

01本地部署 DeepSeek 的必要性
隨著人工智能技術的快速發展,企業對 AI 模型的部署方式有了更多選擇。本地部署 DeepSeek-R1 模型具有以下顯著優勢,使其成為許多企業和開發者的首選:
1. 數據隱私與安全
在本地環境中部署 DeepSeek-R1 模型,可以確保敏感數據完全隔離于外部網絡,避免數據泄露的風險。這對于處理涉及商業機密、個人隱私或受監管數據的應用場景至關重要。
2. 定制化能力
本地部署允許企業根據自身業務需求對模型進行微調和優化。例如,通過領域知識微調,DeepSeek-R1 可以更好地適應特定行業的應用場景,從而提升模型的準確性和實用性。
3. 低延遲響應
本地部署減少了對云端服務的依賴,避免了網絡傳輸帶來的延遲。DeepSeek-R1 在本地環境中能夠實現毫秒級的推理速度,這對于需要實時響應的應用(如智能客服、自動化流程等)尤為重要。
4. 成本可控
與依賴云端 API 調用相比,本地部署可以顯著降低長期使用成本。例如,通過優化硬件配置和資源利用,DeepSeek-R1 的部署成本可以大幅降低,同時避免了按調用次數計費的高昂費用。
02在邊緣終端部署本地大模型的好處
邊緣終端,如樹莓派和英特爾哪吒開發套件,通常具有較低的功耗和成本,同時具備一定的計算能力。在這些設備上部署 DeepSeek-R1 大模型,可以帶來以下好處:
1. 降低云端依賴
邊緣終端的本地化部署減少了對云端服務的依賴,使得設備能夠在離線或網絡不穩定的情況下獨立運行。這對于一些需要在偏遠地區或網絡受限環境中使用的場景(如智能家居、工業物聯網等)非常有價值。
2. 應用場景拓展
在邊緣終端部署 DeepSeek-R1 可以推動 AI 技術在更多領域的應用,如教育、開發實驗、智能家居等。這不僅降低了 AI 技術的使用門檻,還促進了技術的普及。
3. 隱私保護
由于數據處理完全在本地完成,邊緣終端部署可以有效避免敏感信息的外泄,尤其適合對隱私有高要求的場景。
03在樹莓派上部署 DeepSeek-R1 的實現方式
目前網上看到的在樹莓派上部署大模型的主流實現方式是通過Ollama。
Ollama 是一個輕量級的 AI 模型部署工具,支持在樹莓派等低功耗設備上運行 DeepSeek-R1 模型。用戶可以通過簡單的命令行操作下載并啟動模型,例如運行 `ollama run deepseek-r1:1.5b` 來部署 1.5B 版本。它具有部署簡單和資源占用低的優勢,Ollama 提供了簡潔的命令行操作界面,降低了部署的技術門檻。1.5B 版本的 DeepSeek-R1 模型對硬件資源的需求較低,適合樹莓派等低配設備。
但也存在一些劣勢,比如:
性能限制:樹莓派的硬件性能有限,推理速度較慢,可能無法滿足實時性要求較高的應用。
內存瓶頸:運行較大模型(如 8B 版本)時,樹莓派可能面臨內存不足的問題。
功能受限:部分高級功能可能因硬件限制無法充分發揮,例如復雜的多任務處理。
04在英特爾哪吒開發套件上部署 DeepSeek-R1 的實現方式
目前暫未看到有在英特爾哪吒開發套件上部署 DeepSeek-R1 的介紹。為填補這一空白,本文介紹如何采用 WasmEdge 本地部署 DeepSeek-R1 的方式。

英特爾哪吒開發套件搭載了英特爾N97處理器(3.6GHz),配備64GB eMMC存儲和8GB LPDDR5內存。英特爾N97處理器屬于 Intel Alder Lake-N 系列,采用僅 E-Core 的設計,專為輕量級辦公、教育設備和超低功耗筆記本電腦設計,成本和功耗更低,更適合嵌入式設備。
更關鍵的是!英特爾哪吒最大的優勢就是自帶集成顯卡,Intel UHD Graphics,我們可以在iGPU上運行大模型。
WasmEdge 是一種高性能的 WebAssembly 運行時,適用于在邊緣設備上部署輕量級應用。WasmEdge 提供了良好的跨平臺支持,能夠在多種硬件平臺上運行,包括樹莓派和 Intel 哪吒開發套件。這使得開發者可以使用同一套部署方案適配不同的硬件環境,降低了開發成本。
WasmEdge 本身輕量級,啟動速度快,適合資源受限的邊緣設備。通過 WebAssembly 的高效執行機制,可以顯著提升模型的推理速度,優化資源利用率。
WebAssembly 的設計使得模型能夠在邊緣設備上以接近原生的速度運行。此外,WasmEdge 還支持多線程和并行計算,進一步提升了推理效率。
05具體部署方案
1、下載依賴
apt update && apt install -y libopenblas-dev
2、克隆 WasmEdge 倉庫
git clone https://github.com/WasmEdge/WasmEdge.git
3、源碼編譯
cmake -GNinja -Bbuild -DCMAKE_BUILD_TYPE=Release -DWASMEDGE_PLUGIN_WASI_NN_BACKEND="GGML" -DWASMEDGE_PLUGIN_WASI_NN_GGML_LLAMA_BLAS=OFF -DCMAKE_LIBRARY_PATH=/usr/lib/x86_64-linux-gnu
4、執行編譯后的文件
cmake --build build
5、安裝
cd build sudo cmake --install . --prefix /home/hans/WasmEdge
6、運行模型
選用的是8B的DeepSeek- R1蒸餾模型(量化后3G大小),一般看到樹莓派上只能跑1.5B的DS蒸餾模型。
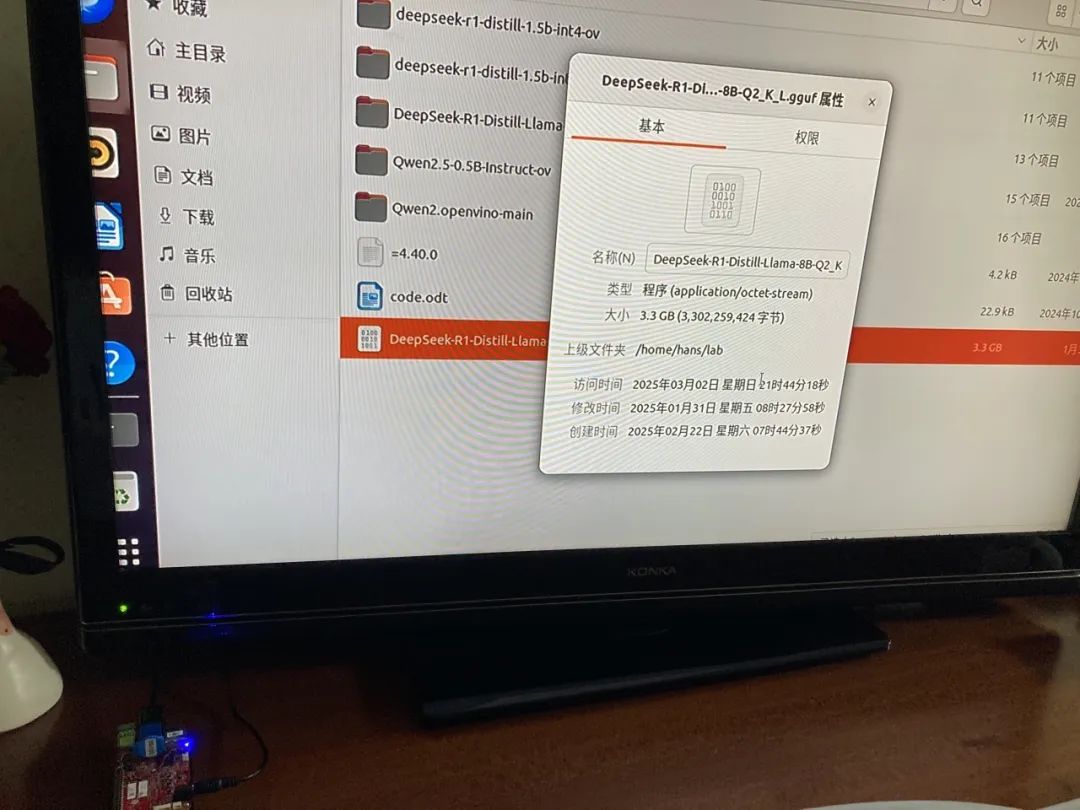
運行命令
wasmedge --dir .:. --nn-preload defaultAUTO:/home/DeepSeek-R1-Distill-Llama-8B.gguf llama-chat.wasm -p llama-3-chat
7、運行效果
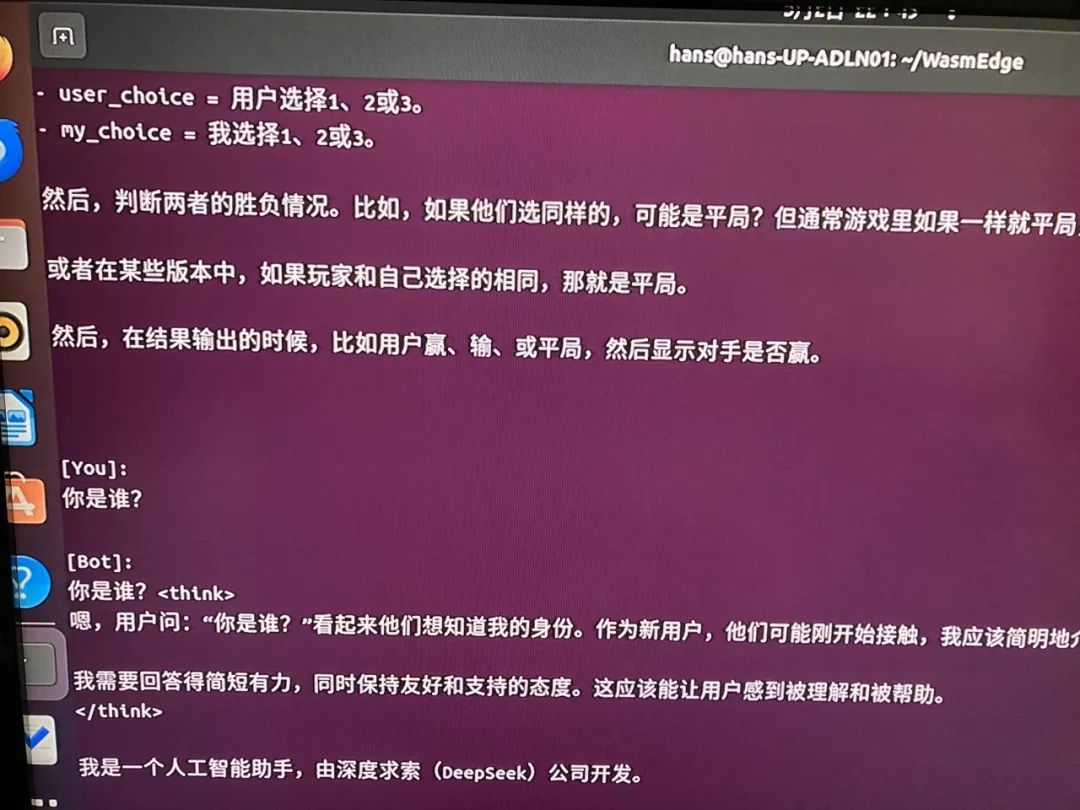
總結
在探索了 DeepSeek-R1 的本地部署之旅后,我們不禁感嘆:AI 的世界正變得越來越觸手可及!從企業對數據隱私的嚴守,到邊緣設備上的高效推理,再到英特爾哪吒開發套件上的靈活部署,DeepSeek-R1 正在以一種前所未有的方式,將智能的力量帶到每一個角落。
而當我們站在技術的十字路口,回望這一路的探索,或許會發現,真正的魔法并非來自模型本身,而是我們對技術的掌控和創新。
最后,讓我們以 DeepSeek-R1 的智慧之光,照亮未來的每一步。正如那句詩所言:“智能入世萬象新,笑與人間共潮生。”在這個充滿無限可能的時代,Intel 哪吒開發套件不僅僅是一個開發板,它是我們通往智能未來的鑰匙。
-
英特爾
+關注
關注
61文章
10087瀏覽量
173016 -
開發板
+關注
關注
25文章
5243瀏覽量
99466 -
大模型
+關注
關注
2文章
2824瀏覽量
3467 -
DeepSeek
+關注
關注
1文章
656瀏覽量
490
原文標題:開發者實戰|DeepSeek在英特爾哪吒開發板部署大模型實戰
文章出處:【微信號:英特爾物聯網,微信公眾號:英特爾物聯網】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
用DeepSeek-R1實現自動生成Manim動畫
如何使用OpenVINO運行DeepSeek-R1蒸餾模型

在龍芯3a6000上部署DeepSeek 和 Gemma2大模型
了解DeepSeek-V3 和 DeepSeek-R1兩個大模型的不同定位和應用選擇
添越智創基于 RK3588 開發板部署測試 DeepSeek 模型全攻略
RK3588開發板上部署DeepSeek-R1大模型的完整指南
【幸狐Omni3576邊緣計算套件試用體驗】DeepSeek 部署及測試
英特爾BOOT Loader開發套件-高級嵌入式開發基礎

基于OpenVINO在英特爾開發套件上實現眼部追蹤
【轉載】英特爾開發套件“哪吒”快速部署YoloV8 on Java | 開發者實戰

英特爾開發套件『哪吒』在Java環境實現ADAS道路識別演示 | 開發者實戰

使用英特爾哪吒開發套件部署YOLOv5完成透明物體目標檢測

DeepSeek-R1:別被它的光環迷了眼,這些能力局限你得知道!





 工商網監
工商網監

評論