 Python 只需20行代碼即可實現驗證碼識別
Python 只需20行代碼即可實現驗證碼識別
一、探討
識別圖形驗證碼可以說是做爬蟲的必修課,涉及到計算機圖形學,機器學習,機器視覺,人工智能等等高深領域……
簡單地說,計算機圖形學的主要研究內容就是研究如何在計算機中表示圖形、以及利用計算機進行圖形的計算、處理和顯示的相關原理與算法。圖形通常由點、線、面、體等幾何元素和灰度、色彩、線型、線寬等非幾何屬性組成。計算機涉及到的幾何圖形處理一般有 2維到n維圖形處理,邊界區分,面積計算,體積計算,扭曲變形校正。對于顏色則有色彩空間的計算與轉換,圖形上色,陰影,色差處理等等。
在破解驗證碼中需要用到的知識一般是 像素,線,面等基本2維圖形元素的處理和色差分析。常見工具為:
支持向量機(SVM)
OpenCV
圖像處理軟件(Photoshop,Gimp…)
Python Image Library
二、PIL安裝
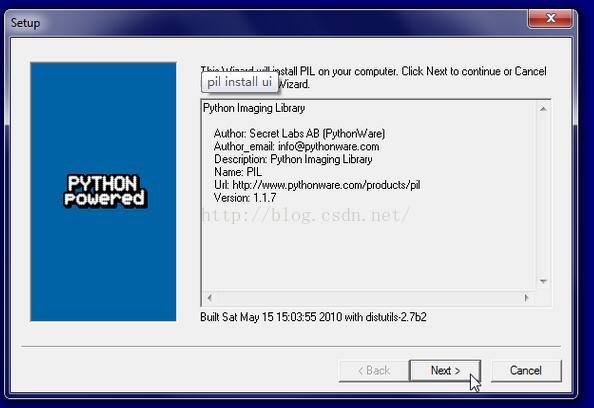
PIL: Python Imaging Library, 是Python平臺的圖像處理標準庫,功能非常強大。
在Debian/Ubantu Linux下直接通過apt安裝:
$sudo apt-get install python-imaging
Max和其他版本的Linux可以直接使用easy_install或pip安裝,安裝前需要把編譯環境裝好:
$ sudo easy_install PIL
Windos平臺可以直接去PIL官網下載exe安裝包。http://pythonware.com/products/pil/
注:官網提供的安裝包是32位的,64位系統請前往這里http://www.lfd.uci.edu/~gohlke/pythonlibs/#pillow下載替代包pillow。
三、一般思路
驗證碼識別的一般思路為:
1、圖片降噪
2、圖片切割
3、圖像文本輸出
3.1 圖片降噪
所謂降噪就是把不需要的信息通通去除,比如背景,干擾線,干擾像素等等,只剩下需要識別的文字,讓圖片變成2進制點陣最好。
對于彩色背景的驗證碼:每個像素都可以放在一個5維的空間里,這5個維度分別是,X,Y,R,G,B,也就是像素的坐標和顏色,在計算機圖形學中,有很多種色彩空間,最常用的比如RGB,印刷用的CYMK,還有比較少見的HSL或者HSV,每種色彩空間的維度都不一樣,但是可以通過公式互相轉換。在RGB空間中不好區分顏色,可以把色彩空間轉換為HSV或HSL。色彩空間參見http://baike.baidu.com/view/3427413.htm
驗證碼圖片7039.jpg: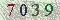
1、導入Image包,打開圖片:
fromPIL importImage
im = Image.open('7039.jpg')
2、把彩色圖像轉化為灰度圖像。RBG轉化到HSI彩色空間,采用I分量:
imgry = im.convert('L')
imgry.show()
灰度看起來是這樣的: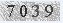
3、二值化處理
二值化是圖像分割的一種常用方法。在二值化圖象的時候把大于某個臨界灰度值的像素灰度設為灰度極大值,把小于這個值的像素灰度設為灰度極小值,從而實現二值化(一般設置為0-1)。根據閾值選取的不同,二值化的算法分為固定閾值和自適應閾值,這里選用比較簡單的固定閾值。
把像素點大于閾值的設置,1,小于閾值的設置為0。生成一張查找表,再調用point()進行映射。
threshold = 140
table = []
foriinrange(256):
ifi < threshold:
table.append(0)
else:
table.append(1)
out = imgry.point(table,'1')
out.show()
處理結果看起來是這樣的:
3.2 圖片切割
識別驗證碼的重點和難點就在于能否成功分割字符,對于顏色相同又完全粘連的字符,比如google的驗證碼,目前是沒法做到5%以上的識別率的。不過google的驗證碼基本上人類也只有30%的識別率。本文使用的驗證碼例子比較容易識別。可以不用切割,有關圖片切割的方法參見這篇博客:http://www.cnblogs.com/apexchu/p/4231041.html
四、利用pytesser模塊實現識別
pytesser是谷歌OCR開源項目的一個模塊,在python中導入這個模塊即可將圖片中的文字轉換成文本。
鏈接:https://code.google.com/p/pytesser/
pytesser 調用了 tesseract。在python中調用pytesser模塊,pytesser又用tesseract識別圖片中的文字。
4.1 pytesser安裝
如果沒有安裝PIL,請到這里下載安裝:http://www.pythonware.com/products/pil/
安裝pytesser,下載地址:http://code.google.com/p/pytesser/ ,下載后直接將其解壓到項目代碼下,或者解壓到python安裝目錄的Libsite-packages下,并將其添加到path環境變量中,不然在導入模塊時會出錯。
下載Tesseract OCR engine:http://code.google.com/p/tesseract-ocr/ ,下載后解壓,找到tessdata文件夾,用其替換掉pytesser解壓后的tessdata文件夾即可。
另外如果現在都是從PIL庫中運入Image,沒有使用Image模塊,所以需要把pytesser.py中的import Image改為from PIL import Image, 其次還需要在pytesser文件夾中新建一個__init__.py的空文件。
ps:如果覺得后面兩步比較麻煩,可以直接到云盤中下載 http://yun.baidu.com/s/1jHJvNiI,操作如步驟2。
4.2 調用pytesser識別
pytesser提供了兩種識別圖片方法,通過image對象和圖片地址,代碼判斷如下:
fromPIL importImage
frompytesser importpytesser
image = Image.open('7039.jpg')
printpytesser.image_file_to_string('7039.jpg')
printpytesser.image_to_string(image)
-
代碼
+關注
關注
30文章
4788瀏覽量
68617 -
python
+關注
關注
56文章
4797瀏覽量
84692
原文標題:20行 Python 代碼實現驗證碼識別
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【國民技術N32項目移植】手機驗證碼項目移植4--手機驗證碼計算
搜狗開放12306驗證碼識別技術助力搶票軟件
多樣變換的手寫驗證碼自動識別算法
一套基于GAN的驗證碼AI識別系統,能在0.5秒之內識別出驗證碼
以一個真實網站的驗證碼為例,實現了基于一下KNN的驗證碼識別
驗證碼層出不窮?試試這個自動跳過驗證碼的工具
爬蟲實現目標網站驗證碼登陸
帶帶弟弟OCR通用驗證碼識別SDK免費開源版
burpsuit驗證碼爆破教程

Java 中驗證碼的使用
SpringBoot分布式驗證碼登錄方案





 工商網監
工商網監
評論