 華為、理想、特斯拉、商湯的世界模型是做什么用的
華為、理想、特斯拉、商湯的世界模型是做什么用的
最近世界模型(World Model)很火,甚至有人說世界模型是終極自動駕駛解決方案,實際上它只是端到端大模型的一種,和VLM沒有本質區別。目前的研究基本都集中在用世界模型生成視頻或其他連續時間序列上的可視化數據,再用這些視頻訓練傳統或端到端的自動駕駛模型,幾乎沒有人研究直接用世界模型做自動駕駛的。即便是視頻生成,也還是處于實驗室的學術研究階段。
圖片來源:網絡
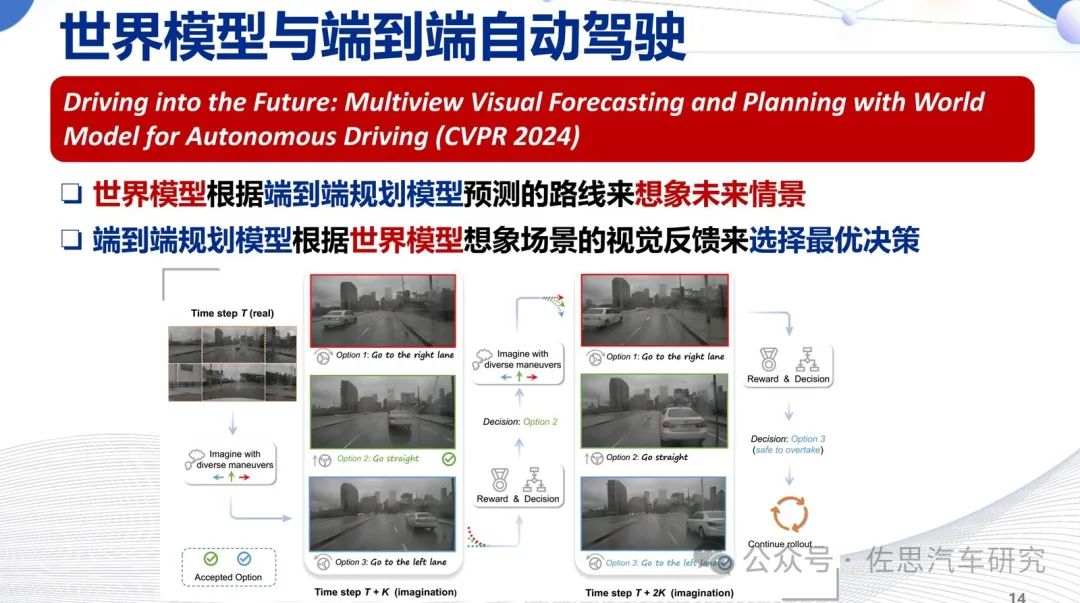
為什么要做世界模型,它實際上是端到端自動駕駛的閉環仿真,世界模型可以看做VLM的逆向工程,用prompt這些文字提示輸出視頻。世界模型和端到端模型是一個互相幫助的過程,世界模型生成的視頻交給車端大模型,車端大模型通過它的規劃執行接下來的動作,接下來的動作產生新的場景、新的視角,再通過世界模型繼續生成新的數據,進行閉環仿真的測試。
圖片來源:網絡
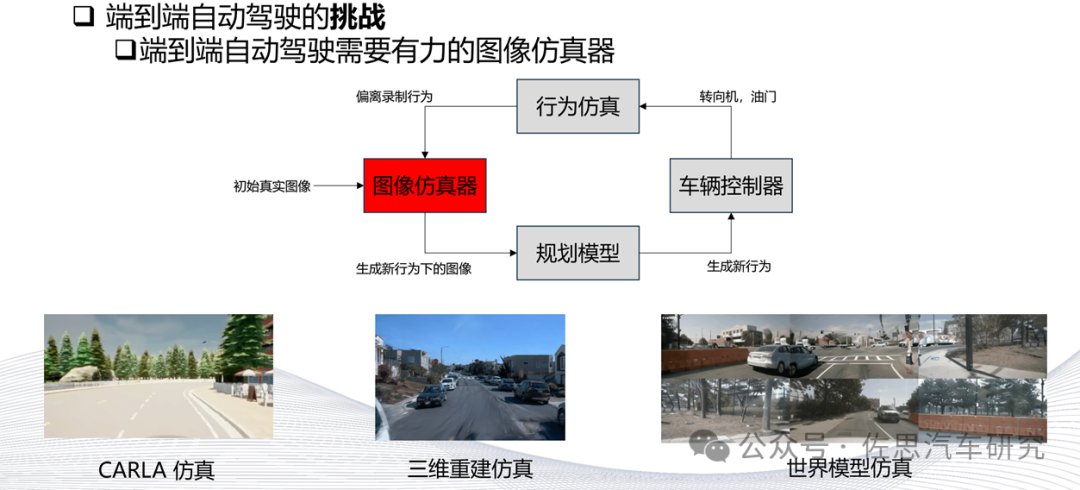
不同于CARLA這些測試型仿真,世界模型是訓練型仿真,它要達到海量規模才有價值。
圖片來源:網絡
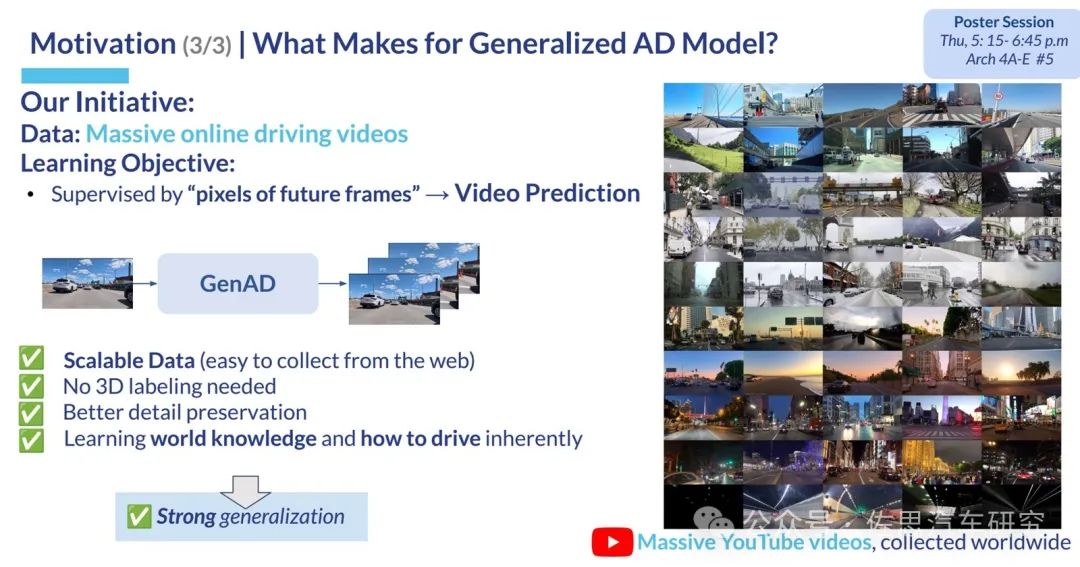
世界模型生成視頻可以是自監督的,無需3D標簽,可以使用海量網絡汽車駕駛視頻。最重要的是它可以生成現實世界中極難采集到的長尾視頻,這是其核心價值。換句話說它生成的視頻價值是現實世界采集到的視頻數據的價值百倍以上,但成本是其1%不到。

圖片來源:網絡
所謂世界模型就是視頻生成加prompt控制。視頻生成有四大類型,包括基于對抗網絡GAN的,基于擴散模型的,基于自回歸模型(基本上就是transformer)和基于掩碼的。其中,擴散模型再分為Stable Video Diffusion (SVD)和Stable Diffusion (SD)兩種,它們還有一種共同的稱呼即隱擴散模型(Latent Diffusion Model, LDM)。目前也有結合diffusion和transformer的模型即DiT,但它本質上還是擴散模型,只不過用transformer替換了擴散模型中的Unet。大名鼎鼎的SORA則是復合型,Sora模型的核心組成包括Diffusion Transformer(DiT)、Variational Autoencoder(VAE)和Vision Transformer(ViT)。DiT負責從噪聲數據中恢復出原始的視頻數據,VAE用于將視頻數據壓縮為潛在表示,而ViT則用于將視頻幀轉換為特征向量以供DiT處理。據說特斯拉就是用的SVD。
基于世界模型的端到端訓練

圖片來源:網絡
生成視頻的質量分為兩部分,一是視頻本身的準確度,主要指標有三個,一個是FID/FVD,另一個是CLIP得分。FID(Fréchet Inception Distance)是一種用于評估生成模型,尤其是在圖像生成任務中,生成圖像的質量和多樣性的指標。它通過比較生成圖像與真實圖像在特定空間內的分布來工作。這個特定的空間通常是通過預訓練的Inception網絡的某一層來定義的。對于生成圖像集和真實圖像集,分別通過Inception網絡(通常是Inception V3模型)計算它們的特征表示。這一步驟會得到每個圖像集的特征向量,計算每個集合的特征向量的均值和協方差矩陣,并做對比,都是高等數學的課程,這里就不展開說了。FVD和FID接近,相當于把FID的圖像特征提取網絡換成視頻特征提取網絡,其他都差不多。最后一個是北大提出來的,就是Trajectory Agent IoU (NTA-IoU),與設定軌跡的交并比,Novel Trajectory Lane IoU (NTL-IoU),與設定車道的交并比。
二是視頻本身的長度、幀率和分辨率,要盡可能與傳統自動駕駛訓練視頻達到一致的幀率和分辨率。
目前世界模型生成視頻的方向有兩個,一個是追求更長、更多視角、更高分辨率,代表作有商湯的《InfinityDrive: Breaking Time Limits in Driving World Models》,華為的《MagicDriveDiT: High-Resolution Long Video Generation》,Wayve的GAIA-1,地平線的DrivingWorld。另一個是追求近乎真實的3D場景渲染,理想在這方面情有獨鐘,理想的Street Gaussians、ReconDreamer、DriveDreamer4D都是這個方向,也是這個領域的主要代表作。
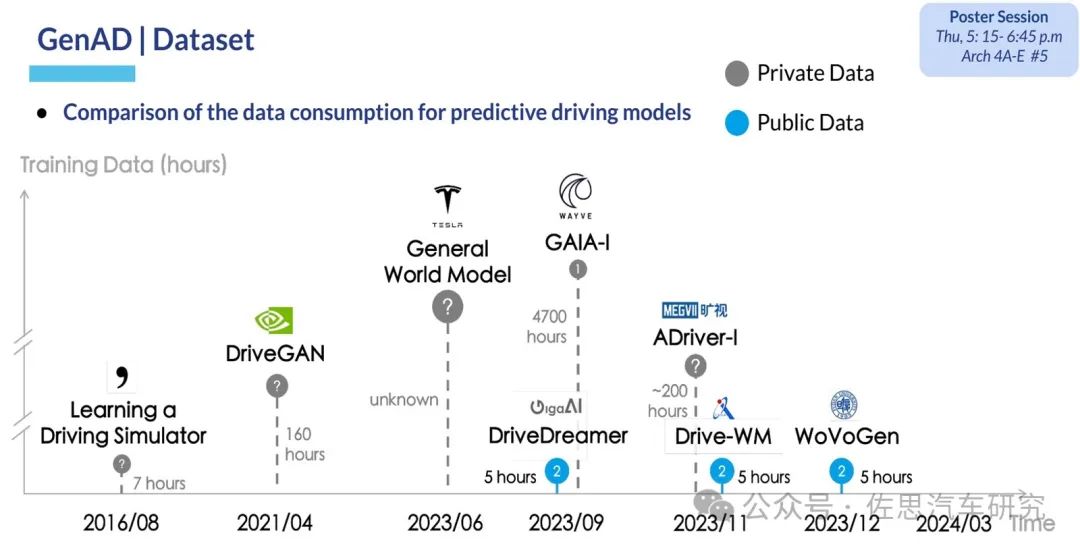
圖片來源:網絡
特斯拉用的什么世界模型,自然是未知,也許它根本就沒用世界模型。
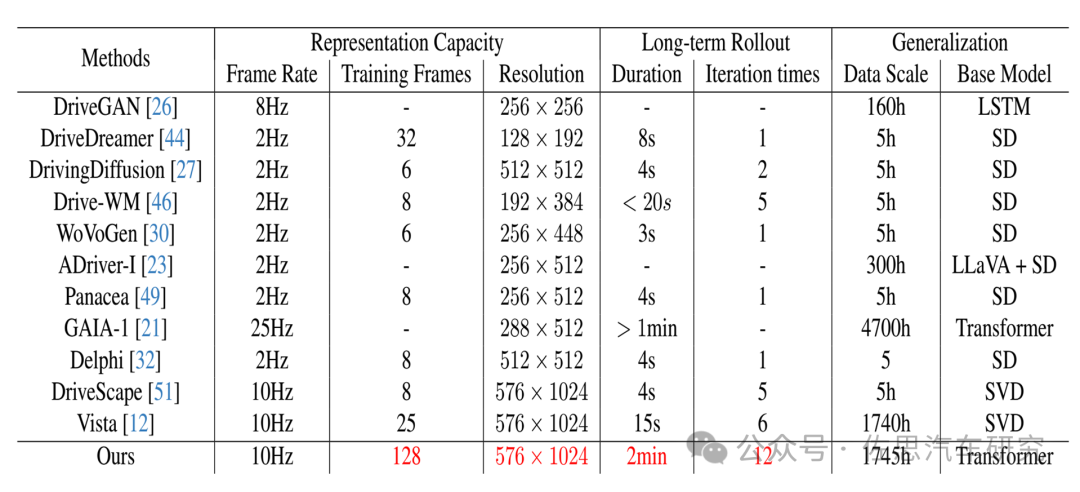
注:“Ours”指的就是InfinityDrive
圖片來源:商湯論文《InfinityDrive: Breaking Time Limits in Driving World Models》

圖片來源:華為的MagicDriveDiT
華為不僅能生成超高分辨率,還能生成多個角度的視頻。
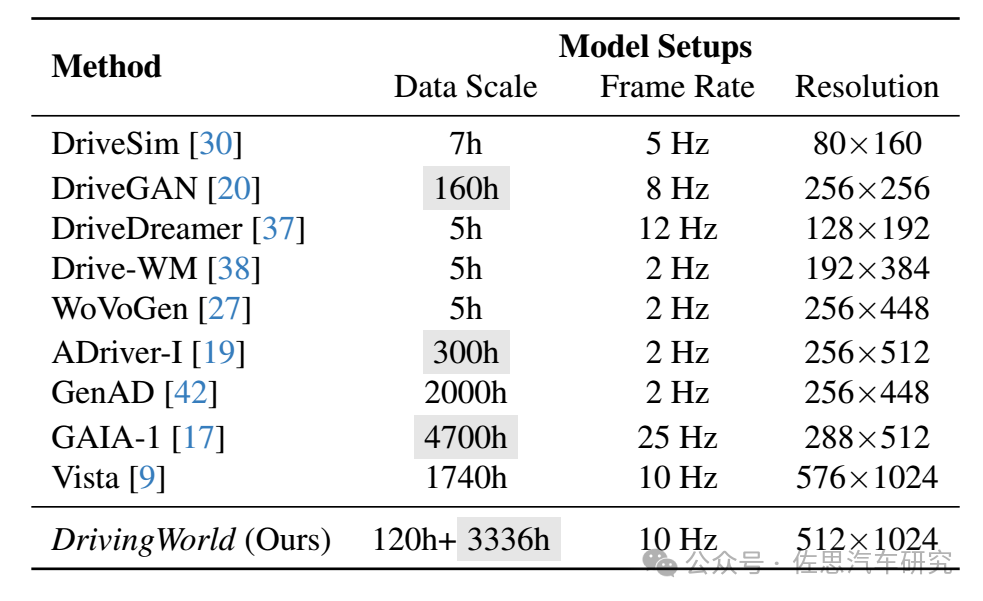
數據來源:地平線的DrivingWorld,數據尺度比較大,分辨率也很高
我們再來看另一條3D渲染線,它的核心應該說有點偏離世界模型的本來意義了,它是追求接近真實的3D渲染,基本上是理想汽車的獨角戲。三個比較有價值的模型基本都有理想汽車的身影,第一個是Street Gaussians: Modeling Dynamic Urban Scenes with Gaussian Splatting,浙江大學和理想汽車合作,九位作者,其中來自理想汽車的作者占四位。第二個是DriveDreamer4D: World Models Are Effective Data Machines for 4D Driving Scene Representation,由極佳科技聯合中國科學院自動化研究所、理想汽車、北京大學、慕尼黑工業大學等單位提出,十二位作者兩位來自理想汽車。第三個是ReconDreamer: Crafting World Models for Driving Scene Reconstruction via Online Restoration,總共十六位作者,其中來自理想汽車的多達八位,來自極佳科技的有六位。
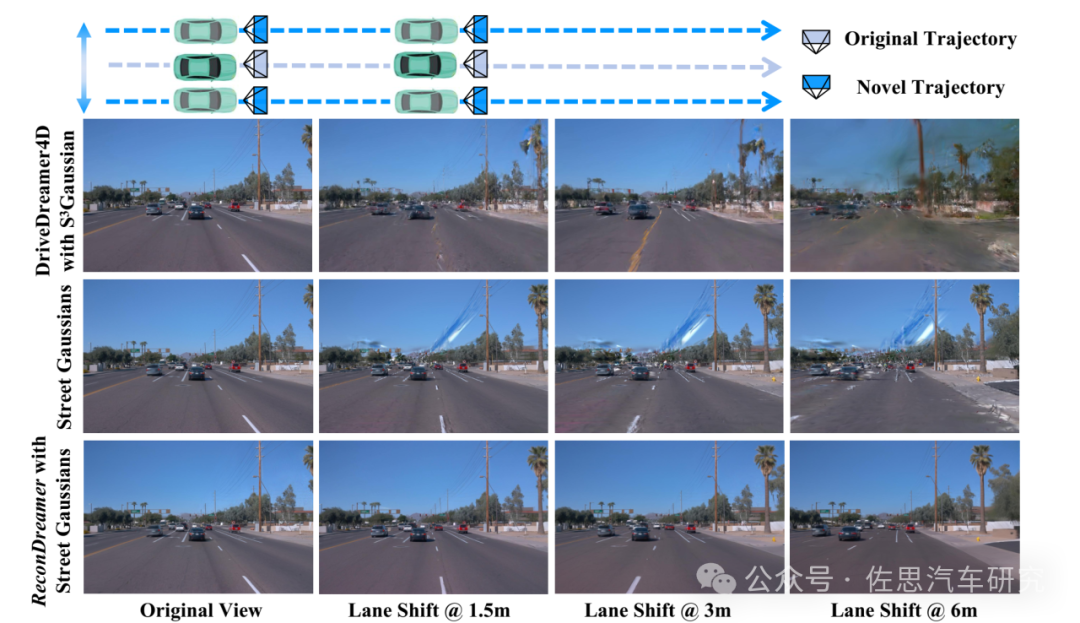
圖片來源:論文《ReconDreamer: Crafting World Models for Driving Scene Reconstruction via Online Restoration》
上圖可以看到,理想汽車與極佳科技合作的最新成果就是ReconDremaer,純粹StreetGaussians的話,一旦偏離中心視角,容易出現空洞或鬼影,車道線也出現扭曲。
ReconDreamer整體框架

圖片來源:論文《ReconDreamer: Crafting World Models for Driving Scene Reconstruction via Online Restoration》
除了生成視頻,還有生成激光雷達點云視頻,如理想與澳門大學合作的《OLiDM: Object-aware LiDAR Diffusion Models for Autonomous Driving》,還有生成語義分割圖的《SynDiff-AD: Improving Semantic Segmentation and End-to-End Autonomous Driving with Synthetic Data from Latent Diffusion Models》。
OLiDM的整體框架
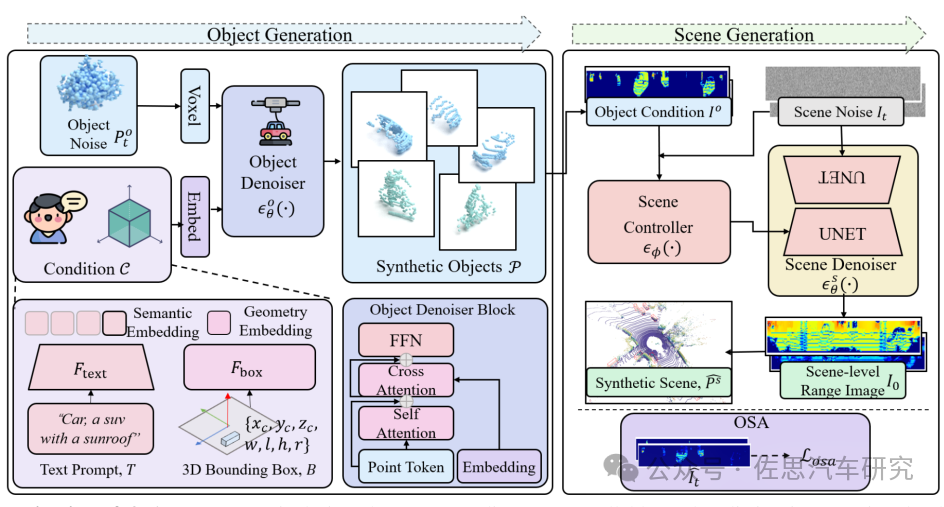
圖片來源:論文《OLiDM: Object-aware LiDAR Diffusion Models for Autonomous Driving》
上圖中,世界模型生成激光雷達點云視頻,再拿這個去訓練激光雷達的識別能力。
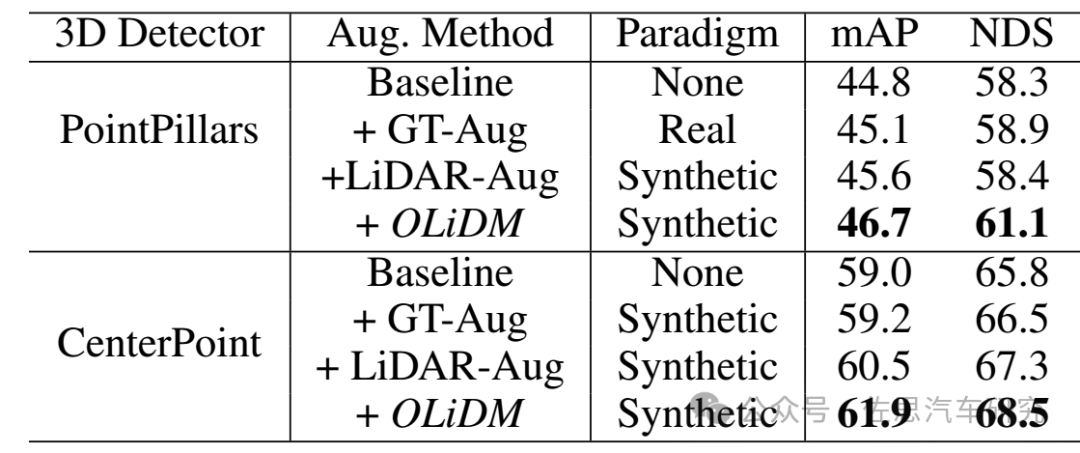
數據來源:論文《OLiDM: Object-aware LiDAR Diffusion Models for Autonomous Driving》。
OLiDM的效果,能有兩三個點的提升,已經是非常難得了,現在在nuScenes上0.001的提升都需要一年半以上的時間。
世界模型一點也不神秘,不僅是端到端自動駕駛,它對傳統自動駕駛也有明顯的提升,自動駕駛的數據成本也大幅度下降至少95%以上,那些所謂影子模式變得毫無價值,實際上沒有世界模型生成視頻,影子模式本身也毫無價值,這也是馬斯克說他用擴散模式生成視頻的原因,如果影子模式真有價值,何必多此一舉?
-
華為
+關注
關注
216文章
34496瀏覽量
252319 -
特斯拉
+關注
關注
66文章
6320瀏覽量
126662 -
商湯
+關注
關注
0文章
56瀏覽量
3963
原文標題:華為、理想、特斯拉、商湯的世界模型是做什么用的?
文章出處:【微信號:zuosiqiche,微信公眾號:佐思汽車研究】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
dac7624 data output timing是做什么用的?
TAS5611a的13腳14腳的晶振是做什么用的?
TAP3118和TPA3116開發板所處位置的電路是做什么用的?
BOOSTXL_BUCKCONV評估板上的高邊電流采樣電路,請問C10-C14都是做什么用的呢?
什么是理想元件?什么是電路模型
opa593的pspice模型里面為什么有很多別的器件呢?
商湯科技與泰國DTGO集團聯合發布泰語大模型

商湯科技發布“日日新SenseNova 5.0”大模型
Linux是做什么用的?
商湯科技新升級大模型,對標GPT-4 Turbo?
商湯SenseChat大模型成功通過與華為Atlas服務器的相互兼容性測試

SENT協議SPC功能是做什么用的?
華為的NFC功能是什么?手機NFC功能有什么用
填充膠是做什么用的?






 工商網監
工商網監
評論