 穿過幻覺荒野,大模型RAG越野賽
穿過幻覺荒野,大模型RAG越野賽

2025年初,大模型賽場熱度不減,有拼成本優勢,拼Tokens調用量的短跑賽;有比慢思考,比大模型推理能力的長跑賽。但在觀看這些“經典賽事”的同時,我們還需要注意另一場正在舉行中,并且對大模型行業未來至關重要的比賽——RAG越野賽。
所謂RAG,是指Retrieval-Augmented Generation檢索增強生成。顧名思義,RAG是將大語言模型的生成能力與搜索引擎的信息檢索能力進行結合,這已經成為目前主流大模型的標配。
之所以說RAG是一場越野賽,是因為大模型最被人質疑的問題,就是生成內容時經常會出現有明顯訛誤的大模型幻覺。這些幻覺就像崇山峻嶺,遮擋了大模型的進化之路。
而RAG的戰略價值,就在于它是克服大模型幻覺的核心方案。換言之,誰能贏得RAG越野賽,誰就能解決大模型的核心痛點,將AI帶到下一個時代。
讓我們進入大模型RAG的賽道,看看這場越野將把AI帶向何方。

讓我們先把時針調回到你第一次接觸大語言模型的時候。初次嘗試與大模型聊天,驚艷之外,是不是感覺好像有哪里不對?
這種不適感,很可能來自大模型的三個問題:
1.胡言亂語。對話過程中,我們經常會發現大模型說一些明顯不符合常識的話,比如“林黛玉的哥哥是林沖”“魯智深是法國文學家”之類的。這就是LLM模型的運行原理,導致其在內容生成過程中會為了生成而生成,不管信息正確與否。這也就是廣受詬病的大模型幻覺。業內普遍認為,幻覺不除,大模型就始終是玩具而非工具。
2.信息落后。大模型還有一個問題,就是知識庫更新較慢,從而導致如果我們問近期發生的新聞與實時熱點它都無法回答。但問題在于,我們工作生活中的主要問題都具有時效性,這導致大模型的實用價值大打折扣。
3.缺乏根據。另一種情況是,大模型給出了回答,但我們無法判斷這些回答的真偽和可靠性。畢竟我們知道有大模型幻覺的存在,進而會對AGIC產生疑慮。我們更希望能夠讓大模型像論文一樣標注每條信息的來源,從而降低辨別成本。
這些問題可以被統稱為“幻覺荒野”。而想要穿越這片荒野,最佳途徑就是將大模型的理解、生成能力,與搜索引擎的信息檢索融合在一起。
因為信息檢索能夠給大模型提供具有時效性的信息,并且指明每條信息的來源。在檢索帶來的信息庫加持下,大模型也可以不再“胡言亂語”。
檢索是方法,生成是目的,通過高質量的檢索系統,大模型有望克服幻覺這個最大挑戰。
于是,RAG技術應運而生。

在RAG賽道上,檢索的優劣將很大程度上影響生成模型最終生成結果的優劣。比如說,百度在中文搜索領域的積累,帶來了語料、語義理解、知識圖譜等方面的積淀。這些積淀有助于提升中文RAG的質量,從而讓RAG技術更快在中文大模型中落地。在搜索引擎領域,百度構建了龐大的知識庫與實時數據體系,在眾多需要專業檢索的垂直領域進行了重點布局。
其實,把搜索領域的積累,第一時間帶到大模型領域,這一點并不容易。因為我們都知道,面向人類的搜索結果并不適合大模型來閱讀理解。想要實現高質量的RAG,就需要尋找能夠高效支持搜索業務場景和大模型生成場景的架構解決方案。
百度早在2023年3月發布文心一言時就提出了檢索增強,大模型發展到今天,檢索增強也早成為業界共識。百度檢索增強融合了大模型能力和搜索系統,構建了“理解-檢索-生成”的協同優化技術,提升了模型技術及應用效果。通俗來看,理解階段,基于大模型理解用戶需求,對知識點進行拆解;檢索階段,面向大模型進行搜索排序優化,并將搜索返回的異構信息統一表示,送給大模型;生成階段,綜合不同來源的信息做出判斷,并基于大模型邏輯推理能力,解決信息沖突等問題,從而生成準確率高、時效性好的答案。
就這樣,RAG成為百度文心大模型的核心差異化技術路徑。可以說,檢索增強成為文心大模型的一張名片。
讓我們隨便問個問題,測測
如今,基本主流大模型都會提供RAG體驗,比如告知用戶模型調用了多少個網頁,檢索信息的出處在哪里等。但RAG這場越野賽依舊有著鮮明的身位差距,想要知道這個排位方法也非常簡單,隨便問各款大模型一個相同的問題就可以。
比如說,春節將至,逛廟會是北京春節必不可少的一部分。但北京春節廟會眾多,小伙伴們肯定會想知道哪個廟會更適合自己,以及他們的營業時間是怎么樣的。
于是,我把“北京春節廟會哪個更推薦?它們的營業時間是什么?”分別提問給百度文心一言、豆包、Kimi、DeepSeek等。在這里,文心一言我們使用的是付費版,文心大模型4.0 Turbo。
文心一言的答案是這樣的,首先它結合檢索到的信息,推薦了數十個北京的春節廟會,并且列出了每個廟會的地點、時間等信息。


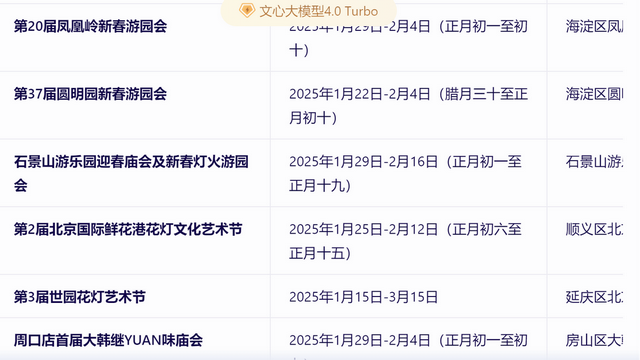
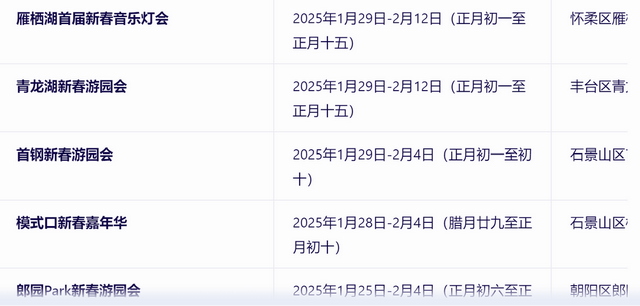
但到這里還沒有結束,接下來文心一言還進行了總結。


可以看到,文心一言理解了我“最推薦”的提問,給出眾多選項的同時,還主要推薦了東岳廟廟會、地壇廟會、娘娘廟廟會、石景山游樂園廟會,并且給出了相應的推薦理由,做到了在信息全面化與推薦個性化之間達成平衡。
同樣的問題給到豆包,則會發現它的回答也非常不錯,但內容完整度上有所欠缺。

豆包的答案,是按照每類愛好者應該去哪個廟會進行分類,總共給出了7個廟會的信息。但需要注意的是,一方面豆包的答案在廟會數量和對每個廟會特色的介紹上都不夠詳盡。另外豆包沒有進行總結,并不符合問題中“哪個最推薦”的訴求。
同樣的問題給Kimi則是另一種景象。

不知道為什么,Kimi的答案里只回答了廠甸廟會一個答案,完全沒有提及其他廟會。這樣確實符合“最推薦”的需求,但未免過分片面和武斷,沒有讓用戶完整了解北京春節廟會的信息。
同樣的問題來問最近火熱的DeepSeek R1大模型,會發現它也能進行RAG深度聯網檢索,并且給出了思考過程,最終給出了10個廟會的推薦信息。


唯一稍顯不足的是,其最終也是只給出了幾個廟會的基本情況,沒有呼應“最推薦”哪個廟會的提問,并且其思考過程稍顯冗長,閱讀體驗也有待提升。
從中不難看出,在“今年春節去哪個廟會”這樣非常具有時效性與實用性的問答上,幾家大模型回答得都還可以,但還是有差異的。這背后就是RAG技術能力的差異。
單看RAG能力,文心一言在檢索增強,尤其是上面這類問答類需求上更顯優勢,另外我們也能看到,文心一言在結果呈現上調用了表格工具來結構化呈現結果。整體來說,在深度思考和工具調用上,文心一言表現不錯。
不難看出,檢索增強對大模型實用性和體驗感有著非常重要的影響。

RAG越野賽的持續,或許將會給整個數字世界帶來新的驚喜。
比如說,RAG可能是——
1.搜索引擎的新引擎。讓大模型理解信息檢索,也將反向帶給搜索引擎與全新發展動力,用戶的模糊性搜索、提問性搜索、多模態搜索將被更好滿足。
2.大語言模型的新支點。大模型不僅要生成內容,更要生成可信、可靠、即時的內容,想要實現這些目標,RAG是已經得到驗證的核心方向。
3.通往未來的一張船票。預訓練大模型只是故事的起點,而故事的高潮則在于創造AI原生應用的無盡可能性。理解、生成、檢索這些數智核心能力的相遇與融合,或許才能真正揭示出AI原生應用的底層邏輯與未來形態。
基礎模型本身是需要靠應用才能顯現出來價值。這個時代無數人在好奇,AI原生應用的核心載體應該是什么?
或許,理解、檢索與生成的結合就是方向。
又或許,RAG越野賽的盡頭就是答案。

-
AI
+關注
關注
87文章
31493瀏覽量
270096 -
大模型
+關注
關注
2文章
2544瀏覽量
3062
發布評論請先 登錄
相關推薦
【「基于大模型的RAG應用開發與優化」閱讀體驗】+Embedding技術解讀
【「基于大模型的RAG應用開發與優化」閱讀體驗】+大模型微調技術解讀
檢索增強型生成(RAG)系統詳解
借助浪潮信息元腦企智EPAI高效創建大模型RAG

RAG的概念及工作原理
名單公布!【書籍評測活動NO.52】基于大模型的RAG應用開發與優化
使用OpenVINO和LlamaIndex構建Agentic-RAG系統
TaD+RAG-緩解大模型“幻覺”的組合新療法
如何手擼一個自有知識庫的RAG系統
阿里達摩院提出“知識鏈”框架,降低大模型幻覺
【大語言模型:原理與工程實踐】大語言模型的應用
什么是RAG,RAG學習和實踐經驗
微軟下架最新大語言模型WizardLM-2,緣因“幻覺測試疏忽”
利用知識圖譜與Llama-Index技術構建大模型驅動的RAG系統(下)






 工商網監
工商網監
評論