 什么是大模型、大模型是怎么訓練出來的及大模型作用
什么是大模型、大模型是怎么訓練出來的及大模型作用
本文通俗簡單地介紹了什么是大模型、大模型是怎么訓練出來的和大模型的作用。
什么是大模型
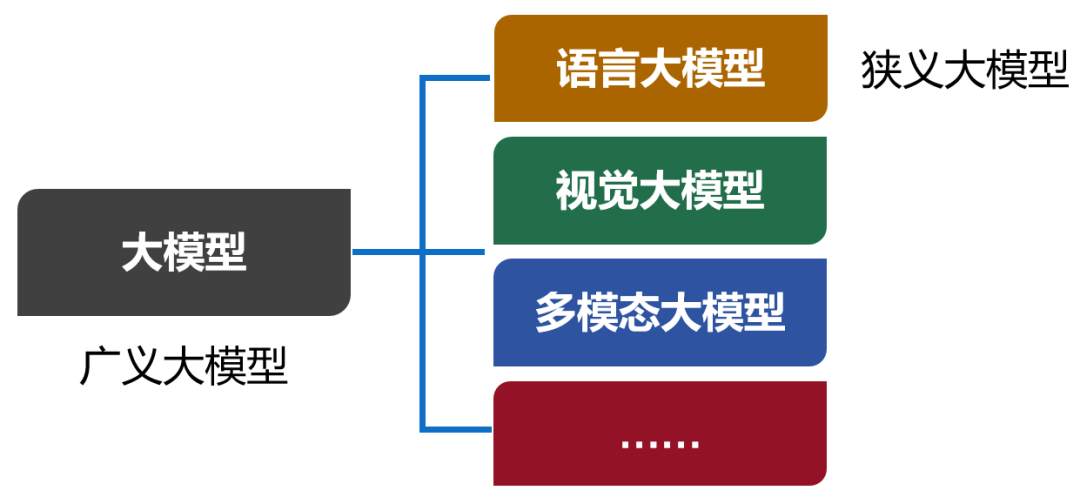
大模型,英文名叫Large Model,大型模型。早期的時候,也叫Foundation Model,基礎模型。 大模型是一個簡稱,完整的叫法,應該是“人工智能預訓練大模型”。預訓練,是一項技術,我們后面再解釋。 我們現在口頭上常說的大模型,實際上特指大模型的其中一類,也是用得最多的一類——語言大模型(Large Language Model,也叫大語言模型,簡稱LLM)。 除了語言大模型之外,還有視覺大模型、多模態大模型等。現在,包括所有類別在內的大模型合集,被稱為廣義的大模型。而語言大模型,被稱為狹義的大模型。
從本質來說,大模型,是包含超大規模參數(通常在十億個以上)的神經網絡模型。 神經網絡是人工智能領域目前最基礎的計算模型。它通過模擬大腦中神經元的連接方式,能夠從輸入數據中學習并生成有用的輸出。
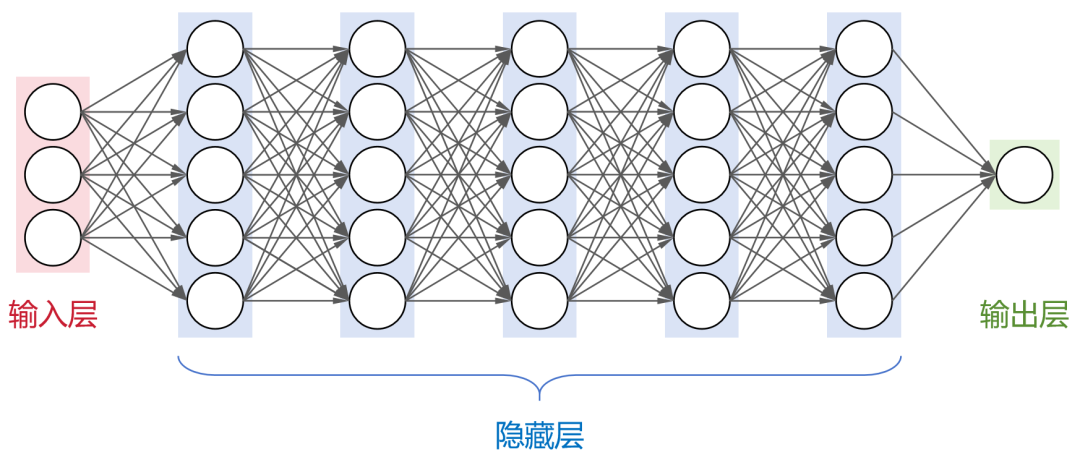
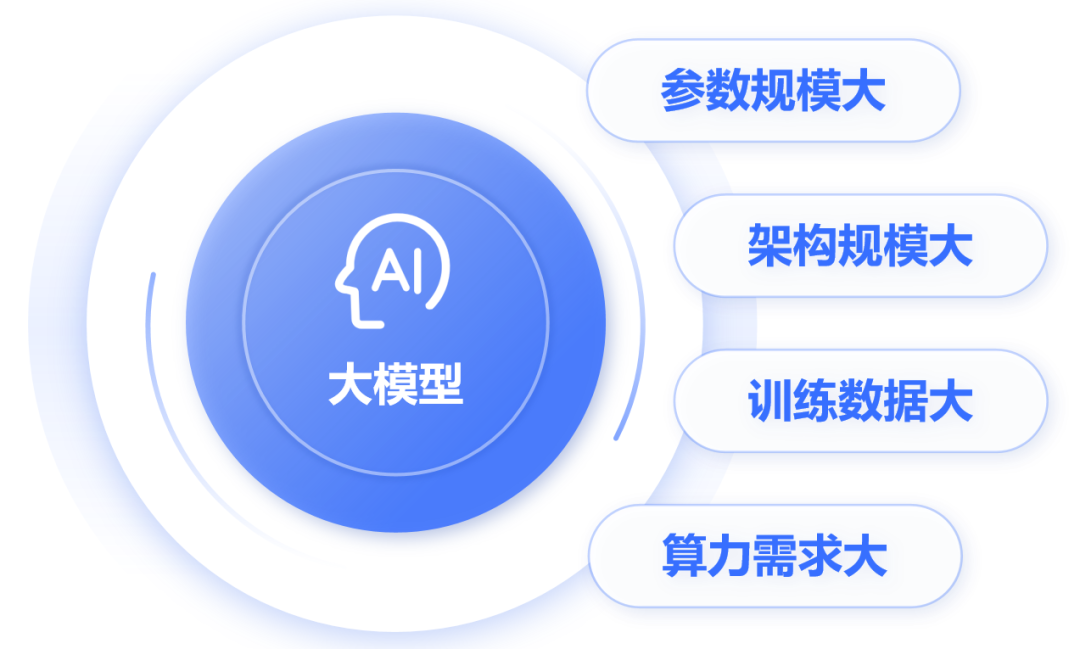
這是一個全連接神經網絡(每層神經元與下一層的所有神經元都有連接),包括1個輸入層,N個隱藏層,1個輸出層。 大名鼎鼎的卷積神經網絡(CNN)、循環神經網絡(RNN)、長短時記憶網絡(LSTM)以及transformer架構,都屬于神經網絡模型。 目前,業界大部分的大模型,都采用了transformer架構。 剛才提到,大模型包含了超大規模參數。實際上,大模型的“大”,不僅是參數規模大,還包括:架構規模大、訓練數據大、算力需求大。
以GPT-3為例。這個大模型的隱藏層一共有96層,每層的神經元數量達到2048個。 大模型的參數數量和神經元節點數有一定的關系。簡單來說,神經元節點數越多,參數也就越多。例如,GPT-3的參數數量,大約是1750億。 大模型的訓練數據,也是非常龐大的。 同樣以GPT-3為例,采用了45TB的文本數據進行訓練。即便是清洗之后,也有570GB。具體來說,包括CC數據集(4千億詞)+WebText2(190億詞)+BookCorpus(670億詞)+維基百科(30億詞),絕對堪稱海量。 最后是算力需求。 這個大家應該都聽說過,訓練大模型,需要大量的GPU算力資源。而且,每次訓練,都需要很長的時間。
GPU算卡 根據公開的數據顯示,訓練GPT-3大約需要3640PFLOP·天(PetaFLOP·Days)。如果采用512張A100 GPU(單卡算力195 TFLOPS),大約需要1個月的時間。訓練過程中,有時候還會出現中斷,實際時間會更長。 總而言之,大模型就是一個虛擬的龐然大物,架構復雜、參數龐大、依賴海量數據,且非常燒錢。 相比之下,參數較少(百萬級以下)、層數較淺的模型,是小模型。小模型具有輕量級、高效率、易于部署等優點,適用于數據量較小、計算資源有限的垂直領域場景。
大模型是如何訓練出來的?
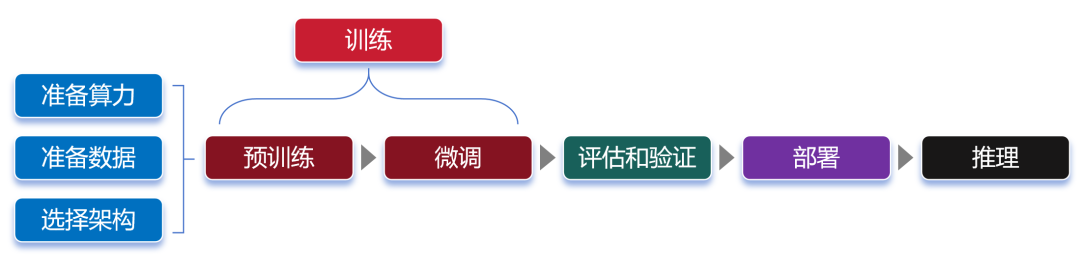
接下來,我們了解一下大模型的訓練過程。 大家都知道,大模型可以通過對海量數據的學習,吸收數據里面的“知識”。然后,再對知識進行運用,例如回答問題、創造內容等。 學習的過程,我們稱之為訓練。運用的過程,則稱之為推理。
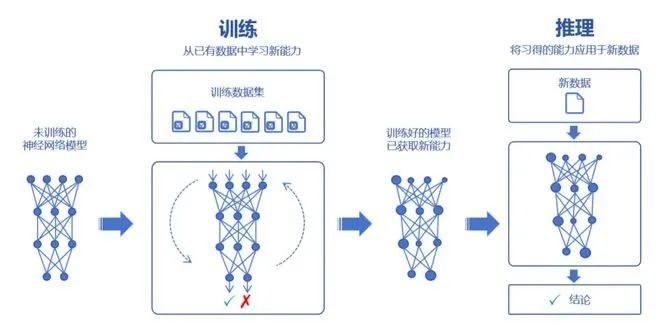
訓練,又分為預訓練(Pre-trained)和微調(Fine tuning)兩個環節。
預訓練
在預訓練時,我們首先要選擇一個大模型框架,例如transformer。然后,通過“投喂”前面說的海量數據,讓大模型學習到通用的特征表示。 那么,為什么大模型能夠具有這么強大的學習能力?為什么說它的參數越多,學習能力就越強? 我們可以參考MIT(麻省理工)公開課的一張圖:
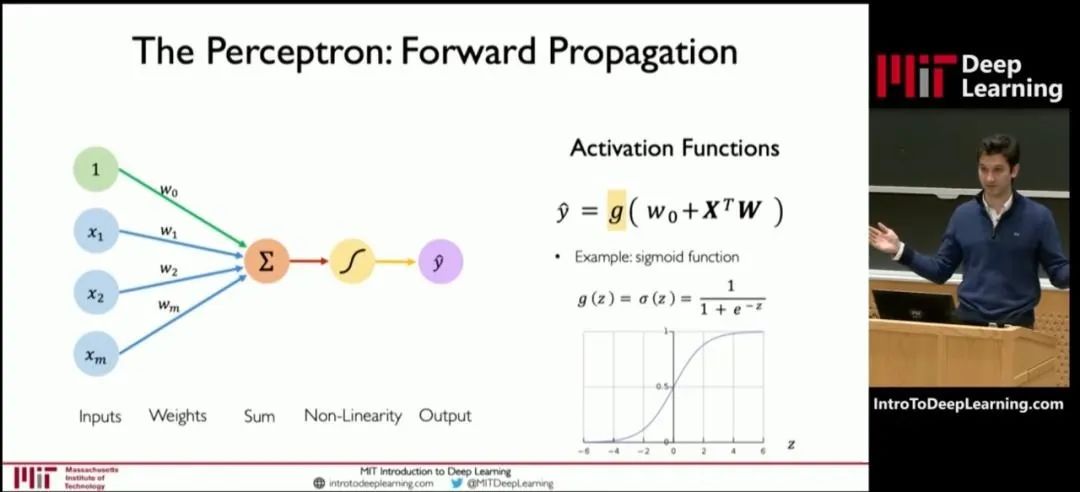
這張圖是深度學習模型中一個神經元的結構圖。 神經元的處理過程,其實就是一個函數計算過程。算式中,x是輸入,y是輸出。預訓練,就是通過x和y,求解W。W是算式中的“權重(weights)”。 權重決定了輸入特征對模型輸出的影響程度。通過反復訓練來獲得權重,這就是訓練的意義。 權重是最主要的參數類別之一。除了權重之外,還有另一個重要的參數類別——偏置(biases)。
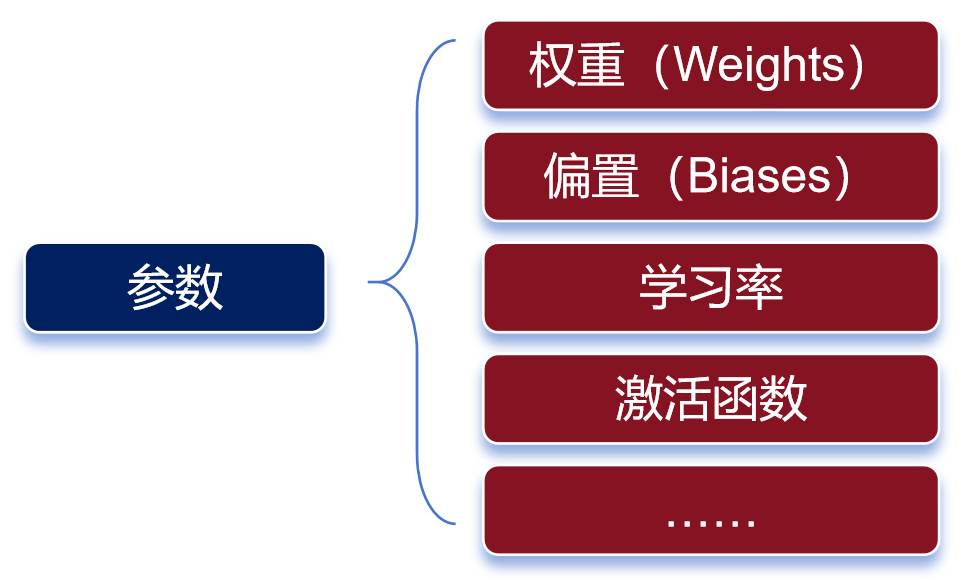
參數有很多種類 權重決定了輸入信號對神經元的影響程度,而偏置則可以理解為神經元的“容忍度”,即神經元對輸入信號的敏感程度。 簡單來說,預訓練的過程,就是通過對數據的輸入和輸出,去反復“推算”最合理的權重和偏置(也就是參數)。訓練完成后,這些參數會被保存,以便模型的后續使用或部署。 參數越多,模型通常能夠學習到更復雜的模式和特征,從而在各種任務上表現出更強的性能。 我們通常會說大模型具有兩個特征能力——涌現能力和泛化能力。 當模型的訓練數據和參數不斷擴大,直到達到一定的臨界規模后,會表現出一些未能預測的、更復雜的能力和特性。模型能夠從原始訓練數據中,自動學習并發現新的、更高層次的特征和模式。這種能力,被稱為“涌現能力”。 “涌現能力”,可以理解為大模型的腦子突然“開竅”了,不再僅僅是復述知識,而是能夠理解知識,并且能夠發散思維。 泛化能力,是指大模型通過“投喂”海量數據,可以學習復雜的模式和特征,可以對未見過的數據做出準確的預測。 參數規模越來越大,雖然能讓大模型變得更強,但是也會帶來更龐大的資源消耗,甚至可能增加“過擬合”的風險。 過擬合,是指模型對訓練數據學習得過于精確,以至于它開始捕捉并反映訓練數據中的噪聲和細節,而不是數據的總體趨勢或規律。說白了,就是大模型變成了“書呆子”,只會死記硬背,不愿意融會貫通。 預訓練所使用的數據,我們也需要再說明一下。 預訓練使用的數據,是海量的未標注數據(幾十TB)。 之所以使用未標注數據,是因為互聯網上存在大量的此類數據,很容易獲取。而標注數據(基本上靠人肉標注)需要消耗大量的時間和金錢,成本太高。 預訓練模型,可以通過無監督學習方法(如自編碼器、生成對抗網絡、掩碼語言建模、對比學習等,大家可以另行了解),從未標注數據中,學習到數據的通用特征和表示。 這些數據,也不是隨便網上下載得來的。整個數據需要經過收集、清洗、脫敏和分類等過程。這樣可以去除異常數據和錯誤數據,還能刪除隱私數據,讓數據更加標準化,有利于后面的訓練過程。 獲取數據的方式,也是多樣化的。 如果是個人和學術研究,可以通過一些官方論壇、開源數據庫或者研究機構獲取。如果是企業,既可以自行收集和處理,也可以直接通過外部渠道(市場上有專門的數據提供商)購買。
微調
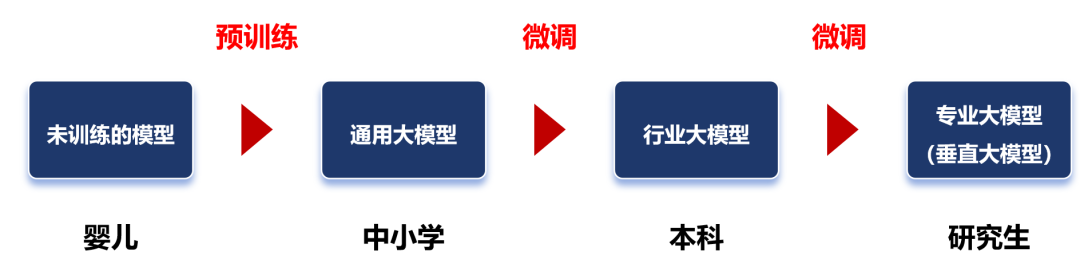
預訓練學習之后,我們就得到了一個通用大模型。這種模型一般不能直接拿來用,因為它在完成特定任務時往往表現不佳。 這時,我們需要對模型進行微調。 微調,是給大模型提供特定領域的標注數據集,對預訓練的模型參數進行微小的調整,讓模型更好地完成特定任務。

行業數據類別 微調之后的大模型,可以稱之為行業大模型。例如,通過基于金融證券數據集的微調,可以得到一個金融證券大模型。 如果再基于更細分的專業領域進行微調,就是專業大模型(也叫垂直大模型)。 我們可以把通用大模型理解為中小學生,行業大模型是大學本科生,專業大模型是研究生。
微調階段,由于數據量遠小于預訓練階段,所以對算力需求小很多。 大家注意,對于大部分大模型廠商來說,他們一般只做預訓練,不做微調。而對于行業客戶來說,他們一般只做微調,不做預訓練。 “預訓練+微調”這種分階段的大模型訓練方式,可以避免重復的投入,節省大量的計算資源,顯著提升大模型的訓練效率和效果。 預訓練和微調都完成之后,需要對這個大模型進行評估。通過采用實際數據或模擬場景對大模型進行評估驗證,確認大模型的性能、穩定性和準確性?等是否符合設計要求。 等評估和驗證也完成,大模型基本上算是打造成功了。接下來,我們可以部署這個大模型,將它用于推理任務。 換句話說,這時候的大模型已經“定型”,參數不再變化,可以真正開始干活了。 大模型的推理過程,就是我們使用它的過程。通過提問、提供提示詞(Prompt),可以讓大模型回答我們的問題,或者按要求進行內容生成。 最后,畫一張完整的流程圖:
大模型究竟有什么作用?
根據訓練的數據類型和應用方向,我們通常會將大模型分為語言大模型(以文本數據進行訓練)、音頻大模型(以音頻數據進行訓練)、視覺大模型(以圖像數據進行訓練),以及多模態大模型(文本和圖像都有)。 語言大模型,擅長自然語言處理(NLP)領域,能夠理解、生成和處理人類語言,常用于文本內容創作(生成文章、詩歌、代碼)、文獻分析、摘要匯總、機器翻譯等場景。大家熟悉的ChatGPT,就屬于此類模型。 音頻大模型,可以識別和生產語音內容,常用于語音助手、語音客服、智能家居語音控制等場景。 視覺大模型,擅長計算機視覺(CV)領域,可以識別、生成甚至修復圖像,常用于安防監控、自動駕駛、醫學以及天文圖像分析等場景。 多模態大模型,結合了NLP和CV的能力,通過整合并處理來自不同模態的信息(文本、圖像、音頻和視頻等),可以處理跨領域的任務,例如文生圖,文生視頻、跨媒體搜索(通過上傳圖,搜索和圖有關的文字描述)等。 今年以來,多模態大模型的崛起勢頭非常明顯,已經成為行業關注的焦點。 如果按照應用場景進行分類,那么類別就更多了,例如金融大模型、醫療大模型、法律大模型、教育大模型、代碼大模型、能源大模型、政務大模型、通信大模型,等等。 例如金融大模型,可以用于風險管理、信用評估、交易監控、市場預測、合同審查、客戶服務等。功能和作用很多很多,不再贅述。
-
大模型
+關注
關注
2文章
2448瀏覽量
2702 -
LLM
+關注
關注
0文章
288瀏覽量
334
原文標題:寫給小白的大模型入門科普
文章出處:【微信號:bdtdsj,微信公眾號:中科院半導體所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【大語言模型:原理與工程實踐】大語言模型的基礎技術
【大語言模型:原理與工程實踐】大語言模型的預訓練
Pytorch模型訓練實用PDF教程【中文】
pytorch訓練出來的模型參數保存為嵌入式C語言能夠調用形式的方法
在Ubuntu上使用Nvidia GPU訓練模型
海思AI芯片學習(十)將yolov3 darknet模型轉換為caffemodel

CNN根本無需理解圖像全局結構,一樣也能SOTA?
AI模型如何將它導入工程里
什么是預訓練AI模型?
深度學習如何訓練出好的模型

關于人工智能的幾個相關概念





 工商網監
工商網監
評論