 FP8在大模型訓練中的應用
FP8在大模型訓練中的應用
越來越多的技術團隊開始使用 FP8 進行大模型訓練,這主要因為 FP8 有很多技術優勢。比如在新一代的 GPU 上,FP8 相對于 BF16 對矩陣乘算子這樣的計算密集型算子,NVIDIATensorCores能夠提供兩倍的峰值性能,相對于 TF32 能夠提供四倍的加速,從而大大縮短計算密集型算子的計算時間。而對于訪存密集型的算子,由于 FP8 所需的數據量更少,可以減輕訪存壓力,加速這些算子。如果在訓練時使用 FP8 精度,可以更方便快速的將 FP8 部署到推理側,使 FP8 訓練可以更容易順暢地與低精度推理相結合等。
同時,由于 FP8 的動態范圍和精度相對于之前使用的 FP16/BF16/FP32 更小,如果使用 FP8 代替原來的數值精度進行訓練,技術團隊在模型和數據集上可能會遇到 FP8 精度的挑戰。
FP8 訓練的主要問題及解決思路
通過與很多技術團隊交流,我們把 FP8 訓練的主要問題分為以下三類,并且對可以考慮的解決思路做一個簡單介紹。
Spike 問題,即 Loss Spike。其實這并不是 FP8 特有的問題,在 BF16 中也可能遇到。引起 Loss Spike 的原因比較多,比如可能與選擇的算法有關,目前沒有特定的解決方案。但如果 FP8 的 Spike 與 BF16 類似,我們大概率可以認為這是一個通用問題;但如果 FP8 的 Spike 更多且需要多次迭代才能恢復正常,則可能是 FP8 訓練存在問題,需要進一步檢查。
FP8 的 Loss 問題,可能會遇到 Loss 增加或發散的情況。我們又可以將其分為三種情況:
o 情況 1:訓練開始時 Loss 就發散,這通常是軟件問題,可能存在 Bug,建議使用 NVIDIA 最新的NeMo /Mcore (Megatron Core) /TE (Transformer Engine)版本來減少出錯概率。
o 情況 2:檢查訓練配置,是否使用了新的優化點,如 CPU offloading、FP8 parameters 等新功能。可以嘗試先關閉這些功能,看看是否是由此導致的問題。
o 情況 3:數值問題也可能導致 Loss 問題,可以嘗試使用 BF16 進行 FP8 計算,輸入為 FP8 tensor,但使用 BF16 的 GEMM。Loss 問題發生在訓練中期,比如訓練了幾百個 token 后突然出現 Loss 上漲或發散,可以嘗試其他 recipe,如 current scaling 或 fangrand scaling,或將某些層 fallback 到 BF16。最近的研究表明,因為首層和最后一層更敏感,將第一層和最后一層 fallback 到 BF16 效果提升明顯。
Loss 沒有問題,但下游任務指標與 BF16 有差距,也可以概括為兩種情況。
o 情況 1:所有下游任務指標都有問題。建議檢查下游任務指標的 inference 流程是否正確,如是否讀取了正確的 scaling factor 和 weight。也可能是某些任務有問題,但其他任務可以與 BF16 對齊,這時可以嘗試改變 FP8 訓練的 recipe,嘗試 current scaling 或部分層 fallback 到 BF16。
o 情況 2:inference 使用 BF16,但訓練使用 FP8。由于模型已經是 FP8 訓練的結果,使用 BF16 進行 inference 可能會引入更多誤差。建議嘗試使用 FP8 訓練加 FP8 inference,看看下游任務打分是否恢復正常。
FP8 Debug 工具介紹
針對 FP8 訓練過程中的 Debug 思路,可以參考“探索 FP8 訓練中 Debug 思路與技巧”技術博客里面的總結:
https://developer.nvidia.com/zh-cn/blog/fp8-training-debug-tips/

圖片來源于 NVIDIA FP8 debug 工具
FP8 的訓練效果我們一般通過觀察 Loss 曲線或下游任務的指標來進行評估。比如,會檢查 Loss 是否發散,從而判斷 FP8 是否有問題。同時我們也希望找到一些其他指標,能在訓練過程中用于評估 FP8 的穩定性。此外,我們還希望通過一些指標來評估量化的誤差,如果出現 FP8 訓練問題,問題是發生在某個特定的層或張量上。通過這些深入的了解,我們可以幫助選擇更好的訓練方案,同時在訓練過程中進行調整。
因此我們開發了一個 FP8 Debug 工具,這個工具中包含了一些指標,用于觀察 FP8 訓練的狀態,包括MSE 和余弦相似性(用于 BF16 和 FP8 之間的量化誤差),Tensor 的 Underflow 和 Overflow(用于查看是否因為 FP8 的動態范圍比 BF16 小而導致過多的 Underflow 或 Overflow,進而引起的精度問題)。
其次,我們還記錄了一些統計值,如對比 Delayed Scaling 的 Scaling Factor 與使用當前 Tensor 的 Current Scaling 的 Scaling Factor 之間的誤差(這代表 Delayed Scaling 是否能準確表征當前 Tensor 的表現)。
除了這些指標外,我們還可以將這些 Tensor Dump 出來,并動態選擇 Dump 哪些層,記錄這些指標。
目前這個工具可以與 NVIDIA 任何版本的NeMo Megatron兼容,沒有改動這些框架的內部代碼,因此無論使用哪個版本的框架,都可以使用這個工具進行相應的分析。

在使用 Debug 工具進行分析的時候,我們會 Dump 一些 Tensor 并進行分析,可以看到:
包括了 Tensor 的名稱和 Layer 的名稱,即哪一層的哪一個 Tensor。例如,我們會 Dump Forward 的 Input,即 GEMM 的 Input 和 Weight,以及反向傳播時的 Dy 的 Tensor。
可以周期性地打印不同 Step 的結果,觀察整個過程中的變化,從而了解不同 Step 的情況。
可以觀察不同的指標,如 AMin 和 AMax,以及 Current Scaling 和 Delay Scaling 這兩種 Scaling 的區別。
通過打印出來的值,觀察余弦相似性 MSE 這兩種量化誤差,以及 Underflow 和 Overflow 的比例來判斷表現。
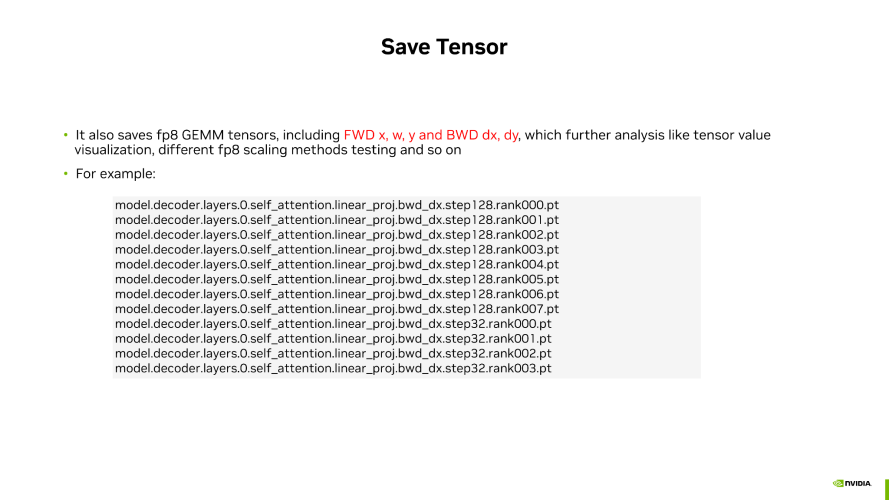
數據來源于 NVIDIAFP8 debug工具
工具也可以將對應的 FP8 Tensor 保存下來,以便后期進行更多的指標分析。
這些指標主要來自我們技術團隊基于一些技術論文以及業務實踐中的討論和總結。
內部實驗中觀察到的案例:
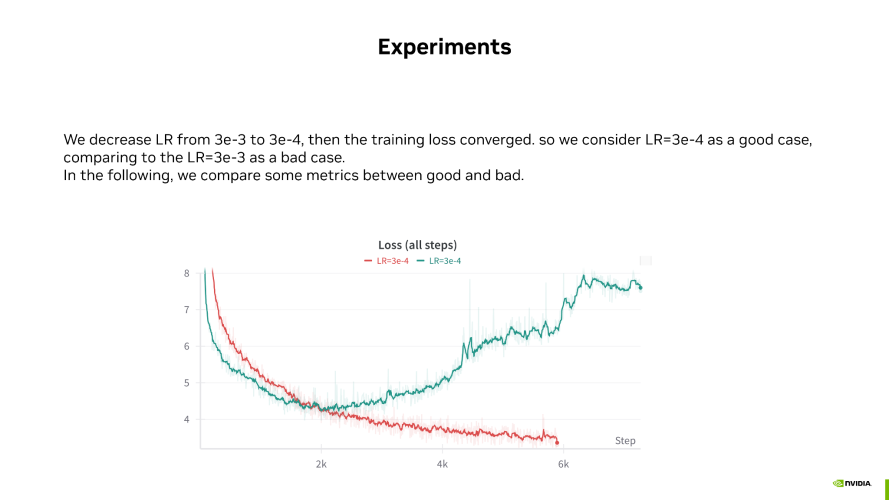
數據來源于 NVIDIAFP8 debug工具
如上圖所示,紅色線條代表 FP8 正常收斂的 good case,沒有出現 Loss 發散,Loss 在正常下降。而綠色線條則代表 FP8 的 bad case,訓練到 2000 步后開始發散。這兩個 case 是我們人為構造的,通過調整學習率來展示 good case 和 bad case。
以下是幾個指標情況:
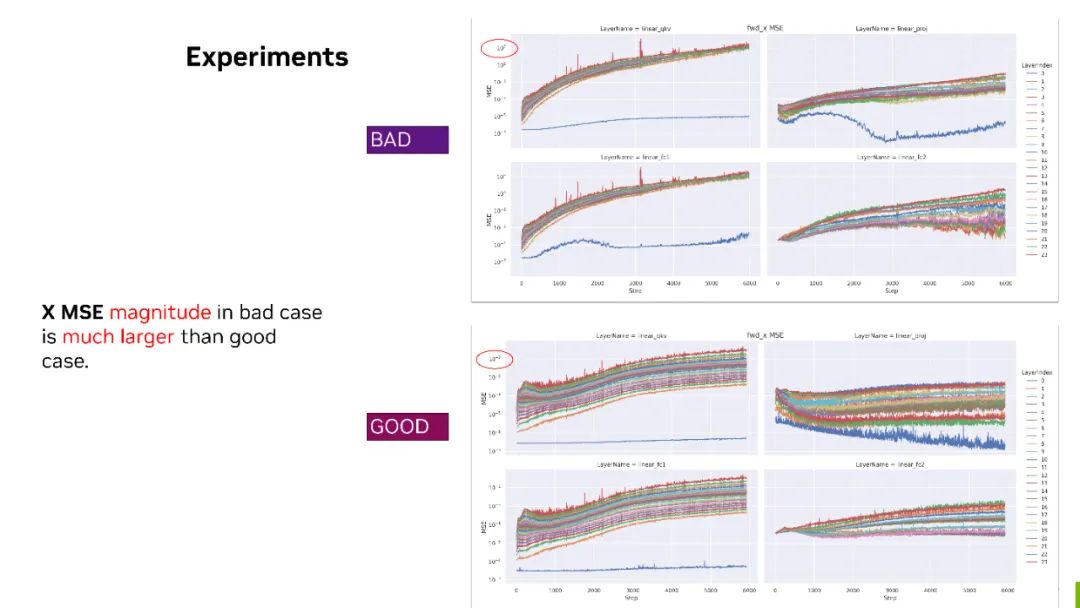
數據來源于 NVIDIA 內部實驗
MSE - 這個指標上邊的是 bad case,下邊是 good case。我們把這兩個放在一起,可以看到對于 forward X,bad case 下幾個矩陣的 MSE 最大值都已經達到了 10 的三次方。也就是說 FP8 和 BF16 的量化誤差已經到了 10 的三次方。但是對于 good case 來說,量化誤差其實只有 10 的負二次方。通過這樣的對比,我們可以看到對于 forward X 的 tensor 來說,它可能是有問題的。
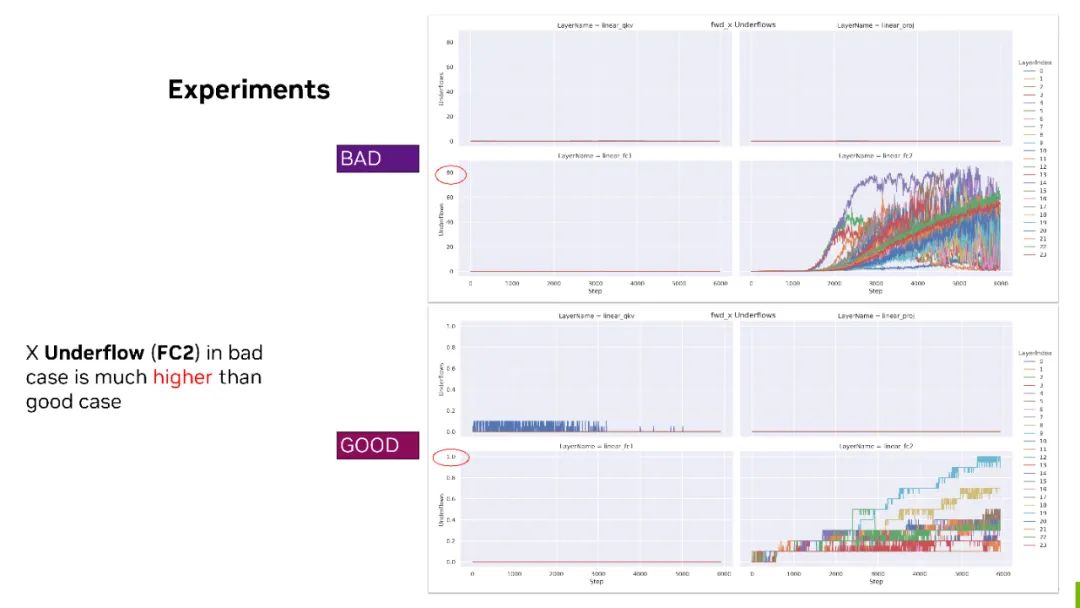
數據來源于 NVIDIA 內部實驗
Underflow 對比 - bad case 上 FC2 的 forward X,有 80% 的最大 Underflow 比率。但對于下邊 good case 來說,它最大的情況下也只有 1% 。
所以對于 forward 的 FC2 來說,X 可能需要格外關注并考慮,比如是否要 fallback 到 BF16?或者用一些其他的 scaling 策略來保證它的精度。
目前,FP8 Debug 工具還在內部測試階段,如果希望了解或嘗試該工具,可以聯系您對接的 NVIDIA 技術團隊,也歡迎您提供建議共同豐富這個工具的功能。
本文摘選自“NVIDIA AI加速精講堂 —— FP8在大模型訓練中的應用、挑戰及實踐”,可訪問NVIDIA 官網觀看完整在線演講。
關于作者
黃雪
NVIDIA 解決方案架構師,碩士畢業于哈爾濱工業大學,主要負責深度學習訓練方面工作,在深度學習框架、超大規模模型訓練,分布式模型訓練加速優化等技術方向有豐富的研究經驗。
GTC 2025 將于2025 年 3 月 17 至 21 日在美國加州圣何塞及線上同步舉行。
-
NVIDIA
+關注
關注
14文章
5072瀏覽量
103520 -
gpu
+關注
關注
28文章
4767瀏覽量
129209 -
大模型
+關注
關注
2文章
2533瀏覽量
3006
原文標題:FP8 在大模型訓練中的應用、挑戰及實踐
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【大語言模型:原理與工程實踐】大語言模型的預訓練
Pytorch模型訓練實用PDF教程【中文】
基于Keras利用訓練好的hdf5模型進行目標檢測實現輸出模型中的表情或性別gradcam
在Ubuntu上使用Nvidia GPU訓練模型
分享一種用于神經網絡處理的新8位浮點交換格式
小米在預訓練模型的探索與優化

【AI簡報20231103期】ChatGPT參數揭秘,中文最強開源大模型來了!

FP8在NVIDIA GPU架構和軟件系統中的應用


FP8模型訓練中Debug優化思路






 工商網監
工商網監
評論