 十億級訂單系統的數據庫查詢性能優化之路
十億級訂單系統的數據庫查詢性能優化之路
作者:京東零售 崔健
0.前言
?系統概要:BIP采購系統用于京東采銷部門向供應商采購商品,并且提供了多種創建采購單的方式以及采購單審批、回告、下傳回傳等業務功能
?系統價值:向供應商采購商品增加庫存,滿足庫存周轉及客戶訂單的銷售,供應鏈最重要的第一環節
1.背景
采購系統在經歷了多年的迭代后,在數據庫查詢層面面臨巨大的性能挑戰。核心根因主要有以下幾方面:
?復雜查詢多,歷史上通過MySQL和JED承載了過多的檢索過濾條件,時至今日很難推動接口使用方改變調用方式
?數據量大,隨著業務的持續發展,帶來了海量的數據增長(日均150萬單左右,訂單主表/子表/渠道表/擴展表分別都是:6.5億行,訂單明細表/分配表:9.2億行,日志表:60億行)
?數據模型復雜,訂單完整數據分布在20+張表,經常需要多表join
引入的主要問題有:
?業務層面:
?訂單列表頁查詢/導出體驗差,性能非常依賴輸入條件,尤其是在面對訂單數據傾斜的時候,部分用戶無法查詢/導出超過半個月以上的訂單
?查詢條件不合理,1.歸檔篩選條件,技術詞匯透傳到業務,導致相同周期的單子無法一鍵查詢/導出,需要切換“是否歸檔”查詢全部;2.無法區分“需要倉庫收貨”類的單子,大部分業務同事主要關注這類單子的履約情況
?技術層面:
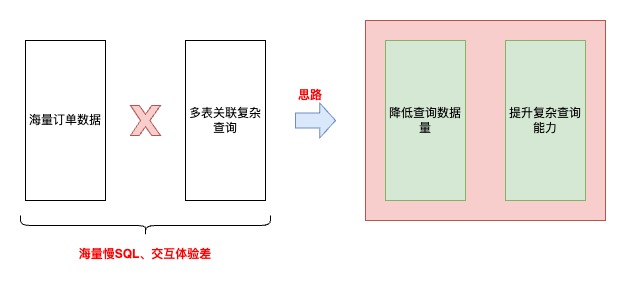
?慢SQL多,各種多表關聯復雜條件查詢導致,索引、SQL已經優化道了瓶頸,經常出現數據庫負載被拉高
?大表多,難在數據庫上做DDL,可能會引起核心寫庫負載升高、主從延遲等問題
?模型復雜,開發、迭代成本高,查詢索引字段散落在多個表中,導致查詢性能下降
2.目標
業務層面:提升核心查詢/導出體驗,加強查詢性能,優化不合理的查詢條件
技術層面:1.減少慢SQL,降低數據庫負載,提高系統穩定性;2.降低單表數據量級;3.簡化數據模型
3.挑戰
提升海量數據、復雜場景下的查詢性能!
?采購訂單系統 VS C端銷售訂單系統復雜度對比:
| 對比項 | 采購訂單系統 | C端訂單銷售系統 |
| 分庫邏輯 | 使用采購單號分庫 | 按用戶pin分庫分表 |
| 查詢場景 | 面向采銷、接口人、供應商、倉儲運營提供包括采銷員、單號、SKU、供應商、部門、配送中心、庫房等多場景復雜查詢 | 主要是按用戶pin進行訂單查詢 |
| 單據所屬人 | 采購單生成后,采銷可以進行單據轉移 | 訂單生成后訂單所屬人不變 |
| 數據傾斜 | 單一采銷或供應商存在大量采購單,并且自動補貨會自動創建采購單 | C端一個用戶pin下訂單數量有限 |
4.方案
思路
優化前
優化后
4.1 降低查詢數據量
4.1.1 前期調研
基于歷史數據、業務調研分析,采購訂單只有8%的訂單屬于“需要實際送貨至京東庫房”的范圍,也就是擁有完整訂單履約流程、業務核心關注時效的。其余訂單屬于通過客戶訂單驅動,在采購系統的生命周期只有創建記錄

基于以上結論,在與產品達成共識后,提出新的業務領域概念:“入庫訂單”,在查詢時單獨異構這部分訂單數據(前期也曾考慮過,直接從寫入層面拆分入庫訂單,但是因為開發成本、改動范圍被pass了)。異構這部分數據實際也參考了操作系統、中間件的核心優化思路,緩存訪問頻次高的熱數據
4.1.2 入庫訂單異構
執行流程
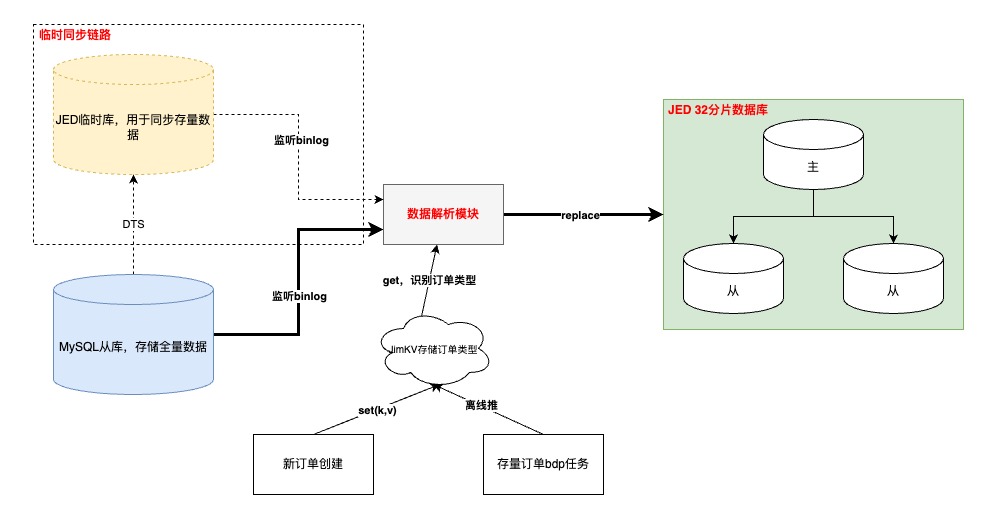
?“入庫”訂單數據打標
?增量訂單在創建訂單完成時寫入;存量訂單通過離線表推數
?需要訂單創建模塊先完成改造上線,再同步歷史,保證數據不丟
?如果在【數據解析模塊】處理binlog時無法及時從JimKV獲取到訂單標識,會補償反查數據庫并回寫JimKV,提升其他表的binlog處理效率
?binlog監聽
?基于公司的【數據訂閱】任務,通過消費JMQ實現。其中訂閱任務基于訂單號進行MQ數據分區,并且在消費端配置不允許消息重試,防止消息時序錯亂
?其中,根據訂單號進行各個表的MQ數據分區,第一版設計可能會引起熱分區,導致消費速率變慢,基于這個問題識別到熱分區主要是由于頻繁更新訂單明細數據導致(訂單(1)->明細(N)),于是將明細相關表基于自身id進行分區,其他訂單緯度表還是基于訂單號。這樣既不影響訂單數據更新的先后順序,也不會造成熱分區、還可以保證明細數據的準確性
?數據同步
?增量數據同步可以采用源庫的增量binlog進行解析即可,存量數據通過申請新庫/表,進行DTS的存量+增量同步寫入,完成binlog生產
?以上是在上線前的臨時鏈路,上線后需要切換到源庫同步binlog的增量訂閱任務,此時依賴“位點回撥”+“數據可重入”。位點回撥基于訂閱任務的binlog時間戳,數據可重入依賴上文提到的MQ消費有序以及SQL覆蓋寫
?數據校對
?以表為緯度,優先統計總數,再隨機抽樣明細進行比對
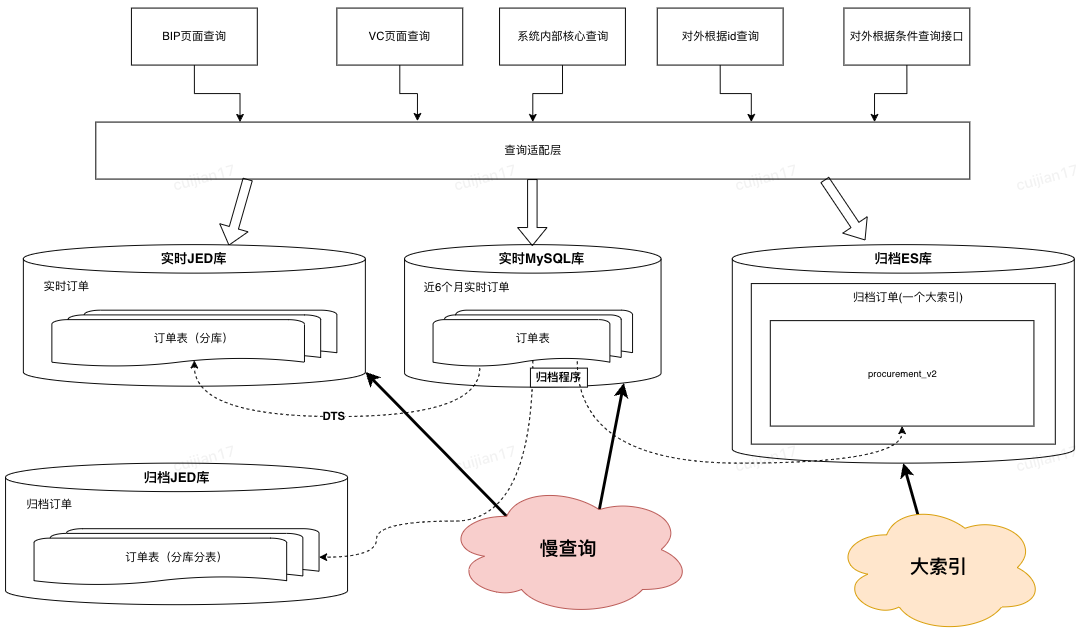
?目前入庫訂單量為穩定在5000萬,全部實時訂單量級6.5億,降低92%
4.2 提升復雜查詢能力
4.2.1 數據準備
?考慮到異構“入庫”訂單到JED,雖然數據查詢時效性可以有一定保障,但是在復雜查詢能力以及識別“非入庫”訂單還沒有支持
?其中,“非入庫”訂單業務對于訂單數據時效性要求并不高(1.訂單創建源于客戶訂單;2.沒有履約流程;3.無需手動操作訂單關鍵節點)
?所以,考慮將這部分查詢能力轉移到ES上
ES數據異構過程
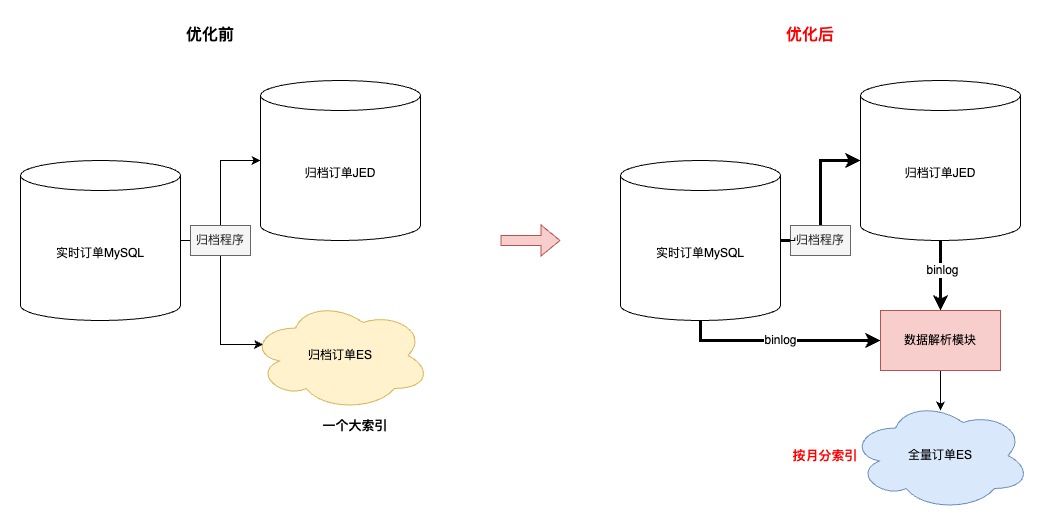
?首先,同步到ES的數據的由“實時+歸檔”訂單組成,其中合計20億訂單,順帶優化了先前歸檔ES大索引(所有訂單放在同一個索引)的問題,改成基于“月份”存儲訂單,之所以改成月份是因為根據條件查詢分兩種:1.一定會有查詢時間范圍(最多3個月);2.指定單號查詢,這種會優先檢索單號對應的訂單創建時間,再路由到指定索引
?其次,簡化了歸檔程序流程,歷史方案是程序中直接寫入【歸檔JED+歸檔ES】,現在優化成只寫入JED,ES數據通過【數據解析模塊】完成,簡化歸檔程序的同時,提高了歸檔能力的時效性
?再次,因為ES是存儲全量訂單,需要支持復雜條件的查詢,所以在訂單沒有物理刪除的前提下,【數據解析模塊】會過濾所有delete語句,保證全量訂單數據的完整性
?接著,為了提升同步到ES數據的吞吐,在MQ消費端,主要做了兩方面優化:1.會根據表和具體操作進行binlog的請求合并;2.降低對于ES內部refresh機制的依賴,將2分鐘內更新到ES的數據緩存到JimKV,更新前從緩存中獲取
?最后,上文提到,同步到入庫JED,有的表是根據訂單號,有的表是根據自身id。那么ES這里,因為NoSQL的設計,和線程并發的問題,為了防止數據錯誤,只能將所有表數據根據單號路由到相同的MQ分區
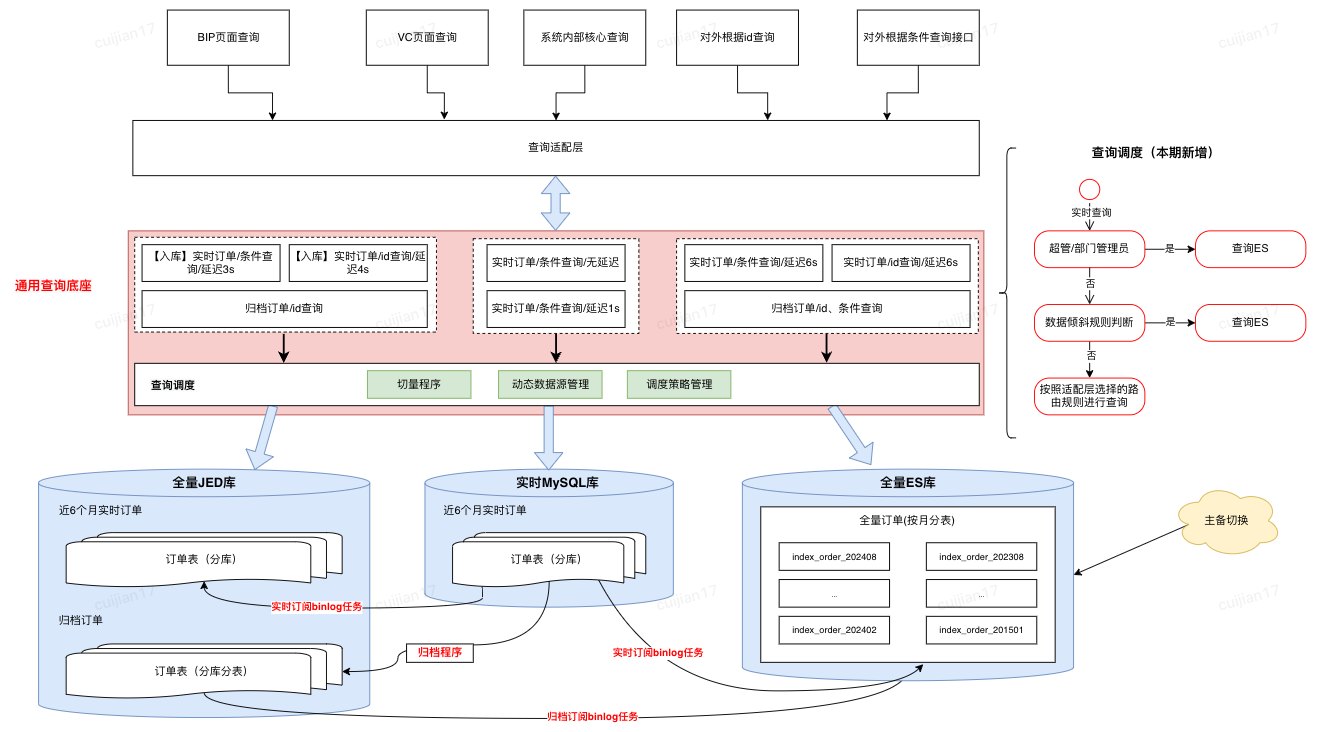
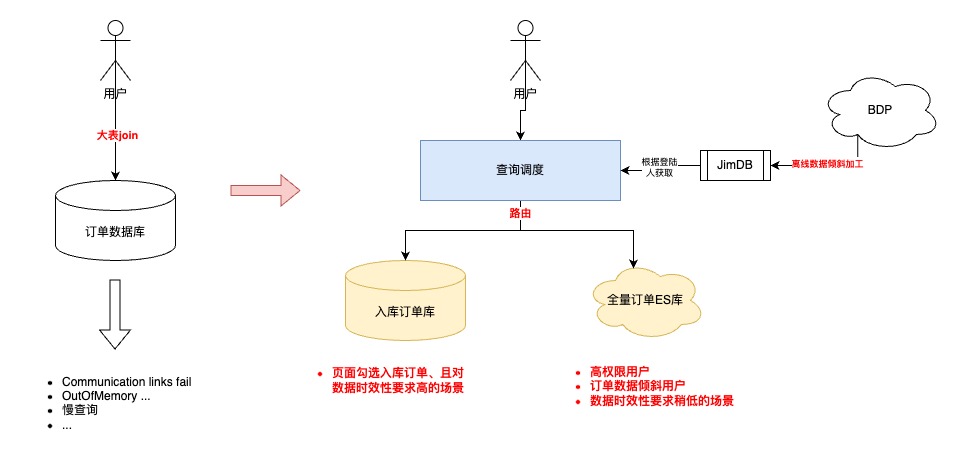
4.2.2 查詢調度策略設計
優化前,所有的查詢請求都會直接落到數據庫進行查詢,可以高效查詢完全取決于用戶的篩選條件是否可以精準縮小數據查詢范圍
優化后,新增動態路由層
?離線計算T-1的采銷/供應商的訂單數據傾斜,將數據傾斜情況推送到JimDB集群
?根據登陸用戶、數據延遲要求、查詢數據范圍,自動調度查詢的數據集群,實現高性能的查詢請求
查詢調度
5.ES主備機制&數據監控
1.主/備ES可以通過DUCC開關,實現動態切換,提升數據可靠性
2.結合公司的業務監控,完成訂單數據延遲監控(數據同步模塊寫入時間-訂單創建時間)
3.開啟消息隊列積壓告警
5.1 ES集群主/備機制
1:1ES集群進行互備,應急預案快速切換,保證高可用

5.2 數據監控

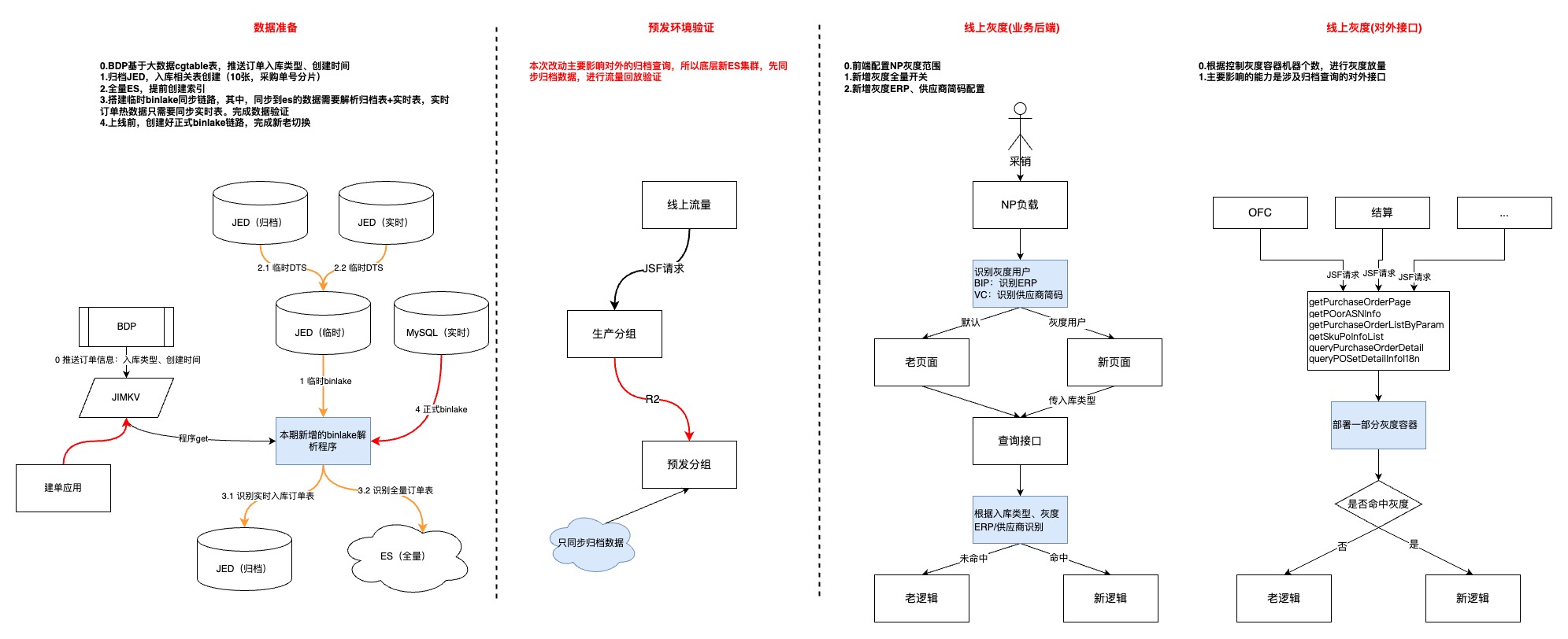
6.灰度上線
?第一步,優先上線數據模塊,耗費較多時間的原因:1.整體數據量級以及歷史數據復雜度的問題;2.數據同步鏈路比較長,中間環節多
?第二步,預發環境驗證,流量回放并沒有做到長周期的完全自動化,根因:1.項目周期相對緊張;2.新老集群的數據還是有一些區別,回放腳本不夠完善
?第三步,用戶功能灰度,主要是借助JDOS的負載均衡策略結合用戶erp完成
?第四部,對外接口灰度,通過控制新代碼灰度容器個數,逐步放量
7.成果
平穩切換,無線上問題
| 指標 | 具體提升 |
|---|---|
| 采購列表查詢(ms) | 1、TP999:4817 優化到 2872,提升40.37% 2、超管、部門管理員由無法查詢超過一周范圍的訂單,優化為可以在2秒內查詢3個月的訂單 3、頁面刪除“是否歸檔”查詢條件,簡化業務操作 4、頁面新增“是否入庫”查詢條件,聚焦核心業務數據 |
| 倉儲運營列表(ms) | TP999:9009 優化到 6545,提升27.34% |
| 采購統計查詢(ms) | TP999:13219 優化到 1546,提升88.3% |
| 慢SQL指標(天緯度) | 1、1s-2s慢SQL數:820->72,降低91% 2、2s-5s慢SQL數:276->26,降低90% 3、5s以上慢SQL數:343->6,降低98% |
8.待辦
?主動監控層面,新增按照天緯度進行數據比對、異常告警的能力,提高問題發現率
?優化數據模型,對歷史無用訂單表進行精簡,降低開發、運維成本,提升需求迭代效率
?精簡存儲集群
?逐步下線其他非核心業務存儲集群,減少外部依賴,提高系統容錯度
?目前全量訂單ES集群已經可以支持多場景的外部查詢,未來考慮是否可以逐步下線入庫訂單JED
?識別數據庫隱患,基于慢日志監控,重新梳理引入模塊,逐步優化,持續降低數據庫負載
?MySQL減負,探索其他優化方案,減少數據量存儲,提升數據靈活性。優先從業務層面出發,識別庫里進行中的僵尸訂單的根因,進行分類,強制結束
?降級方案,當數據同步或者數據庫存在異常時,可以做到秒級無感切換,提升業務可用率
9.寫在最后
?為什么沒考慮Doris?因為ES是團隊應用相對成熟的中間件,處于學習、開發成本考慮
?未來入庫的JED相關表是否可以下掉,用ES完全替代?目前看可以,當初設計冗余入庫JED也是出于對于ES不確定性以及數據延遲的角度考慮,而且歷史的一部分查詢就落在了異構的全量實時訂單JED上。現在,JED官方也不是很推薦非route key的查詢。最后,現階段因為降低了數據量和拆分了業務場景,入庫JED的查詢性能還是非常不錯的
?因為項目排期、個人能力的因素,在方案設計上會有考慮不周的場景,本期只是優化了最核心的業務、技術痛點,未來還有很大持續優化的空間。中間件的使用并不是可以優化數據庫性能的銀彈,最核心的還是要結合業務以及系統歷史背景,在不斷糾結當中尋找balance
審核編輯 黃宇
-
數據庫
+關注
關注
7文章
3799瀏覽量
64388
發布評論請先 登錄
相關推薦
分布式異構數據庫查詢優化方法的研究

如何優化數據庫負載
提高Oracle的數據庫性能
數據庫系統概論之如何進行關系查詢處理和查詢優化
數據庫索引使用策略及優化






 工商網監
工商網監
評論