") AI模型部署邊緣設(shè)備的奇妙之旅:如何實(shí)現(xiàn)手寫數(shù)字識別
AI模型部署邊緣設(shè)備的奇妙之旅:如何實(shí)現(xiàn)手寫數(shù)字識別
1 簡介
近年來,人工智能(AI)技術(shù)的突破性進(jìn)展為嵌入式系統(tǒng)帶來了新的生機(jī)。AI技術(shù)的融入使得嵌入式系統(tǒng)能夠更加智能地處理復(fù)雜任務(wù), 如圖像識別、語音識別、自然語言處理等。這種融合不僅提高了嵌入式系統(tǒng)的智能化水平,還極大地拓展了其應(yīng)用范圍, 使得嵌入式系統(tǒng)在智能家居、智能交通、智能醫(yī)療等領(lǐng)域有了更深層次的運(yùn)用。AI技術(shù)的嵌入,已經(jīng)成為未來嵌入式系統(tǒng)發(fā)展 的一個(gè)重要趨勢。踏入邊緣端部署的第一步,我們可以從一個(gè)經(jīng)典的機(jī)器學(xué)習(xí)案例——手寫數(shù)字識別開始。手寫數(shù)字識別是AI技術(shù)與嵌入式系統(tǒng)融合的一個(gè)直觀且易于理解的例子。它不僅展示了如何在資源受限的設(shè)備上運(yùn)行復(fù)雜的AI算法,而且體現(xiàn)了將智能處理推向數(shù)據(jù)產(chǎn)生源的重要性,從而減少對云端計(jì)算的依賴。
2 基礎(chǔ)知識
2.1 神經(jīng)網(wǎng)絡(luò)模型概覽
神經(jīng)網(wǎng)絡(luò)模型的設(shè)計(jì)靈感來源于人類大腦的結(jié)構(gòu)。人腦由大量相互連接的神經(jīng)元組成,這些神經(jīng)元通過電信號傳遞信息,幫助我們處理和理解周圍的世界。模仿這一過程,人工神經(jīng)網(wǎng)絡(luò)(ANN)利用軟件構(gòu)建的人工神經(jīng)元或節(jié)點(diǎn)來解決復(fù)雜問題。這些節(jié)點(diǎn)被組織成層,并通過計(jì)算系統(tǒng)執(zhí)行數(shù)學(xué)運(yùn)算以求解問題。一個(gè)典型的神經(jīng)網(wǎng)絡(luò)模型包括三個(gè)主要部分:
輸入層:負(fù)責(zé)接收來自外部世界的原始數(shù)據(jù),如圖像、聲音或文本等。輸入節(jié)點(diǎn)對這些數(shù)據(jù)進(jìn)行初步處理后,將它們傳遞給下一層。
隱藏層:位于輸入層與輸出層之間,可以有一層或多層。每一層都會對接收到的數(shù)據(jù)進(jìn)行分析和轉(zhuǎn)換,逐步提取特征直至形成抽象表示。隱藏層的數(shù)量和寬度決定了網(wǎng)絡(luò)的深度和復(fù)雜性。
輸出層:最終產(chǎn)生網(wǎng)絡(luò)的預(yù)測結(jié)果。根據(jù)任務(wù)的不同,輸出層可能包含單個(gè)節(jié)點(diǎn)(例如二分類問題中的0或1)或者多個(gè)節(jié)點(diǎn)(如多類別分類問題)。
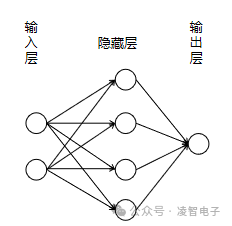
為了更直觀地理解神經(jīng)網(wǎng)絡(luò)的工作原理,我們可以使用在線工具A Neural Network Playground
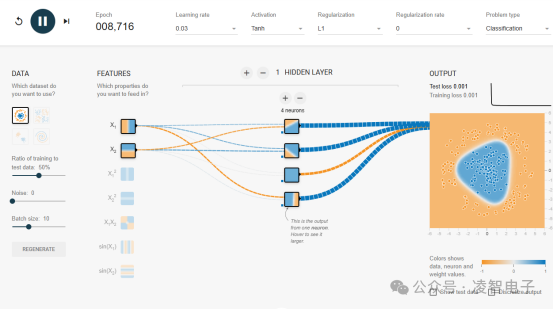
當(dāng)神經(jīng)網(wǎng)絡(luò)中包含多個(gè)隱藏層時(shí),它就被稱為深度神經(jīng)網(wǎng)絡(luò)(DNN),也即深度學(xué)習(xí)網(wǎng)絡(luò)。這類網(wǎng)絡(luò)通常擁有數(shù)百萬甚至更多的參數(shù),使得它們能夠捕捉到數(shù)據(jù)內(nèi)部非常復(fù)雜的非線性關(guān)系。在深度神經(jīng)網(wǎng)絡(luò)中,每個(gè)節(jié)點(diǎn)之間的連接都有一個(gè)權(quán)重值,用來衡量兩個(gè)節(jié)點(diǎn)間的關(guān)聯(lián)強(qiáng)度;正權(quán)重表示激勵(lì)作用,而負(fù)權(quán)重則意味著抑制作用。較高的權(quán)重意味著該節(jié)點(diǎn)對其相鄰節(jié)點(diǎn)的影響更大。理論上講,足夠深且寬的神經(jīng)網(wǎng)絡(luò)幾乎可以擬合任意類型的輸入輸出映射。然而,這種能力是以需要大量的訓(xùn)練數(shù)據(jù)為代價(jià)的——相比起簡單的淺層網(wǎng)絡(luò),深度神經(jīng)網(wǎng)絡(luò)往往需要數(shù)百萬級別的樣本才能達(dá)到良好的泛化性能。
2.3 常見的神經(jīng)網(wǎng)絡(luò)類型
根據(jù)具體應(yīng)用場景和技術(shù)特點(diǎn),人們開發(fā)了多種不同類型的神經(jīng)網(wǎng)絡(luò)架構(gòu):
前饋神經(jīng)網(wǎng)絡(luò)(FNN):最基礎(chǔ)的一種形式,其中數(shù)據(jù)僅沿單一方向流動(dòng),從輸入層經(jīng)過一系列隱藏層到達(dá)輸出層,不存在反饋路徑。
卷積神經(jīng)網(wǎng)絡(luò)(CNN):特別擅長于圖像識別任務(wù),因其特殊的濾波器設(shè)計(jì)能夠有效地捕捉圖像的空間結(jié)構(gòu)信息。
循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN):適用于處理序列數(shù)據(jù),比如自然語言處理中的句子或是時(shí)間序列分析中的股票價(jià)格走勢。RNN具備記憶功能,允許當(dāng)前時(shí)刻的狀態(tài)依賴于之前時(shí)刻的狀態(tài)。
長短期記憶網(wǎng)絡(luò)(LSTM) 和門控循環(huán)單元(GRU):作為RNN的改進(jìn)版本,旨在克服傳統(tǒng)RNN中存在的梯度消失問題,從而更好地建模長時(shí)間跨度上的依賴關(guān)系。
生成對抗網(wǎng)絡(luò)(GAN):由兩個(gè)子網(wǎng)絡(luò)構(gòu)成,一個(gè)是生成器用于創(chuàng)造新的數(shù)據(jù)樣本,另一個(gè)是判別器用來判斷這些樣本的真實(shí)性。兩者相互競爭,共同進(jìn)化,最終實(shí)現(xiàn)高質(zhì)量的數(shù)據(jù)合成。
2.4 模型優(yōu)化技術(shù)
在將深度學(xué)習(xí)模型部署到資源受限的環(huán)境中時(shí),模型優(yōu)化技術(shù)扮演著至關(guān)重要的角色。這些技術(shù)旨在減少模型的大小、降低計(jì)算復(fù)雜度,并提高推理速度,同時(shí)盡量保持或最小化對模型準(zhǔn)確性的負(fù)面影響。以下是三種常見的模型優(yōu)化技術(shù):剪枝、量化和蒸餾。
2.4.1 剪枝(Pruning)
剪枝是一種通過移除神經(jīng)網(wǎng)絡(luò)中不重要或冗余的連接(權(quán)重)或節(jié)點(diǎn)來壓縮模型的技術(shù)。通常,剪枝是基于權(quán)重的絕對值大小來進(jìn)行的,即認(rèn)為較小的權(quán)重對于模型的重要性較低,可以被安全地刪除。
過程:
預(yù)訓(xùn)練階段:首先訓(xùn)練一個(gè)大型的初始模型。
剪枝階段:根據(jù)設(shè)定的標(biāo)準(zhǔn)(如閾值)去除部分權(quán)重或整個(gè)神經(jīng)元。
微調(diào)階段:對剪枝后的模型進(jìn)行再訓(xùn)練,以恢復(fù)可能因剪枝而損失的精度。
優(yōu)點(diǎn):
顯著減少了模型參數(shù)的數(shù)量,從而降低了存儲需求和計(jì)算成本。
對于某些應(yīng)用,可以通過剪枝實(shí)現(xiàn)更高的效率,尤其是在硬件加速器上。
挑戰(zhàn):
剪枝可能會導(dǎo)致模型性能下降,因此需要仔細(xì)選擇剪枝策略并進(jìn)行適當(dāng)?shù)脑儆?xùn)練。
高度非線性的問題中,簡單地剪枝可能會造成較大的準(zhǔn)確率損失。
2.4.2 量化(Quantization)
模型量化是深度學(xué)習(xí)模型優(yōu)化的一種關(guān)鍵技術(shù),旨在通過減少模型參數(shù)和激活值的數(shù)值精度來降低模型的存儲需求和計(jì)算復(fù)雜度。具體來說,量化通常涉及將浮點(diǎn)數(shù)(如32位或16位)表示的權(quán)重和激活轉(zhuǎn)換為低精度的數(shù)據(jù)類型(如8位整數(shù)或更低),從而實(shí)現(xiàn)模型壓縮和加速推理。
過程
(1)訓(xùn)練后量化
這是最簡單的方法,直接應(yīng)用于已經(jīng)訓(xùn)練好的模型。過程如下:
統(tǒng)計(jì)分析:收集模型中所有層的激活和權(quán)重分布信息。
確定范圍:根據(jù)統(tǒng)計(jì)結(jié)果確定量化范圍(例如最小值和最大值),以便將浮點(diǎn)數(shù)映射到整數(shù)區(qū)間。
應(yīng)用量化:將浮點(diǎn)權(quán)重和激活值按照預(yù)定規(guī)則轉(zhuǎn)換為低精度整數(shù)。
校準(zhǔn)(可選):為了最小化量化誤差,可以通過少量數(shù)據(jù)集進(jìn)行校準(zhǔn),調(diào)整量化參數(shù)。
這種方法的優(yōu)點(diǎn)是不需要重新訓(xùn)練模型,但可能導(dǎo)致一定程度的精度損失。
(2)量化感知訓(xùn)練
量化感知訓(xùn)練在模型訓(xùn)練階段就引入了量化操作。這意味著在整個(gè)訓(xùn)練過程中,模型會“學(xué)習(xí)”如何更好地適應(yīng)量化后的環(huán)境。 步驟包括:
模擬量化:在前向傳播時(shí),模擬量化過程,即用低精度數(shù)值代替高精度數(shù)值來進(jìn)行計(jì)算。
反向傳播與更新:在反向傳播期間,仍然使用原始浮點(diǎn)梯度進(jìn)行參數(shù)更新,確保模型能夠正常收斂。
逐步量化:可以選擇性地先對某些層進(jìn)行量化,觀察其影響后再?zèng)Q定是否對其他層也實(shí)施量化。
最終量化:完成訓(xùn)練后,將模型完全轉(zhuǎn)換為量化版本。
這種方法通常能保留更多的模型精度,因?yàn)槟P鸵呀?jīng)在訓(xùn)練中學(xué)會了應(yīng)對量化帶來的變化。
優(yōu)點(diǎn):
顯著降低模型的存儲需求和計(jì)算復(fù)雜度。
在特定硬件(如GPU、NPU)上運(yùn)行時(shí),可以大幅提升推理速度。
挑戰(zhàn):
可能會導(dǎo)致一定的精度損失,盡管這種損失通常是可控的。
不同類型的模型和任務(wù)對量化敏感度不同,需謹(jǐn)慎評估。
2.4.3 蒸餾(Knowledge Distillation)
蒸餾,也稱為知識遷移,是一種通過“教師”模型指導(dǎo)“學(xué)生”模型學(xué)習(xí)的方法。“教師”模型通常是更大、更復(fù)雜的模型,具有較高的準(zhǔn)確性;而“學(xué)生”模型則設(shè)計(jì)得更加緊湊,以便于部署。“教師”的輸出(軟標(biāo)簽)作為額外信息傳遞給“學(xué)生”,幫助其學(xué)習(xí)。
過程:
教師模型訓(xùn)練:先訓(xùn)練出一個(gè)高性能但可能過于龐大的教師模型。
學(xué)生模型訓(xùn)練:使用教師模型的輸出作為監(jiān)督信號,訓(xùn)練一個(gè)較小的學(xué)生模型,使其模仿教師的行為。
混合損失函數(shù):結(jié)合硬標(biāo)簽(原始目標(biāo)值)與軟標(biāo)簽(教師預(yù)測),構(gòu)成最終的損失函數(shù)用于訓(xùn)練學(xué)生模型。
優(yōu)點(diǎn):
可以在幾乎不影響預(yù)測質(zhì)量的情況下大幅減小模型規(guī)模。
學(xué)生模型繼承了教師的知識,能夠在資源受限的設(shè)備上高效運(yùn)行。
挑戰(zhàn):
設(shè)計(jì)有效的教學(xué)策略以及選擇合適的損失函數(shù)是關(guān)鍵。
教師模型的質(zhì)量直接影響到學(xué)生的學(xué)習(xí)效果,因此需要高質(zhì)量的教師模型。
2.5 ONNX
ONNX(Open Neural Network Exchange)是一種用于在各種深度學(xué)習(xí)框架之間轉(zhuǎn)換神經(jīng)網(wǎng)絡(luò)模型的開放格式。它允許用戶將訓(xùn)練好的模型從深度學(xué)習(xí)框架轉(zhuǎn)換為其他框架,或者將模型從一種框架轉(zhuǎn)換為另一種框架。借助它支持不同的人工智能框架(如 PyTorch、MXNet)采用相同格式存儲模型數(shù)據(jù)并交互。
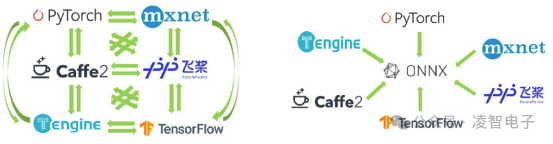
在沒有ONNX之前,每個(gè)深度學(xué)習(xí)框架都有其自己的模型格式,這導(dǎo)致了所謂的“框架鎖定”問題——即一旦選擇了某個(gè)框架進(jìn)行開發(fā),就很難將模型遷移到其他框架中去。ONNX通過定義一種標(biāo)準(zhǔn)化的模型交換格式打破了這種限制,允許模型在PyTorch、TensorFlow、MXNet等流行框架之間自由轉(zhuǎn)換。這意味著開發(fā)者可以根據(jù)項(xiàng)目需求靈活選擇最適合的工具鏈,而不必?fù)?dān)心后期遷移的成本。對于那些希望快速迭代并優(yōu)化模型的企業(yè)和個(gè)人開發(fā)者而言,ONNX極大地簡化了從研究到生產(chǎn)的路徑。例如,研究人員可以在一個(gè)框架中設(shè)計(jì)并訓(xùn)練模型,而工程師則可以輕松地將該模型轉(zhuǎn)換為另一種更適合生產(chǎn)環(huán)境的框架來部署。此外,許多推理引擎和硬件加速器也支持ONNX格式,從而進(jìn)一步加快了模型部署的速度。
在凌智視覺模塊中模型轉(zhuǎn)換就比較簡單,我們只需要點(diǎn)擊運(yùn)行即可,下面是具體的代碼。
%cd /home/aistudio/PaddleX!pip uninstall -y paddle2onnx!pip install paddle2onnx -i https://pypi.doubanio.com/simple/ --trusted-host pypi.douban.com!paddle2onnx --model_dir ./output/best_model/inference \ --model_filename inference.pdmodel \ --params_filename inference.pdiparams \ --save_file ${MODEL_NAME}.onnx \ --deploy_backend rknn!cp ${MODEL_NAME}.onnx /home/aistudio/output%cd /home/aistudio/LockzhinerVisionModule然后使用 LockzhinerVisionModule 模型轉(zhuǎn)換工具,將 ONNX 模型轉(zhuǎn)換為 RKNN 模型。# 將 FP32 ONNX 模型轉(zhuǎn)換為 RKNN 模型import osdef list_image_files(directory, output_file): with open(output_file, 'w') as f: for root, dirs, files in os.walk(directory): for file in files: if file.lower().endswith(('.png', '.jpg', '.jpeg')): abs_path = os.path.abspath(os.path.join(root, file)) f.write(abs_path + '\n')directory_path = '/home/aistudio/data/Dataset' # 替換為你的目錄路徑output_file_path = 'dataset.txt' # 輸出文件名list_image_files(directory_path, output_file_path)!pip install onnxslim!python utils/export.py \ --config_path=./configs/${MODEL_NAME}.yaml \ --model_load_path=/home/aistudio/output/${MODEL_NAME}.onnx \ --model_save_path=/home/aistudio/output/${MODEL_NAME}.rknn \ --target_platform=RV1106
2.6 邊緣端部署需考慮因素
邊緣計(jì)算是一種將數(shù)據(jù)處理任務(wù)盡可能靠近數(shù)據(jù)源執(zhí)行的計(jì)算模式,其主要目的是減少延遲、節(jié)省帶寬,并增強(qiáng)隱私保護(hù)。與依賴遠(yuǎn)程數(shù)據(jù)中心進(jìn)行數(shù)據(jù)處理和存儲的傳統(tǒng)云計(jì)算不同,邊緣計(jì)算讓智能處理更貼近用戶或傳感器,帶來了顯著的優(yōu)勢:
低延遲:由于減少了數(shù)據(jù)往返云端的時(shí)間,邊緣計(jì)算可以實(shí)現(xiàn)近乎即時(shí)的數(shù)據(jù)處理和響應(yīng)。
帶寬優(yōu)化:通過在本地處理數(shù)據(jù),邊緣計(jì)算減少了需要上傳到云端的數(shù)據(jù)量,從而降低了通信成本和網(wǎng)絡(luò)負(fù)載。
隱私與安全:敏感數(shù)據(jù)可以在本地處理,而不必傳輸?shù)酵獠糠?wù)器,這有助于更好地保護(hù)用戶隱私和數(shù)據(jù)安全。
然而,邊緣計(jì)算也帶來了獨(dú)特的挑戰(zhàn),特別是在資源受限的嵌入式系統(tǒng)中部署復(fù)雜的AI模型時(shí)。為了確保神經(jīng)網(wǎng)絡(luò)模型能夠在邊緣設(shè)備上高效運(yùn)行,必須考慮以下關(guān)鍵因素:
(1)硬件性能限制
邊緣設(shè)備通常配備有較低功耗的處理器(如CPU或GPU),這意味著它們的計(jì)算能力有限。對于深度學(xué)習(xí)模型而言,這可能是一個(gè)瓶頸。因此,選擇合適的硬件加速器變得至關(guān)重要,比如神經(jīng)處理單元(NPU)、數(shù)字信號處理器(DSP)等,這些專用硬件可以顯著提高推理速度,同時(shí)保持較低的功耗。
(2)內(nèi)存容量
內(nèi)存大小直接關(guān)系到模型的復(fù)雜度和可加載性。大型神經(jīng)網(wǎng)絡(luò)往往需要大量的RAM來存儲權(quán)重和其他參數(shù)。對于內(nèi)存有限的小型嵌入式系統(tǒng)來說,這可能意味著無法支持過于復(fù)雜的模型。因此,在設(shè)計(jì)階段就需要權(quán)衡模型精度與所需資源之間的關(guān)系,必要時(shí)簡化模型結(jié)構(gòu)以適應(yīng)目標(biāo)平臺。
(3)功耗管理
許多邊緣設(shè)備依靠電池供電,這意味著長時(shí)間運(yùn)行高能耗的應(yīng)用程序會導(dǎo)致電量快速耗盡。為了延長續(xù)航時(shí)間,開發(fā)者應(yīng)該采用節(jié)能算法和技術(shù),例如量化、剪枝等方法來降低模型對計(jì)算資源的需求。此外,還可以利用動(dòng)態(tài)電壓頻率調(diào)節(jié)(DVFS)技術(shù)根據(jù)實(shí)際工作負(fù)載調(diào)整處理器的工作狀態(tài),進(jìn)一步節(jié)約電力。
(4)存儲空間
盡管現(xiàn)代邊緣設(shè)備擁有一定的內(nèi)部存儲,但深度學(xué)習(xí)框架及相關(guān)庫可能會占用大量空間。特別是當(dāng)涉及到預(yù)訓(xùn)練模型時(shí),文件大小可能相當(dāng)可觀。因此,壓縮模型或者精簡依賴項(xiàng)成為了一個(gè)重要的考量點(diǎn)。使用輕量級框架、去除不必要的功能模塊以及應(yīng)用模型壓縮技術(shù)(如量化感知訓(xùn)練)都是有效的解決方案。
3 部署
3.1 準(zhǔn)備工作
在進(jìn)行模型的部署之前,我們首先需要確認(rèn)自己手上的模塊的支持哪些算子、支持什么類型的量化(int4/int8/fp16/混合精度)、內(nèi)存大小等參數(shù),對于手上的板子有一個(gè)全面的了解。在進(jìn)行部署時(shí),我們常常將訓(xùn)練的模型轉(zhuǎn)化成onnx中間文件,再根據(jù)硬件設(shè)備要求的轉(zhuǎn)化成硬件要求的模型文件。在本次實(shí)驗(yàn)中,我使用的模塊是凌智視覺模塊(Lockzhiner Vision Module) ,這個(gè)模塊是福州市凌睿智捷電子有限公司聯(lián)合百度飛槳傾力打造的一款高集成度人工智能視覺模塊,專為邊緣端人工智能和機(jī)器視覺應(yīng)用而設(shè)計(jì),模塊的參數(shù)如下圖所示。

這個(gè)模塊有著一個(gè)很吸引人的特點(diǎn)與飛槳低代碼開發(fā)工具 PaddleX 完美適配,配合飛槳星河社區(qū) Al Studio, 可以實(shí)現(xiàn)一鍵訓(xùn)練;配合凌智視覺算法部署庫,用戶可以實(shí)現(xiàn)一鍵部署,減少我們在模型部署時(shí)遇到的疑難雜癥。如果遇到問題,可以去廠家開源倉庫提交問題。凌智視覺模塊Gitee鏈接
3.2 模型轉(zhuǎn)換
廢話不多說,試一試這個(gè)低代碼平臺是否真的如宣傳所說的那樣容易使用。在 百度飛槳的 AiStudio 中,搜索【PaddleX】在凌智視覺模塊上部署手寫數(shù)字分類模型如果說有自己制作數(shù)據(jù)的話,需要將數(shù)據(jù)上傳,然后在修改全局配置項(xiàng),修改數(shù)據(jù)集地址以及對應(yīng)的類別數(shù)。
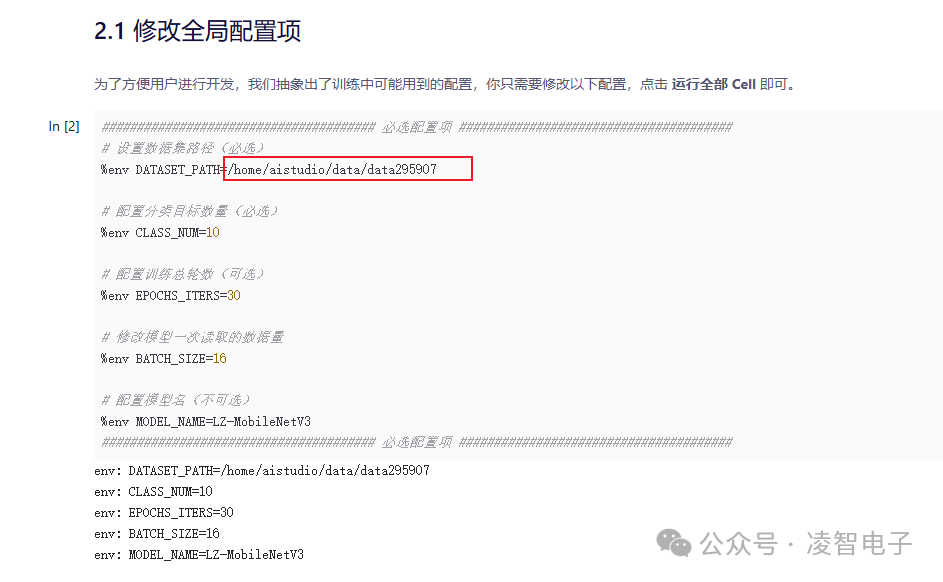
按照廠家提供的配置直接進(jìn)行訓(xùn)練轉(zhuǎn)換。
模型的訓(xùn)練時(shí)間大概為半個(gè)小時(shí),訓(xùn)練完成后,會自動(dòng)生成一個(gè)rknn模型文件,
3.3 部署結(jié)果
模型的推理結(jié)果如下圖所示

-
嵌入式系統(tǒng)
+關(guān)注
關(guān)注
41文章
3593瀏覽量
129466 -
AI
+關(guān)注
關(guān)注
87文章
30887瀏覽量
269065 -
人工智能
+關(guān)注
關(guān)注
1791文章
47274瀏覽量
238467
發(fā)布評論請先 登錄
相關(guān)推薦
邊緣AI應(yīng)用越來越普遍,AI模型在邊緣端如何部署?

邊緣側(cè)部署大模型優(yōu)勢多!模型量化解決邊緣設(shè)備資源限制問題
AI模型部署邊緣設(shè)備的奇妙之旅:如何實(shí)現(xiàn)手寫數(shù)字識別
AI模型部署邊緣設(shè)備的奇妙之旅:如何在邊緣端部署OpenCV
AI模型部署邊緣設(shè)備的奇妙之旅:目標(biāo)檢測模型
基于RBM實(shí)現(xiàn)手寫數(shù)字識別高準(zhǔn)確率
MNIST數(shù)據(jù)集訓(xùn)練手寫數(shù)字識別模型的優(yōu)化
EdgeBoard FZ5 邊緣AI計(jì)算盒及計(jì)算卡
【HarmonyOS HiSpark AI Camera】基于圖像的手語識別機(jī)器人系統(tǒng)
如何將AI模型部署到嵌入式系統(tǒng)中
介紹在STM32cubeIDE上部署AI模型的系列教程
如何去實(shí)現(xiàn)基于K210的MNIST手寫數(shù)字識別
嵌入式邊緣AI應(yīng)用開發(fā)指南
Pytorch實(shí)現(xiàn)MNIST手寫數(shù)字識別
AI模型部署邊緣設(shè)備的奇妙之旅:目標(biāo)檢測模型






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論