維、協議設計、業務測試等一些列的技術挑戰。這一系列的問題需要業界充分協作,共同努力在現有開放生態基礎上不斷完善、加速GPU超節點系統的成熟與發展。
奇異摩爾自研的網絡加速芯粒GPU Link Chiplet——NDSA-G2G,以其極高的靈活性和可擴展性為Scale-up互聯生態提供了強有力的支撐。該產品基于可編程眾核流式架構,支持用戶自定義的協議和處理格式。通過將Chiplet芯粒集成在GPU加速卡內,并利用UCIe D2D接口與GPU互聯,NDSA-G2G能夠實現高性能的數據流,從而全面加速分布式計算網絡。
“據中國IDC圈不完全統計,目前國內不同建設階段的智算中心項目已超過500個,其中投產運營的項目160個,開工在建項目超過200個。智算中心的建設可謂是如火如荼,其發展關乎到區域經濟的發展和產業布局的未來。”
AI網絡基礎設施作為智算中心的重要基石,直接決定了智算中心的能力、效率、可靠性和安全性。從芯片、交換機、網卡、光模塊到其他IT硬件設備,每一個組件都不可或缺,共同構成了一套跨尺度、多層次的復雜系統工程。
奇異摩爾期待未來行業能夠擁抱一種開放而統一的物理接口,產業鏈通過標準制定、軟硬件結合等方面的協同最終實現以太網為基礎的Scale-up網絡和Scale-out網絡的融合,從而構建一個更加高效、靈活的智算網絡架構,為國內智算中心的發展釋放無限可能。
關于我們
AI網絡全棧式互聯架構產品及解決方案提供商
奇異摩爾,成立于2021年初,是一家行業領先的AI網絡全棧式互聯產品及解決方案提供商。公司依托于先進的高性能RDMA 和Chiplet技術,創新性地構建了統一互聯架構——Kiwi Fabric,專為超大規模AI計算平臺量身打造,以滿足其對高性能互聯的嚴苛需求。
我們的產品線豐富而全面,涵蓋了面向不同層次互聯需求的關鍵產品,如面向北向Scale out網絡的AI原生智能網卡、面向南向Scale up網絡的GPU片間互聯芯粒、以及面向芯片內算力擴展的2.5D/3D IO Die和UCIe Die2Die IP等。這些產品共同構成了全鏈路互聯解決方案,為AI計算提供了堅實的支撐。
奇異摩爾的核心團隊匯聚了來自全球半導體行業巨頭如NXP、Intel、Broadcom等公司的精英,他們憑借豐富的AI互聯產品研發和管理經驗,致力于推動技術創新和業務發展。團隊擁有超過50個高性能網絡及Chiplet量產項目的經驗,為公司的產品和服務提供了強有力的技術保障。我們的使命是支持一個更具創造力的芯世界,愿景是讓計算變得簡單。奇異摩爾以創新為驅動力,技術探索新場景,生態構建新的半導體格局,為高性能AI計算奠定穩固的基石。
-
處理器
+關注
關注
68文章
19372瀏覽量
230421 -
NVIDIA
+關注
關注
14文章
5047瀏覽量
103326 -
網絡
+關注
關注
14文章
7586瀏覽量
88994 -
AI
+關注
關注
87文章
31230瀏覽量
269579
原文標題:Kiwi Talks | Scale-up 軍備賽愈演愈烈,集體對抗英偉達的暴力美學
文章出處:【微信號:奇異摩爾,微信公眾號:奇異摩爾】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論