") 國(guó)產(chǎn)大模型DeepSeek推出DeepSeek-V3
國(guó)產(chǎn)大模型DeepSeek推出DeepSeek-V3
眾所周知,過去一年間,大語(yǔ)言模型(LLM)領(lǐng)域經(jīng)歷了翻天覆地的變化...
回望2023年底,OpenAI的GPT-4還是一座難以逾越的高峰,其他AI實(shí)驗(yàn)室都在思考同一個(gè)問題:OpenAI究竟掌握了哪些獨(dú)特的技術(shù)秘密?
一年后的今天,形勢(shì)已發(fā)生根本性轉(zhuǎn)變,據(jù)Chatbot Arena排行榜顯示,原始版本的GPT-4(GPT-4-0314)已跌至第70位左右。目前,已有18家機(jī)構(gòu)的70個(gè)模型在性能上超越了這個(gè)曾經(jīng)的標(biāo)桿。
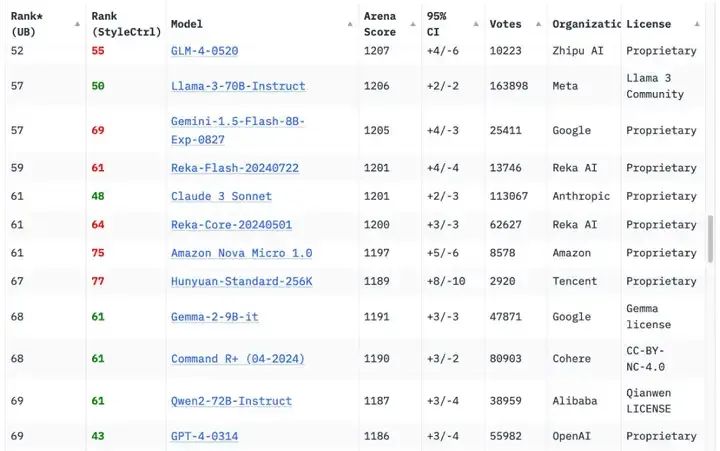
圖源:Chatbot Arena
隨著2025年的嶄新啟航,是否意味著AI圈的一顆“王炸”已悄然“引爆”?
近日,國(guó)產(chǎn)大模型DeepSeek推出DeepSeek-V3,一個(gè)強(qiáng)大的混合專家(Mixture-of-Experts, MoE)語(yǔ)言模型,DeepSeek-V3擁有高達(dá)6710億的參數(shù)規(guī)模,但每次推理僅激活370億參數(shù)。
尤其,當(dāng)o1、Claude、Gemini和Llama 3等模型還在為數(shù)億美元的訓(xùn)練成本苦惱時(shí), DeepSeek-V3用557.6萬(wàn)美元的預(yù)算,在2048個(gè)H800 GPU集群上僅花費(fèi)3.7天/萬(wàn)億tokens的訓(xùn)練時(shí)間,就達(dá)到了足以與它們比肩的性能 。
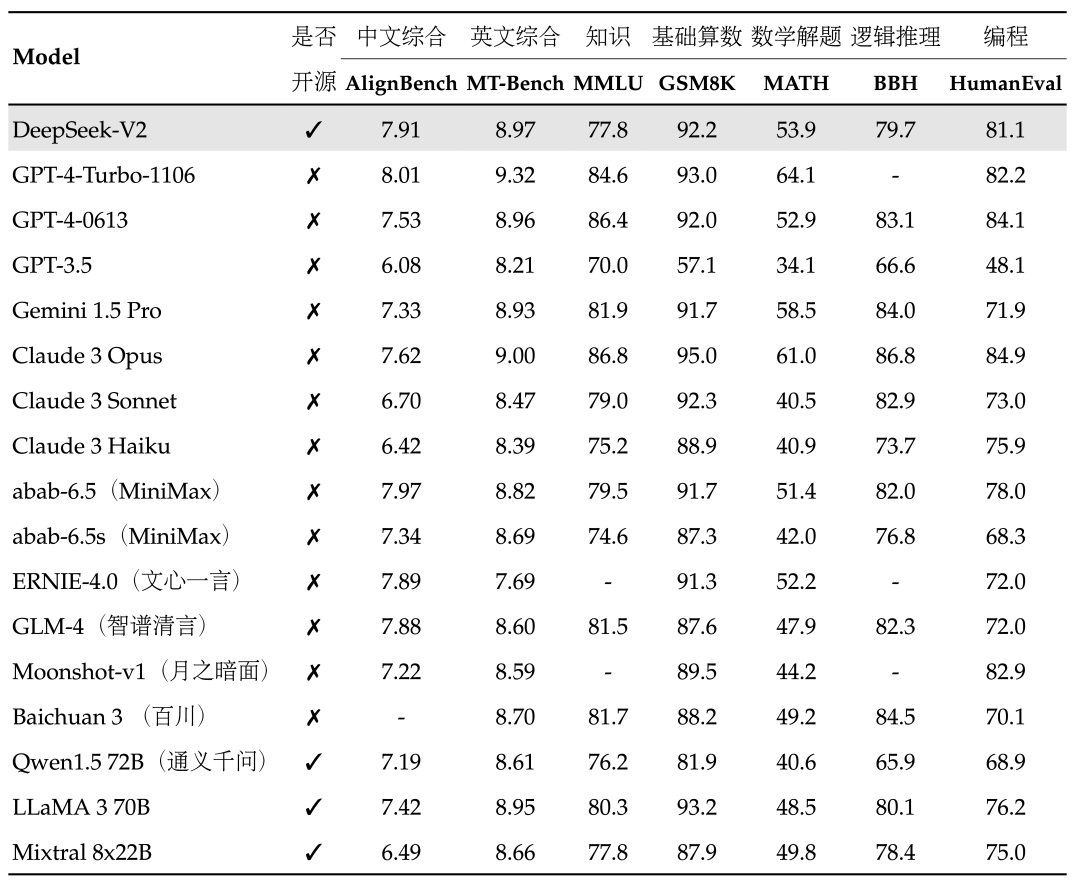
與此同時(shí),DeepSeek-V3相比其他前沿大模型,性能卻足以比肩乃至更優(yōu)。
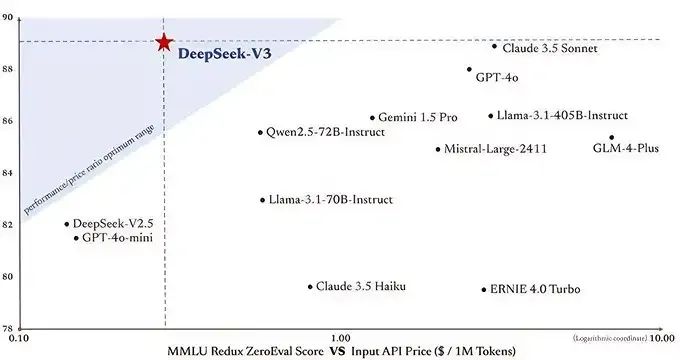
DeepSeek-V3與其他大模型性能對(duì)比
其中,這種設(shè)計(jì)使得模型在性能和效率上實(shí)現(xiàn)了完美平衡,在多項(xiàng)模型測(cè)評(píng)中,DeepSeek-V3不僅超越了Llama 3.1 405B等頂級(jí)開源模型,更在代碼、數(shù)學(xué)、長(zhǎng)文本處理等領(lǐng)域,與GPT-4o和Claude 3.5 Sonnet等閉源模型分庭抗禮。
其次,通過671B的總參數(shù)量,在每個(gè)token激活37B參數(shù)的精準(zhǔn)控制下,DeepSeek-V3用14.8萬(wàn)億高質(zhì)量多樣化token,構(gòu)建出了一個(gè)能夠超越所有開源模型,直逼GPT-4和Claude-3.5的AI巨人。
另外,在基礎(chǔ)理解能力測(cè)試中,DeepSeek-V3與Claude-3.5模型面對(duì)中文腦筋急轉(zhuǎn)彎“小明的媽媽有三個(gè)孩子”的問題,DeepSeek V3表現(xiàn)出色,不僅答對(duì)還進(jìn)行了自我驗(yàn)證。但在英文雙關(guān)語(yǔ)“April Fool's Day”的測(cè)試中則略顯不足,未能理解其中的語(yǔ)言巧思,而Claude3.5Sonnet則輕松應(yīng)對(duì)。
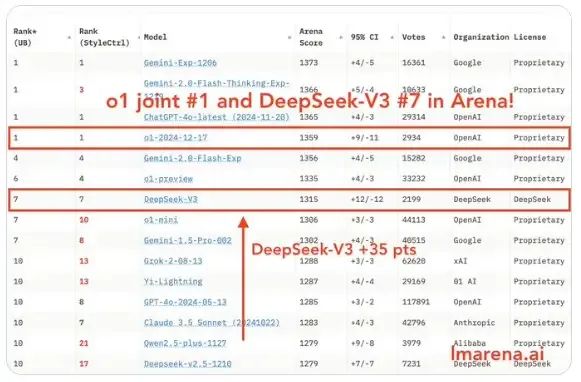
DeepSeek-V3與Claude-3.5實(shí)測(cè)對(duì)比
除此之外,DeepSeek自言,這得益于采用了Multi-head Latent Attention (MLA)和DeepSeek MoE架構(gòu),實(shí)現(xiàn)了高效的推理和經(jīng)濟(jì)高效的訓(xùn)練。
Multi-head Latent Attention (MLA):MLA 通過對(duì)注意力鍵和值進(jìn)行低秩聯(lián)合壓縮,減少了推理時(shí)的 KV 緩存,同時(shí)保持了與標(biāo)準(zhǔn)多頭注意力(MHA)相當(dāng)?shù)男阅堋?/p>
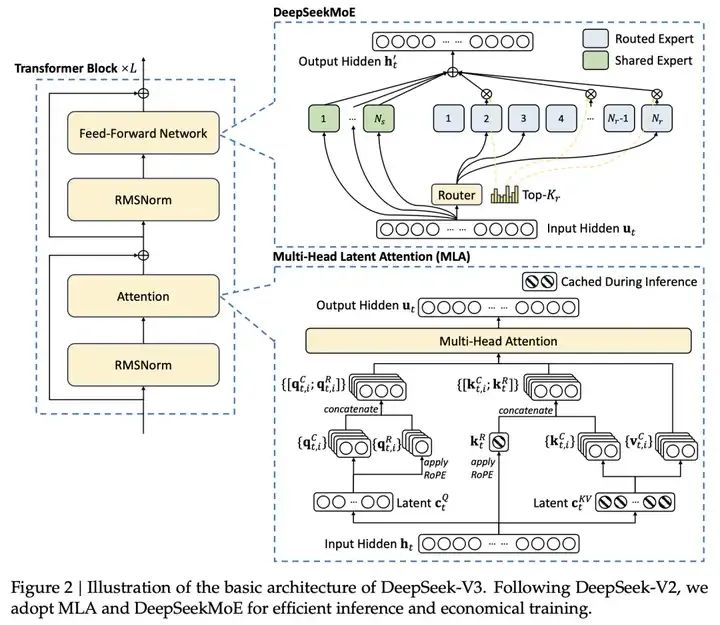
DeepSeek-V3 的核心亮點(diǎn)
DeepSeekMoE:DeepSeekMoE 采用了更細(xì)粒度的專家分配策略,每個(gè) MoE 層包含 1 個(gè)共享專家和 256 個(gè)路由專家,每個(gè)令牌激活 8 個(gè)專家,確保了計(jì)算的高效性。
因此,在系統(tǒng)架構(gòu)層面,DeepSeek就使用了專家并行訓(xùn)練技術(shù),通過將不同的專家模塊分配到不同的計(jì)算設(shè)備上同時(shí)進(jìn)行訓(xùn)練,提升了訓(xùn)練過程中的計(jì)算效率。
DeepSeek探索出一個(gè)精妙的解決策略,不等到最后再算總和,而是每加128個(gè)數(shù)就把當(dāng)前結(jié)果轉(zhuǎn)移到科學(xué)計(jì)算器上繼續(xù)計(jì)算。其過程不影響速度,此技術(shù)利用了H800 GPU的特點(diǎn):就像有兩個(gè)收銀員,當(dāng)一個(gè)在結(jié)算購(gòu)物籃的同時(shí),另一個(gè)便可繼續(xù)掃描新商品。
這一策略使得模型訓(xùn)練速度大幅提升,畢竟核心計(jì)算能提升100%的速度,而顯存使用減少也非常明顯,并且模型最終的效果精度損失能做到小于0.25%,幾乎無(wú)損。
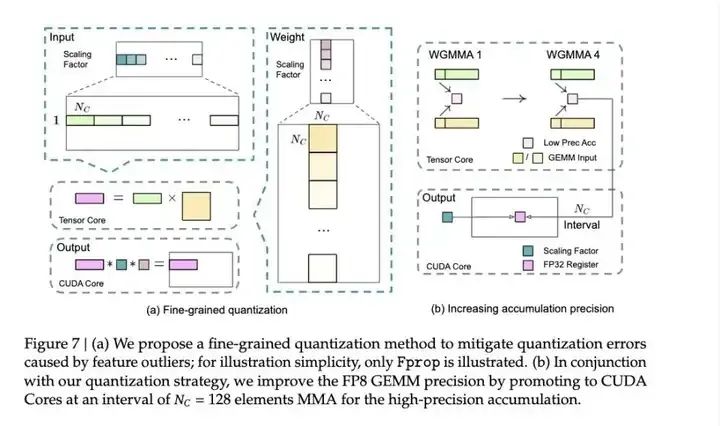
DeepSeek 提出的誤差積累解決方法
但由于DeepSeek“大方”開源,Open AI水靈靈地被網(wǎng)友cue進(jìn)行橫向?qū)Ρ龋幸环N被push的支配感。
Scale AI創(chuàng)始人亞歷山大·王 (Alexander Wang)更表示,DeepSeek-V3帶來的辛酸教訓(xùn)是:當(dāng)美國(guó)休息時(shí),中國(guó)在工作,以更低的成本、更快的速度迎頭趕上,變得更強(qiáng)。
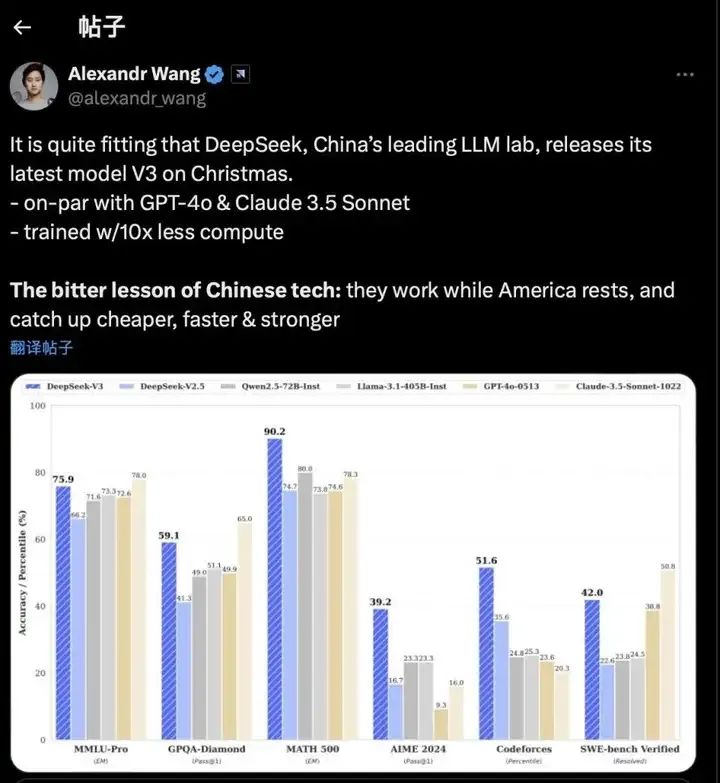
圖源:X平臺(tái)
簡(jiǎn)言之,這種劇變深刻折射出AI領(lǐng)域的變革。在2023年,超越GPT-4還是一個(gè)值得載入史冊(cè)的重大突破,轉(zhuǎn)眼至2024年,這一成就已然演變?yōu)楹饬宽敿?jí)AI模型的基準(zhǔn)線。
而剛到來的2025年,DeepSeek用行動(dòng)說明,中國(guó)大模型創(chuàng)業(yè)者,共同參與這場(chǎng)全球創(chuàng)新AI競(jìng)賽中。
由于篇幅受限,本次的DeepSeek V3就先介紹這么多......
想了解更多半導(dǎo)體行業(yè)動(dòng)態(tài),請(qǐng)您持續(xù)關(guān)注我們。
-
開源
+關(guān)注
關(guān)注
3文章
3381瀏覽量
42604 -
LLM
+關(guān)注
關(guān)注
0文章
297瀏覽量
357
原文標(biāo)題:DeepSeek-V3橫空出世,GPT-4時(shí)代終結(jié)?
文章出處:【微信號(hào):奇普樂芯片技術(shù),微信公眾號(hào):奇普樂芯片技術(shù)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
采用FP8混合精度,DeepSeek V3訓(xùn)練成本僅557.6萬(wàn)美元!
談?wù)?b class='flag-5'>DeepSeek-v3提到的基礎(chǔ)設(shè)施演進(jìn)
雷軍千萬(wàn)年薪挖角95后AI天才少女 DeepSeek開源大模型DeepSeek-V2關(guān)鍵開發(fā)者之一羅福莉
國(guó)產(chǎn)大模型發(fā)展的經(jīng)驗(yàn)與教訓(xùn)

中國(guó)AI企業(yè)創(chuàng)新降低成本打造競(jìng)爭(zhēng)力模型
零一萬(wàn)物正式開源Yi-Coder系列模型 PerfXCloud火速支持等你體驗(yàn)!
PerfXCloud順利接入MOE大模型DeepSeek-V2
大模型發(fā)展下,國(guó)產(chǎn)GPU的機(jī)會(huì)和挑戰(zhàn)

斯坦福團(tuán)隊(duì)抄襲國(guó)產(chǎn)大模型,主要責(zé)任人失聯(lián)
國(guó)產(chǎn)RISC-V芯片性能穩(wěn)定嗎?
Meta推出最強(qiáng)開源模型Llama 3 要挑戰(zhàn)GPT
國(guó)產(chǎn)GPU在AI大模型領(lǐng)域的應(yīng)用案例一覽






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論