 GPT架構及推理原理
GPT架構及推理原理
導讀
本篇是作者從開發人員的視角,圍繞著大模型正向推理過程,對大模型的原理的系統性總結,希望對初學者有所幫助。
引言
什么是人工智能?
清華大學出版社出版的《人工智能概論》中提出,人工智能是對人的意識、思維的信息過程的模擬。人工智能不是人的智能,但它能像人那樣思考,也可能超過人的智能。
基于這個設想,人工智能應當能夠執行通常需要人類智能的任務,如視覺感知、語音識別、決策和語言翻譯等工作。就像人一樣,可以看見、聽見、理解和表達。這涉及了眾多人工智能的分支學科,如計算機視覺(CV)、自然語言處理(NLP)、語音識別(VC)、知識圖譜(KG)等。

NLP語言模型的發展,引自《A Survey of Large Language Models》
NLP作為其中之一,其發展歷經了多個階段。在統計語言模型階段,模型利用馬爾科夫假設學會了如何進行預測。在神經語言模型的階段,我們通過詞嵌入的向量表示讓模型開始理解詞的語義,并通過神經網絡模型給人工智能裝上了神經元,讓模型開始“思考”。在預訓練語言模型階段,我們通過預訓練告訴語言模型,要先學習走路再去跑。而在如今的大語言模型階段,我們基于擴展法則認識到了了力大磚飛的重要性,并收獲了各種涌現能力的驚喜,為AGI的發展立下了一個新的里程碑。
如今大模型已經帶領NLP 領域走向了全新的階段,并逐步向其他AI領域擴展。LangChain的2024年Agent調研報告顯示,51.1%的企業已經在生產中使用Agent,78.1%的企業有計劃將Agent投入生產,AI的浪潮已經席卷而來。并且AI發展的步伐還在加快。模型方面,OpenAI在2024年12月的發布會上,推出了o1專業版,憑借其在后訓練階段的深度推理,使得模型在數學、編程、博士級問題上達到了人類專家的水平,相比于此前的大模型達到了斷層領先,近期國內Qwen推出了QwQ模型,月之暗面的KIMI推出了KIMI探索版,也都具有深度推理能力,國內外AI上的差距正在逐步縮短。應用方面,各家都在大力發展多模態AI,Sora、可靈等,讓視頻創意的落地成本從數十萬元降低到了幾十元,VLM的加持下的端到端自動駕駛也在大放異彩。
總而言之,我們仍然處在第四次科技革命的起點,業內預測在2025年我們可能會見證AGI(通用人工智能)的落地,并且還提出了ASI(超級人工智能)的概念,認為人類可能創造出在各個方面都超越人類智能的AI,AI很有可能帶領人類進入新的時代。
目光放回到大模型本身,對于開發人員而言,大模型的重要性,不亞于JAVA編程語言。大模型的推理原理,就像JVM虛擬機原理一樣,如果不了解,那么在使用大模型時難免按照工程化的思維去思考,這樣常常會遇到困難,用不明白大模型。比如為什么模型不按照提示詞的要求輸出,為什么大家都在用思維鏈。
而本篇是作者從開發人員的視角,圍繞著大模型的正向推理過程,對大模型的原理的系統性總結,希望對像我一樣的初學者有所幫助。文中會引入部分論文原文、計算公式和計算過程,同時會添加大量例子和解釋說明,以免內容晦澀難懂。篇幅較長難免有所紕漏,歡迎各位指正。
大語言模型架構
Transformer

鎮樓圖,來自萬物的起源《Attention is All You Need》
Transformer架構由Google在2017年發表的論文《Attention is All You Need》首次提出,它使用自注意力(Self-Attention)機制取代了之前在 NLP 任務中常用的RNN(循環神經網絡),使其成為預訓練語言模型階段的代表架構。
要澄清一點,注意力機制并不是由Transformer提出。注意力機制最早起源于計算機視覺領域,其思想在上世紀九十年代就已經被提出。在2014年的論文《Neural Machine Translation by Jointly Learning to Align and Translate》中注意力機制首次應用于NLP領域,結合了RNN和注意力機制,提出了序列到序列(Seq2Seq)模型,來改進機器翻譯的性能。Transformer的貢獻在于,它提出注意力機制不一定要和RNN綁定,我們可以將注意力機制單獨拿出來,形成一套全新的架構,這也就是論文標題《Attention Is All You Need》的來源。
在正式開始前,首先需要說明,什么是注意力機制?
在NLP領域,有三個基礎概念:
分詞(Tokenization):首先大模型會將輸入內容進行分詞,分割成一系列的詞元(Token),形成一個詞元序列。
詞元(Token):指將輸入的文本分割成的最小單位,詞元可以是一個單詞、一個詞組、一個標點符號、一個字符等。
詞嵌入(Embedding):分詞后的詞元將被轉換為高維空間中的向量表示,向量中包含了詞元的語義信息。
舉個例子,當我們輸入“我可以擁有一杯咖啡嗎?”時,首先通過分詞形成“我”、“可以”、“擁有”、“一杯”、“咖啡”、“嗎?”這幾個詞元,然后通過詞嵌入轉變成高維空間中的向量。
在向量空間中,每一個點代表一個實體或者概念,我們稱之為“數據點”。這些數據點可以代表著具體的單詞、短語、句子,他們能夠被具體地、明確地識別出來,我們稱之為“實體”;也可以不直接對應于一個具體的實體,而是表達一種對事物的抽象理解,我們稱之為“概念”。這些數據點在向量空間中的位置和分布反映了實體或概念之間的相似性和關系,相似的實體或概念在空間中會更接近,而不同的則相距較遠。其所在空間的每一個方向(維度)都代表了數據點的某種屬性或特征。這些屬性和特征是通過模型訓練獲得的,可能包括了“情感”、“語法”、“詞性”等方面,事實上由于這些屬性和特征是模型通過訓練進行內部學習的結果,他們的具體含義往往難以直觀解釋清楚。
當詞元被嵌入到向量空間中,每個詞元都會形成一個實體的數據點,此時這些數據點所對應的向量,就代表了詞本身的語義。但是在不同的上下文語境中,相同的詞也會有不同的語義。比如在“科技巨頭蘋果”、“美味的蘋果”這兩句話中,“蘋果”這個詞,分別代表著蘋果公司和水果。因此模型需要對原始向量“蘋果”,基于上下文中“科技巨頭”、“美味的”等信息,來進行數據點位置的調整,豐富其語義。換句話說,詞元與上下文中各個詞元(包括其自己)之間具有一定程度的“依賴關系”,這種關系會影響其自身的語義。
為了進一步解釋上述內容,我畫了一張圖幫助大家理解。如下圖是一個向量空間,我們假設其只有兩個維度,分別是“經濟價值”和“食用價值”。“科技巨頭”、“美味的”、“蘋果”在詞嵌入后,會在空間中分別形成自己的數據點,顯然“科技巨頭”相對于“美味的”的經濟價值屬性更明顯而食用價值的屬性更模糊。當我們輸入“科技巨頭蘋果”時,“蘋果”的含義會受“科技巨頭”的影響,其數據點的位置會向“科技巨頭”靠攏,在空間中會形成一個新的概念。
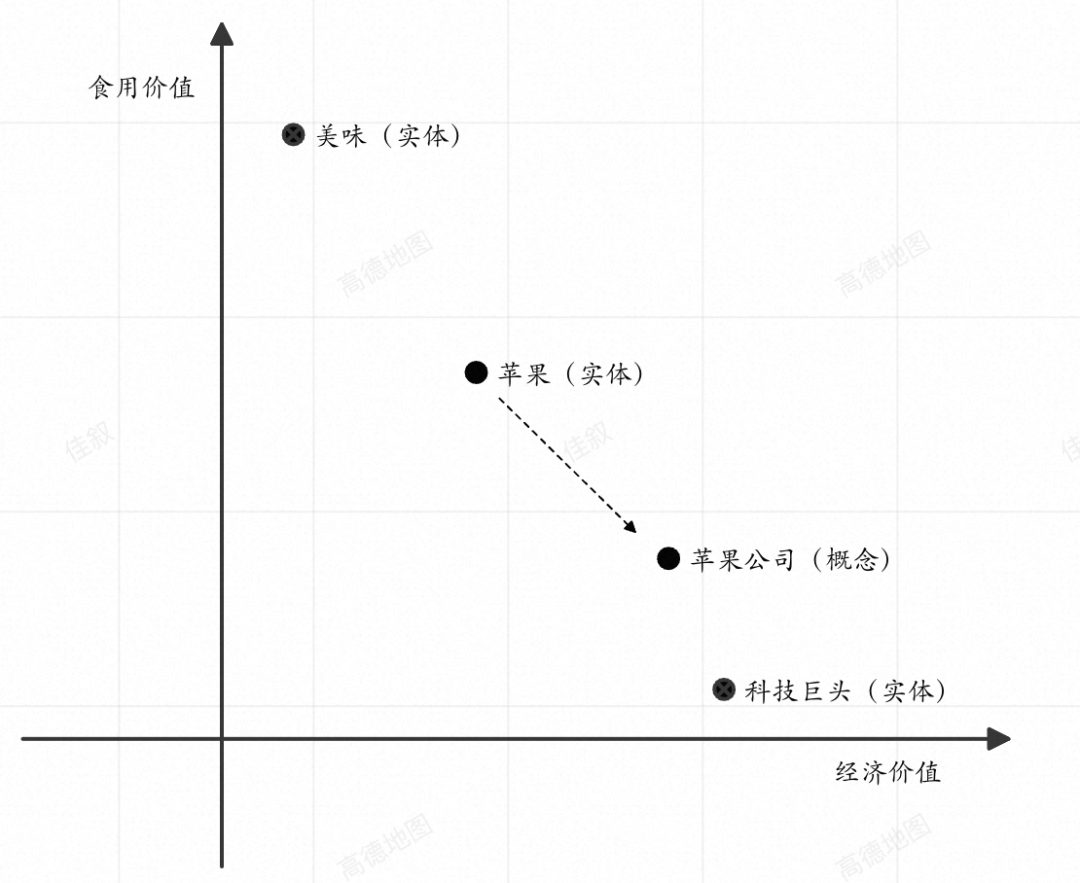
向量空間中的“科技巨頭蘋果”
每個詞元都需要捕捉自身與序列中其他詞元的依賴關系,來豐富其語義。在“我配擁有一杯咖啡嗎?”中,對于“配”而言,它依賴“我”作為其主語,這是一條依賴關系。對于“咖啡”而言,“一杯”是其量詞,這也是一條依賴關系。
這種關系不只會在相鄰的詞元之間產生,在論文中有個詞叫長距離依賴關系(long-range dependencies ),它指在詞元序列中,相隔較遠的位置的詞元之間的相互依賴或關聯。比如,在“我深切地感覺到,在這段漫長而忙碌的日子里,保持清醒和集中精力非常有用,難道此時不配擁有一杯咖啡嗎?”中,“我”和“配”之間相隔很遠,但他們仍然具有語法層面的依賴關系。這種依賴關系可能非常長,從文章的開頭,一直到文章的結尾。比如,在一篇議論文中,作者可能在文章開頭提出一個論點,然后通過一系列的論據和分析來支持這個論點,直到文章結尾可能再次強調或總結這個論點。在這個過程中,文章開頭的論點和結尾的總結之間就存在著長距離依賴關系,它們在語義上是緊密相連的。
不過雖然詞元與各個詞元之間都可能存在依賴關系,但是其依賴程度不同,為了體現詞元之間的依賴程度,NLP選擇引入“注意力機制”。“注意力機制”可以動態地捕捉序列中不同位置元素之間的依賴關系,分析其強弱程度,并根據這些依賴關系生成新的序列表示。其核心思想是模仿人類的注意力,即在處理大量信息時,能夠聚焦于輸入數據的特定部分,忽略掉那些不太重要的信息,從而更好地理解輸入內容。
繼續以“我配擁有一杯咖啡嗎?”為例,讀到“擁有”這個詞元時,我們會發現“我”是“擁有”的主語,“配”是對“擁有”的強調,他們都與“擁有”產生了依賴關系。這句話的核心思想,是某人認為自己有資格擁有某物,所以可能“配”相對“我”而言,對“擁有”來說更重要,那么我們在分析“擁有”這個詞的語義時,會給“配”分配更多的注意力,這通常體現為分配更高的“注意力權重”。
實際上,我們在日常工作中已經應用了注意力機制。比如,我們都知道思維鏈(COT,常用<輸入, 思考, 輸出>來描述)對大模型處理復雜問題時很有幫助,其本質就是將復雜的問題拆分成相對簡單的小問題并分步驟處理,使模型能夠聚焦于問題的特定部分,來提高輸出質量和準確性。“聚焦”的這一過程,就是依賴模型的注意力機制完成。通常模型會依賴輸出內容或內部推理(如o1具有內部推理過程,即慢思考)來構建思考過程,但哪怕沒有這些內容,僅僅依靠注意力本身,COT也能讓模型提高部分性能。
Why Transformer
自注意力機制是Transformer的核心。在論文中,Transformer說明了三點原因,來說明為何舍棄RNN和CNN,只保留注意力機制
Transformer論文:《Attention is All You Need》
原文:In this section we compare various aspects of self-attention layers to the recurrent and convolutional layers commonly used for mapping one variable-length sequence of symbol representations (x1, ..., xn) to another sequence of equal length (z1, ..., zn), with xi, zi ∈ Rd, such as a hidden layer in a typical sequence transduction encoder or decoder. Motivating our use of self-attention we consider three desiderata.- One is the total computational complexity per layer.
- Another is the amount of computation that can be parallelized, as measured by the minimum number of sequential operations required.
- The third is the path length between long-range dependencies in the network. Learning long-range dependencies is a key challenge in many sequence transduction tasks. One key factor affecting the ability to learn such dependencies is the length of the paths forward and backward signals have to traverse in the network. The shorter these paths between any combination of positions in the input and output sequences, the easier it is to learn long-range dependencies [12].
譯文:在這一部分中,我們比較了自注意力層與通常用于將一個可變長序列的符號表示(x1, ..., xn)映射到另一個等長序列(z1, ..., zn)的循環層和卷積層的不同方面,其中xi, zi ∈ Rd。我們考慮了三個主要因素來激勵我們使用自注意力:
- 每層的總計算復雜性
- 可以并行化的計算量,通過所需的最小順序操作數來衡量。
- 網絡中長距離依賴之間的路徑長度。學習長距離依賴性是許多序列轉換任務中的一個關鍵挑戰。影響學習這些依賴性能力的一個關鍵因素是前向和后向信號在網絡中必須穿越的路徑長度。輸入和輸出序列中任意兩個位置之間的路徑越短,學習長距離依賴性就越容易。
其中后兩點尤其值得注意:
并行化計算:在處理序列數據時,能夠同時處理序列中的所有元素,這很重要,是模型訓練時使用GPU的并行計算能力的基礎。
長距離依賴捕捉:在注意力機制上不依賴于序列中元素的特定順序,可以有效處理序列中元素之間相隔較遠但仍相互影響的關系。
可能有些難以理解,讓我們輸入“我配擁有一杯咖啡?”來進行文本預測,分別看一下RNN和Transformer的處理方式。

依賴捕捉上的差異,是Transformer可以進行并行處理的前提,而并行處理是Transformer的核心優勢之一。在預訓練語言模型階段,預訓練(Pretrain)+微調(Finetune)是模型訓練的主要范式。Transformer的并行化計算能力大大提高了模型訓練的速度,長距離依賴捕捉能力為模型打開了上下文窗口,再結合位置編碼等能力,使得Transformer相對于RNN獲得了顯著優勢。而預訓練又為Transformer帶來了特征學習能力(從數據中自動學習和提取特征的能力)和遷移學習能力(將在一個任務上學習到的知識應用到另一個相關任務上的能力)的提升,顯著提升了模型的性能和泛化能力。
這些優勢,也正是GPT選擇Transformer的原因。
GPT-1的論文《Improving Language Understanding by Generative Pre-Training》
原文:For our model architecture, we use the Transformer, which has been shown to perform strongly on various tasks such as machine translation, document generation, and syntactic parsing. This model choice provides us with a more structured memory for handling long-term dependencies in text, compared to alternatives like recurrent networks, resulting in robust transfer performance across diverse tasks.
翻譯:對于我們的模型架構,我們使用了Transformer,它在機器翻譯、文檔生成和句法解析等各種任務上都表現出色。與循環網絡等替代方案相比,這種模型選擇為我們提供了更結構化的記憶來處理文本中的長期依賴關系,從而在多樣化任務中實現了穩健的遷移性能。
Transformer
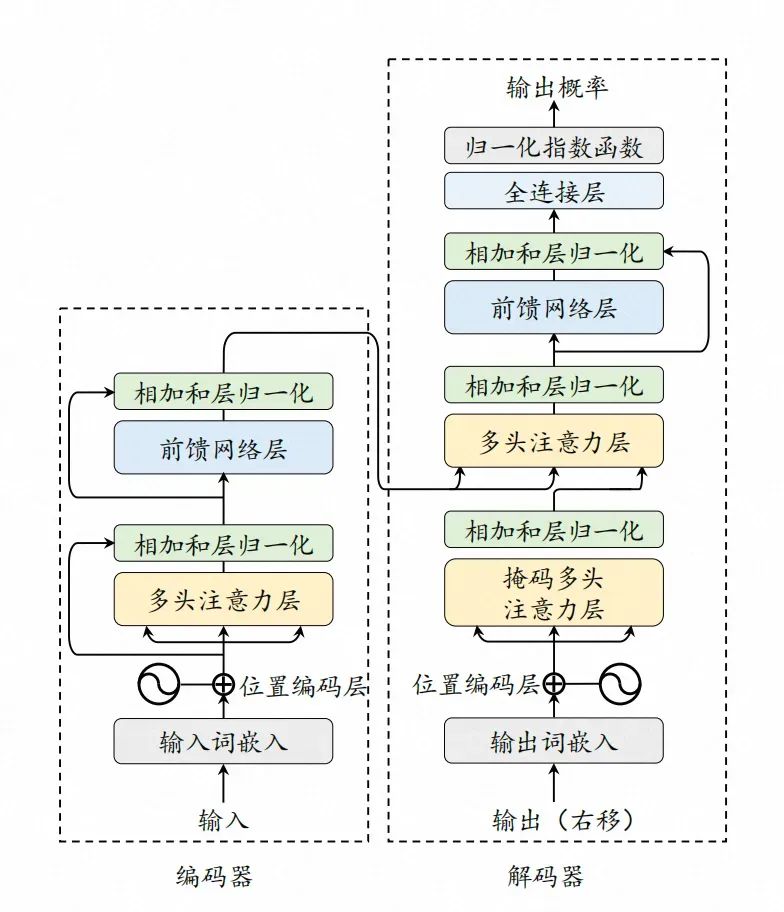
Transformer架構圖,引自《A Survey of Large Language Models》
理解了Transformer的優勢后,讓我們先忘記RNN,回到Transformer本身。從架構圖中可知,Transformer架構分為兩部分:
編碼器:用于理解輸入序列的內容。它讀取輸入數據,并將其轉換成一個連續的表示,這個表示捕捉了輸入數據的關鍵信息和上下文。
解碼器:用于生成輸出序列,使用編碼器的輸出和之前生成的輸出來預測序列中的下一個元素。
以文本翻譯為例,輸入“我愛喝咖啡”,并要求模型將其翻譯成英文。編碼器首先工作,通過理解每個詞元本身的含義,以及其上下文的依賴關系,形成一種向量形式的中間表示,并傳遞給解碼器,這里面包含了整個序列的語義,即“我愛喝咖啡”這句話的完整含義。解碼器結合該信息,從零開始,不斷地預測下一個最可能的英文詞元并生成詞元,直至完成翻譯。
值得注意的是,在解碼器的多頭注意力層(也叫交叉注意力層,或編碼器-解碼器自注意力層),編碼器所提供的輸出中,“我愛喝咖啡”這句話的含義已經明示。這對于文本翻譯這種序列到序列的任務而言,可以確保生成內容的準確性,但對于預測類的任務而言,無疑是提前公布了答案,會降低預測的價值。
Transformer to GPT
隨著技術的演進,基于Transformer已經形成了三種常見架構
編碼器-解碼器架構(Encoder-Decoder Architecture),參考模型:T5
編碼器架構(Encoder-Only Architecture),參考模型:BERT
解碼器架構(Decoder-Only Architecture),參考模型:GPT(來自OpenAI)、Qwen(來自通義千問)、GLM(來自清華大學)
其中編碼器-解碼器架構,適合進行序列到序列的任務,比如文本翻譯、內容摘要。編碼器架構,適合需要對輸入內容分析但不需要生成新序列的任務,比如情感分析、文本分類。解碼器架構,適合基于已有信息生成新序列的任務,比如文本生成、對話系統。
解碼器架構下,又有兩個分支:
因果解碼器(Causal Decoder),參考模型:GPT、Qwen
前綴解碼器(Prefix Decoder),參考模型:GLM
二者之間的主要差異在于注意力的模式。因果解碼器的特點,是在生成每個詞元時,只能看到它之前的詞元,而不能看到它之后的詞元,這種機制通過掩碼實現,確保了模型在生成當前詞元時,不會利用到未來的信息,我們稱之為“單向注意力”。前綴解碼器對于輸入(前綴)部分使用“雙向注意力”進行編碼,這意味著前綴中的每個詞元都可以訪問前綴中的所有其他詞元,但這僅限于前綴部分,生成輸出時,前綴解碼器仍然采用單向的掩碼注意力,即每個輸出詞元只能依賴于它之前的所有輸出詞元。
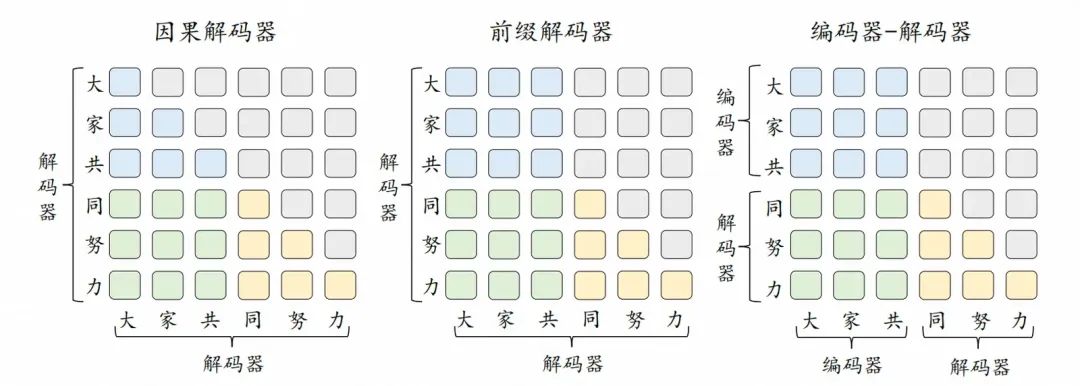
不同架構的注意力模式比較,引自《A Survey of Large Language Models》
可能有些晦澀,讓我們參考《大語言模型概述》的例子來說明一下。該例子中,已經存在了“大家共同努力”這六個詞元,模型正在思考如何產生下一個新的詞元。此時,“大家共”是輸入(前綴),“同努力”是模型解碼已經產生的輸出,藍色代表可以前綴詞元之間可以互相建立依賴關系,灰色代表掩碼,無法建立依賴關系。
因果解碼器和前綴解碼器的差異在“大家共”(前綴)所對應的3*3的方格中,兩種解碼器都會去分析前綴詞元之間的依賴關系。對于因果解碼器而言,哪怕詞元是前綴的一部分,也無法看到其之后的詞元,所以對于前綴中的“家”(對應第二行第二列),它只能建立與“大”(第二行第一列)的依賴關系,無法看到“共”(第二行第三列)。而在前綴解碼器中,“家”可以同時建立與“大”和“共”的依賴關系。
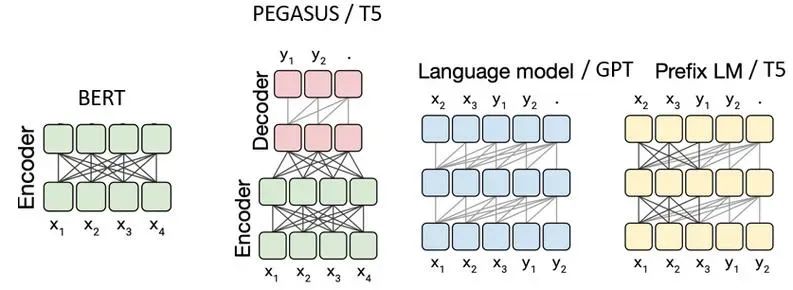
最后貼一張圖大家感受一下不同架構之間注意力模式上的差異。
單向注意力和雙向注意力,有各自的優勢,例如,對于文本生成任務,可能會優先考慮單向注意力以保持生成的連貫性。而對于需要全面理解文本的任務,可能會選擇雙向注意力以獲取更豐富的上下文信息。如上圖分別是編碼器架構(BERT)、編碼器-解碼器架構(T5)、因果解碼器架構(GPT)、前綴解碼器架構(T5、GLM)的注意力模式。
這些架構在當今的大語言模型階段都有應用,其中因果解碼器架構是目前的主流架構,包括Qwen-2.5在內的眾多模型采用的都是這種架構。具體可以參考下面的大語言模型架構配置圖,其中類別代表架構,L 表示隱藏層層數,N 表示注意力頭數,H 表示隱藏狀態的大小。
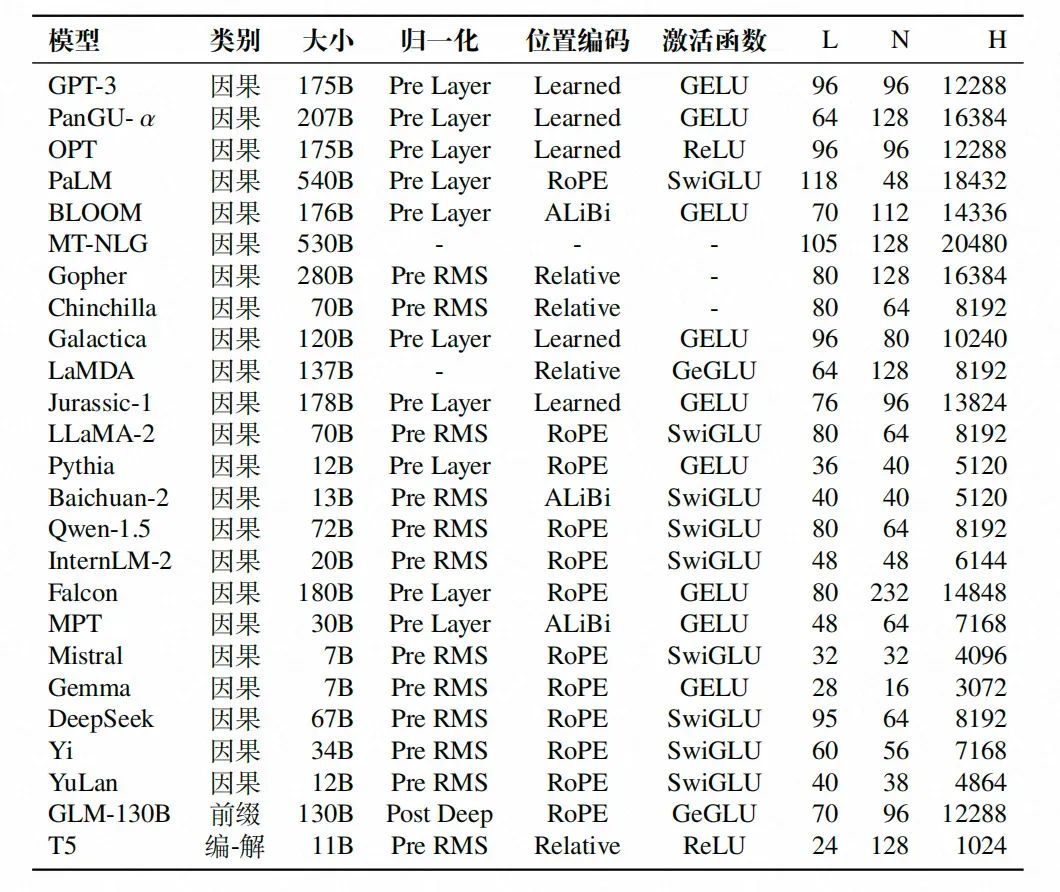
大語言模型架構配置表,引自《A Survey of Large Language Models》
從2018年GPT-1開始,模型的基本原理確實經歷了一些變化和改進,但是探討其基本架構仍然有價值。
GPT
時間來到2018年,OpenAI團隊的論文《Improving Language Understanding by Generative Pre-Training》橫空出世,它提出可以在大規模未標注數據集上預訓練一個通用的語言模型,再在特定NLP子任務上進行微調,從而將大模型的語言表征能力遷移至特定子任務中。其創新之處在于,提出了一種新的預訓練-微調框架,并且特別強調了生成式預訓練在語言模型中的應用。生成式,指的是通過模擬訓練數據的統計特性來創造原始數據集中不存在的新樣本,這使得GPT在文本生成方面具有顯著的優勢。
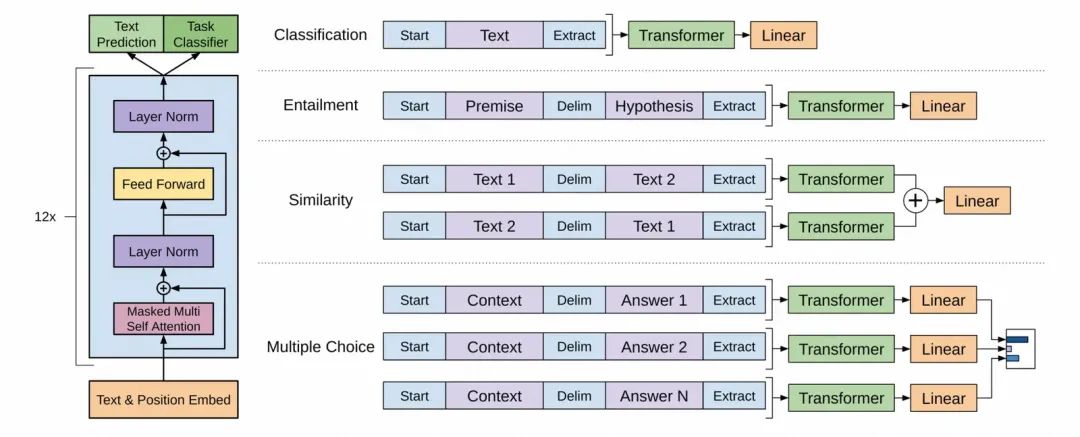
GPT模型架構,引自GPT-1的論文《Improving Language Understanding by Generative Pre-Training》
上圖來自于GPT-1的論文,圖片左側是GPT涉及到的核心組件,這是本文的重點內容。圖片右側是針對不同NLP任務的輸入格式,這些格式是為了將各種任務的輸入數據轉換為Transformer模型能夠處理的序列形式,用于模型與訓練的過程。
GPT使用了Transformer的解碼器部分,同時舍棄了編碼器中的交叉注意力機制層,保留了其余部分。整體上模型結構分為三部分:
輸入層(Input Layer):將文本轉換為模型可以處理的格式,涉及分詞、詞嵌入、位置編碼等。
隱藏層(Hidden Layer):由多個Transformer的解碼器堆疊而成,是GPT的核心,負責模型的理解、思考的過程。
輸出層(Output Layer):基于隱藏層的最終輸出生成為模型的最終預測,在GPT中,該過程通常是生成下一個詞元的概率分布。
在隱藏層中,最核心的兩個結構分別是
掩碼多頭自注意力層(Masked Multi Self Attention Layers,對應Transformer的Masked Multi-Head Attention Layers,簡稱MHA,也叫MSA)。
前置反饋網絡層(Feed Forward Networks Layers,簡稱FFN,與MLP類似)。
MHA的功能是理解輸入內容,它使模型能夠在處理序列時捕捉到輸入數據之間的依賴關系和上下文信息,類似于我們的大腦在接收到新的信息后進行理解的過程。FFN層會對MHA的輸出進行進一步的非線性變換,以提取更高級別的特征,類似于我們的大腦在思考如何回應,進而基于通過訓練獲得的信息和知識,產生新的內容。
舉個例子,當我們輸入“美國2024年總統大選勝出的是”時,MHA會理解每個詞元的含義及其在序列中的位置,讀懂問題的含義,并給出一種中間表示,FFN層則會對這些表示進行進一步的變換,進而從更高級別的特征中得到最相近的信息——“川普”。

MHA和FFN的多層結構,引自3Blue1Brown的視頻《GPT是什么?直觀解釋Transformer》
隱藏層不只有一層,而是一種多層嵌套的結構。如上圖,Attention是MHA,Multilayer Perceptron(MLP)是FFN,它們就像奧利奧餅干一樣彼此交錯。這是為了通過建立更深的網絡結構,幫助模型在不同的抽象層次上捕捉序列內部的依賴關系,最終將整段文字的所有關鍵含義,以某種方式充分融合到最后的輸出中。隱藏層的層數并不是越多越好,這取決于模型的設計,可以參考前文貼過的模型參數表,其中的L就代表該模型的隱藏層的層數。較新的Qwen2-72B有80層,GPT-4有120層。
目前主流的大模型,在這兩層都進行了不同程度的優化。比如Qwen2使用分組查詢注意力(Grouped Multi-Query Attention,簡稱GQA)替代MHA來提高吞吐量,并在部分模型上嘗試使用混合專家模型(Mixture-of-Experts,簡稱MoE)來替代傳統FFN。GPT-4則使用了多查詢注意力(Multi-Query Attention)來減少注意力層的KV緩存的內存容量,并使用了具有16個專家的混合專家模型。關于這里提到的較新的技術,在后文中會詳細闡述。
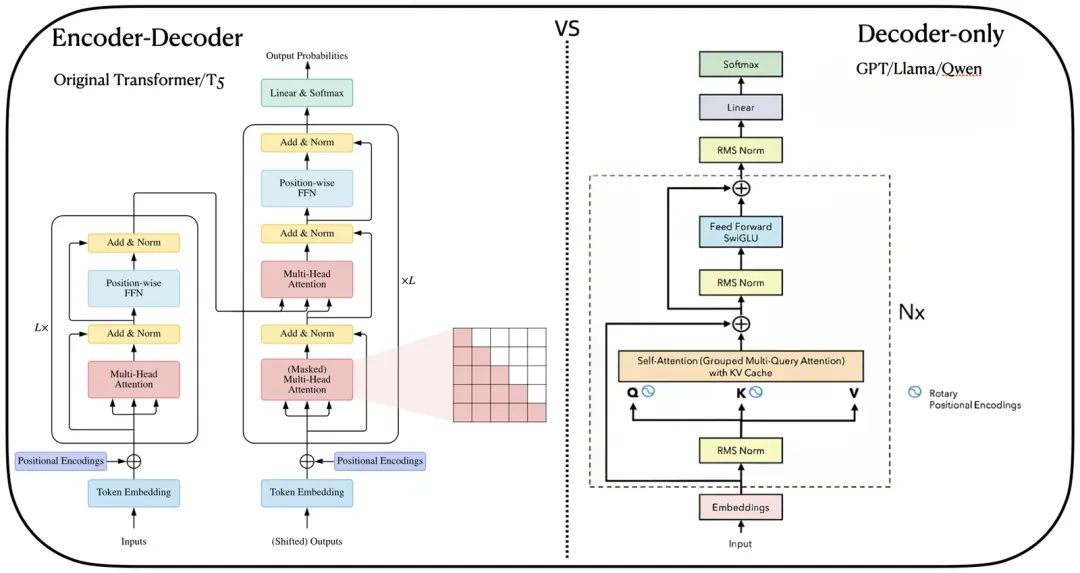
編碼器-解碼器架構與解碼器架構,引自Llama的論文
此外,模型還保留了Transformer的其他部分,包括了(參考上圖右半部分,該圖片的細節更多一些)
詞嵌入 (Embedding,對應GPT論文中的Text & Position Embed)。
位置編碼(Positional Encodings,簡稱PE,對應GPT論文中的Text & Position Embed,Rotary Positional Encodings是位置編碼的一種技術)。
層歸一化(Layer Norm,上圖中表示為RMS Norm,通常與殘差連接一起用,Layer Norm和RMS Norm是歸一化的兩種不同技術)。
線性層(Linear,負責將FFN層的輸出通過線性變換,通常用于將模型的輸出映射到所需的維度)。
Softmax(Softmax層,負責生成概率分布,以便進行最終的預測)。
這些部分單獨拿出來看會有些抽象,讓我們嘗試將一段文本輸入給大模型,看一看大模型的整體處理流程
1.分詞(Tokenization):首先大模型會進行分詞,將文本內容分割成一系列的詞元(token)。
2.詞嵌入(Embedding):分詞后的詞元將被轉換為高維空間中的向量表示,向量中包含了詞元的語義信息。
3.位置編碼(PE):將詞元的在序列中的位置信息,添加到詞嵌入中,以告知模型每個單詞在序列中的位置。
4.掩碼多頭自注意力層(MHA):通過自注意力機制捕捉序列內部詞元間的依賴關系,形成對輸入內容的理解。
5.前饋反饋網絡(FFN):基于MHA的輸出,在更高維度的空間中,從預訓練過程中學習到的特征中提取新的特征。
6.線性層(Linear):將FFN層的輸出映射到詞匯表的大小,來將特征與具體的詞元關聯起來,線性層的輸出被稱作logits。
7.Softmax:基于logits形成候選詞元的概率分布,并基于解碼策略選擇具體的輸出詞元。
在該流程中,我故意省略了層歸一化,層歸一化主要是在模型訓練過程中改善訓練過程,通過規范化每一層的輸出,幫助模型更穩定地學習。而在使用模型時,輸入數據會按照訓練階段學到的層歸一化參數進行處理,但這個參數是固定的,不會動態調整,從這個意義上說,層歸一化不會直接影響模型的使用過程。
分詞、詞嵌入、位置編碼,屬于輸入層,MHA、FFN屬于隱藏層,線性層、Softmax屬于輸出層。可能讀到這里,對于輸入層的理解會相對清晰,對其他層的理解還有些模糊。沒關系,它們的作用有簡單的幾句話很難描述清楚,請繼續往下讀,在讀完本文的所有內容后,再回頭來看會比較清楚。本文中,我們會圍繞著隱藏層和輸出層來詳細介紹,尤其是其中GPT的核心——隱藏層。
自注意力機制(Attention)
MHA(多頭注意力)
MHA,全拼Multi-Head Attention(多頭注意力),在GPT等因果解碼器架構下模型中,指掩碼多頭自注意力,全拼Masked Multi Self Attention。“掩碼”賦予了GPT單向注意力的特性,這符合因果解碼器的架構,“多頭”使GPT可以從不同角度發現特征,自注意力中的“自”指的是模型關注的是單一詞元序列,而不是不同序列之間的特征,比如RNN的循環注意力圍繞的是同一序列的不同時間步。
多頭注意力機制的概念,來自于上古時期Google的論文《Attention Is All You Need》 。
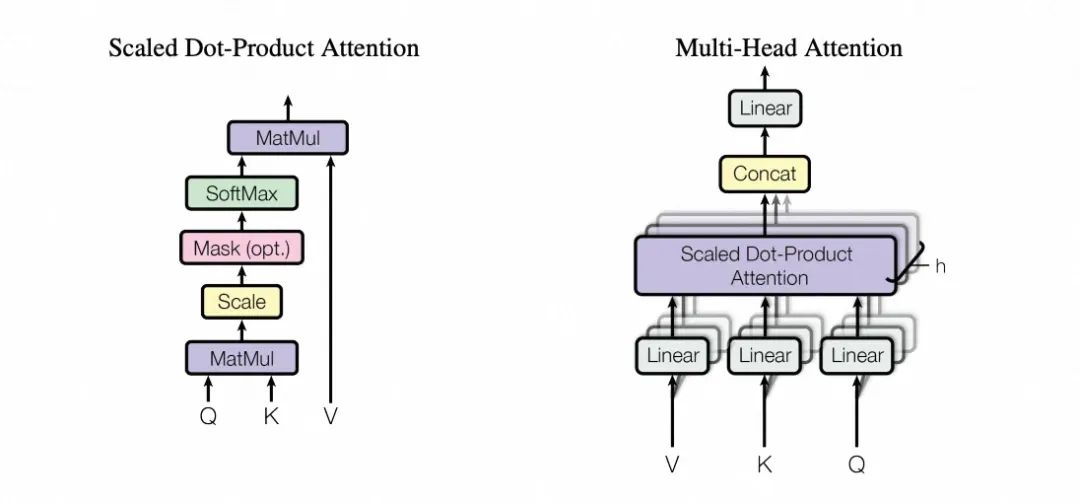
縮放點積注意力(左)和多頭注意力(右),來自《Attention Is All You Need》
從上圖可以看到,多頭注意力是由多個并行運行的縮放點積注意力組成,其中縮放點積注意力的目的,是幫助模型在大量數據中快速找到并專注于那些對當前任務最有價值的信息,讓我們由此講起。
單頭注意力(縮放點積注意力)

了解模型計算注意力的過程是很重要的,Transformer團隊使用了上圖中非常簡潔的公式來表達縮放點積注意力的計算過程。首先要再次明確一下,注意力的計算是詞元維度的,它計算的是當前詞元與上下文中其他詞元的依賴關系,并在此基礎上調整詞元本身的語義。比如在“我配擁有一杯咖啡嗎?”中,會分別計算“我”、“配”、“擁有”、“一杯”、“咖啡”、“嗎?”各自的注意力,并分別調整每個詞元的語義。 整個公式可以看作兩部分,首先是含softmax在內的注意力權重計算過程,其作用是計算“當前詞元”與“其他詞元”(包含當前詞元自身)之間的注意力權重,來體現他們之間的依賴程度,其結果是一個總和為1的比例分布。比如輸入“我愛你”時,“你”會分別計算與“我”、“愛”、“你”三個詞元的注意力權重,并獲得一個比例分布比如[0.2,0.3,0.5]。? 然后,這些注意力權重會分別與“其他詞元”各自的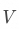 相乘獲得“當前詞元”的數據點在向量空間中偏移的方向和距離。比如,我們設原本“你”的數據點的坐標是
相乘獲得“當前詞元”的數據點在向量空間中偏移的方向和距離。比如,我們設原本“你”的數據點的坐標是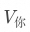 ,那么在注意力計算后的值會變成
,那么在注意力計算后的值會變成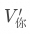 ,其計算的方式就是
,其計算的方式就是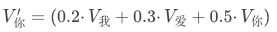 。如果說就是在前文What is Attention小節中舉例的“科技巨頭蘋果”中“蘋果(實體)”所在的位置,那么此時就是“蘋果公司(概念)”所在的位置。 上述描述可能還不夠透徹,請跟著我進一步逐步拆解其計算過程。 首先,X為輸入的詞元序列的嵌入矩陣,包含了詞元的語義信息和位置信息,矩陣中的每一列就是一個詞元的向量,列的長度就是隱藏層的參數量,比如GPT-3的隱藏層參數量是12288,那么在輸入100個詞元的情況下,矩陣的大小就是100 * 12288。
。如果說就是在前文What is Attention小節中舉例的“科技巨頭蘋果”中“蘋果(實體)”所在的位置,那么此時就是“蘋果公司(概念)”所在的位置。 上述描述可能還不夠透徹,請跟著我進一步逐步拆解其計算過程。 首先,X為輸入的詞元序列的嵌入矩陣,包含了詞元的語義信息和位置信息,矩陣中的每一列就是一個詞元的向量,列的長度就是隱藏層的參數量,比如GPT-3的隱藏層參數量是12288,那么在輸入100個詞元的情況下,矩陣的大小就是100 * 12288。 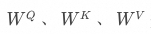 是通過訓練得到的三個權重矩陣,在模型訓練過程中這三個參數矩陣可以采用隨機策略生成,然后通過訓練不斷調整其參數。輸入矩陣X通過與相乘,可以分別得到Q、K、V三個矩陣。
是通過訓練得到的三個權重矩陣,在模型訓練過程中這三個參數矩陣可以采用隨機策略生成,然后通過訓練不斷調整其參數。輸入矩陣X通過與相乘,可以分別得到Q、K、V三個矩陣。
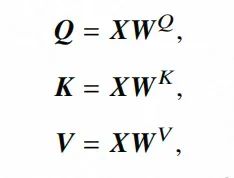
QKV計算公式,引自《A Survey of Large Language Models》? 那么Q、K、V分別是什么?
原文:An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key. 翻譯:注意力函數可以被描述為將一個查詢(query)和一組鍵值對(key-value pairs)映射到一個輸出(output)的過程,其中查詢、鍵、值和輸出都是向量。輸出是通過值的加權和計算得到的,每個值所分配的權重是通過查詢與相應鍵的兼容性函數(compatibility function)計算得出的。
我們可以認為
Q:查詢,通常可以認為模型代表當前的“問題”或“需求”,其目的是探尋其他詞元與當前詞元的相關性。
K:鍵,即關鍵信息,這些信息用于判斷詞元的相關性,可能包括語義信息、語法角色或其他與任務相關的信息。
V:值,即對于鍵所標識的關鍵信息的具體“回應”或“擴展”,可以認為它是鍵背后的詳細信息。
Q屬于當前詞元,而K、V都屬于其他詞元,每個詞元的K、V之間都是相互綁定的。就像是一本書,V就是這本書的摘要、作者、具體內容,K就是這本書的標簽和分類。 每個詞元,都會用自身的Q和其它詞元的K,來衡量 與
與 之間的相關性。衡量的方式就是計算QK之間的點積,在公式中體現為
之間的相關性。衡量的方式就是計算QK之間的點積,在公式中體現為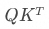 。點積運算是綜合衡量兩個向量在各個維度上的相關性的一種方式,比如
。點積運算是綜合衡量兩個向量在各個維度上的相關性的一種方式,比如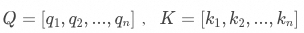 ,其點積的結果就是
,其點積的結果就是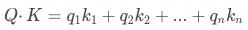 ,即對應分量的乘積之和。相關性的大小,就是通過點積運算獲得的結果的大小體現的。? 舉個例子,以“有一天,一位勇敢的探險家”作為輸入序列給大模型
,即對應分量的乘積之和。相關性的大小,就是通過點積運算獲得的結果的大小體現的。? 舉個例子,以“有一天,一位勇敢的探險家”作為輸入序列給大模型
Q:假設Q代表著“查找最相關的信息點”這個概念,那么在“探險家”這個詞元上,Q所對應的這一列,可能代表“和探險家最相關的信息點是什么?”,那它尋找的可能就是“冒險”、“勇氣”、“積極”等特征。
K:在“勇敢的”這個詞元上,K可能在語義上與“冒險”、“勇氣”相關聯,在語法上與“修飾語”相關聯,在情感上與“積極”相關聯。這些都屬于關鍵信息。
V:在“探險家”這個token上,如果Q是“和探險家最相關的信息點是什么”,那么V向量將提供與“探險家”直接相關的上下文信息,比如探險家的行為、特征或相關事件。
對于“探險家”所對應的Q的向量,會分別與序列中的其他詞元對應的K向量計算點積,獲得與“有一天”、“一位”、“勇敢的”、“探險家”這些詞元點積的值,這代表著二者之間的語義相似度。有可能,“探險家”由于其也具有“冒險”、“勇氣”等關鍵特征,其與“勇敢的”的點積相對更大,那么其在歸一化后的占比也會更高,在GPT的理解中,“勇敢的”對于“探險家”而言,就更重要。 關于為何要使用點積進行運算,論文中也進行了分析,文中分析了加性注意力和點積注意力的這兩種兼容性函數之間的差異,發現點積注意力能夠捕捉序列中元素間的長距離依賴關系的同時,在計算上高效且能穩定梯度。
原文:The two most commonly used attention functions are additive attention [ 2], and dot-product (multi-plicative) attention. Dot-product attention is identical to our algorithm, except for the scaling factor. Additive attention computes the compatibility function using a feed-forward network with a single hidden layer. While the two are similar in theoretical complexity, dot-product attention is much faster and more space-efficient in practice, since it can be implemented using highly optimized matrix multiplication code. 翻譯:兩種最常用的注意力函數是加性注意力[2]和點積(乘法)注意力。點積注意力與我們的算法相同,除了有一個縮放因子。加性注意力使用具有單個隱藏層的前饋網絡來計算兼容性函數。雖然兩者在理論上的復雜度相似,但在實踐中,點積注意力要快得多,也更節省空間,因為它可以利用高度優化的矩陣乘法代碼來實現。
點積的結果會除以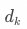 的平方根,來對點積的結果進行縮放,確保數值穩定,這一段在原文中也有表述。通過將“探險家”與每一個詞元都進行一次計算,就可以得到一個向量,向量中的每一個元素代表著“探險家”與對應詞元的點積的值。之后進行掩碼(Mask),在前文中提到,在因果解碼器中,當前詞元是無法看到自身之后的詞元的,所以需要將當前詞元之后的所有點積置為負無窮,以便使其在歸一化后的占比為零。? 最后對點積softmax進行歸一化,就可以得到一個總和為1的一個比例分布,這個分布就叫“注意力分布”。下面表格中“探險家”所對應的那一列,就是“探險家”的注意力分布,代表著從“探險家”的視角出發,每一個詞元對于自身內容理解的重要程度。
的平方根,來對點積的結果進行縮放,確保數值穩定,這一段在原文中也有表述。通過將“探險家”與每一個詞元都進行一次計算,就可以得到一個向量,向量中的每一個元素代表著“探險家”與對應詞元的點積的值。之后進行掩碼(Mask),在前文中提到,在因果解碼器中,當前詞元是無法看到自身之后的詞元的,所以需要將當前詞元之后的所有點積置為負無窮,以便使其在歸一化后的占比為零。? 最后對點積softmax進行歸一化,就可以得到一個總和為1的一個比例分布,這個分布就叫“注意力分布”。下面表格中“探險家”所對應的那一列,就是“探險家”的注意力分布,代表著從“探險家”的視角出發,每一個詞元對于自身內容理解的重要程度。
| KeyQuery | Q 有一天 | Q 一位 | 勇敢的 | 探險家 |
| K 有一天 | 1 | 0.13 | 0.03 | 0.02 |
| K 一位 | 0 | 0.87 | 0.1 | 0.05 |
| K 勇敢的 | 0 | 0 | 0.87 | 0.08 |
| K 探險家 | 0 | 0 | 0 | 0.85 |
一個可能的Softmax后的概率分布(每一列的和都為1,灰色代表掩碼)
最后,將Softmax后獲得的注意力分布,分別與每一個K對應的V相乘,通過注意力權重加權求和,就可以得到一個向量,稱為上下文向量。它就是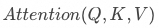 求解出來的值,其中包含了序列中與當前元素最相關的信息,可以認為是模型在結合了上下文的信息后,對序列內容的理解的一種表示形式。
求解出來的值,其中包含了序列中與當前元素最相關的信息,可以認為是模型在結合了上下文的信息后,對序列內容的理解的一種表示形式。
多頭注意力
關于什么是多頭注意力,為何使用多頭注意力,論文中有這樣一段描述,各位一看便知。
原文:Instead of performing a single attention function with dmodel-dimensional keys, values and queries, we found it beneficial to linearly project the queries, keys and values h times with different, learned linear projections to dk, dk and dv dimensions, respectively. On each of these projected versions of queries, keys and values we then perform the attention function in parallel, yielding dv-dimensional output values. These are concatenated and once again projected, resulting in the final values, as depicted in Figure 2. Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions. With a single attention head, averaging inhibits this. 翻譯:我們發現,與其執行一個具有dmodel維鍵、值和查詢的單一注意力函數,不如將查詢、鍵和值線性投影h次,使用不同的、學習得到的線性投影到dk、dk和dv維度。然后我們并行地在這些投影版本的查詢、鍵和值上執行注意力函數,得到dv維的輸出值。這些輸出值被連接起來,再次被投影,得到最終的值,如圖2所示。多頭注意力允許模型同時關注不同表示子空間中的信息,以及不同位置的信息。而單一注意力頭通過平均操作抑制了這一點。
多頭注意力的“多頭”,指的是點積注意力函數實例有多種。不同的頭,他們的都可能不同,這可能意味著詞元會從不同角度去發問,同時表達出不同角度的特征,比如一個頭可能專注于捕捉語法信息,另一個頭可能更關注語義信息,還有一個頭可能更關注情感分析。這對于充分捕獲上下文信息,尤其是在處理復雜的序列數據時,變得更加強大和靈活。? 這種優化并沒有使計算的復雜度升高,論文中特別提到
原文:In this work we employ h = 8 parallel attention layers, or heads. For each of these we use dk = dv = dmodel/h = 64. Due to the reduced dimension of each head, the total computational cost is similar to that of single-head attention with full dimensionality.
翻譯:在這項工作中,我們使用了 h=8 個并行的注意力層,或者說是“頭”(heads)。對于每一個頭,我們設置 dk=dv=dm/h=64 。這里的dk和dv分別代表鍵(keys)和值(values)的維度,而 是模型的總維度。
是模型的總維度。
進一步舉個例子來解釋一下這段內容。下面是節選的GPT-3模型配置,N代表注意力頭數,H代表隱藏狀態的大小(參數量)。在單頭注意力的情況下,每個頭都是12288維,而在多頭注意力的情況下,頭與頭之間會均分參數量,每個頭的參數量只有12288/96 =128維,并且不同頭的注意力計算都是并行的。

GPT-3模型配置,引自《A Survey of Large Language Models》 如今,這種設計隨著技術的發展有所演進,Q的頭數在標準的MHA下,通常與KV的頭數相同,然后目前主流的大模型都進行KV緩存的優化,Q和KV的頭數可能并不相同。比如我們常用的Qwen2-72B,其隱藏層有8192個參數,有64個Q和8個KV頭,每個頭的參數量是128。數據來自于Qwen2的技術報告(如下圖),具體技術細節在后續GQA部分會有詳細說明。
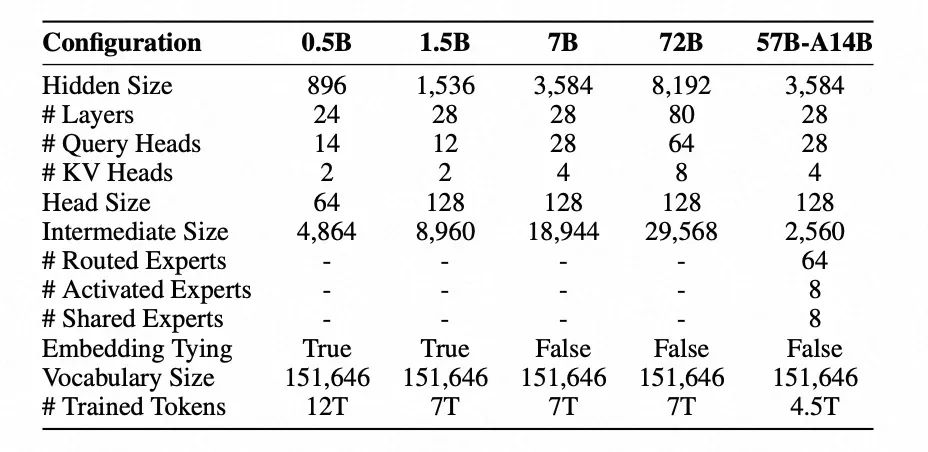
Qwen2系列模型參數,引自《QWEN2 TECHNICAL REPORT》? 回到計算過程中,多頭注意力,會在每個頭都按照縮放點積注意力的方式進行運算后,將他們產生的上下文向量進行連接,基于輸出投影矩陣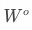 進行變換。這個過程是為了綜合不同注意力頭所提供的信息,就像是綜合考慮96個人的不同意見,并形成最終的結論。 這種綜合的過程并不是簡單地求平均值,而是通過進行的連接操作。
進行變換。這個過程是為了綜合不同注意力頭所提供的信息,就像是綜合考慮96個人的不同意見,并形成最終的結論。 這種綜合的過程并不是簡單地求平均值,而是通過進行的連接操作。

具體來說,首先多頭注意力會獲取每個單頭注意力所提供的上下文向量,并在特征維度上進行連接,形成一個更長的向量,對應公式中的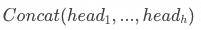 ,其中h是注意力頭數。拼接后的矩陣的維度是隱藏層的維度,比如GPT-3有96個頭,每個頭有128*12288維,那么拼接后形成的就是一個12288*12288維的矩陣。是模型在訓練過程中學習到的關鍵組成部分,將拼接后的矩陣向量基于該矩陣做一次線性變換,有助于模型在多頭注意力的基礎上進一步優化特征表示,提高模型的整體性能。 至此,標注的MHA的相關內容就結束了。接下來MHA層的輸出,會傳遞到下一層,可能是FFN,也可能是MoE,取決于具體的模型。在此之前,先來看一下大模型對注意力層的優化。 ?
,其中h是注意力頭數。拼接后的矩陣的維度是隱藏層的維度,比如GPT-3有96個頭,每個頭有128*12288維,那么拼接后形成的就是一個12288*12288維的矩陣。是模型在訓練過程中學習到的關鍵組成部分,將拼接后的矩陣向量基于該矩陣做一次線性變換,有助于模型在多頭注意力的基礎上進一步優化特征表示,提高模型的整體性能。 至此,標注的MHA的相關內容就結束了。接下來MHA層的輸出,會傳遞到下一層,可能是FFN,也可能是MoE,取決于具體的模型。在此之前,先來看一下大模型對注意力層的優化。 ?
KV Cache
前文提到,因果解碼器的特點,是在生成每個詞元時,只能看到它之前的詞元,而不能看到它之后的詞元。也就是說,無論模型在自回歸過程中生成多少詞元,此前已經生成的詞元對上下文內容的理解,都不會發生任何改變。因此我們在自回歸過程中,不需要在生成后續詞元時重新計算已經生成的詞元的注意力。
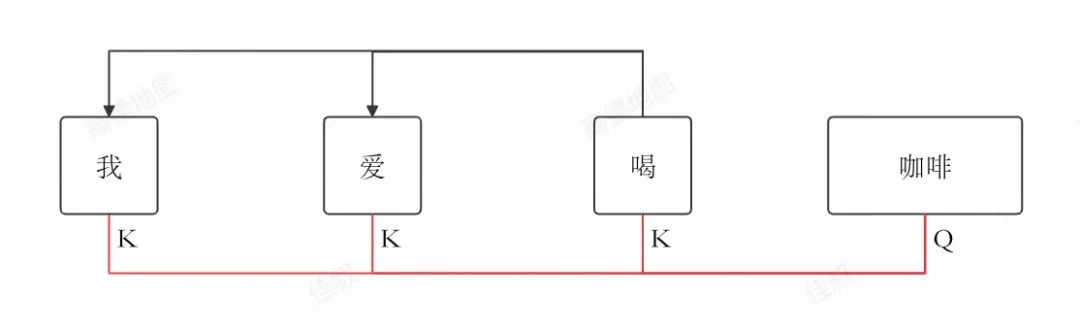
我是真的愛喝咖啡? 但是,新生成的詞元的注意力需要計算,這會涉及新生成的詞元的Q與其它詞元的K計算點積,并使用其它詞元的V生成上下文向量。而此前生成的詞元K、V,實際上始終不會改變,因此我們可以將他們緩存起來,在新生成的詞元計算注意力的時候直接使用,避免重復計算,這就是KV緩存。如上圖,已經生成的詞元“我”、“愛”、“喝”都不會重新計算注意力,但是新生成的“咖啡”需要計算注意力,期間我們需要用到的是“咖啡”的 Q,和“我”、“愛”、“喝”的K、V。 KV緩存的核心思想是:
緩存不變性:在自回歸生成過程中,已經生成的詞元的鍵(Key,K)和值(Value,V)不會改變。
避免重復計算:由于K和V不變,模型在生成新詞元時,不需要重新計算這些已生成詞元的K和V。
動態更新:當新詞元生成時,它的查詢(Query,Q)會與緩存的K進行點積計算,以確定其與之前所有詞元的關聯。同時,新詞元的K和V會被計算并添加到緩存中,以便用于下一個詞元的生成。
在使用KV Cache的情況下,大模型的推理過程常被分為兩個階段
預填充階段(Prefill):模型處理輸入序列,計算它們的注意力,并存儲K和V矩陣到KV Cache中,為后續的自回歸過程做準備。
解碼階段(Decode):模型使用KV緩存中的信息,逐個生成輸出新詞元,計算其注意力,并將其K、V添加到KV Cache中。
其中預填充階段是計算密集型的,因為其涉及到了矩陣乘法的計算,而解碼階段是內存密集型的,因為它涉及到了大量對緩存的訪問。緩存使用的是GPU的顯存,因此我們下一個面臨的問題是,如何減少KV Cache的顯存占用。?
MQA
2019年,Google團隊發布了論文《Fast Transformer Decoding: One Write-Head is All You Need》,并提出了多查詢注意力的這一MHA的架構變種,其全拼是Multi-Query Attention,簡稱MQA,GPT-4模型就是采用的MQA來實現其注意力層。? Google為何要提出,論文中提到
原文1:Transformer relies on attention layers to communicate information between and across sequences. One major challenge with Transformer is the speed of incremental inference. As we will discuss, the speed of incremental Transformer inference on modern computing hardware is limited by the memory bandwidth necessary to reload the large "keys" and "values" tensors which encode the state of the attention layers. 原文2:We propose a variant called multi-query attention, where the keys and values are shared across all of the different attention "heads", greatly reducing the size of these tensors and hence the memory bandwidth requirements of incremental decoding. 翻譯1:Transformer依賴于注意力層來在序列之間和內部傳遞信息。Transformer面臨的一個主要挑戰是增量推理的速度。正如我們將要討論的,現代計算硬件上增量Transformer推理的速度受到重新加載注意力層狀態所需的大型“鍵”和“值”張量內存帶寬的限制。 翻譯2:我們提出了一種變體,稱為多查詢注意力(Multi-Query Attention),其中鍵(keys)和值(values)在所有不同的注意力“頭”(heads)之間共享,大大減少了這些張量的大小,從而降低了增量解碼的內存帶寬需求。
增量推理(Incremental Inference)是指在處理序列數據時,模型逐步生成輸出結果的過程。張量其實就是多維數組,在注意力層主要指的是各個與注意力有關的權重矩陣。不難看出,Google團隊注意到了K、V所帶來的巨大內存帶寬占用,通過MQA將K、V在不同注意力頭之間共享,提高了模型的性能。
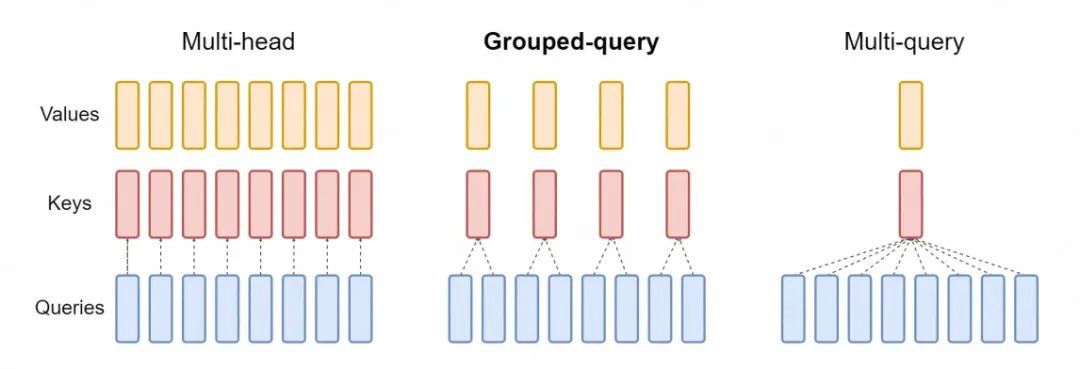
MHA、GQA、MQA的比較,引自《GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints》 我們用GPT-3舉例,它有96個自注意力頭。那么在傳統MHA中,生成一個新的詞元,都需要重新計算96個Q、K、V矩陣。而在MQA中,只需要計算96個Q矩陣,再計算1次K、V矩陣,再將其由96個頭共享。每次Q、K、V的計算都需要消耗內存帶寬,通過降低K、V的計算次數,可以有效優化模型的解碼速度。
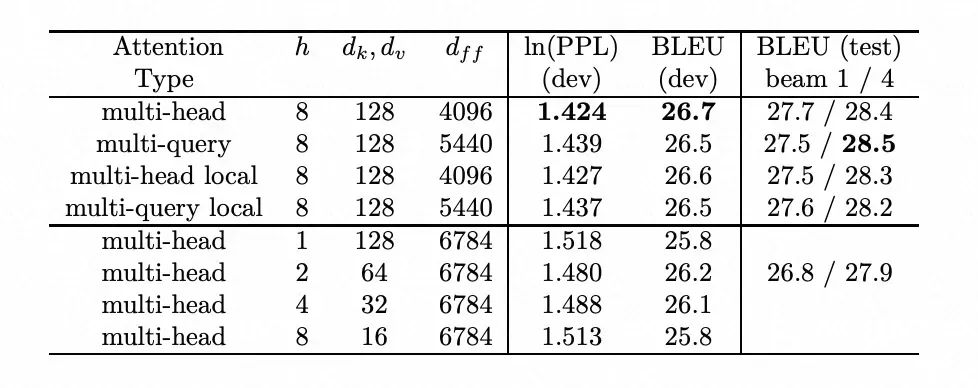
在WMT14英德(English to German)翻譯任務上的性能比較,來自《Fast Transformer Decoding: One Write-Head is All You Need》 BLEU是一種評估機器翻譯質量的自動化指標,分數越高表示翻譯質量越好。根據論文中對性能比較的結果,MQA確實相對于MHA,在翻譯效果上的性能有所下降,但是相對于其他減少注意力頭數量等替代方案而言,效果仍然很好。 實際上由于KV緩存的使用,MQA降低的主要資源消耗,并不是內存帶寬,而是內存占用,也就是KV緩存的大小。?
GQA
GQA,來自于Google團隊的2023年的論文《GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints》,GQA的全拼是Grouped Query Attention(分組查詢注意力),被包括Llama3、Qwen2在內的眾多主流模型廣泛采用。 論文中提到
原文:However, multi-query attention (MQA) can lead to quality degradation and training instability, and it may not be feasible to train separate models optimized for quality and inference. Moreover, while some language models already use multiquery attention, such as PaLM (Chowdhery et al., 2022), many do not, including publicly available language models such as T5 (Raffel et al., 2020) and LLaMA (Touvron et al., 2023). 翻譯:然而,多查詢注意力(MQA)可能導致質量下降和訓練不穩定性,并且可能不切實際去訓練分別針對質量和推理優化的獨立模型。此外,雖然一些語言模型已經采用了多查詢注意力,例如PaLM(Chowdhery等人,2022年),但許多模型并沒有采用,包括公開可用的語言模型,如T5(Raffel等人,2020年)和LLaMA(Touvron等人,2023年)。
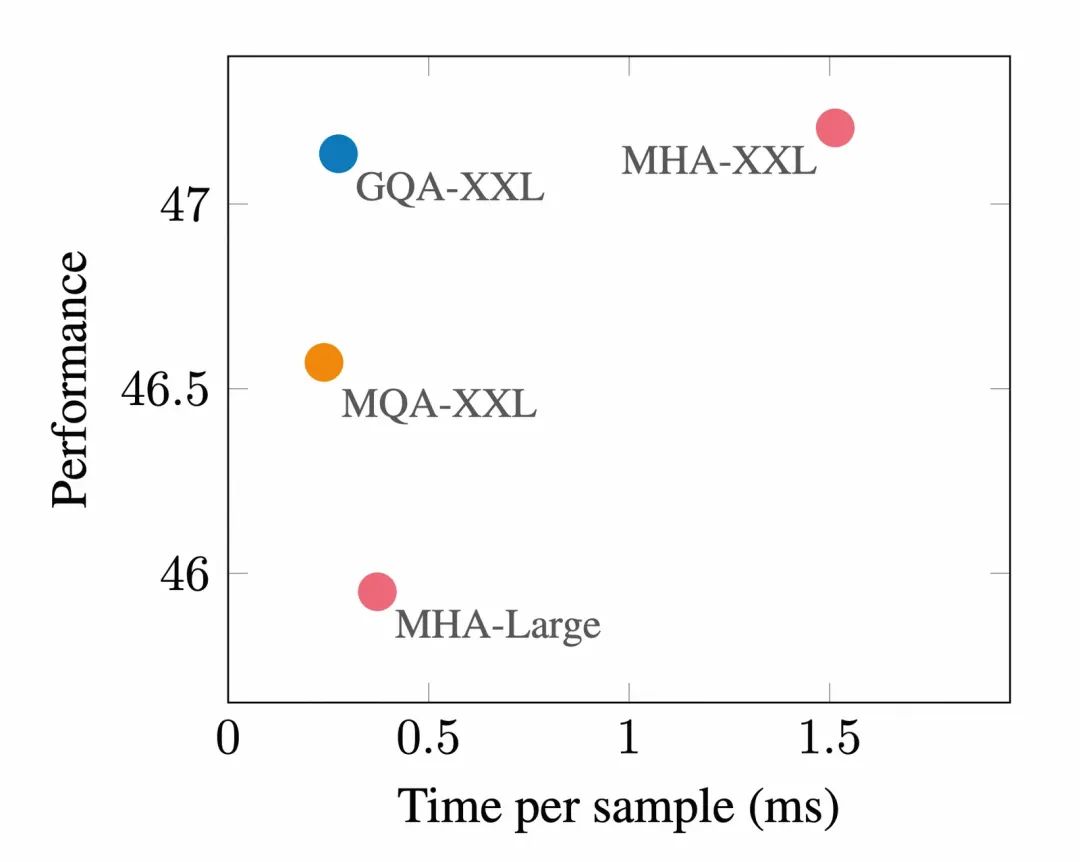
MHA、MQA、GQA的性能比較,引自《GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints》? 它的本質其實是對MHA、MQA的一種折中,在顯存占用和推理性能上的一種平衡。上圖是對MQA、GQA、MHA三種注意力模式下模型性能的比較。(XXL代表Extra Extra Large,超大型模型,具備最多的參數量,Large代表大型模型,其參數量在標準模型和XXL之間)。
前饋神經網絡
FFN,全拼Feed-Forward Network,前饋神經網絡。FFN層,通過對自注意力層提供的充分結合了上下文信息的輸出進行處理,在高維空間中進行結合訓練獲得的特征和知識,獲得新的特征。FFN因其簡單性,在深度學習領域備受歡迎,其原理也相對更容易解釋。
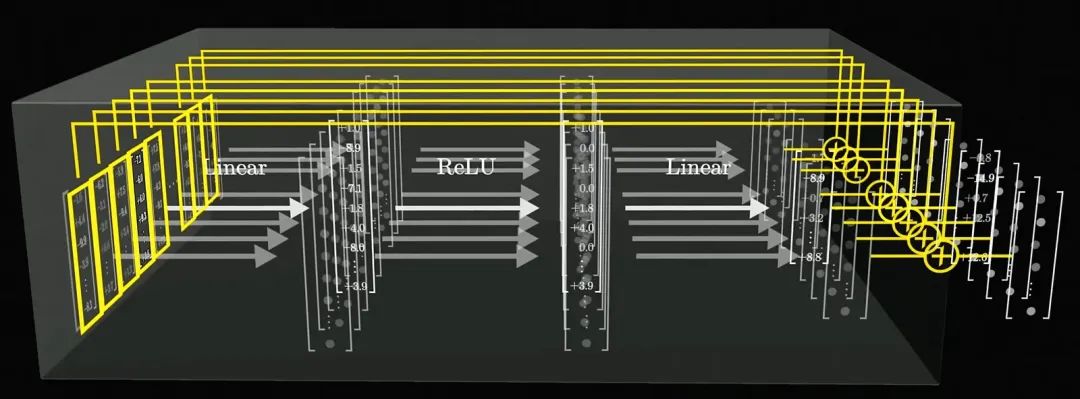
FFN層的處理過程,引自3Blue1Brown的視頻《直觀解釋大語言模型如何儲存事實》? 在Transformer中,FFN層由兩個線性變換和一個激活函數構成,它的處理過程是詞元維度的,每個詞元都會并行地進行計算,如上圖,因此在學習FFN層的處理過程時,我們只需要分析單個詞元的處理過程。
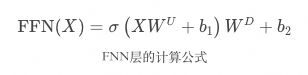
這個過程同樣可以用一個簡潔的公式來表示,如上圖,讓我們來逐步解讀一下。 首先,X是輸入向量,代表了已經充分結合上下文信息的單個詞元,它由自注意力層提供,其維度就是隱藏層的維度,比如GPT-3中是12288。我們將接收到的詞元,首先與通過模型訓練獲得的矩陣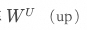 相乘,進行一次線性變換,進而將輸入向量映射到一個更高維度的空間,這個空間通常被稱為FFN的“隱藏層”。這個過程可以認為是對輸入的“擴展”,目的是使FFN的隱藏層能夠表達更多的特征,這一層的維度通常比自注意力層提供的輸出維度大得多,比如GPT-3中它的維度是49152,剛好是自注意力層輸出維度的四倍。 舉個例子,假設在自注意力層產生的輸入中,模型只能了解到詞元的語法特征、語義特征,比如“勇敢的”,模型能感知到它是“形容詞”、代表“勇敢”。那么在經過這次線性變換后,模型通過擴充維度,就能感知到其“情感特征”,比如“正向”、“積極”。 b代表bias,中文意思是偏置、偏見、傾向性,它也是通過模型訓練獲得的,在模型的正向推理過程中可以視為一個常數。神經網絡中的神經元可以通過公式
相乘,進行一次線性變換,進而將輸入向量映射到一個更高維度的空間,這個空間通常被稱為FFN的“隱藏層”。這個過程可以認為是對輸入的“擴展”,目的是使FFN的隱藏層能夠表達更多的特征,這一層的維度通常比自注意力層提供的輸出維度大得多,比如GPT-3中它的維度是49152,剛好是自注意力層輸出維度的四倍。 舉個例子,假設在自注意力層產生的輸入中,模型只能了解到詞元的語法特征、語義特征,比如“勇敢的”,模型能感知到它是“形容詞”、代表“勇敢”。那么在經過這次線性變換后,模型通過擴充維度,就能感知到其“情感特征”,比如“正向”、“積極”。 b代表bias,中文意思是偏置、偏見、傾向性,它也是通過模型訓練獲得的,在模型的正向推理過程中可以視為一個常數。神經網絡中的神經元可以通過公式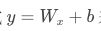 來表示,b在其中可以控制函數到原點的距離,也叫函數的截距。通過引入bias,可以避免模型訓練過程中的過擬合,增強其泛化性,以更好地適應不同的數據分布,進而提高預測的準確性。
來表示,b在其中可以控制函數到原點的距離,也叫函數的截距。通過引入bias,可以避免模型訓練過程中的過擬合,增強其泛化性,以更好地適應不同的數據分布,進而提高預測的準確性。 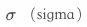 ,西格瑪,代表激活函數。激活函數的作用,是為模型引入非線性的因素,作為一個“開關”或者“調節器”,來控制信息在神經網絡中的傳遞方式,即某些特征是否應當被傳遞到下一層。這種非線性的因素,使得模型能夠學習和模擬復雜的函數映射關系。并通過讓模型專注于那些對當前任務更有幫助的正向特征,來讓模型能夠更好的選擇和組合特征。 舉個例子,我們通過線性變換,獲得了關于輸入內容的大量特征信息,但其中一部分信息相對沒那么重要或毫不相關,我們需要將他們去掉,避免對后續的推理產生影響。比如“我”這個詞,自身的語法特征很清晰,我們要保留,但是其并沒有什么情感特征,因此我們要將與“我”的情感特征相關的信息去除。
,西格瑪,代表激活函數。激活函數的作用,是為模型引入非線性的因素,作為一個“開關”或者“調節器”,來控制信息在神經網絡中的傳遞方式,即某些特征是否應當被傳遞到下一層。這種非線性的因素,使得模型能夠學習和模擬復雜的函數映射關系。并通過讓模型專注于那些對當前任務更有幫助的正向特征,來讓模型能夠更好的選擇和組合特征。 舉個例子,我們通過線性變換,獲得了關于輸入內容的大量特征信息,但其中一部分信息相對沒那么重要或毫不相關,我們需要將他們去掉,避免對后續的推理產生影響。比如“我”這個詞,自身的語法特征很清晰,我們要保留,但是其并沒有什么情感特征,因此我們要將與“我”的情感特征相關的信息去除。
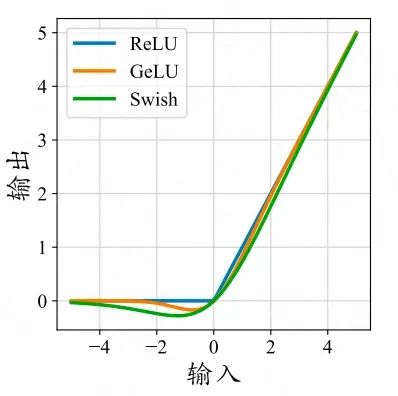
不同函數的曲線對比,引自《A Survey of Large Language Models》 當然,“去除”這個詞其實并不準確,應當叫做“抑制”。ReLU作為一種激活函數,會將所有相乘后結果為零的部分去除,只保留所有結果為正的信息,我們可以認為是“去除”。不過ReLU在目前主流的大模型中并不常用,比如Qwen、Llama等模型選擇使用SwiGLU,GPT選擇GeLU,他們的曲線相對更加平滑,如上圖。不同激活函數的選擇,是一種對于模型的非線性特性和模型性能之間的權衡,類似于ReLU這種函數可能會導致關閉的神經元過多,導致模型能夠感知到的特征過少,變得稀疏。
FFN層的處理過程,引自3Blue1Brown的視頻《直觀解釋大語言模型如何儲存事實》? 在經過激活函數進行非線性變換處理后的向量,會再次通過矩陣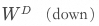 進行第二次線性變換,將高維空間中的向量,重新映射回原始維度,并追加第二個偏置
進行第二次線性變換,將高維空間中的向量,重新映射回原始維度,并追加第二個偏置 ,來形成模型的輸出。這種降維操作,一方面使得FFN層的輸出能夠與下一層(自注意力層或輸出層)的輸入維度相匹配,保持模型的深度不變,減少后續層的計算量,另一方面模型可以對升維后學習到的特征進行選擇和聚焦,只保留最重要的信息,這有助于提高模型的泛化能力。到此單次FFN層的執行過程就講述完畢了,整體過程可以參考上圖。? 總結一下,向上的線性變換,使得詞元能夠表達出更多的特征,激活函數通過非線性因素,來增強模型對特征的表達能力,向下的線性變換,會將這些特征進行組合,這就是FFN層中模型的“思考”過程。 另外要說明,向量的特征,并不會像我們前面舉例的那樣簡單地可以概括為“語義”、“語法”、“情感”特征。比如在模型訓練過程中,模型可能學習到“美國總統”和“川普”之間具有關聯性,“哈利”與“波特”之間具有關聯性,“唱”、“跳”、“Rap”與“籃球”之間具有關聯性,這些關聯性很難用簡單的語言來表達清楚,但它們也實實在在地形成了“川普”、“波特”、“籃球”的某些特征。 有人會說“訓練大模型的過程就像煉丹”,這其實是在描述模型內部的黑盒性。而我們使用大模型時,也要避免工程化的思維,認為大模型一定會按照預設的規則去執行,這其實并不尊重模型本身的特性。因為模型的推理過程,不僅僅受到輸入(包括提示詞以及模型自回歸過程中不斷產生的輸出)的影響,還會受到訓練數據、模型架構、以及訓練過程中的超參數的影響。但我們可以在理解了注意力機制后通過設計良好的提示詞,在理解了模型的思考過程后通過進行模型的微調或增強學習,來馴化大模型。
,來形成模型的輸出。這種降維操作,一方面使得FFN層的輸出能夠與下一層(自注意力層或輸出層)的輸入維度相匹配,保持模型的深度不變,減少后續層的計算量,另一方面模型可以對升維后學習到的特征進行選擇和聚焦,只保留最重要的信息,這有助于提高模型的泛化能力。到此單次FFN層的執行過程就講述完畢了,整體過程可以參考上圖。? 總結一下,向上的線性變換,使得詞元能夠表達出更多的特征,激活函數通過非線性因素,來增強模型對特征的表達能力,向下的線性變換,會將這些特征進行組合,這就是FFN層中模型的“思考”過程。 另外要說明,向量的特征,并不會像我們前面舉例的那樣簡單地可以概括為“語義”、“語法”、“情感”特征。比如在模型訓練過程中,模型可能學習到“美國總統”和“川普”之間具有關聯性,“哈利”與“波特”之間具有關聯性,“唱”、“跳”、“Rap”與“籃球”之間具有關聯性,這些關聯性很難用簡單的語言來表達清楚,但它們也實實在在地形成了“川普”、“波特”、“籃球”的某些特征。 有人會說“訓練大模型的過程就像煉丹”,這其實是在描述模型內部的黑盒性。而我們使用大模型時,也要避免工程化的思維,認為大模型一定會按照預設的規則去執行,這其實并不尊重模型本身的特性。因為模型的推理過程,不僅僅受到輸入(包括提示詞以及模型自回歸過程中不斷產生的輸出)的影響,還會受到訓練數據、模型架構、以及訓練過程中的超參數的影響。但我們可以在理解了注意力機制后通過設計良好的提示詞,在理解了模型的思考過程后通過進行模型的微調或增強學習,來馴化大模型。

FFN層的神經網絡結構圖 最后,我想講一個概念。在各種技術報告中,我們常會看到一個詞——“稠密模型”,它指的是模型在處理任務時,模型的每個神經元都彼此相連,所有參數都共同參與計算的模型。如上圖,FFN層無論是在向上的線性變換還是向下的線性變換的過程中,每一個神經元都彼此相連,因此這兩層線性變換其實就是FFN層的兩層稠密層,FFN層也就可以視為稠密模型的一種形式。? 稠密模型由于其參數量很大,能夠捕捉更豐富的特征和復雜的模式,但這也導致其較高的訓練和推理成本,且在數據集規模較少時,嘗試去擬合那些不具有普遍性的噪聲,導致模型的過擬合,降低模型的泛化性。? 與“稠密模型”相對應的是“稀疏模型”,其核心思想是利用數據的稀疏性,即數據中只有少部分特征是重要的,大部分特征都是冗余或者噪聲。MoE就是一種典型的稀疏模型,目前在GPT-4,以及Qwen2的部分模型等眾多大語言模型上,被用于替代FFN層。
輸出層
在最后的最后,模型在經過多輪的隱藏層的計算后,獲得了最終的隱藏狀態。輸出層,則負責將這個隱藏狀態,轉換為下一個詞元的概率分布。
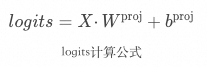
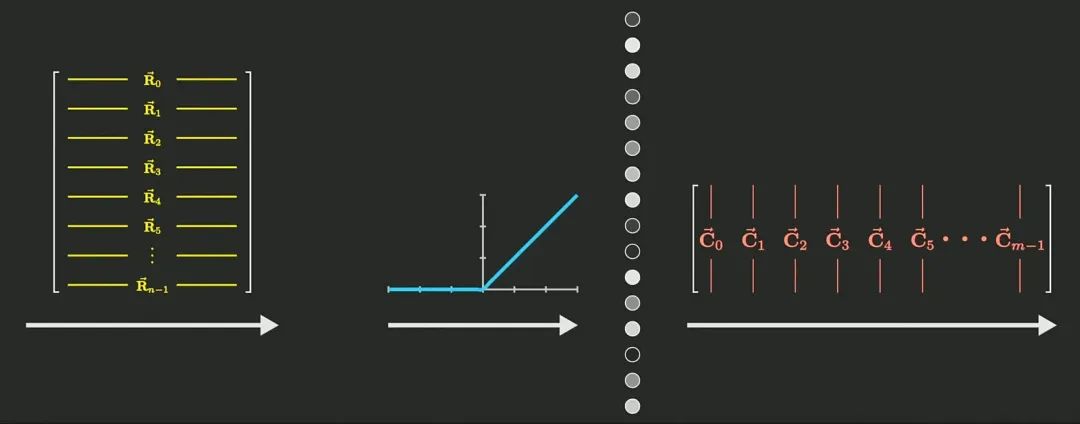
X是隱藏層的最終輸出,其維度是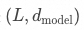 ,
,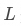 是輸入序列的長度,
是輸入序列的長度,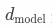 是隱藏層的維度。而
是隱藏層的維度。而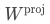 是通過訓練獲得的權重矩陣,其維度是
是通過訓練獲得的權重矩陣,其維度是 ,
,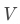 是詞匯表的大小,比如Qwen2-72B的詞匯表大小是151646。通過矩陣相乘,再與偏置bias相加,就可以將隱藏狀態轉換為輸出詞元的分數,也就是
是詞匯表的大小,比如Qwen2-72B的詞匯表大小是151646。通過矩陣相乘,再與偏置bias相加,就可以將隱藏狀態轉換為輸出詞元的分數,也就是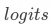 ,它代表了模型經過“思考”后的特征,用哪個“詞元”來形容更合適。
,它代表了模型經過“思考”后的特征,用哪個“詞元”來形容更合適。
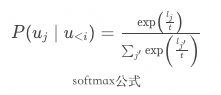
然后將通過歸一化操作(Softmax),轉換為詞元的概率,在此基礎上結合解碼策略,就可以選擇具體的下一個詞元進行輸出。這個公式非常簡單,其中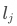 就是某一個詞元的分數。通過將指數函數應用于形成
就是某一個詞元的分數。通過將指數函數應用于形成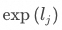 ,不僅可以確保詞元分數的數值為正(便于轉換為概率),還能增加不同分數之間的差異性。最后將單個詞元的分數,與所有詞元的分數之和相除,就能得到單個詞元的概率,如此就能獲得詞匯表中每個詞元的概率分布。
,不僅可以確保詞元分數的數值為正(便于轉換為概率),還能增加不同分數之間的差異性。最后將單個詞元的分數,與所有詞元的分數之和相除,就能得到單個詞元的概率,如此就能獲得詞匯表中每個詞元的概率分布。
此時,你可能會好奇,那個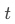 是什么?指的是temperature,沒錯就是我們在神機平臺上常常見到的那個大模型節點的參數,它通過影響softmax后的概率,來影響最終輸出概率分布的平滑程度。類似作用的還有top_p參數,這也是在模型的輸出層起作用。這些參數很重要,并且我們在開發過程中會常常遇到。 至此,模型的推理過程核心內容就都講述清楚了,當然還有很多內容,比如分詞、詞嵌入、位置編碼、殘差連接、層歸一化、以及FFN之后又興起的MoE架構等內容,篇幅所限,此處不再展開。
是什么?指的是temperature,沒錯就是我們在神機平臺上常常見到的那個大模型節點的參數,它通過影響softmax后的概率,來影響最終輸出概率分布的平滑程度。類似作用的還有top_p參數,這也是在模型的輸出層起作用。這些參數很重要,并且我們在開發過程中會常常遇到。 至此,模型的推理過程核心內容就都講述清楚了,當然還有很多內容,比如分詞、詞嵌入、位置編碼、殘差連接、層歸一化、以及FFN之后又興起的MoE架構等內容,篇幅所限,此處不再展開。
寫在最后
提示工程
Prompt Engineering(提示工程),則是指針對特定任務設計合適的任務提示(Prompt)的過程。? 在大模型的開發和性能優化的過程中,OpenAI建議將提示工程作為大模型應用的起點,從上下文優化、大模型優化兩個角度思考,這兩種角度對應了兩個方向:提示工程、微調。
提示工程:通過精心設計的輸入提示(Prompt)來引導預訓練模型生成期望的輸出,而無需對模型的權重進行調整。
微調:微調是在預訓練模型的基礎上,使用特定任務的數據進一步訓練模型,以調整模型權重,使其更好地適應特定任務。
提示工程側重于優化輸入數據的形式和內容,以激發模型的潛在能力,來提高輸出的準確性和相關性。它可以快速適應新任務。而微調可以使模型更深入地理解特定領域的知識和語言模式,進而顯著提高模型在特定任務上的性能,但其在靈活性上相對較弱,訓練依賴于計算資源和高質量的標注數據。對于高德的業務團隊而言,會相對更側重靈活性來適應快速變化的業務需求,因此基于提示工程進行優化的方法已經成為我們使用大語言模型解決下游任務的主要途徑。? 實際上不僅僅對于業務團隊,對于任何團隊,在使用大模型時,都應從提示工程開始。OpenAI針對需要提供給大模型額外知識的場景提供了一份合理的優化路線圖(如下圖):從基礎Prompt開始,通過提示工程優化Prompt,接入簡單RAG,進行模型微調,接入高級ARG,最后帶著RAG樣本進行模型微調。
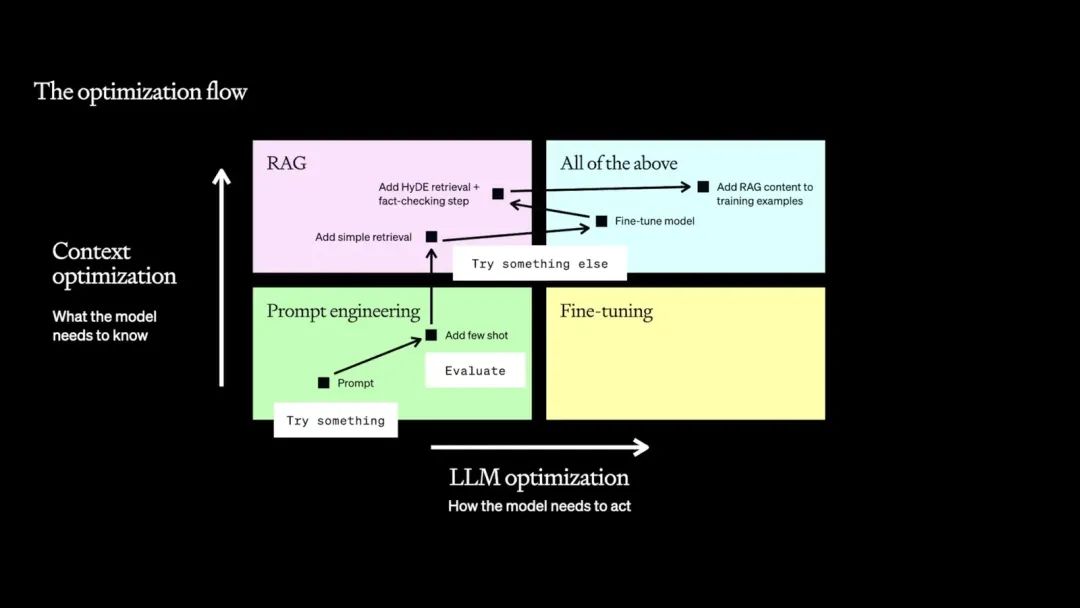
OpenAI: How to maximize LLM performance(https://humanloop.com/blog/optimizing-llms) 通過提示工程我們可以應對大部分的業務場景,如果性能不夠,第一件事是要考慮提示工程,再考慮其他手段。RAG的功能是上下文增強,其輸出結果是提示詞的一部分,因此RAG也可以視為提示工程的一部分。而對于有垂類場景模型需求的場景,也需要通過提示工程來獲取高質量的用例數據,來進行模型微調,再基于微調后模型產出的更高質量用例,正向迭代來進一步優化性能。 對于開發人員而言,如果希望提升馴化大模型的能力,我建議從提示工程開始。這包括了提示詞結構化(LangGPT等)、提示設計方法(如OpenAI提出的六大原則)、提示框架(ReACT等)、提示技術(COT、Few-Shot、RAG等)、Agent的概念和架構。?
-
人工智能
+關注
關注
1793文章
47567瀏覽量
239415 -
GPT
+關注
關注
0文章
356瀏覽量
15454
原文標題:一文徹底講透GPT架構及推理原理
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
使用TC21x的GPT實現1m計時器執行定時任務,怎么配置GTM和GPT?
GPT定時器?基本知識詳解
GPT高精度延時定時器簡介
GPT2模塊的相關資料推薦
使用NVIDIA TensorRT優化T5和GPT-2

使用FasterTransformer和Triton推理服務器部署GPT-J和T5
ChatGPT/GPT的原理 ChatGPT的技術架構
GPT/GPT-2/GPT-3/InstructGPT進化之路
GPT-4拿下最難數學推理數據集新SOTA!新型Prompting讓大模型推理能力狂升!

將客戶360度系統與GPT API集成:技術架構視角
爆了!GPT-4模型架構、訓練成本、數據集信息都被扒出來了

GPT-4沒有推理能力嗎?





 工商網監
工商網監
評論