

本期Kiwi Talks將從集群Scale Up互聯的需求出發,解析DeepSeek在張量并行及MoE專家并行方面采用的優化策略。DeepSeek大模型的工程優化以及國產AI 產業鏈的開源與快速部署預示著國產AI網絡自主自控將大有可為。
DeepSeekMoE架構融合了專家混合系統(MoE)、多頭注意力機制(Multi-Head Latent Attention, MLA)和RMSNorm三個核心組件。通過專家共享機制、動態路由算法等緩存技術,該模型在保持性能水平的同時,實現了相較傳統MoE模型40%的計算開銷降低。該技術在模型規模與計算效率之間找到了新的平衡點,其在降低計算成本的同時保持了領先的性能水平,為大規模AI系統的可持續發展提供了新的思路。
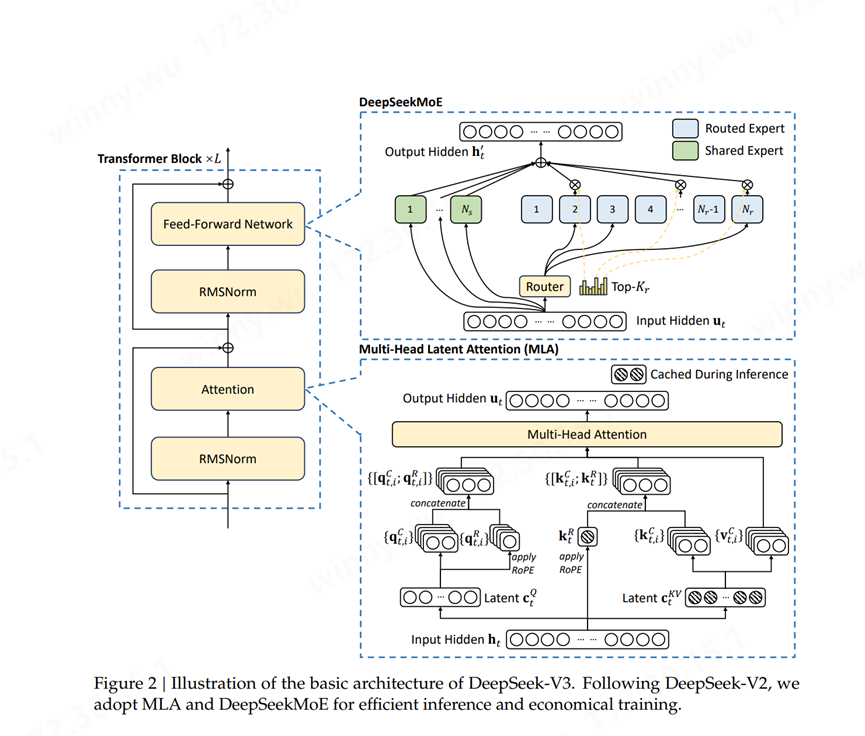
(來源:DeepSeek-V3 Technical Report) Scale Up互聯源頭:張量并行與專家并行
Scale Up互聯需求源頭:張量并行與專家并行
在大規模 AI 訓練中,GPU 通常使用各種并行技術協同工作。其中張量并行是指將大型張量分散到多個 GPU 上進行計算,這種技術對互聯帶寬和時延特別敏感。
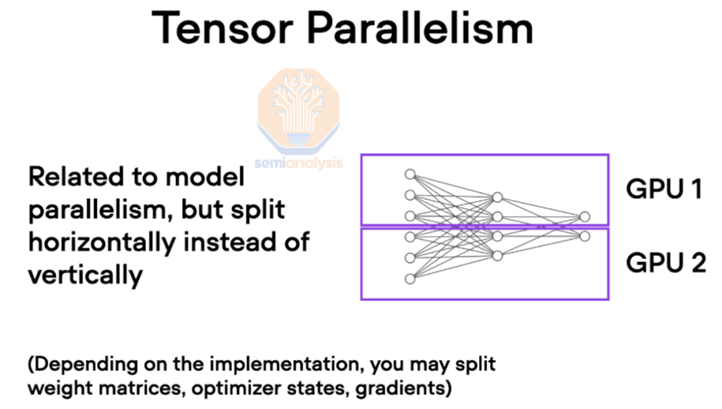
(來源:Semi analysis) 簡單來說,張量是人工智能模型中用來表示輸入、權重和中間計算的基本數據結構。在訓練大型 AI 模型時,這些張量可能會變得非常龐大,以至于無法放入單個 GPU 的內存中。為了解決這個問題,張量被拆分到多個 GPU 上,每個 GPU 處理一部分張量。這種劃分允許模型跨多個 GPU 擴展,從而能夠訓練比原本更大的模型。然而,分割張量需要 GPU 之間頻繁通信以同步計算并共享結果。這時互聯速度就變得至關重要。
(來源:Deepgram.com)
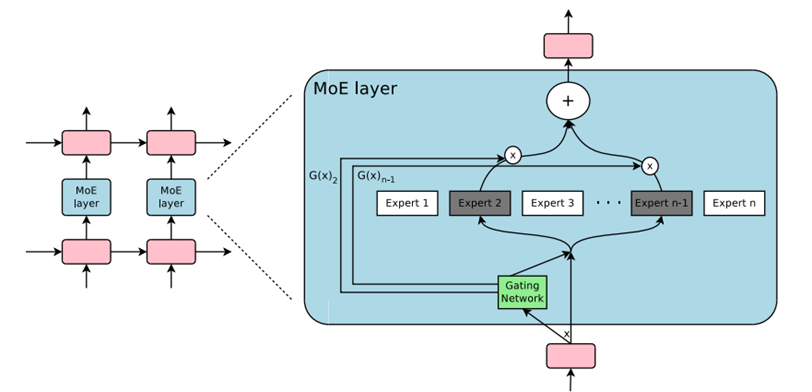
另一方面,MoE模型本身適合大規模、復雜任務、計算效率要求高且訓練復雜程度高。DeepSeek MoE多模態模型涉及專家并行,它將復雜的模型分解為多個專家模型,并在這些專家模型之間進行并行計算。在專家并行中,不同GPU負責不同的專家模型,同時Attention模塊在每個GPU上復制,由于每個專家模型需要單獨加載數據,因此對每個token施加了額外的內存帶寬需求。此外專家并行需要網絡支持高并發、有效的負載均衡機制以及故障容錯性等一系列復雜需求。
因此在Scale-up網絡中,張量并行和專家并行的策略對于大模型訓推的效率至關重要,也是AI網絡互聯網絡帶寬(TB級)和極低時延需求的源頭。
H800 中 NVLink 帶寬的降低會減慢此階段 GPU 之間的通信速度,從而導致延遲增加并降低整體訓練效率。在涉及具有數十億個參數的大型模型的場景中,這種瓶頸變得更加明顯,因為 GPU 之間需要頻繁通信來同步張量并行和專家并行。
在并行策略上,DeepSeek-V3使用64路的專家并行,16路的流水線并行,以及數據并行(ZeRO1)。其中,專家并行會引入all-to-all通信,由于每個token會激活8個專家,這導致跨節點的all-to-all通信開銷成為主要的系統瓶頸。
那么DeepSeek是如何通過算法工程優化來解決這些瓶頸并提升大模型訓推效率?
DeepSeek V3集群互聯框架概述
從DeepSeek公開的論文中數據來看: Scale Inside單個芯片使用英偉達H800,共計2048張計算卡。集群組網使用Infiniband網絡,Scale Up每個節點內通過NVLink互聯。GPU之間的帶寬是160GB,節點之間的帶寬是50GB。Scale Out網絡據推測,每個節點包含8個400Gb/s的智能網卡(H100/H800 上后向網絡通常都會采用 400 Gb/s網卡)。
路由優化策略降低TP開銷
在其公布的V3技術論文中所提及網絡集群中路由的優化策略:跨節點 GPU 與 IB 完全互連,節點內通信通過 NVLink 處理。NVLink 提供 160 GB/s 帶寬,大約是 IB(50 GB/s)的 3.2倍。為了有效利用IB和NVlink的帶寬差異,DeepSeek限制每個token最多分派到4個GPU節點,從而限制IB網絡的傳輸流量。當網絡路由決策確定后,它將首先通過IB傳輸到目標節點上具有相同節點內索引的GPU。一旦到達目標節點,努力確保它通過NVLink瞬時轉發到托管其目標專家的特定GPU,而不被隨后到達的token阻塞。這樣,通過IB和NVLink的通信完全重疊,每個token可以高效地在每個節點上選擇平均3.2個專家,而不會產生來自NVLink的額外開銷。這意味著,盡管DeepSeek-V3在實際中只選擇8個路由專家,但它可以將其數量擴大到最多13個專家(4個節點×每個節點3.2個專家),同時保持相同的通信成本。
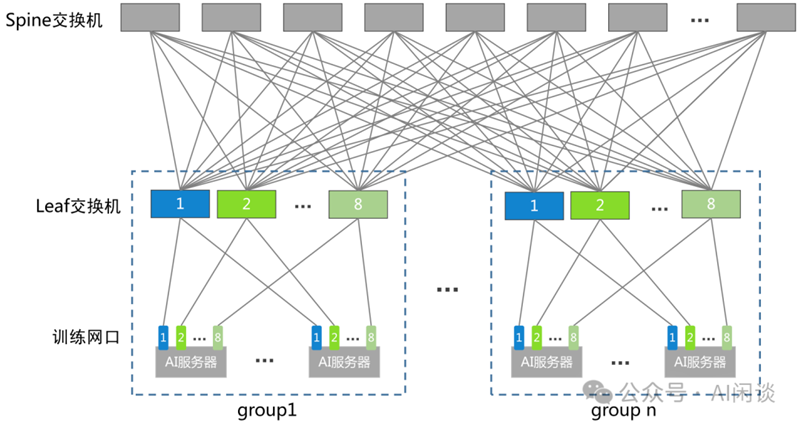
(來源:公眾號AI閑談)
這樣做是因為高性能 GPU 訓練集群往往會采用軌道優化,同號 GPU 在一個 Leaf Switch 下,如上圖所示,因此可以利用高速的 NVLink 來代替從 Leaf Switch 到 Spine Switch 的流量,從而降低 IB 通信時延,并且減少 Leaf Switch 和 Spine Switch 之間的流量。總體而言,在這種通信策略下,僅20個SM就足以充分利用IB和NVLink的帶寬,這種路由的優化策略達到了減少張量并行通信開銷的目的。
FP8與冗余專家技術減少MoE內存與通信開銷
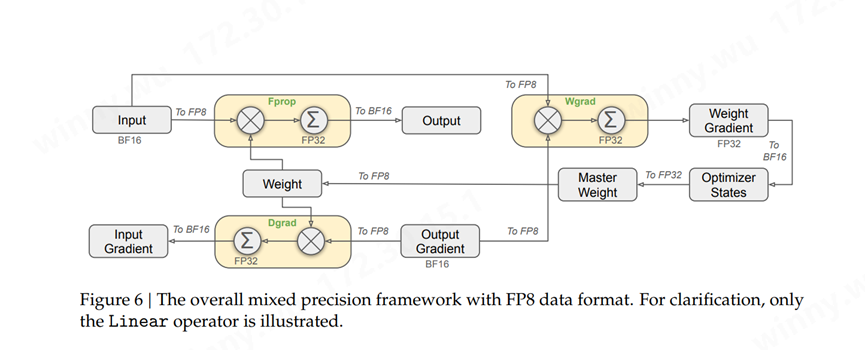
(來源:DeepSeek-V3 Technical Report)
為了進一步減少MoE訓練中的內存和通信開銷,DeepSeek在FP8中緩存和分發激活值,同時以BF16存儲低精度優化器狀態。在兩個與DeepSeek-V2-Lite和DeepSeek-V2相似規模的模型上驗證了提出的FP8混合精度框架,訓練了大約1萬億個Token。這一設計理論上使計算速度較原 BF16 方法提升一倍。此外,FP8 Wgrad GEMM 允許激活值以 FP8 存儲,供 Backward 使用,從而顯著降低內存消耗。
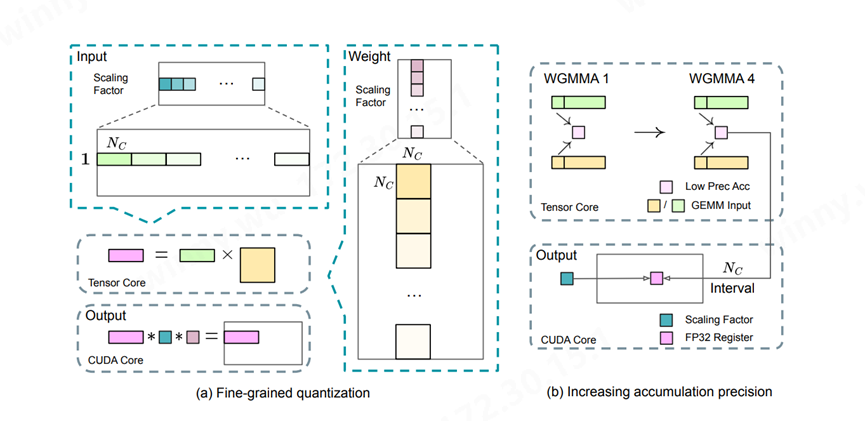
(來源:DeepSeek-V3 Technical Report)
為了在MoE部分的不同專家間實現負載均衡,需要確保每個GPU處理大概相同數量的Token。DeepSeek MoE引入了冗余專家部署策略,對高負載專家并行進行復制并冗余部署。根據在線服務中的專家負載統計信息,在一定間隔內定期確定冗余專家集,通過探索解碼階段的動態冗余策略優化各GPU負載,減少all-to-all通信開銷。在實際處理大規模文本生成任務時,DeepSeek MoE可以通過動態分配專家資源,實現高效的文本生成,而不需要像傳統模型那樣進行大規模的全模型計算。
DeepSeek MLA KV Cache壓縮優化
Multi-Head Latent Attention (MLA) 是 DeepSeek-V3 模型中用于高效推理的核心注意力機制。MLA 通過低秩聯合壓縮技術,減少了推理時的鍵值(KV)緩存,從而在保持性能的同時顯著降低了內存占用。這類創新技術一方面減少了KV緩存的需求,加快了數據訪問速度,從而全面提升了模型的推理速度。
KV緩存技術注解:
大語言模型通常是通常自回歸的方式產生輸出序列,后序生成的詞塊依賴與前序的所有詞塊,這些詞塊包括輸入的詞塊以及前面已經生成的詞塊。因此隨著輸出序列的增長,推理過程的開銷顯著增大。為了解決上述問題,KV Cache的技術被提出,該技術通過存儲和復用前序Token產生的Key值和Value值,極大減少了計算上的冗余,用存儲開銷換取顯著的加速效果,但同時增加的存儲開銷和帶寬需求也對AI Data Center的設計提出了挑戰。
國產AI網絡自主自控未來可期
DeepSeek 模型的成功預示著AI大模型系統驗證了新的Scaling Law,AI能力邊界將引來新一輪的擴張。在全球地緣政治日趨復雜的背景下,構建國產算力閉環系統已成為當務之急。然而,算力芯片始終是大模型系統算力的堅實基石。 DeepSeek憑借其開源和低成本的優勢,將顯著提升國產GPU在推理任務中的性價比和ROI。近期,眾多GPU廠商和云服務提供商紛紛宣布已完成與DeepSeek的適配部署,為國產AI產業的蓬勃發展注入了強勁動力。
目前,Scale Up網絡受限于PCIe總線的速率,僅支持傳統的八卡GPU互聯。而基于私有協議的GPU超帶寬域,由于缺乏成熟的生態產業鏈支持,難以實現大規模集群的高性能互聯。DeepSeek模型的出現,預示著國產芯片將在其引領的AI大模型新紀元中迎來廣泛機遇。
在這一背景下,作為助力國產GPU 實現自主自控的參與者,奇異摩爾自研的網絡加速芯粒GPU Link Chiplet——NDSA-G2G,以其極高的靈活性和可擴展性為Scale-up互聯生態提供了強有力的支撐。NDSA -G2G以IO Chiplet芯粒形式集成在GPU加速卡內,并利用UCIe D2D接口與GPU互聯,NDSA-G2G能夠實現高性能的數據流,從而全面加速分布式計算網絡,最終實現TB級別的GPU互聯。
奇異摩爾作為國產AI網絡生態鏈的一份子,將持續與大模型廠商、運營商/云廠商及國產GPU廠商共同探索AI系統的優化潛力,持續推動生態適配工作,為國產AI早日實現算力閉環、邁向自主自控新紀元貢獻堅實力量。
關于我們
AI網絡全棧式互聯架構產品及解決方案提供商
奇異摩爾,成立于2021年初,是一家行業領先的AI網絡全棧式互聯產品及解決方案提供商。公司依托于先進的高性能RDMA 和Chiplet技術,創新性地構建了統一互聯架構——Kiwi Fabric,專為超大規模AI計算平臺量身打造,以滿足其對高性能互聯的嚴苛需求。我們的產品線豐富而全面,涵蓋了面向不同層次互聯需求的關鍵產品,如面向北向Scale out網絡的AI原生智能網卡、面向南向Scale up網絡的GPU片間互聯芯粒、以及面向芯片內算力擴展的2.5D/3D IO Die和UCIe Die2Die IP等。這些產品共同構成了全鏈路互聯解決方案,為AI計算提供了堅實的支撐。
奇異摩爾的核心團隊匯聚了來自全球半導體行業巨頭如NXP、Intel、Broadcom等公司的精英,他們憑借豐富的AI互聯產品研發和管理經驗,致力于推動技術創新和業務發展。團隊擁有超過50個高性能網絡及Chiplet量產項目的經驗,為公司的產品和服務提供了強有力的技術保障。我們的使命是支持一個更具創造力的芯世界,愿景是讓計算變得簡單。奇異摩爾以創新為驅動力,技術探索新場景,生態構建新的半導體格局,為高性能AI計算奠定穩固的基石。
-
并行計算
+關注
關注
0文章
28瀏覽量
9496 -
大模型
+關注
關注
2文章
2824瀏覽量
3470 -
DeepSeek
+關注
關注
1文章
656瀏覽量
501
原文標題:Kiwi Talks | 解析DeepSeek MoE并行計算優化策略 國產AI網絡自主自控大有可為
文章出處:【微信號:奇異摩爾,微信公眾號:奇異摩爾】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
arm系統中并行計算優化
區域分解對氣象模式并行計算速度的影響
THE MATHWORKS推出新版并行計算工具箱
并行計算和嵌入式系統實踐教程
基于Matlab和GPU的BESO方法的全流程并行計算策略
基于異構并行計算的兩個子概念異構和并行的簡單分析
基于云計算的電磁問題并行計算方法
C編程的并行計算詳細資料說明
CUDA的異構并行計算詳細資料介紹





 工商網監
工商網監

評論