 NVIDIA在美國發布了 Quadro 系列和 DGX 系列的兩款新品
NVIDIA在美國發布了 Quadro 系列和 DGX 系列的兩款新品
3 月 28 日(北京時間),NVIDIA 在美國圣何塞召開了 GTC 2018(GPU Technology Conference 2018)大會,并發布了 Quadro 系列和 DGX 系列的兩款新品。
Quadro GV 100 是 NVIDIA 「專業圖形顯卡」系列的最新成員,公司 CEO 黃仁勛稱其為「世界上體積最大的 GPU」。
Quadro GV 100 擁有 5120 顆 CUDA 流處理器,640 顆 Tensor 處理器,最高可提供 14.8TFLOPS 的單精度浮點性能, 7.4TFLOPS 雙精度浮點性能;采用 32GB HBM2 顯存,顯存帶寬為 870GB/s;能夠提供 118T 的深度學習性能。
接口方面,Quadro GV 100 配備 4 個 Display 1.4 接口,可以對接最多 4 個 4096 x 2160 分辨率,120Hz 刷新率的顯示器;或 4 個 5120 x 2880 分辨率, 60Hz 刷新率的顯示器;或 2 個 7680 x 4320 分辨率,60Hz 刷新率的顯示器。
DGX-2 是一臺專門用于人工智能訓練和/或推理任務的桌面計算機,是 NVIDIA 的第二代 DGX「小型超級計算機」,采用新的 NVSwitch 技術并聯 16 塊 32GB 顯存的 Tesla V100 計算卡,以及兩枚英特爾 Xeon Platinum 處理器 ,擁有 1.5TB 系統內存,與 30TB 的 NVMe SSD 作為存儲空間,顯存容量則為 512GB HBM2,可以提供最高 2petaFLOPS 的浮點性能。
這是它的內部結構:
你可以看到,在圖中 1 和 2 的位置看起來是很多塊芯片。其實他們是英偉達的 Tesla V100 Volta 架構 GPGPU,單枚算力達到雙精度 7.8 TFLOPS(萬億次浮點計算)、單精度 15.7TFLOPS、深度學習 125TFLOPS。
而DGX-2 單機箱安裝了 16 枚 V100,總體性能達到了驚人的 2PFLOPS——業界第一臺超過千萬億次浮點計算能力的單機箱計算機——稱它為超算或許并不浮夸。
但 DGX-2 的算力并非靠堆疊出來,如果它們之間不能實現高帶寬的數據互通則無意義。
時間倒回兩年前,英偉達有意在深度學習的設備市場上對英特爾發起直接挑戰,推出了 Pascal 架構的 P100 GPGPU。在當時,主流服務器 PCIe 總線接口的帶寬和時延,已經無法滿足英偉達的需求。于是它們開發出了一個新的設備內互聯標準,叫做 NVLink,使得帶寬達到了 300 GB/s。一個 8 枚 GPGPU 的系統里,NVLink 大概長這樣:
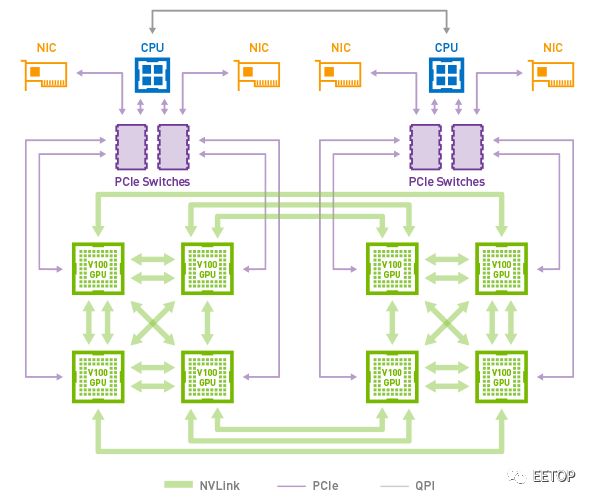
然而 NVLink 的標準拓撲結構在理論上最多支持 8 枚 顯卡,仍不足以滿足英偉達對于新系統內置更多顯卡的需要。于是在 NVLink 的基礎上,英偉達開發出了一個名專門在顯卡之間管理 NVLink 任務的協處理器,命名為 NVSwitch。這個元件在 DGX-2 上,讓 16 枚 GPGPU 中兩兩之間實現 NVLink 互通,總帶寬超過了 14.4 TB。
這一數字創造了桌面級電腦內總線接口帶寬的新高,但實現它的目的并非跑分,而在于 DGX-2 可以 1)更快速地訓練一個高復雜度的神經網絡,或 2)同時訓練大量不同結構的神經網絡。
N 卡之所以被稱為核彈有一種另類的解釋方式:它的多核心架構在這個依核心數量論高下的時代顯得超凡脫俗——動輒幾百、上千個 CUDA 核心,令人不明覺厲。而在 DGX-2 上,16 枚 V100 的 CUDA 核數達到了瘋狂的 81,920 核心。這一事實,結合 NVSwitch 技術、512GB 現存、30TB NVMe 固態硬盤、兩枚至強 Platimum CPU 和高達 1.5TB 的主機內存——
黃仁勛用 GPU 深度學習里程碑式的杰作 AlexNet 來舉例。研究者 Alex Krizhevsk 用了 6 天,在英偉達 GPU 上訓練 AlexNet,這個研究首次利用梯度下降法和卷積神經網絡進行計算機圖像識別,顯著優于此前的手調參數法,拿下了 ImageNet 圖像識別競賽冠軍。AlexNet 讓 Alex 世界聞名,這 6 天可以說值了。
然而,“同樣的 8 層卷積神經網絡,我用 DGX-2 跑了一下,只用 18 分鐘就達到了同樣的結果,”黃仁勛說,“五年,500倍的進步。”
這說明了很多東西。其中有一條:在這五年里,英偉達的技術進步節奏已經無法用摩爾定律來描述了。
Nvidia DGX-2 可提供 10 倍于上一代 Nvidia DGX-1 的深度學習性能,整體功耗為為 10KW,重 350 磅,售價僅為 39.9 萬美元(約合 250 萬人民幣)。
除了上述兩款重磅產品外,在今天的GTC 2018上,黃仁勛還宣布了英偉達的以下進展:
1、推出光線追蹤RTX技術(ray-tracing),能夠提供電影級畫質的實時渲染,渲染出逼真的反射、折射和陰影畫面。這一技術由英偉達在前不久的GDC全球游戲開發者大會上展示過;
2、推出了第一款專用于醫療圖像處理的超級電腦Clara;
3、推出新版機器學習應用平臺TensorRT 4,支持INT8與FP16精度,并與谷歌合作,將其整合進AI開源框架谷歌TensorFlow 1.7中;
4、宣布打造下一代名為DRIVE Orin的自動駕駛芯片,但除了名字外沒有透露更多信息;
5、正式推出3D仿真自動駕駛測試平臺DRIVE Constellation,這一測試平臺英偉達在CES上展示過,能夠幫助自動駕駛系統提升“姿勢水平”;
6、推出ISAAC機器人仿真訓練平臺SDK,將訓練機器人的技術開放出去;
此外英偉達還宣布將把它的開源深度學習架構(NVDLA)帶到ARM即將推出的項目 Trillium 平臺上,NVDLA將幫助開發人員加速推理過程。英偉達通常依賴于自己的封閉平臺,不過,要想在移動物聯網設備方面發揮影響,英偉達有必要和在該領域占主導地位的ARM合作。
黃仁勛演講內容:
重現照相質量的3D世界一直以來是3D圖學的終極目標,真實世界中光線來自四面八方,為了要重現真實世界,就必須把各個光線的來源綜合計算,復雜度極高,傳統GPU可能一秒只能計算一格畫面,但我們今天利用新技術,可以達到每秒60張畫面,這是非常不可思議的突破。
我們過去利用了許多不同的圖學技巧,不論是要降低計算負擔,或者是加速執行,但仍然很難真實重現照片畫質。
圖丨黃仁勛演講現場(圖片來源:DT君)
但決定畫面真實與否的最終條件,往往是畫面中的小細節,比如說光線和物件之間的折射、散射、漫射、透射與反射等等,通過光線追蹤技術,我們可以把真實世界的畫面成像原理搬到3D圖學當中,并且利用我們的GPU技術架構來完成。
要考慮到不同的物件會吸收光線、折射光線的程度不同,比如說玻璃、塑膠,甚至我們的皮膚,都會一定程度的吸收光線,因此我們利用了subsurface scattering來達到這樣的效果,這在一般計算機圖學中是非常難以達到的效果,但通過光線追蹤技術,我們可以輕易的達到。
黃仁勛用一段星際大戰影片來展示光線追蹤的效果,其效果幾乎和真實的電影畫面毫無差異,用肉眼幾乎看不出來是計算機計算的影片。尤其是在帝國士兵身上的鎧甲效果,反射光源后,和周圍環境進行多次折射和反射,以及光線的吸收,最終形成非常真實的畫面,幾乎和電影畫面沒有差別。
圖丨黃仁勛用星際大戰影片來展示光線追蹤的效果(來源:DT君)
這樣的畫面是在DGX超級計算平臺,通過2塊Volta繪圖卡達成。這是世界首次以實時呈現光線追蹤的效果。
在電影產業中,其實相關與光線處理相關的圖學技術都被使用,當你看到廣告、影片中,很多憑空創造出來的產物,基本上都是利用GPU創造出來的,而GPU每年都創造了超過10億張這些數字創作。通過GPU計算,我們讓產生這些圖像的成本和需要的時間降到最低,我們可以說,用越多GPU,你越省錢!
圖丨The more GPU you buy,the more you save
如今,通過使用 Quadro GV100,我們可以在單一機架中取代傳統龐大耗電的render farm,目前主要電影創作者都逐漸往這個方向前進,比如說 Pixar,就利用了這樣的架構來產生他們的電影畫面。
而考慮到世界上有多少電影工作室正在從事電影相關創作,我們可以考慮一下這個市場規模會有多大,牽涉到多大的金額,天文數字。
GPU推動了AI產業的發展,但AI產業也同時推動了GPU的進步,不只是GPU架構本身,還有相對應的開發環境與軟件生態,考慮到目前AI生態越來越蓬勃發展,我們可以說現時是個最佳的時間點,是讓產業改頭換面,前進到AI的領域中。
圖丨各種各樣的AI Network正在涌現
而為了滿足這些開發者的需求,超過800萬個開發者下載了我們的CUDA工具,他們創造出來的計算效能超過370PETAFLOPS。
這些高性能計算很大程度都是要用來改變世界,包括研究疾病、醫療、氣候變遷,甚至了解HIV的結構。
我們拿2013年的GPU架構和今年推出的最新產品相比,我們的GPU每隔五年就達到10倍的效能成長,傳統半導體有摩爾定律,但是在CUDA GPU中,我們創造了不同的定律,不只是硬件本身,我們也針對算法不斷的改善,總和以上的努力,我們才能達到這樣的成就。
傳統服務器的龐大、耗電,通過我們的GPU有了根本性的改變,我們可以說,你們在計算領域用了越多的GPU,其實就是越省錢!
在醫療圖像方面,很多疾病是越早偵測就越有機會治愈,但如何偵測疾病,視覺化的身體掃描技術,包括超音波、斷層掃描等,如果能夠利用3D技術重建掃描結果,我們可以看到更真實的結果,而不是能依靠不明顯的陰影來判斷病征。
圖丨英偉達在醫療上的合作伙伴
通過遠端與醫療圖像設備連線,這些設備產生的圖形實時反饋到我們的CUDA服務器中,并實時產生這些清晰的動態圖像,通過深度學習,我們可以輕易判讀這些掃描的結果,并還原到我們肉眼可以簡單判讀的3D立體型態。通過把這些服務器虛擬化,利用AI來后處理這些醫學圖像,我們可以創造出更容易判讀,且更不容易誤判的醫療圖像。
深度學習可以說重新塑造了我們現在的AI應用,從過去厚重、龐大、笨拙的印象,變呈現在輕巧、快速、聰明的結果。從芯片設計者,到互聯架構,到軟件設計者,再到OEM廠商等,不論你在供應鏈中的哪個環節,我們都可以全力支持。
客戶想要達成不同的計算目標,不論是購買成品,或者是自行架設,我們都能滿足客戶的需求。
近十年從機器學習到深度學習,從最早的模型,衍生出無數種不同的神經網絡、模型,隨著應用的增加,也越來越復雜。
當然,為了要應付這些復雜的神經網絡計算,現有的小型GPU其實很難以負擔,但我們從不同的方向去思考,如果把個別的GPU通過高效能的互聯結構結合起來,形成一個巨大的GPU,這個GPU上面可以創造出過去不可能達成的計算成果。
圖丨用NVSwitch互聯16個GPU的DXG2 server
我們通過NVSwitch達成了這個目的,通過這個互聯架構,我們在DXG-2 server中互聯了16顆GPU,形成一個龐大的GPU架構,通過最新的NVLink,技術,GPU和GPU之間可以用比PCIE快20倍的效率互相溝通。這個互聯結構不是網絡狀結構,而是速度更快的交換器結構,通過這樣的互聯設計,我們在單一結構中實現了2PETAFLOP的驚人效能。而且只需要2000W的功耗。其功耗性能比可說遠遠超出目前的超級計算機。
圖丨黃仁勛和世界上最大的GPU合影
現在新的AI芯片把云計算、深度學習看得太簡單,要考慮的因素太多,包括延遲、學習速率以及準確度等等,并不是在機架中塞進幾個ASIC芯片就能夠輕易解決的工作。我們要把盡可能快速的產生模型,盡可能讓模型更小,盡可能確保正確的結果輸出,背后的最大功臣就是開發工具。繼去年針對推理大幅進化的TensorRT3之后,我們現在推出了最新的TensorRT 4,支持更多主流框架,也更能把不同的神經網絡部署到云服務器當中。這個版本我們又更加強化了推理性能。
通過TensorRT、NCCL和cuDNN,以及面向機器人的全新Isaac軟件開發套件,基于GPU的計算生態也更加完整。此外,通過與領先云服務提供商的密切合作,各大主流深度學習框架都在持續優化,以充分利用NVIDIA的GPU計算平臺。
NVIDIA新推出的DGX-2系統通過借鑒NVIDIA為所有層級的計算堆棧開發的各種業界領先的技術優勢,實現了每秒2千萬億次浮點運算的里程碑式突破。
圖丨黃仁勛演講
DGX-2是首款采用NVSwitch的系統,其中采用的16個GPU均共享統一的內存空間。這讓開發者獲得了相應的深度學習訓練能力,以處理最大規模的數據集和最復雜的深度學習模型。
DGX-2能夠在不到兩天的時間內完成對FAIRSeq的訓練,FAIRSeq是一種采用最新技術的神經網絡機器翻譯模型,其性能相較于去年9月份推出的基于Volta架構的DGX-1提高了10倍。
我們在此也要宣布推出DRIVE Constellation計算平臺。該平臺基于兩個不同的服務器,第一臺服務器運行DRIVE Sim軟件來模擬自動駕駛汽車的傳感器,例如攝像頭、LiDAR和雷達,第二臺則包括英偉達強大的Drive Pegasus自駕車AI計算機,運行完整的自駕車軟件堆棧和處理過程,就像駕駛汽車的傳感器一樣。
通過虛擬仿真,人們可以通過測試數十億英里的自定義場景和罕見的場景案例來增強算法的穩健性,最終所花的時間和成本只是在真實物理道路上需要的一小部分。
-
芯片
+關注
關注
456文章
50936瀏覽量
424669 -
神經網絡
+關注
關注
42文章
4773瀏覽量
100890 -
NVIDIA
+關注
關注
14文章
5013瀏覽量
103244
原文標題:剛剛Nvidia發布僅售250萬元的超級怪獸DGX-2|附黃仁勛演講實錄
文章出處:【微信號:eetop-1,微信公眾號:EETOP】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
鼎陽科技銀河系列三款高端射頻新品重磅發布

納芯微發布兩款車規級壓力傳感器新品
蘋果將于今晚發布MacBook Pro系列新品
Littelfuse發布高頻MOSFET柵極驅動器新品
移遠通信推出兩款全功能ARM主板
Vishay發布兩款采用超小型MiniLED封裝的新型LED產品
NVIDIA推出兩款基于NVIDIA Ampere架構的全新臺式機GPU
Bosch Sensortec攜兩款最新傳感器解決方案亮相Sensor Shenzhen
NVIDIA發布兩款新的專業顯卡RTX A1000、RTX A400






 工商網監
工商網監
評論