 集合通信與AI基礎架構
集合通信與AI基礎架構
人工智能集群的性能,尤其是機器學習訓練集群,受到神經網絡處理單元NPUs(即GPU或TPU)之間并行計算能力的顯著影響。在我們稱為縱向擴展scale-up和橫向擴展scale-out設計中,NPUs之間網絡的特性成為定義整個系統性能的關鍵因素之一。通過定義不同的并行策略,NPUs需要定期相互交換數據,對模型的各個層輸出,或者梯度進行數據通信,從而更快速地完成前向和反向的訓練過程。
根據并行方案和機器學習框架的具體細節,數據通信的要求可能會有所不同。通常,NPUs之間的數據傳輸被稱為集合通信。集合通信原理已將其形式化為幾種類型,具體取決于數據的初始和最終位置,以及是否需要在過程中執行數學運算。常用的類型包括廣播和收集、ReduceScatter和AllGather、AllReduce和AlltoAll。操作名稱中存在“Reduce”關鍵字表示該操作對數據進行計算。
集合通信算子
集合通信可以通過多種算法來實現。其中一些算法較為簡單,因此性能較低;有些算法利用操作的性質,通常是網絡拓撲,完成得更快。AllReduce的知名算法包括單向環和雙向環、雙二進制樹以及Halving-Double算法,每種算法根據NPUs的數量以及它們如何互連,表現出不同的性能。
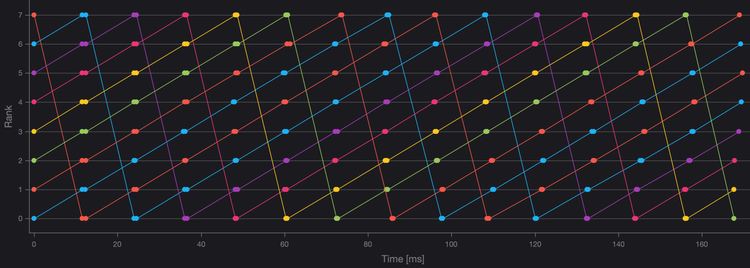
圖1、8個計算節點的AllReduce單向環
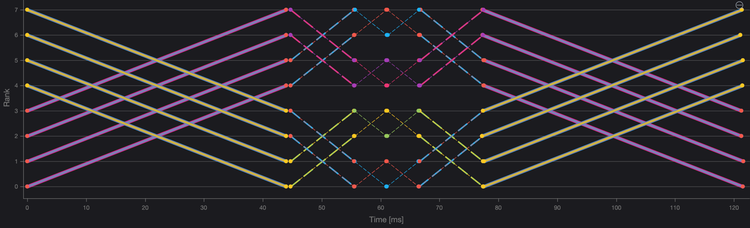
圖2、8個計算節點的AllReduce Halving-Double
Rank 與通信集群大小
在集合通信中,每個參與交換數據消息的單元稱為一個Rank。在大多數實際應用中,每個參與操作的NPU通常對應一個Rank。集合中所有Rank總數稱為通信集群大小,用n表示,Rank是使用從0開始的整數ID進行順序編號的,因此,最大的Rank ID是n - 1。在像廣播(Broadcast)和收集(Gather)這樣的集合通信操作中,有一個專門的發送者或接收者,稱為根,默認情況下使用Rank ID 0作為根。
集合通信庫
用于在人工智能集群中實現集合操作的軟件通常稱作“集合通信庫”(Collective Communication Library)。其中一個最早的庫 NCCL由NVIDIA開發。NCCL有多個衍生版本,其中一些是公開的,而其他一些則是私有的。
通信完成時間
集群完成集合通信操作的速度越快,訓練任務就能越快地在昂貴的NPUs上進行下一輪計算。因此,我們致力于改進的是操作完成時間,即集合完成時間(Collective Completion Time,CCT),我們通常以秒為單位進行測量。
通信數據大小
集合通信操作的目標是移動數據,因此數據的大小顯著影響操作所需的時間。在集合通信基準測試方法中,我們將一個Rank的通信數據大小定義為S,并以字節(B)為單位進行設置。
根據具體的操作和實現方式,集合通信算法會將數據大小S劃分為多個算法數據塊,每個塊的大小為c,并且每個塊在集合的Rank之間移動時都會遵循特定的路徑。塊的概念對于表達和理解集合操作算法的邏輯非常有用。
數據大小S參數具有幾個值得注意的特性:
在大多數集合通信操作中,所有Rank的數據大小S都是一致的。但也有一些例外,例如在廣播操作中,只有一個Rank提供輸入數據。在AlltoAll-v操作中,每個NPU的數據大小S可能不同。
每個Rank通過網絡發送的有效負載量D通常與S不同。這取決于具體的集合操作和所采用的算法。例如,在AlltoAll并行操作中,每個秩會保留一個大小為c = S/n的塊給自己,并通過網絡發送D = c * (n – 1)的數據。而在AllReduce環形操作中,每個秩將發送的數據量是D = 2 * c *(n – 1),因為這個操作是由ReduceScatter和AllGather兩個步驟組成的復合操作。
在真實的AI/ML訓練作業中,集合通信操作使用的數據大小受同一作業內部和不同作業之間的多種因素影響。由于AI集群基礎設施在其生命周期內需要支持不斷變化的作業,因此我們需要了解集合通信操作的性能如何隨數據大小變化。這就是為什么集合通信基準測試方法會遍歷不同的數據大小,以測量每個S值的關鍵指標的主要原因。
在AI集群中,大多數操作移動的是位于與NPUs直接連接的內存中的數據,而不是CPU內存中的數據。因此,我們可以通過檢查現代NPUs的內存量來確定S的上限,這樣做的實際意義在于基準測試。以NVIDIA H100 SXM為例,它擁有80GB的內存。由于這部分內存需要在AI模型的權重、訓練數據和梯度之間共享,因此在這種情況下,32GB可能是一個實際的數據大小限制。
算法帶寬
集合通信操作領域的研究人員不斷發現新的算法,這些算法顯著提高了集合通信完成時間(CCT),這通常歸功于對底層網絡拓撲的理解——即拓撲感知。由于CCT直接依賴于數據大小S,而S是特定于任務的,因此引入一個新的指標來衡量算法性能是很有幫助的,這個指標可以在不同的任務之間進行比較。類似于我們通過速度而不是旅行時間來比較汽車的性能,這個指標就是算法帶寬(algbw)。它定義為數據大小S除以CCT,并以千兆字節每秒(GB/s)為單位進行測量。
請注意,盡管飛機的平均速度高于汽車,但由于等待時間,我們并不使用它們進行短距離旅行。類似地,當數據大小太小,無法完全加載網絡時,CCT的一大部分時間將花費在啟動和停止數據傳輸上。在這種情況下,algbw將不是一個有意義的指標,因為它會在不同的數據大小之間顯著變化。在比較哪個算法性能更好時,您可能需要回到使用CCT。
為了說明這一點,圖3是一個基準測試輸出,其中在較小的數據大小上,CCT保持在7毫秒左右,但algbw每次數據大小翻倍時都會翻倍。另一方面,在較大的數據大小上,algbw趨于穩定在25GB/s,而CCT則隨著數據大小的增加而繼續增加。
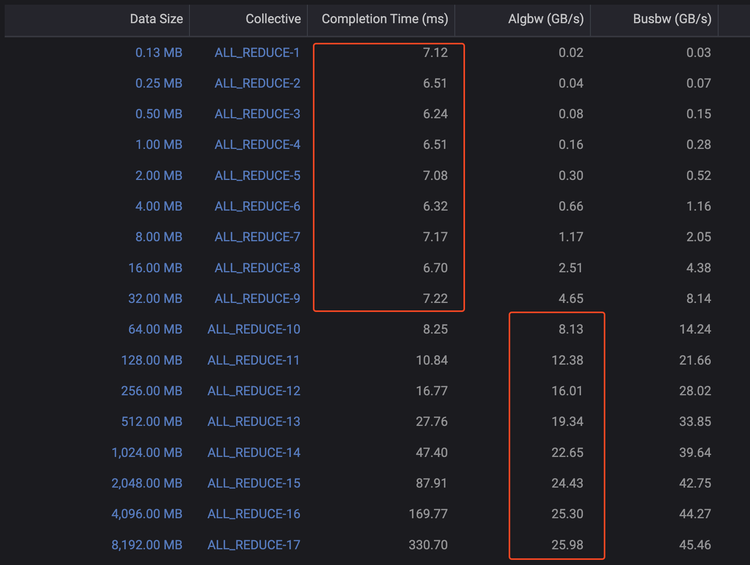
圖3、不同集合通信大小下的算法帶寬表現
注意:由于算法在執行時實際傳輸的有效負載D與數據大小S之間的區別,將算法帶寬(algbw)與網絡接口的理論速度進行比較是不恰當的。
總線帶寬
雖然CCT和algbw依賴于數據大小S,但通信集群大小n的影響就不那么明顯了。根據算法的不同,這種依賴性可能更直接或更間接。例如,對于AlltoAll并行操作,在保持相同數據大小的情況下增加集合中的Rank數,會導致算法數據塊c = S / n變小。因此,更大的帶寬比例會浪費在數據包頭上,CCT大約會增加相同的比例。相比之下,對于AllReduce環形操作,通信集群中的Rank數越多,每個數據塊為了完成環形需要穿越的跳數就越多,導致CCT線性增加。我們需要一個指標來描述通信集群的性能,這個指標與訓練作業的大小無關。
為了這個目的,我們可以想象由集合通信算法定義的數據塊移動類似于汽車在城市中的移動,其中停車場、車道、道路和交叉口分別代表內存、NIC、電線和開關,而汽車就是數據塊。當與城市街道相比較時,這里唯一真正的延伸是所有數據塊都沿著完全相同的模式移動,并且不會分心。有了這個類比,我們可以很有把握地猜測,汽車到達最終目的地所需的時間將很大程度上受到其路徑上最慢路段的影響——瓶頸路段。當瓶頸路段達到其容量時,需要通過的汽車數量翻倍,它們通過所需的時間也將翻倍。換句話說,瓶頸的峰值吞吐量不依賴于城市中停車場的數量(通信集群大小n)或汽車的數量(通信數據大小S)。
這個類比的另一個用處是,盡管瓶頸的峰值吞吐量不依賴于相鄰街道和汽車移動的模式(拓撲和算法),但所有汽車完成旅行所需的時間將非常取決于它們所采取的路線,以及它們在城市中的數量。
總結來說,只要汽車(數據塊)以峰值數量穿越瓶頸,達到其容量(帶寬),它將決定我們城市基礎設施(AI集群)的性能——有效負載的移動速率無法超越系統中瓶頸的峰值容量。描述AI基礎設施對集合通信操作瓶頸的指標稱為總線帶寬(busbw),并以千兆字節每秒(GB/s)為單位測量。
對比理想CCT
一些集合通信基準測試工具無法深入了解底層的L1-4 OSI堆棧,因此無法在測試過程中提供網絡利用率的信息,也無法判斷是否還有優化空間。在創建AI Data Center Builder軟件時,Keysight團隊考慮到了這一點,并融入了對底層的洞察。KAI Collective Benchmarks應用程序會計算每個集合通信算法的理想CCT,并將其與實際測量得到的CCT值進行比較。因此,由KAI Collective Benchmarks產生的數據包含了與理想CCT值的比較,指標形式為百分比。
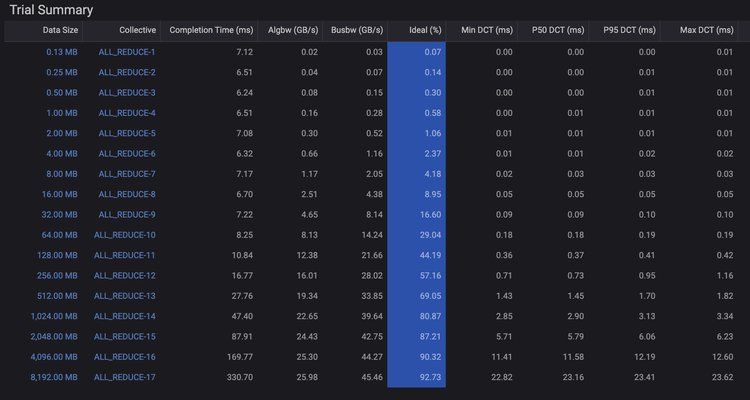
圖4、KAI Collective Benchmarks 綜合結果中的理想百分比
數據塊完成時間分布
許多集合通信算法在每次Rank移動數據塊時都展現出對稱性。這是一個重要結論:當系統為每個數據塊分配相等帶寬時,即實現了帶寬公平性,此時性能最佳。缺乏公平性會導致數據移動的尾延遲增加。一種評估公平性的方法是測量每個數據塊的完成時間(DCT),并報告最小值、最大值,以及第50和第95百分位數。在具有帶寬公平性的系統中,最小和最大DCT值應當較為接近。如果它們相差較大,您可以通過檢查P50和P95的結果來判斷異常值是更多地出現在快速還是慢速一側。這些指標對于網絡工程師來說非常熟悉,并且比學術文獻中提到的其他公平性指標更容易在團隊和組織之間使用。
請注意,只有在集合算法中所有數據塊的大小相等時,報告DCT百分位數才是有意義的。
結論
集合通信操作的基準測試是理解分布式AI基礎設施性能極限的基礎性方法。它是AI集群設計和優化過程中尋找改進方案的有用工具。無論是開源還是商業實現,這些工具都圍繞著一組共同的輸入參數和測量指標進行操作。在本文中,我們提供了這些參數的定義,并詳細闡述了它們的含義,以助力術語的標準化。
術語和定義一覽表
術語
Collective Operation
定義
集合通信算子,這些通信模式涉及一組進程間的數據交換,是擴展型AI/ML集群中網絡通信的基本單元,負責在GPU之間移動數據。
單位/值
Broadcast
Gather
Scatter
ReduceScatter
AllGather
AllReduce
AlltoAll
術語
Rank
定義
在集合通信操作中交換消息的端點的標識符。通常,一個Rank代表一個GPU。在某些情況下,一個GPU可以有多個Rank。
單位/值
從0開始的整數
術語
Collective Size(n)
定義
集合通信中Rank的數量
單位/值
2或大于2的整數
術語
Data Size(S)
定義
集合通信操作中,單個Rank輸入的數據大小
單位/值
Bytes
術語
Collective Completion Time (CCT)
定義
集合通
集合通信操作完成所需的時間,尤其適用于比較不同集合通信算法在處理不同數據大小時的性能表現。
單位/值
秒
術語
Algorithm Bandwidth (algbw)
定義
一種用于比較不同數據大小下集合通信算法性能的指標。算法帶寬(algbw)= 數據大小S / 集合完成時間(CCT)
單位/值
GB/s
術語
Bus Bandwidth (busbw)
定義
描述了集合通信算法在AI基礎設施中的瓶頸性能。該公式是特定于算法的。
單位/值
GB/s
術語
Ideal %
定義
將測量的集合通信完成時間(CCT)與給定算法、傳輸開銷和網絡接口速度的最小理論值進行比較。
單位/值
秒
術語
Data chunk Completion Time (DCT)
定義
在兩個Rank之間傳輸一個數據塊所需的時間。測量集合通信操作中每個數據塊完成時間(DCT)的值,并報告最小值、最大值、第50百分位數(P50)和第95百分位數(P95)有助于理解系統中的帶寬公平性。
單位/值
秒
關于是德科技
是德科技(NYSE:KEYS)啟迪并賦能創新者,助力他們將改變世界的技術帶入生活。作為一家標準普爾 500 指數公司,我們提供先進的設計、仿真和測試解決方案,旨在幫助工程師在整個產品生命周期中更快地完成開發和部署,同時控制好風險。我們的客戶遍及全球通信、工業自動化、航空航天與國防、汽車、半導體和通用電子等市場。我們與客戶攜手,加速創新,創造一個安全互聯的世界。
-
通信
+關注
關注
18文章
6042瀏覽量
136138 -
gpu
+關注
關注
28文章
4752瀏覽量
129056 -
AI
+關注
關注
87文章
31097瀏覽量
269430 -
人工智能
+關注
關注
1792文章
47409瀏覽量
238923 -
機器學習
+關注
關注
66文章
8424瀏覽量
132765
原文標題:集合通信與AI基礎架構
文章出處:【微信號:是德科技KEYSIGHT,微信公眾號:是德科技KEYSIGHT】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【CC3200AI實驗教程14】瘋殼·AI語音人臉識別-AI人臉系統架構
中國聯通正式啟用OSS融合通信系統進行擴容
面向5G的光纖無線融合通信技術






 工商網監
工商網監
評論