

作者:算力魔方創(chuàng)始人/英特爾創(chuàng)新大使劉力
近日,荷蘭科學(xué)家Raz發(fā)布了Reinforce-Lite算法,實(shí)現(xiàn)了在 48GB顯存的顯卡上僅用 12 小時在3B模型上重現(xiàn)DeepSeek“Wait!/Aha”時刻。
原文鏈接:https://medium.com/@rjusnba/overnight-end-to-end-rl-training-a-3b-model-on-a-grade-school-math-dataset-leads-to-reasoning-df61410c04c6
滑動查看更多
一,Reinforce-Lite算法的顯存要求
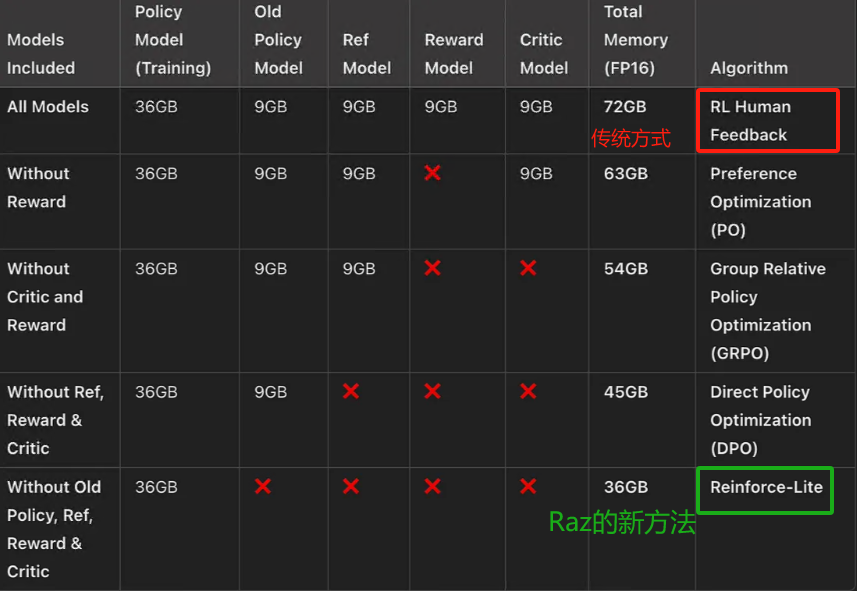
Raz通過移除KL,移除替代比率,去掉評論模型,使用組相對獎勵(DeepSeek的GRPO風(fēng)格)進(jìn)行優(yōu)勢計(jì)算,提出了一種更簡單、更穩(wěn)定、更高效的輕量級強(qiáng)化學(xué)習(xí)方法:Reinforce-Lite,使得顯存需求,從72GB下降到36GB!下表是:端到端的用強(qiáng)化學(xué)習(xí)訓(xùn)練 3B 模型的顯存需求。
二,Reinforce-Lite算法的PyTorch實(shí)現(xiàn)
Reinforce-lite算法的PyTorch實(shí)現(xiàn)如下所示:
第一步,初始化一個指令微調(diào)的LLM,并適當(dāng)提示以將其推理步驟包含在標(biāo)簽中。
第二步,定義一個獎勵函數(shù)用于模型輸出(例如,GSM8K數(shù)學(xué)推理任務(wù)中的正確性)。通過正則表達(dá)式提取標(biāo)簽中的數(shù)值,并與數(shù)據(jù)集中的實(shí)際答案進(jìn)行比較。
第三步,通過直接計(jì)算相對于獎勵的梯度來優(yōu)化策略,而不需要替代損失。
第四步,使用組相對歸一化進(jìn)行優(yōu)勢計(jì)算,消除了對評論模型的需求。我們使用組大小為10。
第五步,使用標(biāo)準(zhǔn)對數(shù)概率梯度更新模型。
def reinforce_lite(batch, policy_model, tokenizer, device, step, save_dir):
"""
使用強(qiáng)化學(xué)習(xí)方法訓(xùn)練策略模型。
Args:
batch (list of tuples): 包含提示和目標(biāo)句子的列表。
policy_model (torch.nn.Module): 策略模型,用于生成響應(yīng)。
tokenizer (transformers.PreTrainedTokenizer): 用于處理文本的標(biāo)記器。
device (torch.device): 指定模型運(yùn)行的設(shè)備。
step (int): 當(dāng)前訓(xùn)練步數(shù)。
save_dir (str): 保存模型的目錄。
Returns:
tuple: 包含策略損失、平均獎勵、策略損失項(xiàng)、0.0、第一個響應(yīng)和所有響應(yīng)的長度。
"""
# 設(shè)置模型為訓(xùn)練模式
policy_model.train()
# 解包輸入數(shù)據(jù)
prompts, targets = zip(*batch)
# 獲取批量大小
batch_size = len(prompts)
# 初始化評估組索引
evaluated_group = 0
# 初始化存儲列表
all_logprobs = []
all_rewards = []
all_responses = []
all_lengths = []
for group_idx in range(config.GROUP_SIZE):
# 格式化提示
formatted_prompts = [format_prompt(p, tokenizer) for p in prompts]
# 將提示轉(zhuǎn)換為模型輸入
inputs = tokenizer(
formatted_prompts,
return_tensors="pt",
padding=True,
truncation=True,
max_length=config.MAX_SEQ_LENGTH
).to(device)
# 生成參數(shù)
generate_kwargs = {
**inputs,
"max_new_tokens": config.MAX_NEW_TOKENS,
"do_sample": True,
"temperature": 0.7,
"top_p": 0.9,
"pad_token_id": tokenizer.pad_token_id,
"return_dict_in_generate": True,
}
# 判斷當(dāng)前組是否為評估組
if group_idx == evaluated_group:
# 生成響應(yīng)
generated = policy_model.generate(**generate_kwargs)
# 獲取生成的響應(yīng)ID
generated_ids = generated.sequences
# 獲取模型輸出
outputs = policy_model(
generated_ids,
attention_mask=(generated_ids != tokenizer.pad_token_id).long()
)
# 獲取提示長度和響應(yīng)長度
prompt_length = inputs.input_ids.shape[1]
response_length = generated_ids.shape[1] - prompt_length
# 計(jì)算對數(shù)概率
if response_length > 0:
logits = outputs.logits[:, prompt_length-1:-1, :]
response_tokens = generated_ids[:, prompt_length:]
log_probs = torch.log_softmax(logits, dim=-1)
token_log_probs = torch.gather(log_probs, -1, response_tokens.unsqueeze(-1)).squeeze(-1)
sequence_log_probs = token_log_probs.sum(dim=1)
else:
sequence_log_probs = torch.zeros(batch_size, device=device)
else:
# 在不計(jì)算梯度的情況下生成響應(yīng)
with torch.no_grad():
generated = policy_model.generate(**generate_kwargs)
sequence_log_probs = torch.zeros(batch_size, device=device)
# 解碼生成的響應(yīng)
responses = tokenizer.batch_decode(
generated.sequences[:, inputs.input_ids.shape[1]:],
skip_special_tokens=True
)
# 計(jì)算獎勵
rewards = torch.tensor([get_reward(resp, tgt) for resp, tgt in zip(responses, targets)], device=device)
# 存儲結(jié)果
all_responses.extend(responses)
all_rewards.append(rewards)
all_logprobs.append(sequence_log_probs)
all_lengths.extend([len(r.split()) for r in responses])
# 堆疊獎勵和對數(shù)概率
rewards_tensor = torch.stack(all_rewards)
logprobs_tensor = torch.stack(all_logprobs)
# 分離評估組的獎勵和其他組的獎勵
evaluated_rewards = rewards_tensor[evaluated_group]
others_rewards = torch.cat([
rewards_tensor[:evaluated_group],
rewards_tensor[evaluated_group+1:]
], dim=0)
# 計(jì)算基線值
baseline = others_rewards.mean(dim=0)
# 計(jì)算優(yōu)勢
advantages = (evaluated_rewards - baseline) / (others_rewards.std(dim=0) + 1e-8)
advantages = torch.clamp(advantages, -2.0, 2.0)
# 計(jì)算策略損失
policy_loss = -(logprobs_tensor[evaluated_group] * advantages.detach()).mean()
return policy_loss, rewards_tensor.mean().item(), policy_loss.item(), 0.0, all_responses[0], all_lengths
滑動查看更多
三,Reinforce-Lite算法的數(shù)據(jù)集:GSM 8K
Reinforce-Lite使用GSM8K數(shù)據(jù)集:這是一個小學(xué)數(shù)學(xué)數(shù)據(jù)集,包含數(shù)學(xué)問題及其答案,格式如下:
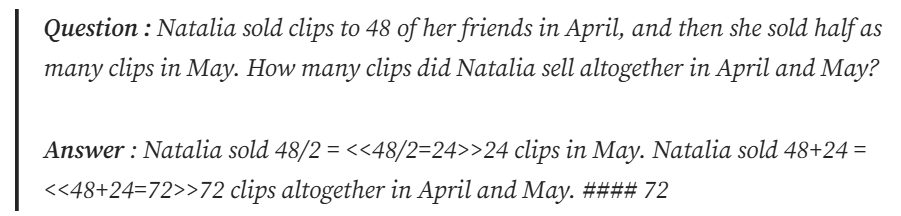
雖然答案也涉及推理步驟,但我們感興趣的是 ### 之后的最終答案。我們將簡單地提示策略模型以 格式輸出最終答案,并使用它來驗(yàn)證策略模型計(jì)算出的答案是否正確。這更像是蒙特卡洛問題,我們會在情節(jié)結(jié)束時獲得獎勵。
Reinforce-Lite的完整實(shí)現(xiàn)方式和訓(xùn)練過程,Raz將很快開源!敬請期待。
四,DeepSeek:快速生成PPT大綱
Reinforce-Lite 改進(jìn)了結(jié)構(gòu)化推理:從生成的序列中我們可以看到 RL 微調(diào)模型,評估分?jǐn)?shù)略有提高。
Reinforce-Lite 不需要 PPO 的復(fù)雜性:單個策略網(wǎng)絡(luò)足以進(jìn)行 LLM 微調(diào)。
Reinforce-Lite 是一種計(jì)算友好的算法,允許端到端 RL 訓(xùn)練,同時最大限度地降低訓(xùn)練復(fù)雜性和顯存的需求,讓AI平權(quán)的時代可盡快到來。
人人都能在自己的48GB顯存顯卡上,重現(xiàn)DeepSeek“Wait!/Aha”時刻!另外,需要48GB顯存的顯卡,請聯(lián)系我們!
如果你有更好的文章,歡迎投稿!
稿件接收郵箱:nami.liu@pasuntech.com
更多精彩內(nèi)容請關(guān)注“算力魔方?”!
審核編輯 黃宇
-
顯卡
+關(guān)注
關(guān)注
16文章
2496瀏覽量
68993 -
AI
+關(guān)注
關(guān)注
87文章
33510瀏覽量
274085 -
DeepSeek
+關(guān)注
關(guān)注
1文章
754瀏覽量
992
發(fā)布評論請先 登錄
相關(guān)推薦
在龍芯3a6000上部署DeepSeek 和 Gemma2大模型
【實(shí)測】用全志A733平板搭建一個端側(cè)Deepseek算力平臺
HarmonyOS NEXT開發(fā)實(shí)戰(zhàn):DevEco Studio中DeepSeek的使用
如何基于Android 14在i.MX95 EVK上運(yùn)行Deepseek-R1-1.5B和性能
NVIDIA不放棄12nm圖靈顯卡,將推出8GB版RTX 2060
曝NVIDIA將推出RTX 2060顯卡的8GB顯存版 仍不放棄12nm圖靈顯卡
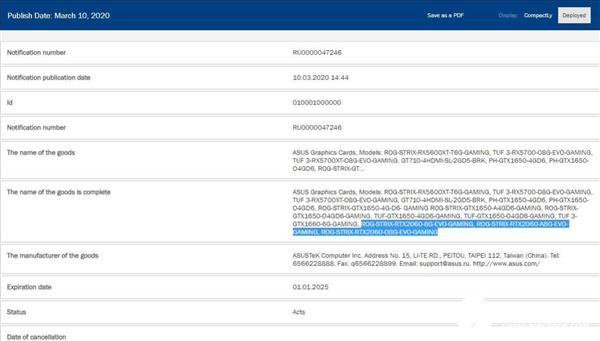
RTX 3080 20GB顯卡復(fù)活本月即將上市
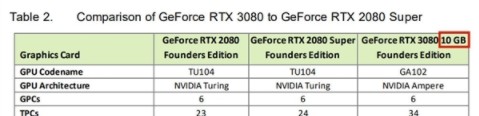
英偉達(dá)正式發(fā)布RTX 3060 顯卡:12GB 顯存
微星推出面向Mini-ITX主機(jī)/主板的RTX 3060 12GB顯卡
NVIDIA推出了RTX 3060顯卡 12GB顯存超過RTX 3080
NVIDIA正式宣布其基于Ampere GPU架構(gòu)的GeForce RTX 3060 12 GB顯卡
新型DDR5內(nèi)存的應(yīng)用
集成在主板上的獨(dú)立顯卡是屬于集成顯卡還是獨(dú)立顯卡的范圍?
SK海力士推出48GB 16層HBM3E產(chǎn)品
DeepSeek在昇騰上的模型部署的常見問題及解決方案





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論