

生成式推薦系統優勢
推薦系統的主要任務在于根據用戶的過往行為預測其潛在興趣點,并據此推薦相應的商品。在傳統的推薦系統中,當處理用戶請求時,會觸發多個召回模塊,例如熱門商品召回、個性化召回以及深度召回等,從而召回大量候選商品。之后,系統會借助相對簡單的粗排模型對這些候選集進行初步篩選,以縮小候選范圍,最后通過精排和重排模型,確定最終返回給用戶的推薦結果。
隨著大語言模型 (LLM) 在推薦系統中的廣泛應用,生成式推薦系統相較于傳統推薦系統可展現出以下顯著優勢:
推薦流程的簡化:生成式推薦系統從多級過濾的判別式 (discriminative-based) 架構轉變成單級過濾的生成式 (generative-based) 架構。通過直接生成推薦結果,大幅簡化了推薦流程,顯著降低了系統復雜性。
知識融合:LLM 具備更強的泛化能力和穩定性。借助其豐富的世界知識和推理能力,生成式推薦系統可以突破傳統電商平臺在商品和用戶建模時面臨的數據局限。在新用戶、新商品的冷啟動以及新領域的推薦場景中,生成式推薦系統可以提供更優質的推薦效果和更出色的遷移性能。
規模定律(Scaling Law):傳統的點擊率 (CTR) 稀疏模型在模型規模擴大時,往往會面臨邊際收益遞減的問題。而 LLM 所表現出的規模定律屬性,為模型的有效擴展提供了一種新路徑,即模型性能隨著規模的增加而持續提升。這意味著通過擴大模型規模,可以獲得更優的推薦效果,從而突破傳統模型的性能瓶頸。
以下是基于京東廣告場景落地的生成式召回應用,介紹大語言模型在推薦系統中的實踐。
生成式召回方案介紹
1. 生成式召回算法與實現步驟
生成式推薦包含兩個接地 (grounding) 過程:一是將商品與自然語言連接起來。二是將用戶行為與目標商品連接起來。具體實現步驟如下:
商品表示:直接生成文檔或商品描述在實際中幾乎是不可行的。因此采用短文本序列(即語義 ID)來表征商品。選取高點擊商品的標題、類目等語義信息,經由編碼器模型獲得向量表示,再利用 RQ-VAE 對向量進行殘差量化,最終得到商品的語義 ID。例如,商品:“XXX 品牌 14+ 2024 14.5 英寸輕薄本 AI 全能本高性能獨顯商務辦公筆記本電腦”可表示為:
用戶畫像與行為建模:通過構建提示詞來定義任務,并將用戶畫像、用戶歷史行為數據等用戶相關信息轉化為文本序列。例如:“用戶按時間順序點擊過這些商品:
模型訓練:確定生成模型的輸入(用戶表示)和輸出(商品物料標識符)后,即可基于生成式 Next Token Prediction 任務進行模型訓練。
模型推理:經過訓練后,生成模型能夠接收用戶信息并預測相應的商品語義 ID,這些語義標識可以對應數據集中的實際商品 ID。
2. LLM 模型部署的工程適配
傳統基于深度學習的召回模型,參數量通常在幾十萬到幾千萬之間,且模型結構以 Embedding 層為主。而基于 LLM 實現的生成式召回模型,參數規模大幅提升至 0.5B 至 7B 之間,模型結構主要由 Dense 網絡構成。由于參數量顯著增加,LLM 在推理過程中所需的計算資源相比于傳統模型大幅提升,通常高出幾十倍甚至上百倍。因此,LLM 在處理復雜任務時具備更強的表現力,但同時也對計算能力有著更高的要求。
為了將如此龐大的算力模型部署至線上環境,并確保其滿足毫秒級實時響應的需求,同時在嚴格控制資源成本的前提下實現工業化應用,我們必須對在線推理架構進行極致的性能優化。
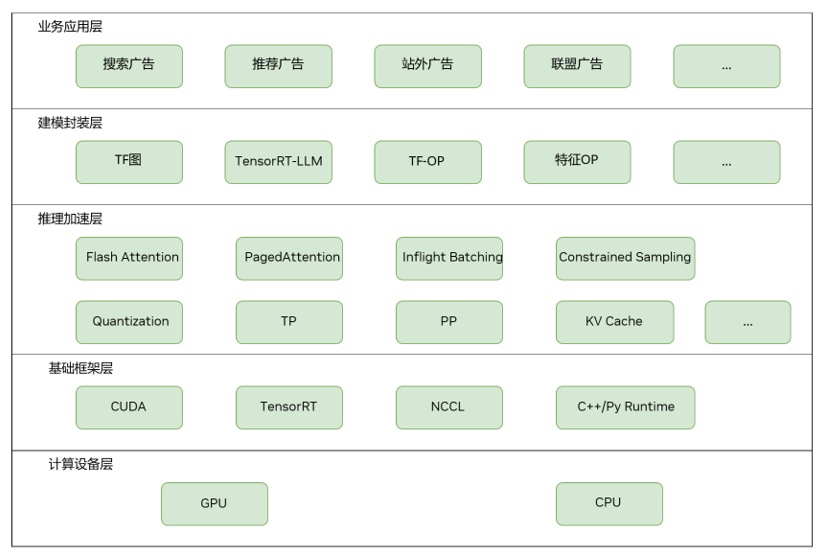
圖 1: 在線推理架構
該圖片來源于京東,若您有任何疑問或需要使用該圖片,請聯系京東
3. 基于 TensorRT-LLM 的 LLM構建優化及系統部署
在建模封裝層,通過TensorRT-LLM實現 LLM 模型的構建與優化,并將其無縫整合到現有生態系統中,利用 Python 與 TensorFlow API 構建端到端推理圖。基于 TensorFlow 原生算子及現有業務的自定義 TensorFlow 算子庫(例如用戶行為特征處理算子),實現算法的靈活建模。
在推理優化層,通過應用 Inflight Batching、Constrained Sampling、Flash Attention 及 Paged Attention 等加速方案,最大化提升單卡吞吐量并降低推理延遲。
在系統部署方面,為了最大程度利用時間資源,生成式召回一期的部署采用了與傳統多分支召回模塊并行的方式。由于簡化了推理流程,相較于傳統召回方式,生成式召回的資源消耗更少,運行時間更短,并且召回效果更優。
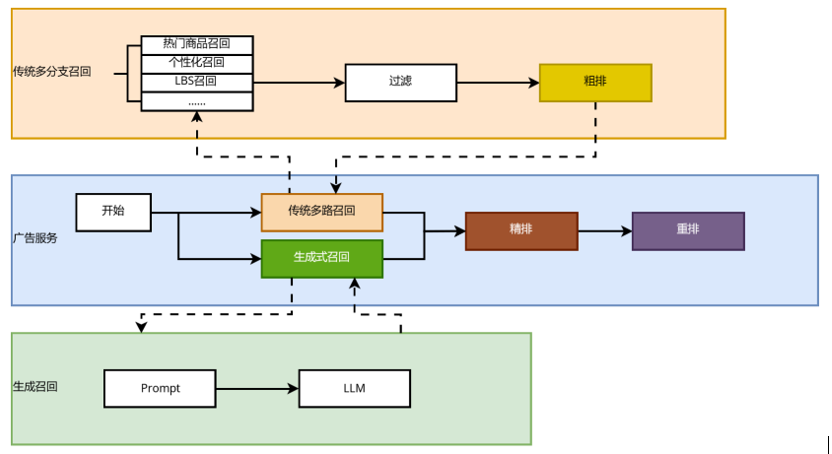
圖 2:生成式召回與傳統多路召回并行
該圖片來源于京東,若您有任何疑問或需要使用該圖片,請聯系京東
4. 生成式召回一期
在推薦廣告及搜索廣告的成功應用
目前,生成式召回一期已在京東推薦廣告及搜索廣告等主要業務線成功實施。在推薦廣告方面,基于生成式模型的參數規模及語義理解優勢,AB 實驗結果顯示商品點擊率與消費得到了顯著提升。在搜索廣告方面,LLM 所具備的語義理解能力顯著提升了對查詢與商品的認知能力,尤其是在處理搜索中的長尾查詢時,填充率有明顯提升,AB 實驗也取得了點擊率與消費幾個百分點的收益增長。
通過 TensorRT-LLM 進行推理優化加速:
降低延遲并提升吞吐
在原先的模型推理方案中,線上業務的低延遲要求往往較難達成。然而,在切換到 TensorRT-LLM 之后,借助其豐富的優化特性,不僅模型推理延遲達到線上業務要求,同時吞吐也有了顯著提升。
在 NVIDIA GPU 上進行的測試顯示,與基線對比,在限制 100 毫秒推理耗時的廣告場景下,采用 TensorRT-LLM 進行推理的吞吐量提升了五倍以上。這相當于將部署成本降至原來的五分之一。
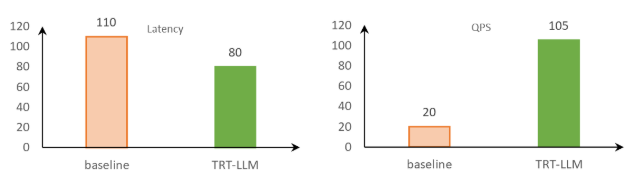
圖 3:TensorRT-LLM 和基線的對比 (Qwen2-1.5B | beam 5 | vocab size 15W | input 150 | output 4) ,數據來自京東廣告團隊測試結果
該圖片來源于京東,若您有任何疑問或需要使用該圖片,請聯系京東
針對這個特定的應用場景,合理配置 beam width 對檢索結果有著重要影響。一般來說,較高的 beam width 能夠增加候選商品的數量,從而提高檢索的準確性。例如,在需要返回 300 個商品時,若 beam width 設置較低,每個 code 就需要對應更多的商品 id,這無疑會導致檢索的精度降低。
為了解決這個問題,NVIDIA DevTech 技術團隊進行了有針對性的二次開發和優化工作,從而讓 TensorRT-LLM 支持更大范圍的 beam width,及時滿足了線上的業務需求。
持續優化技術以實現模型效率效果提升
未來,我們將持續在生成式推薦領域深入探索,重點聚焦以下幾個方向:
提升模型規模以滿足實時推理需求
目前,由于算力、時間消耗和成本等客觀條件的限制,生成式推薦系統在實時推理中的可部署模型規模相對較小(約 0.5B 至 6B 參數之間)。然而,離線實驗的數據表明,擴大模型規模可以顯著提升線上推薦效果。這意味著對在線性能優化提出了更高要求。為了支持更大規模的模型在線部署,同時不顯著增加成本,我們需要進一步優化模型結構和推理效率。例如,采用模型剪枝、量化等模型壓縮技術,優化采樣檢索算法效率,以及高效的分布式推理架構。
擴展用戶行為輸入以提升模型效果
實驗表明,輸入更長的用戶歷史行為序列能夠顯著提高模型的推薦效果,但同時也會增加計算資源消耗和推理時間。因此,我們需要在效果提升和性能開銷之間找到平衡。優化方案包括:
a. Token 序列壓縮:對輸入序列進行壓縮(例如去除冗余信息、合并相似行為等),減少序列長度,同時保留關鍵信息。
b. 用戶行為 KV 緩存復用:在推理過程中,針對用戶行為特征有序遞增的特點,對長期行為進行離線計算并進行緩存,在線部分負責計算實時行為,從而避免重復計算,最大化利用算力,提高推理效率。
融合稀疏與稠密模型以實現聯合推理
隨著模型參數量的增加,我們可以將稀疏的傳統 CTR 模型與稠密的 LLM 模型進行聯合推理。稀疏模型擅長處理高維度的稀疏特征,計算效率高;而稠密模型可以捕獲復雜的非線性特征和深層次的語義信息。通過對兩者的優勢進行融合,構建一個既高效又精確的推薦系統。
針對于稀疏訓練場景, NVIDIA 可以提供DynamicEmb方案。DynamicEmb 是一個 Python 包,專門針對推薦系統提供稀疏訓練方案,包括模型并行的 dynamic embedding 表和 embedding lookup 功能。
DynamicEmb 利用 HierarchicalKV 哈希表后端,將鍵值(特征-嵌入)對存儲在 GPU 的高帶寬內存 (HBM) 以及主機內存中,而 embedding lookup 部分則主要利用了 EMBark 論文中的部分算法。
-
NVIDIA
+關注
關注
14文章
5160瀏覽量
104937 -
模型
+關注
關注
1文章
3438瀏覽量
49592 -
推薦系統
+關注
關注
1文章
44瀏覽量
10139 -
LLM
+關注
關注
1文章
315瀏覽量
566
原文標題:NVIDIA TensorRT-LLM 在推薦廣告及搜索廣告的生成式召回的加速實踐
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
名單公布!【書籍評測活動NO.31】大語言模型:原理與工程實踐
【大語言模型:原理與工程實踐】探索《大語言模型原理與工程實踐》
【大語言模型:原理與工程實踐】大語言模型的基礎技術
【大語言模型:原理與工程實踐】大語言模型的預訓練
【大語言模型:原理與工程實踐】大語言模型的評測
【大語言模型:原理與工程實踐】大語言模型的應用
大語言模型:原理與工程實踐+初識2
在Ubuntu上使用Nvidia GPU訓練模型
NVIDIA SWI UNETR模型在醫療中的應用

NVIDIA NeMo最新語言模型服務幫助開發者定制大規模語言模型
KT利用NVIDIA AI平臺訓練大型語言模型
現已公開發布!歡迎使用 NVIDIA TensorRT-LLM 優化大語言模型推理






 工商網監
工商網監

評論