 Llama 7B大語言模型本地部署全攻略!一步步教你輕松上手
Llama 7B大語言模型本地部署全攻略!一步步教你輕松上手
隨著大模型技術不斷迭代,AI大模型的應用與推理訓練已從云端部署迅速向本地化、場景化發展,成為推動產業升級的重要力量。LLaMA 7B作為一款輕量化的大規模語言模型,以其卓越的語言理解與生成能力,逐步成為智能化應用的理想選擇,廣泛適用于智能客服、內容審核、文本生成、翻譯等多個場景,為企業提供了經濟高效的解決方案,推動行業智能化轉型。
本期樣例使用英碼科技EA500I Mini部署meta-llama/Llama-2-7b-hf和TinyLlama/TinyLlama-1.1B-Chat-v1.0大語言模型,在本地實現多模態處理和自然語言處理功能,助力企業將大模型技術落地到垂直行業應用中,加快智能化升級。

環境搭建 (視頻演示版:https://www.bilibili.com/video/BV1MofEY9E69/?spm_id_from=333.1387.homepage.video_card.click)
參考鏈接:ascend-llm: 基于昇騰310芯片的大語言模型部署
硬件環境:英碼科技EA500I Mini
軟件環境:CANN-7.0.1.1
進入EA500I Mini終端,下載源碼
cd $HOME tar -zxvf ascend-llm.tar.gz cd $HOME/ascend-llm/inference pip install -r requirements.txt cd $HOME/ascend-llm/export_llama pip install -r requirements.txt
算子適配
1. protoc 安裝
根據昇騰文檔選擇合適的protoc版本,protoc版本和CANN版本強相關。CANN7.0/7.2使用的protoc 1.13.0。
# 安裝protoc==1.13.0, 找一空閑目錄下載 wget https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/wanzutao/tiny-llama/protobuf-all-3.13.0.tar.gz --no-check-certificate tar -zxvf protobuf-all-3.13.0.tar.gz cd protobuf-3.13.0 apt-get update apt-get install autoconf automake libtool ./autogen.sh ./configure make -j4 make install sudo ldconfig protoc --version # 查看版本號
查看版本號,如下圖即完成

2. 算子編譯部署
# 將./custom_op/matmul_integer_plugin.cc 拷貝到指定路徑 cd ascend-llm export ASCEND_PATH=/usr/local/Ascend/ascend-toolkit/latest cp custom_op/matmul_integer_plugin.cc $ASCEND_PATH/tools/msopgen/template/custom_operator_sample/DSL/Onnx/framework/onnx_plugin/ cd $ASCEND_PATH/tools/msopgen/template/custom_operator_sample/DSL/Onnx
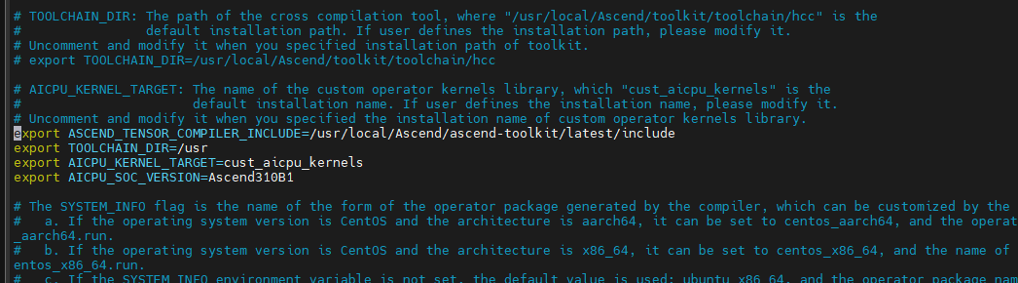
打開build.sh,找到下面四個環境變量,解開注釋并修改如下:
export ASCEND_TENSOR_COMPILER_INCLUDE=/usr/local/Ascend/ascend-toolkit/latest/include export TOOLCHAIN_DIR=/usr export AICPU_KERNEL_TARGET=cust_aicpu_kernels export AICPU_SOC_VERSION=Ascend310B1
編譯運行
./build.sh cd build_out/ ./custom_opp_ubuntu_aarch64.run # 生成文件到customize到默認目錄 $ASCEND_PATH/opp/vendors/,刪除冗余文件 cd $ASCEND_PATH/opp/vendors/customize rm -rf op_impl/ op_proto/
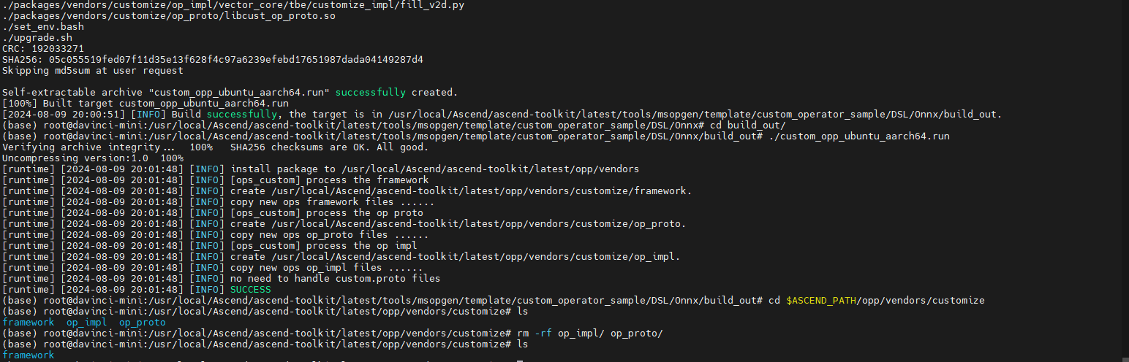
完成算子的編譯部署
模型量化與轉換
注意事項:該步驟可以直接使用資料已經量化轉換好的模型
1.導出onnx 模型
將transformer庫中的modeling_llama替換為export_llama文件下的modeling_llama。
可以通過 pip show transformers 命令找到 transformers 的庫路徑,然后通過cp命令復制。

通過一下命令將模型導出為onnx(相對路徑均為相對export_llama.py文件)
python export_llama.py --model --output --act-path --quant
2.模型量化
量化需要引入quantize.py和config文件下的配置文件,詳情查看 export_llama 的readme文件。本樣例將直接使用已經量化好的模型文件,對于TinyLlama-1.1B采用per-token的absmax量化(即w8x8.py);對于Llama-2-7b-hf,采用靜態混合精度分解(即sd.py)。
3.模型轉換
atc --framework=5 --model="xxx.onnx" --output="xxx" --input_format=ND --input_shape="input_ids:batch,seq_len;attention_mask:batch,seq_len+kv_len;position_ids:batch,seq_len;past_key_values:n_layer,2,batch,n_head,kv_len,head_dim" --log=debug --soc_version=Ascend310B1 --precision_mode=must_keep_origin_dtype
上述的n_layer, n_head, head_dim變量由模型決定。對于Llama-2-7b,n_layer=32, n_head=32, head_dim=128;對于TinyLlama-1.1B,n_layer=22, n_head=4, head_dim=64
對于batch, seq_len, kv_len, 請根據需要填入,建議設置batch=1, seq_len=1, kv_len=1024。如對于TinyLlama-1.1B
atc --framework=5 --model="./tiny-llama.onnx" --output="tiny-llama" --input_format=ND --input_shape="input_ids:1,1;attention_mask:1,1025;position_ids:1,1;past_key_values:22,2,1,4,1024,64" --log=debug --soc_version=Ascend310B1 --precision_mode=must_keep_origin_dtype
模型推理
從資料鏈接里已經量化導出的模型
項目提供了兩種運行方式:
1. cli模式:在終端運行,每一次輸入一行,一次性返回所有的推理結果。
2. web模式:前端代碼在github或者gitee,打包出dist文件夾,放在inference文件夾下即可。
采取cli模式如下:
cd inference python main.py --model --hf-dir # 需要tokenizer和模型配置文件,權重不需要 --engine --sampling --sampling_value --temperature #采樣相關配置 --cli # 添加--cli表示在終端運行
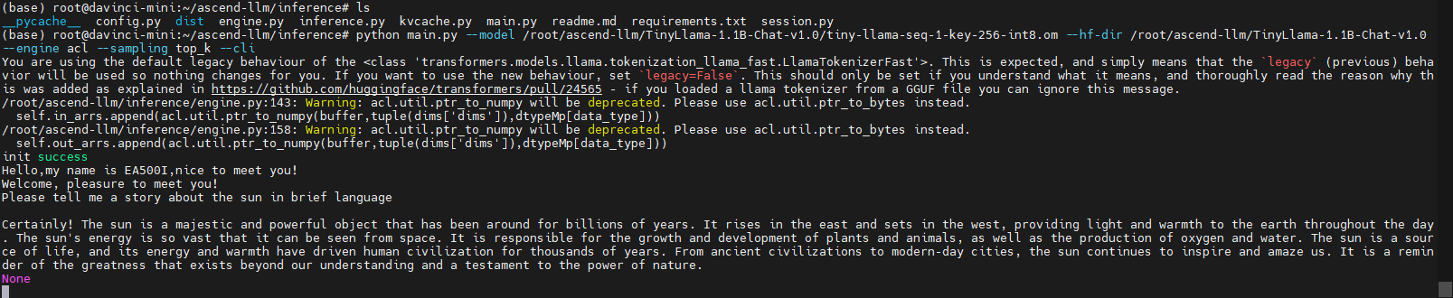
TinyLlama-1.1B-Chat-v1.0推理運行
python main.py --model /root/ascend-llm/TinyLlama-1.1B-Chat-v1.0/tiny-llama-seq-1-key-256-int8.om --hf-dir /root/ascend-llm/TinyLlama-1.1B-Chat-v1.0 --engine acl --sampling top_k --cli
效果展示
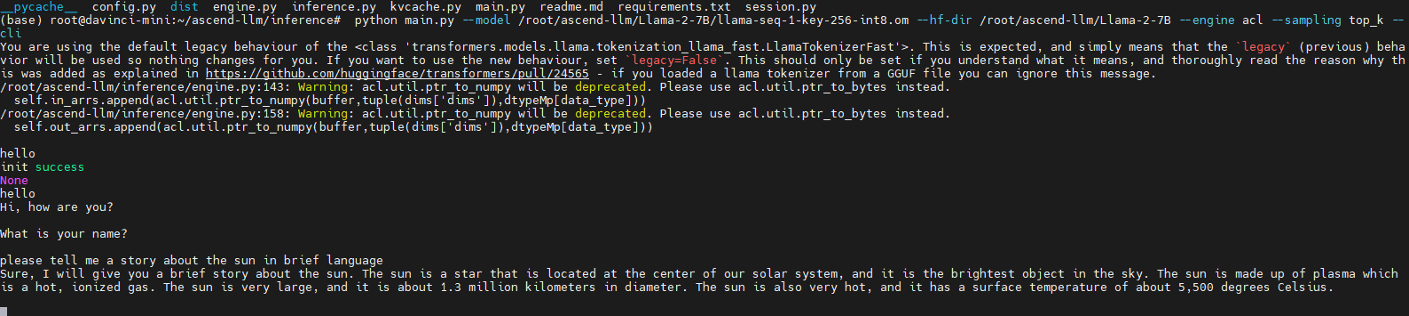
Llama-2-7B推理運行
python main.py --model /root/ascend-llm/Llama-2-7B/llama-seq-1-key-256-int8.om --hf-dir /root/ascend-llm/Llama-2-7B --engine acl --sampling top_k --cli
效果展示
安裝LLM_WEB
nodejs安裝 20.12.2
sudo apt update sudo apt-get remove nodejs sudo apt autoremove sudo whereis node sudo rm -rf /usr/local/bin/node sudo apt-get update sudo apt install curl curl -fsSL https://deb.nodesource.com/setup_20.x | sudo -E bash - sudo apt install -y nodejs node -v

npm安裝10.5.0 (對應nodejs==20.12.2)
sudo apt install npm sudo npm install -g npm@10.5.0 npm -v
npm安裝pnpm
# 如遇FATAL ERROR: NewSpace::EnsureCurrentCapacity Allocation failed - JavaScript heap out of memory 報錯嘗試清下緩存,如下 npm cache clean --forcenpm config set registry https://registry.npmjs.org/npm install -g pnpm
打包步驟
clone本倉到本地,進入本地倉目錄,執行以下命令```pnpm install npm run build``` 進入/root/ascend-llm/inference目錄 執行 python main.py --model /root/ascend-llm/TinyLlama-1.1B-Chat-v1.0/tiny-llama-seq-1-key-256-int8.om --hf-dir /root/ascend-llm/TinyLlama-1.1B-Chat-v1.0 --engine acl --sampling top_k
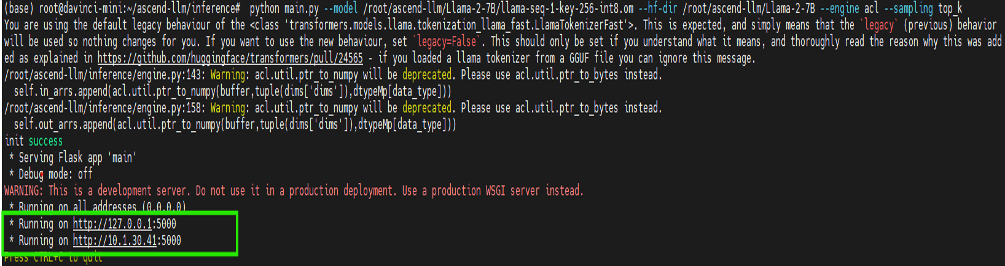
復制地址到瀏覽器開始與模型對話
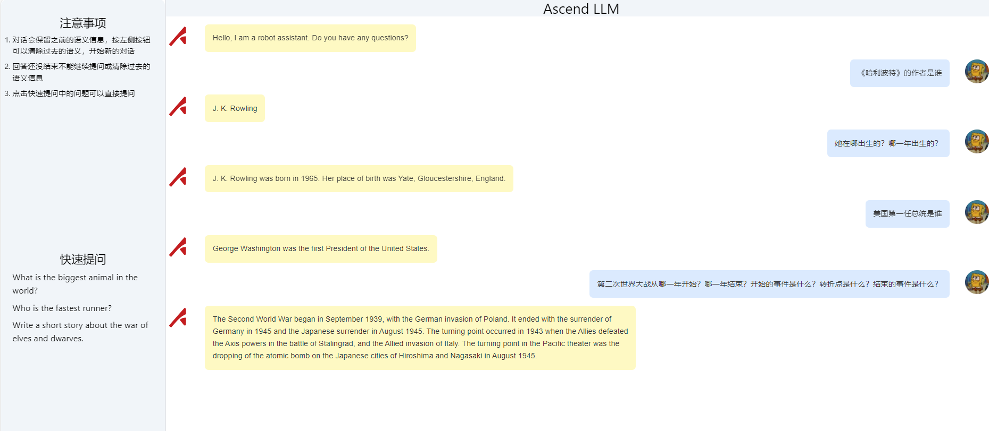
結語
以上就是英碼科技昇騰產品系列EA500I Mini邊緣計算盒子適配大模型Llama 7B的完整部署流程。未來,我們將持續推出更多基于昇騰AI芯片產品的技術干貨,歡迎大家留言告訴我們您希望了解哪些內容,我們會根據需求整理并分享!
-
AI芯片
+關注
關注
17文章
1904瀏覽量
35159 -
大模型
+關注
關注
2文章
2541瀏覽量
3012
發布評論請先 登錄
相關推薦
CC2530一步步演示程序燒寫
一步步進行調試GPRS模塊


基于一步步蒸餾(Distilling step-by-step)機制
用Ollama輕松搞定Llama 3.2 Vision模型本地部署






 工商網監
工商網監
評論