

本篇測評由電子工程世界的優秀測評者“小火苗”提供。
本文將介紹基于米爾電子MYD-LT527開發板(米爾基于全志T527開發板)的FacenetPytorch人臉識別方案測試。
一、facenet_pytorch算法實現人臉識別
深度神經網絡1.簡介
Facenet-PyTorch 是一個基于 PyTorch 框架實現的人臉識別庫。它提供了 FaceNet 模型的 PyTorch 實現,可以用于訓練自己的人臉識別模型。FaceNet 是由 Google 研究人員提出的一種深度學習模型,專門用于人臉識別任務。
在利用PyTorch神經網絡算法進行人臉圖像對比的實驗設置中,我們專注于對比環節,而不涉及實際項目的完整實現細節。但為了貼近實際應用,我們可以構想以下流程:1)捕捉新人臉圖像:首先,我們使用攝像頭或其他圖像采集設備捕捉一張新的人臉照片。
2)加載存儲的人臉圖像:接著,從數據庫中加載所有已存儲的人臉圖像。這些圖像是之前采集并存儲的,用于與新捕捉到的人臉照片進行對比。
3)構建神經網絡模型:為了實現對比功能,我們需要一個預先訓練好或自定義的神經網絡模型。這個模型能夠提取人臉圖像中的關鍵特征,使得相似的圖像在特征空間中具有相近的表示。
4)特征提取:利用神經網絡模型,對新捕捉到的人臉照片和存儲的每一張人臉圖像進行特征提取。這些特征向量將用于后續的對比計算。
5)計算相似度:采用合適的相似度度量方法(如余弦相似度、歐氏距離等),計算新照片特征向量與存儲圖像特征向量之間的相似度。
6)確定匹配圖像:根據相似度計算結果,找到與新照片相似度最高的存儲圖像,即認為這兩張圖像匹配成功。
7)輸出匹配結果:最后,輸出匹配成功的圖像信息或相關標識,以完成人臉對比的實驗任務。
2.核心組件
MTCNN:Multi-task Cascaded Convolutional Networks,即多任務級聯卷積網絡,專門設計用于同時進行人臉檢測和對齊。它在處理速度和準確性上都有出色的表現,是當前人臉檢測領域的主流算法之一。
FaceNet:由Google研究人員提出的一種深度學習模型,專門用于人臉識別任務。FaceNet通過將人臉圖像映射到一個高維空間,使得同一個人的不同圖像在這個空間中的距離盡可能小,而不同人的圖像距離盡可能大。這種嵌入表示可以直接用于人臉驗證、識別和聚類。
3.功能
支持人臉檢測:使用MTCNN算法進行人臉檢測,能夠準確識別出圖像中的人臉位置。
支持人臉識別:使用FaceNet算法進行人臉識別,能夠提取人臉特征并進行相似度計算,實現人臉驗證和識別功能。
二、安裝facenet_pytorch庫
1.更新系統
更新ubuntu系統,詳情查看米爾提供的資料文件
2.更新系統軟件
apt-get update
3.安裝git等支持軟件
sudo apt-get install -y python3-dev python3-pip libopenblas-dev libssl-dev libffi-dev git cmake
4.安裝Pytorch支持工具
# 克隆 PyTorch 源代碼git clone --recursive https://github.com/pytorch/pytorch# 進入 PyTorch 目錄cd pytorch# 安裝 PyTorch (需要根據你的需求選擇 CUDA 版本,如果不需要 GPU 支持則不需要 --cuda 參數)pip3 install --no-cache-dir torch -f https://download.pytorch.org/whl/torch_stable.html# 測試 PyTorch 安裝python3 -c "import torch; print(torch.__version__)"
5.安裝facenet_pytorch
pip3 install facenet_pytorch
三、CSDN參考案例
1.代碼實現
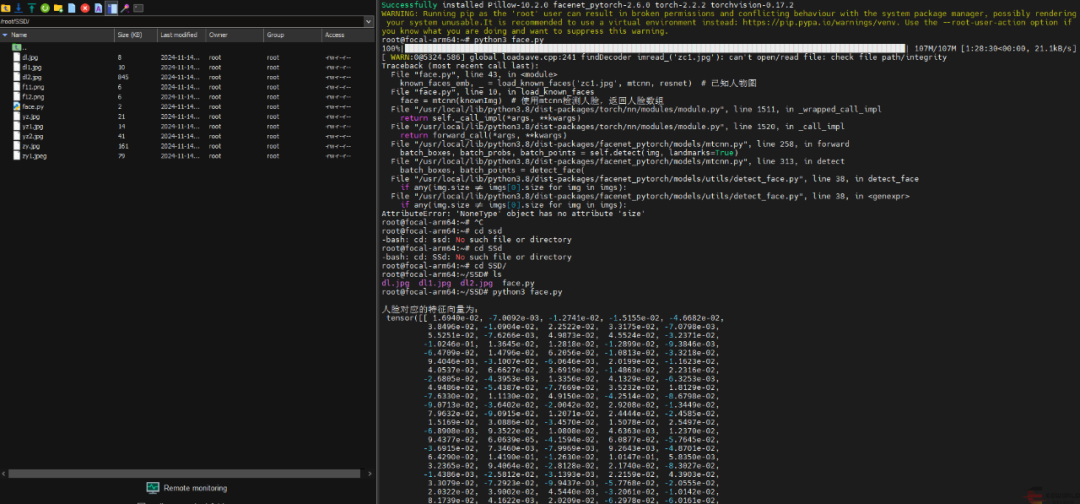
############face_demo.py#############################import cv2import torchfrom facenet_pytorch import MTCNN, InceptionResnetV1# 獲得人臉特征向量def load_known_faces(dstImgPath, mtcnn, resnet):aligned = []knownImg = cv2.imread(dstImgPath) # 讀取圖片face = mtcnn(knownImg) # 使用mtcnn檢測人臉,返回人臉數組if face is not None:aligned.append(face[0])aligned = torch.stack(aligned).to(device)with torch.no_grad():known_faces_emb = resnet(aligned).detach().cpu()# 使用ResNet模型獲取人臉對應的特征向量
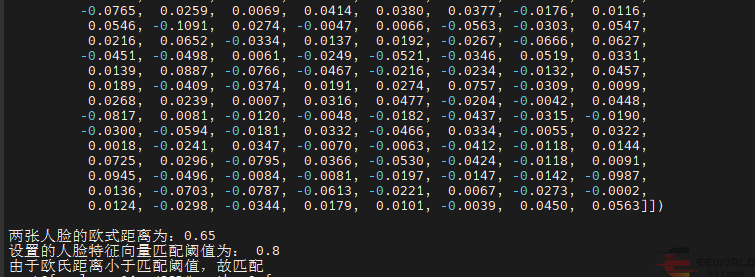
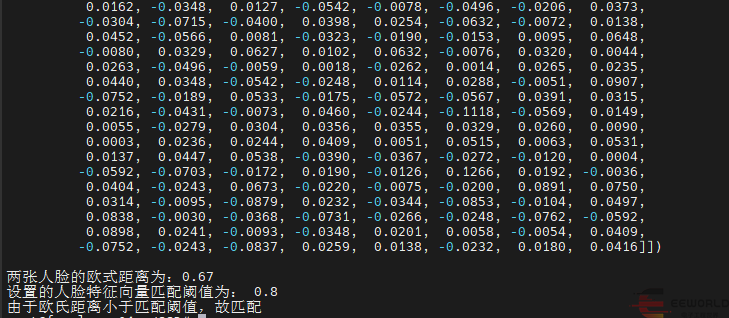
print("\n人臉對應的特征向量為:\n", known_faces_emb)return known_faces_emb, knownImg# 計算人臉特征向量間的歐氏距離,設置閾值,判斷是否為同一張人臉
def match_faces(faces_emb, known_faces_emb, threshold):isExistDst = Falsedistance = (known_faces_emb[0] - faces_emb[0]).norm().item()print("\n兩張人臉的歐式距離為:%.2f" % distance)if (distance < threshold):isExistDst = Truereturn isExistDstif __name__ == '__main__':# help(MTCNN)# help(InceptionResnetV1)# 獲取設備device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')# mtcnn模型加載設置網絡參數,進行人臉檢測
mtcnn = MTCNN(min_face_size=12, thresholds=[0.2, 0.2, 0.3],keep_all=True, device=device)
# InceptionResnetV1模型加載用于獲取人臉特征向量resnet = InceptionResnetV1(pretrained='vggface2').eval().to(device)MatchThreshold = 0.8 # 人臉特征向量匹配閾值設置known_faces_emb, _ = load_known_faces('yz.jpg', mtcnn, resnet) # 已知人物圖faces_emb, img = load_known_faces('yz1.jpg', mtcnn, resnet) # 待檢測人物圖isExistDst = match_faces(faces_emb, known_faces_emb, MatchThreshold) # 人臉匹配print("設置的人臉特征向量匹配閾值為:", MatchThreshold)if isExistDst:boxes, prob, landmarks = mtcnn.detect(img, landmarks=True)print('由于歐氏距離小于匹配閾值,故匹配')else:print('由于歐氏距離大于匹配閾值,故不匹配')
此代碼是使用訓練后的模型程序進行使用,在程序中需要標明人臉識別對比的圖像。
2.實踐過程
第一次運行時系統需要下載預訓練的vggface模型,下載過程較長,后面就不需要在下載了運行會很快。如圖所示:
3.程序運行異常唄終止
運行程序,提示killed,系統殺死了本程序的運行,經過多方面的測試,最終發現是識別的圖片過大,使得程序對內存消耗過大導致。后將圖片縮小可以正常運行了。
以下是對比圖像和對比結果。
四、gitHub開源代碼
1.首先下載代碼文件
代碼庫中,大致的介紹了facenet算法的訓練步驟等。
2.代碼實現
以下是facenet的python代碼,注意需要更改下面的一條程序"cuda" False,因為t527使用的是cpu,芯片到時自帶gpu但是cuda用不了,因為cuda是英偉達退出的一種計算機架構。
import matplotlib.pyplot as pltimport numpy as npimport torchimport torch.backends.cudnn as cudnnfrom nets.facenet import Facenet as facenetfrom utils.utils import preprocess_input, resize_image, show_config#--------------------------------------------## 使用自己訓練好的模型預測需要修改2個參數# model_path和backbone需要修改!#--------------------------------------------#class Facenet(object):_defaults = {
#--------------------------------------------------------------------------## 使用自己訓練好的模型進行預測要修改model_path,指向logs文件夾下的權值文件# 訓練好后logs文件夾下存在多個權值文件,選擇驗證集損失較低的即可。# 驗證集損失較低不代表準確度較高,僅代表該權值在驗證集上泛化性能較好。#--------------------------------------------------------------------------#"model_path" : "model_data/facenet_mobilenet.pth",
#--------------------------------------------------------------------------## 輸入圖片的大小。#--------------------------------------------------------------------------#"input_shape" : [160, 160, 3],#--------------------------------------------------------------------------## 所使用到的主干特征提取網絡#--------------------------------------------------------------------------#"backbone" : "mobilenet",#-------------------------------------------
## 是否進行不失真的resize#-------------------------------------------#"letterbox_image" : True,#-------------------------------------------## 是否使用Cuda# 沒有GPU可以設置成False#-------------------------------------------
#"cuda" : False,}@classmethoddef get_defaults(cls, n):if n in cls._defaults:return cls._defaults[n]else:return "Unrecognized attribute name '" + n + "'"
#---------------------------------------------------## 初始化Facenet#---------------------------------------------------
#def __init__(self, **kwargs):self.__dict__.update(self._defaults)for name, value in kwargs.items():setattr(self, name, value)self.generate()show_config(**self._defaults)def generate(self):#---------------------------------------------------## 載入模型與權值#---------------------------------------------------#print('Loading weights into state dict...')device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')self.net = facenet(backbone=self.backbone, mode="predict").eval()self.net.load_state_dict(torch.load(self.model_path, map_location=device), strict=False)print('{} model loaded.'.format(self.model_path))if self.cuda:self.net = torch.nn.DataParallel(self.net)cudnn.benchmark = Trueself.net = self.net.cuda()#---------------------------------------------------## 檢測圖片#---------------------------------------------------#def detect_image(self, image_1, image_2):#---------------------------------------------------##
圖片預處理,歸一化#---------------------------------------------------#with torch.no_grad():image_1 = resize_image(image_1, [self.input_shape[1], self.input_shape[0]], letterbox_image=self.letterbox_image)image_2 = resize_image(image_2, [self.input_shape[1], self.input_shape[0]], letterbox_image=self.letterbox_image)photo_1 = torch.from_numpy(np.expand_dims(np.transpose(preprocess_input(np.array(image_1, np.float32)), (2, 0, 1)), 0))photo_2 = torch.from_numpy(np.expand_dims(np.transpose(preprocess_input(np.array(image_2, np.float32)), (2, 0, 1)), 0))if self.cuda:photo_1 = photo_1.cuda()photo_2 = photo_2.cuda()
#---------------------------------------------------## 圖片傳入網絡進行預測#---------------------------------------------------#output1 = self.net(photo_1).cpu().numpy()output2 = self.net(photo_2).cpu().numpy()#---------------------------------------------------## 計算二者之間的距離#---------------------------------------------------#
l1 = np.linalg.norm(output1 - output2, axis=1)plt.subplot(1, 2, 1)plt.imshow(np.array(image_1))plt.subplot(1, 2, 2)plt.imshow(np.array(image_2))plt.text(-12, -12, 'Distance:%.3f' % l1, ha='center', va= 'bottom',fontsize=11)plt.show()return l1
3.代碼實現
此代碼調用的簽名的代碼,但其可以直接的去調用圖片進行人臉識別。
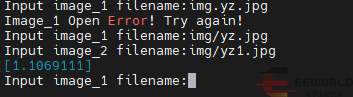
from PIL import Imagefrom facenet import Facenetif __name__ == "__main__":model = Facenet()while True:image_1 = input('Input image_1 filename:')try:image_1 = Image.open(image_1)except:print('Image_1 Open Error! Try again!')continueimage_2 = input('Input image_2 filename:')try:image_2 = Image.open(image_2)except:print('Image_2 Open Error! Try again!')continueprobability = model.detect_image(image_1,image_2)print(probability)
4.程序運行
運行程序后首先顯示的是程序的配置信息,然后可以輸入圖像對比檢測的內容。以下是圖像識別的效果和對比的準確率。

五、參考文獻
CSDN博客
https://blog.csdn.net/weixin_45939929/article/details/124789487?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_baidulandingword~default-1-124789487-blog-142987324.235^v43^pc_blog_bottom_relevance_base6&spm=1001.2101.3001.4242.2&utm_relevant_index=4
官方源碼來源
https://gitcode.com/gh_mirrors/fac/facenet-pytorch/overview
*部分圖片來源于網絡,如有版權問題請聯系刪除
-
開發板
+關注
關注
25文章
5265瀏覽量
99825 -
人臉識別
+關注
關注
76文章
4033瀏覽量
82999 -
米爾
+關注
關注
0文章
53瀏覽量
8083
發布評論請先 登錄
相關推薦
FacenetPytorch人臉識別方案--基于米爾全志T527開發板
搭載全志T527芯片的AvaotaA1開發板

飛凌全志T527開發板buildroot系統下擴大rootfs分區
【米爾首發-全志T527開發板-國產8核A55-免費試用】米爾全志T527開發板安裝測試軟件
【米爾首發-全志T527開發板-國產8核A55-免費試用】米爾全志T527開發板開箱驗機
米爾T527系列加推工控板和工控機,更多工業場景DEMO


通過物聯網管理多臺MQTT設備-基于米爾T527開發板
米粉派7折!米爾全志T527發布Linux系統





 工商網監
工商網監

評論