 知行科技大模型研發體系初見效果
知行科技大模型研發體系初見效果
數據的質量和規模才是端到端的“命脈”
11月,知行科技作為共同第一作者提出的Strong Vision Transformers Could BeExcellent Teachers(ScaleKD),以預訓練ViT(視覺Transformer)模型作為教師,CNN網絡作為學生進行學習。推進異構神經網絡間知識蒸餾研究的具體范式/方法,被收錄于NeurIPS 2024(第38屆神經信息處理系統會議)。
這是知行科技構建大模型體系能力的初步成果之一。2024年年中,知行科技開始從資源、組織等多線程入手,打造面向大模型的研發架構體系,并完成組織架構調整,引入包括清華大學計算機博士背景的大模型架構師等多位大模型與自動駕駛領域專家,構建起對齊主流的研發組織架構和專家人才庫,為2025落地端到端大模型系統上車做好準備。
01構建以數據為中心的開發體系
端到端讓所有智駕玩家有機會重新站上起跑線,但做端到端的挑戰并不全在于“模型”本身。
原特斯拉FSD研發負責人Andrej Karpathy曾表示,特斯拉自動駕駛部門將3/4的精力用在采集、清洗、分類、標注高質量數據上,只有1/4用于算法探索和模型創建。究其原因,數據是人工智能發展的燃料,而端到端大模型將AI的“油耗”水平推到了新的高度。
“100萬個視頻 Case 訓練,勉強夠用;200萬個,稍好一些;300萬個,就會感到Wow;到了1000 萬個,就變得難以置信了。”特斯拉創始人馬斯克曾這樣量化FSD的訓練數據需求。
問題是,雖然人類活動生生不息,有效數據卻不是源源不斷。ChatGPT 3 的開發文檔中提到,45TB的純文本質量過濾后,僅獲得570GB的文本,有效數據僅為1.27%。大語言和多模態模型領域已經開始出現高質量的真實文本、視頻數據耗盡,性能撞墻的情況。
對自動駕駛來說,高質量的數據多來自罕見路況和場景,產生條件苛刻,導致樣本量相對語言類更為稀缺,更是難以滿足大模型的參數需求。
目前,端到端自動駕駛系統上車帶來更上限的同時,也開始遭遇數據分布問題、高質量數據不足,導致的部分場景性能回退、困難場景性能不穩定的情況。
數據的質量和規模才是端到端的“命脈”。知行科技在進入端到端賽道時,決定構建“以數據為中心”的研發體系,用以滿足大模型對高質量數據“貪婪”的特性。
知行科技重構研發組織架構,形成大模型、模型部署、基礎設施、大數據等多模塊在內的主流人工智能開發框架。其中,大模型組不僅在模型層面提供新的技術支持,在數據自動標注算法、基于擴散模型的數據生成、基于多模態大模型的數據挖掘方面也都有發力,以更低成本的數據生產為目標,保質保量地滿足知行科技端到端大模型的數據需求。
02仿真數據,數據戰爭的下一步
當數據需求是百萬clips起步時,應該如何打這場數據戰爭?
知行科技一方面強化自有數據采集和標注能力,并與生態伙伴形成一定程度的數據協同;
在數據采集方面,知行科技已自建采集車隊,自主搭建數據采集軟件、車端采集系統和后端耦合系統,實現數據采集全鏈條的自動化和高度可控,日采集效率達20萬幀,為BEV行泊車功能閉環量產提供必要的數據支持。
在數據標注方面,知行科技已經建成自動化標注體系并在不斷地完善,在OD(障礙物檢測)、LD(車道線檢測)項目中實現完全自動標注,整體減少至少50%的數據標注成本。
與此同時,面向端到端系統海量數據需求,知行科技則借助大模型的能力,探索仿真數據的產業應用前景。
12月,OpenAI和谷歌先后發布了視頻產品,提供文本、圖像、視頻轉視頻的功能,展現出擴散模型等大模型對現實世界極強的復現和“改寫”能力。事實上,包括特斯拉在內的自動駕駛頭部玩家,也已正在加大仿真數據領域的投入。
因為,仿真數據在數據生產降本,和稀有場景數據獲得方面,有著至關重要的作用:
經過良好預訓練的大模型能夠“向前”,渲染復制現實世界生成圖像,并通過在虛擬世界中車輛動態擺放,僅用幾分鐘生成成千上萬段仿真場景信息;
也能夠“向后”推理,基于已有場景和環境信息,進行規劃控制的學習,打通整個感知和規劃鏈路;
此外,基于對物理世界的理解,大模型還能夠通過改變場景中的關鍵數值,提升數采場景的有效比例。
目前,知行科技通過大模型進行數據生成已取得階段性成果:能夠使用原圖進行天氣,光照等條件的修改達到快速擴充真值的目標;通過給定特殊控制量,達到數據生產的目的。通過在自動標注和大模型數據生成方面的全面布局,知行科技在數據生產的降本和質量提升方面,已取得實質性進展。
此外,在數據挖掘方面,知行科技已初步建成ImoGPT-多模態大模型的安全解決方案,通過MoE(混合專家系統)大模型,進行文本理解、圖片理解和視頻理解。其將在實現場景可解釋性、數據挖掘、端到端安全方案等多方面發揮重要作用。
03大模型,有教無類的“良師”
大模型可以是數據的生產者,也可以是端側小模型的“好老師”。
如ChatGPT解釋,憑借龐大的參數量和復雜的結構,大模型能夠通過海量數據訓練,發現新的、更高層次的特征和模式,表現出未能預測、更復雜的能力和特性,實現智能的涌現。“涌現能力”也是大模型擴大使用場景,提升泛化性的核心。但大模型也存在計算資源消耗巨大、推理速度慢、模型可解釋性差的問題,難以被部署在計算和能耗都非常有限的端側。
如何使端模型也獲得相應的知識和泛化能力,知識蒸餾(Knowledge Distillation)技術應運而生:將大模型學到的知識遷移到一個更小的模型中,保持性能的同時降低模型部署難度和計算開銷。
知行科技被NeurIPS 收錄的ScaleKD,正是一種大模型知識蒸餾方法。
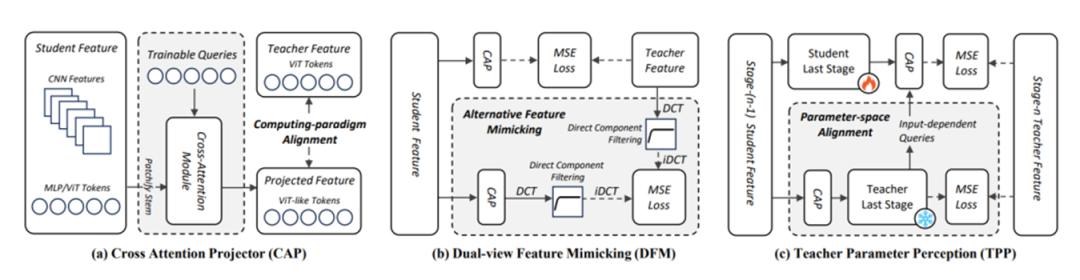
ScaleKD通過結合三個緊密耦合的組件(交叉注意力投影器,雙視圖特征模仿和教師參數感知),對齊云端教師模型和端側學生模型之間的特征計算范式差異、型規模差異和知識密度差異,實現任何目標學生模型在大規模數據集上的時間密集的預訓練范式。
這意味著,大模型能夠作為“有教無類”的良師,將知識和規律“復制”到端側模型,大幅提升其性能和泛化性。
從前沿學術研究出發,知行科技將根據實際中使用的端模型,構建對應的老師模型進行訓練,獲得更強的能力,從而通過知識蒸餾提高端模型的學習效果和速度。
端到端大模型的應用,為智能駕駛玩家帶來重新開局的機會。中國的場景復雜性、市場需求,中國團隊工程化和應用落地的能力,以及大模型技術領域不斷涌現的新能力,使后來者能夠快速、確定性地切入賽道。
知行科技著力構建的數據生產能力,積累的高質量數據,將為端到端模型訓練提供源源不斷的”燃料“,推動智駕功能從“能用”、“好用”,走向消費者“愛用”的未來。
-
自動駕駛
+關注
關注
784文章
13812瀏覽量
166448 -
知行科技
+關注
關注
1文章
44瀏覽量
3423 -
大模型
+關注
關注
2文章
2448瀏覽量
2702
原文標題:備戰端到端,知行科技大模型研發體系初見效果
文章出處:【微信號:gh_dd1765c34afb,微信公眾號:知行科技iMotion】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
“全球Robotaxi第一股”文遠知行榮獲「廣州開發區40周年優秀上市公司」

文遠知行在珠海橫琴新設科技公司
知行機器人獲誠美資本與中關村智友聯合領投
全球通用自動駕駛第一股文遠知行成功登陸納斯達克
自動駕駛公司文遠知行正式掛牌上市
如何評估AI大模型的效果
文遠知行發布全新量產Robotaxi GXR
文遠知行無人駕駛掃路機在廣東汕頭落地
知行科技獲得歐洲某豪華高性能電動汽車品牌車型定點
商湯科技發布日日新5.5大模型體系
yolox_bytetrack_osd_encode示例自帶的yolox模型效果不好是怎么回事?
知行科技榮獲ISO/IEC 27001信息安全管理體系認證!






 工商網監
工商網監
評論