 transformer專用ASIC芯片Sohu說明
transformer專用ASIC芯片Sohu說明
2022年,我們打賭說transformer會統治世界。
我們花了兩年時間打造Sohu,這是世界上第一個用于transformer(ChatGPT中的“T”)的專用芯片。
將transformer架構燒到芯片中,我們無法運行大多數傳統的AI模型:支持Instagram廣告的DLRM,像AlphaFold 2這樣的protein-folding模型,或者像Stable Diffusion 2這樣的舊圖像模型,也不能運行CNN、RNN或LSTM。
但對于transformer來說,Sohu是有史以來最快的芯片。
借助Llama 70B每秒超過50萬個token的吞吐量,Sohu可以讓您構建在GPU上無法實現的產品。Sohu甚至比英偉達(NVIDIA)的下一代Blackwell (B200)GPU更快、更便宜。
今天,每個最先進的AI模型都是一個transformer:ChatGPT,Sora, Gemini,Stable Diffusion 3等等。如果transformer被SSM、RWKV或任何新架構所取代,我們的芯片將毫無用處。
但如果我們是對的,Sohu將改變世界。這就是我們打這個賭的原因。
超級智能所需要的是規模擴展
在五年內,AI模型在大多數標準化測試中變得比人類更聰明。因為Meta在訓練Llama 400B (2024 SoTA,比大多數人都聰明)時使用的計算比OpenAI在GPT-2 (2019 SoTA)上使用的計算多5萬倍。
通過給AI模型提供更多的算力和更好的數據,它們會變得更聰明。規模擴展是唯一一個幾十年來一直有效的技巧,每一家大型AI公司(谷歌、OpenAI /微軟、Anthropic /亞馬遜等)在未來幾年都將花費超過1000億美元來保持擴展。我們生活在有史以來最大的基礎設施建設中。
“我認為(我們)可以擴大到1000億美元的規模,……我們將在幾年內實現這一目標。”
——Dario Amodei, Anthropic CEO
擴展下一個1000倍將非常昂貴。下一代數據中心的成本將超過一個小國的GDP。以目前的速度,我們的硬件、電網和錢包都跟不上。
我們不擔心數據耗盡。無論是通過合成數據、標注管道,還是新的AI標記數據源,我們認為數據問題實際上是一個推理計算問題。Mark Zuckerberg、Dario Amodei和Demis Hassabis似乎也同意這一點。
GPU正遇到壁壘
小秘密是GPU并沒有變得更好,而是變得更大了。該芯片每面積的算力(TFLOPS)四年來幾乎持平。
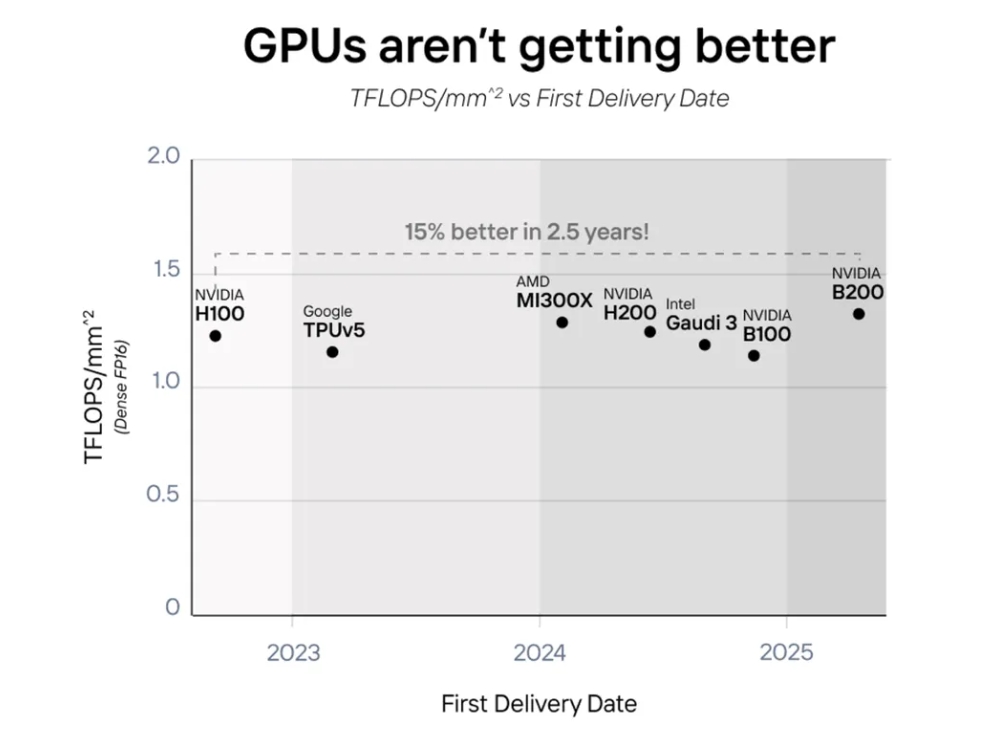
從2022年到2025年,AI芯片并沒有變得更好,而是變得更大了。英偉達的B200、AMD的MI300、英特爾的Gaudi 3和亞馬遜的Trainium2將兩個芯片作為一張卡來“加倍”性能。2022-2025年間的所有GPU性能提升都使用了這個技巧,除了Etched。
隨著摩爾定律的放緩,提高性能的唯一方法就是專業化。
專用芯片不可避免
在transformer占領世界之前,許多公司制造了靈活的AI芯片和GPU來處理數百種不同的架構。舉幾個例子:
NVIDIA’s GPUs
Google’s TPUs
Amazon’s Trainium
AMD’s accelerators
Graphcore’s IPUs
SambaNova SN Series
Cerebras’s CS-2
Groq’s GroqNode
Tenstorrent’s Grayskull
D-Matrix’s Corsair
Cambricon’s Siyuan
Intel’s Gaudi
目前還沒有人開發出專門針對算法的AI芯片(ASIC)。芯片項目耗資5000 -1億美元,需要數年時間才能投產。剛開始的時候,沒有市場。
突然之間,情況發生了變化:
前所未有的需求:在ChatGPT之前,transformer推斷市場約為5000萬美元,而現在是數十億美元。所有大型科技公司都使用transformer模型(OpenAI、b谷歌、亞馬遜、微軟、Facebook等)。
架構融合:AI模型過去經常發生變化。但自GPT-2以來,最先進的模型架構幾乎保持相同!OpenAI的GPT家族,谷歌的PaLM, Facebook的LLaMa,甚至特斯拉的FSD都是transformer。
當模型的訓練成本超過10億美元,推理成本超過100億美元時,專用芯片是不可避免的。在這個規模上,1%的改進將證明一個5000 -1億美元的定制芯片項目是合理的。
實際上,ASIC比GPU要快幾個數量級。2014年,當比特幣進入市場時,扔掉GPU比用它們挖比特幣更便宜。
隨著數十億美元的投入,AI也將面臨同樣的命運。
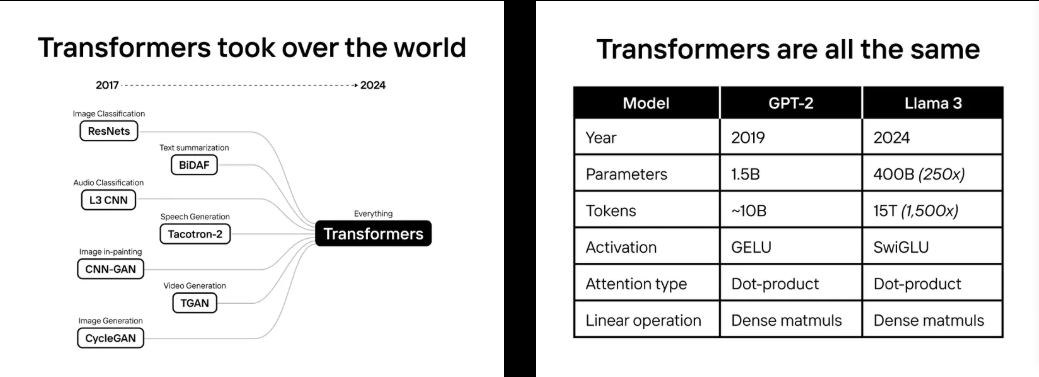
transformer驚人地相似:像SwiGLU激活和RoPE編碼這樣的調整無處不在:LLM、嵌入模型、圖像繪制和視頻生成。
雖然GPT-2和Llama-3是最先進的(SoTA)型號,但它們的架構幾乎相同。唯一的主要區別是規模。
transformer有一條巨大的護城河
我們相信硬件抽獎:獲勝的機型是那些在硬件上運行最快、最便宜的機型。transformer功能強大、有用、利潤豐厚,足以在替代產品出現之前主導每一個主要的AI計算市場:
transformer為每一個大型AI產品提供動力:從代理到搜索再到聊天。為了優化用于transformer的GPU,AI實驗室已經投入了數億美元的研發資金。當前和下一代最先進的型號是transformer。
未來幾年,隨著模型規模從10億美元擴大到100億美元,再到1000億美元的訓練費用,測試新架構的風險也會飆升。與其重新測試縮放定律和性能,不如把時間花在構建transformer的特性上,比如multi-token預測。
今天的軟件堆棧針對transformer進行了優化。每個流行的庫(TensorRT-LLM, vLLM, Huggingface TGI等)都有專門的內核用于在GPU上運行transformer模型。在transformer之上構建的許多特性在替代方案中不容易得到支持(例如推測解碼、樹搜索)。
未來的硬件堆棧將針對transformer進行優化。NVIDIA的GB200對transformer(TransformerEngine)有特殊的支持。像Sohu這樣的ASIC進入這個市場標志著不可能再回頭了。transformer殺手需要在GPU上運行的速度比在Sohu上運行的速度快。如果發生這種情況,我們也將為此構建一個ASIC !
遇見Sohu
Sohu是世界上第一個transformer專用集成電路。一臺8xSohu服務器替換160個H100 GPU。
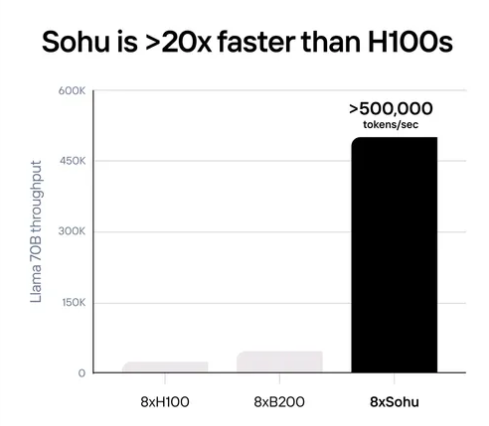
通過專業化,Sohu獲得了前所未有的業績。一臺8xSohu服務器每秒可以處理超過500,000個Llama 70Btoken。
基準是在FP8精度下的lama- 370B:無稀疏性,8倍模型并行,2048輸入/128輸出長度。
用TensorRT-LLM 0.10.08(最新版本)計算8xH100,估計8xGB200的數字。
Sohu只支持transformer推理,無論是Llama還是Stable Diffusion3。Sohu支持目前所有的模型(谷歌,Meta, Microsoft, OpenAI,Anthropic等),并可以處理對未來模型的調整。
由于Sohu只能運行一種算法,絕大多數控制流邏輯可以被移除,從而允許它擁有更多的數學塊。因此,Sohu擁有超過90%的FLOPS利用率(相比之下,使用TRT-LLM的GPU7只有30%)。
怎么能在芯片上容納比GPU更多的FLOPS呢?
NVIDIA H200具有989 TFLOPS的FP16/BF16無稀疏性計算。這是最先進的(甚至超過了谷歌的新Trillium芯片),而在2025年推出的GB200只多了25%的計算能力(每芯片1,250 TFLOPS)。
由于GPU的絕大部分區域都致力于可編程性,專門研究transformer可以讓您適應更多的計算。你可以從第一原理中證明這一點:
構建單個FP16/BF16/FP8乘加電路需要10,000個晶體管,這是所有矩陣數學的構建模塊。H100 SXM有528個張量核,每個核有4*8*16個FMA電路。乘法告訴我們H100有27億個晶體管專用于張量核。
但是H100有800億個晶體管!這意味著H100 GPU上只有3.3%的晶體管用于矩陣乘法!
這是英偉達和其他靈活AI芯片深思熟慮的設計決策。如果想支持各種模型(CNN、LSTM、SSM等),你不能做得比這更好了。
通過只運行transformer,我們可以在芯片上容納更多的FLOPS,而不會降低精度或稀疏性。
推理的瓶頸不應該是在內存帶寬上,而不是在計算上嗎?
事實上,對于像Llama-3這樣的現代模型來說,答案是no!
讓我們使用NVIDIA和AMD的標準基準:2048個輸入token和128個輸出token。大多數AI產品的提示都比完成時間長得多(甚至一個新的Claude聊天在系統提示中也有1000多個token)。
在GPU和Sohu上,推理是批量運行的。每個批處理一次加載所有模型權重,并在批處理中的每個token上重用它們。一般來說,LLM的輸入是計算綁定的,而LLM的輸出是內存綁定的。當我們將輸入和輸出token與連續批處理結合在一起時,工作負載變得非常計算受限。
下面是LLM的連續批處理示例。這里我們正在運行具有四個輸入token和四個輸出token的序列;每種顏色都是不同的序列。
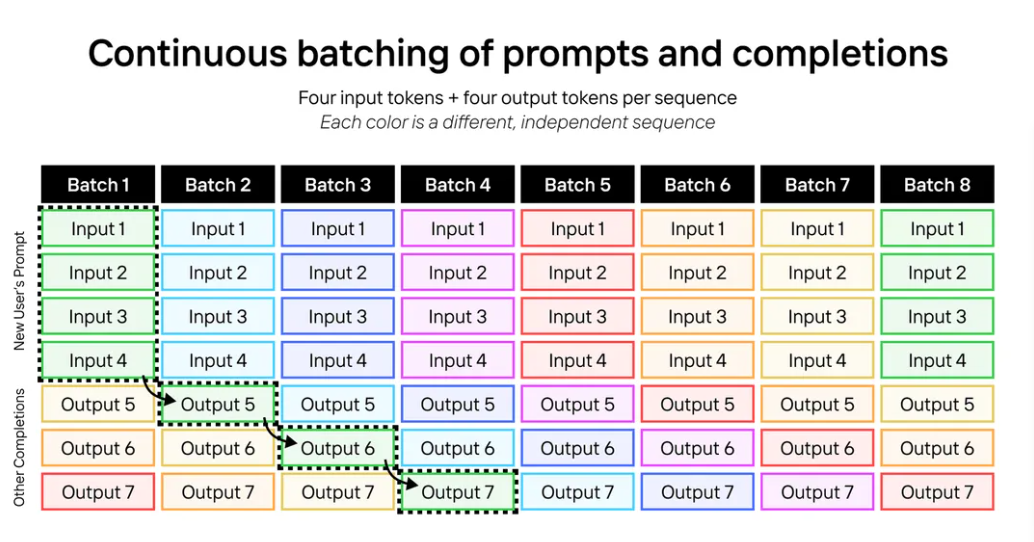
我們可以擴展同樣的技巧來運行Llama-3-70B,使用2048個輸入token和128個輸出token。每個批處理包含一個序列的2048個輸入token,以及127個不同序列的127個輸出token。
如果我們這樣做,每批將需要大約(2048 + 127)*70B params *2字節/ param = 304 TFLOPs,而只需要加載70B params *2字節/ param = 140 GB的模型權重和大約127 *64*8 *128*(2048 + 127)*2*2 = 72GB的KV緩存權重。這遠遠超過了內存帶寬:一臺H200需要6.8 PFLOPS的計算才能最大限度地利用其內存帶寬。這是在100%利用率下,如果利用率是30%,你需要3倍以上計算負載。
由于Sohu有如此多的計算和非常高的利用率,我們可以運行巨大的吞吐量,而不會出現內存帶寬的瓶頸。
在現實世界中,批處理要大得多,輸入長度變化很大,請求以泊松分布到達。這種技術在這些情況下效果更好,但我們在這個例子中使用2048/128基準,因為NVIDIA和AMD使用它。
軟件是如何工作的?
在GPU和TPU上,軟件是一場噩夢。處理任意CUDA和PyTorch代碼需要一個非常復雜的編譯器。第三方AI芯片(AMD、英特爾、AWS等)在軟件上總共花費了數十億美元,但收效甚微。
但是Sohu只運行transformer,我們只需要為transformer編寫軟件!
大多數運行開源或內部模型的公司使用特定于transformer的推理庫,如TensorRT-LLM、vLLM或HuggingFace的TGI。這些框架非常嚴格——雖然可以調整模型超參數,但并不真正支持更改底層模型代碼。但這很好——因為所有的transformer模型都是如此相似(甚至是文本/圖像/視頻的),調整超參數是你真正需要的。
雖然這支持95%的AI公司,但最大的AI實驗室都是定制的。他們有工程師團隊手動調整GPU內核,以擠出更多的利用率,逆向工程,比如哪個寄存器對張量核心的延遲最低。
有了Etched,你再也不需要逆向工程了——我們的軟件,從驅動程序到內核再到服務棧,都將是開源的。如果想實現自定義的transformer層,您的內核向導可以自由地這樣做。
Etched將是第一個
如果這個賭注現在看起來很瘋狂,想象一下在2022年實現它。剛開始的時候,ChatGPT還不存在!圖像和視頻生成模型是U-Nets,自動駕駛汽車是由CNN驅動的,transformer架構遠未普及。
幸運的是,形勢已經朝著有利于我們的方向轉變。從語言到視覺,每個領域的頂級模型現在都是transformer。這種融合不僅證明了這一押注是正確的,而且也使Sohu成為這十年來最重要的硬件項目。
我們正在進行歷史上最快的芯片發布之一:
頂尖的AI研究人員和硬件工程師離開了重大的AI芯片項目,加入我們;
我們已經直接與臺積電合作開發他們的4nm工藝。我們已經從頂級供應商那里獲得了足夠的HBM和服務器供應,可以快速啟動第一年的生產;
我們的早期客戶已經預訂了數千萬美元的硬件.
?
如果我們是對的,Sohu將改變世界
如果AI模型一夜之間變得快20倍、便宜20倍,會發生什么?
今天,Gemini要花60秒回答一個關于視頻的問題。編碼代理的成本高于軟件工程師,完成任務需要花費數小時。視頻模型每秒生成一幀,甚至當ChatGPT注冊用戶達到1000萬(僅占世界的0.15%)時,OpenAI的GPU容量也耗盡了。
我們并沒有在解決這個問題的軌道上——即使我們繼續讓GPU變得更大,以每兩年2.5倍的速度,也需要十年的時間才能實現實時視頻生成。
但有了Sohu,這將是即時的。當實時視頻、電話、代理和搜索最終正常工作時,會發生什么?
很快,你就會知道了。
原文鏈接:
https://www.etched.com/announcing-etched
-
芯片
+關注
關注
456文章
51121瀏覽量
426092 -
asic
+關注
關注
34文章
1205瀏覽量
120639 -
Transformer
+關注
關注
0文章
145瀏覽量
6030
原文標題:揭秘transformer專用ASIC芯片:Sohu!
文章出處:【微信號:SSDFans,微信公眾號:SSDFans】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
ASIC和GPU的原理和優勢
FPGA與ASIC的區別 FPGA性能優化技巧
ASIC集成電路與通用芯片的比較
只能跑Transformer的AI芯片,卻號稱全球最快?
什么是專用集成電路 通信專用集成電路有哪些類型
專用集成電路包括什么和什么兩種 專用集成電路包括什么功能設備
專用集成電路和通用有哪些區別
專用集成電路asic是不是芯片
專用集成電路測試方法有哪些
專用集成電路芯片類型是什么
專用集成電路包括驅動芯片嗎為什么
到底什么是ASIC和FPGA?






 工商網監
工商網監
評論