") 機(jī)器學(xué)習(xí)應(yīng)用中的常見(jiàn)問(wèn)題分類問(wèn)題你了解多少
機(jī)器學(xué)習(xí)應(yīng)用中的常見(jiàn)問(wèn)題分類問(wèn)題你了解多少
分類問(wèn)題是機(jī)器學(xué)習(xí)應(yīng)用中的常見(jiàn)問(wèn)題,而二分類問(wèn)題是其中的典型,例如垃圾郵件的識(shí)別。本文基于UCI機(jī)器學(xué)習(xí)數(shù)據(jù)庫(kù)中的銀行營(yíng)銷數(shù)據(jù)集,從對(duì)數(shù)據(jù)集進(jìn)行探索,數(shù)據(jù)預(yù)處理和特征工程,到學(xué)習(xí)模型的評(píng)估與選擇,較為完整的展示了解決分類問(wèn)題的大致流程。文中包含了一些常見(jiàn)問(wèn)題的處理方式,例如缺失值的處理、非數(shù)值屬性如何編碼、如何使用過(guò)抽樣和欠抽樣的方法解決分類問(wèn)題中正負(fù)樣本不均衡的問(wèn)題等等。
1. 數(shù)據(jù)集選取與問(wèn)題定義
本次實(shí)驗(yàn)選取UCI機(jī)器學(xué)習(xí)庫(kù)中的銀行營(yíng)銷數(shù)據(jù)集(Bank Marketing Data Set:http://archive.ics.uci.edu/ml/datasets/Bank+Marketing) 。這些數(shù)據(jù)與葡萄牙銀行機(jī)構(gòu)的直接營(yíng)銷活動(dòng)有關(guān)。這些直接營(yíng)銷活動(dòng)是以電話為基礎(chǔ)的。通常來(lái)說(shuō),銀行機(jī)構(gòu)的客服人員至少需要聯(lián)系一次客戶來(lái)得知客戶是否將認(rèn)購(gòu)銀行的產(chǎn)品(定期存款)。因此,與該數(shù)據(jù)集對(duì)應(yīng)的任務(wù)是分類任務(wù),而分類目標(biāo)是預(yù)測(cè)客戶是(yes)否(no)認(rèn)購(gòu)定期存款(變量y)。
數(shù)據(jù)集包含四個(gè)csv文件:
1) bank-additional-full.csv: 包含所有的樣例(41188個(gè))和所有的特征輸入(20個(gè)),根據(jù)時(shí)間排序(從2008年5月到2010年9月);
2) bank-additional.csv: 從1)中隨機(jī)選出10%的樣例(4119個(gè));
3) bank-full.csv: 包含所有的樣例(41188個(gè))和17個(gè)特征輸入,根據(jù)時(shí)間排序。(該數(shù)據(jù)集是更老的版本,特征輸入較少);
4) bank.csv: 從3)中隨機(jī)選出10%的樣例4119個(gè))。
提供小的數(shù)據(jù)集(bank-additional.csv和bank.csv)是為了能夠快速測(cè)試一些計(jì)算代價(jià)較大的機(jī)器學(xué)習(xí)算法(例如SVM)。本次實(shí)驗(yàn)將選取較新的數(shù)據(jù)集,即包含20個(gè)特征量的1)和2)。
2. 認(rèn)識(shí)數(shù)據(jù)
2.1 數(shù)據(jù)集輸入變量與輸出變量
數(shù)據(jù)集的輸入變量是20個(gè)特征量,分為數(shù)值變量(numeric)和分類(categorical)變量。具體描述見(jiàn)數(shù)據(jù)集網(wǎng)站http://archive.ics.uci.edu/ml/datasets/Bank+Marketing。
輸出變量為y,即客戶是否已經(jīng)認(rèn)購(gòu)定期存款(binary: "yes", "no")。
2.2 原始數(shù)據(jù)分析
首先載入數(shù)據(jù),

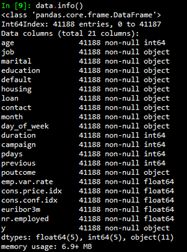
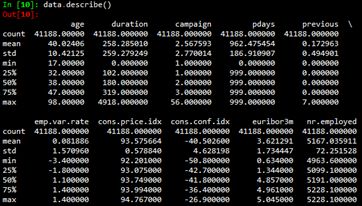
然后使用info()函數(shù)和describe()函數(shù)查看數(shù)據(jù)集的基本信息。
3. 數(shù)據(jù)預(yù)處理與特征工程
3.1 缺失值處理
從2.2節(jié)給出的數(shù)據(jù)集基本信息可以看出,數(shù)值型變量(int64和float64)沒(méi)有缺失。非數(shù)值型變量可能存在unknown值。使用如下代碼查看字符型變量unknown值的個(gè)數(shù)。
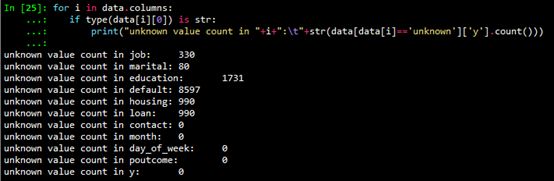
缺失值處理通常有如下的方法:
對(duì)于unknown值數(shù)量較少的變量,包括job和marital,刪除這些變量是缺失值(unknown)的行;
如果預(yù)計(jì)該變量對(duì)于學(xué)習(xí)模型效果影響不大,可以對(duì)unknown值賦眾數(shù),這里認(rèn)為變量都對(duì)學(xué)習(xí)模型有較大影響,不采取此法;
可以使用數(shù)據(jù)完整的行作為訓(xùn)練集,以此來(lái)預(yù)測(cè)缺失值,變量housing,loan,education和default的缺失值采取此法。由于sklearn的模型只能處理數(shù)值變量,需要先將分類變量數(shù)值化,然后進(jìn)行預(yù)測(cè)。本次實(shí)驗(yàn)使用隨機(jī)森林預(yù)測(cè)缺失值,代碼如下:
def fill_unknown(data, bin_attrs, cate_attrs, numeric_attrs):
# fill_attrs = ['education', 'default', 'housing', 'loan']
fill_attrs = []
for i in bin_attrs+cate_attrs:
if data[data[i] == 'unknown']['y'].count() < 500:
# delete col containing unknown
data = data[data[i] != 'unknown']
else:
fill_attrs.append(i)
data = encode_cate_attrs(data, cate_attrs)
data = encode_bin_attrs(data, bin_attrs)
data = trans_num_attrs(data, numeric_attrs)
data['y'] = data['y'].map({'no': 0, 'yes': 1}).astype(int)
for i in fill_attrs:
test_data = data[data[i] == 'unknown']
testX = test_data.drop(fill_attrs, axis=1)
train_data = data[data[i] != 'unknown']
trainY = train_data[i]
trainX = train_data.drop(fill_attrs, axis=1)
test_data[i] = train_predict_unknown(trainX, trainY, testX)
data = pd.concat([train_data, test_data])
return data
3.2 分類變量數(shù)值化
為了能使分類變量參與模型計(jì)算,我們需要將分類變量數(shù)值化,也就是編碼。分類變量又可以分為二項(xiàng)分類變量、有序分類變量和無(wú)序分類變量。不同種類的分類變量編碼方式也有區(qū)別。
3.2.1 二分類變量編碼
根據(jù)上文的輸入變量描述,可以認(rèn)為變量default 、housing 和loan 為二分類變量,對(duì)其進(jìn)行0,1編碼。代碼如下:
def encode_bin_attrs(data, bin_attrs):
for i in bin_attrs:
data.loc[data[i] == 'no', i] = 0
data.loc[data[i] == 'yes', i] = 1
return data
3.2.2 有序分類變量編碼
根據(jù)上文的輸入變量描述,可以認(rèn)為變量education是有序分類變量,影響大小排序?yàn)?illiterate", "basic.4y", "basic.6y", "basic.9y", "high.school", "professional.course", "university.degree", 變量影響由小到大的順序編碼為1、2、3、...,。代碼如下:
def encode_edu_attrs(data):
values = ["illiterate", "basic.4y", "basic.6y", "basic.9y",
"high.school", "professional.course", "university.degree"]
levels = range(1,len(values)+1)
dict_levels = dict(zip(values, levels))
for v in values:
data.loc[data['education'] == v, 'education'] = dict_levels[v]
return data
3.2.3 無(wú)序分類變量編碼
根據(jù)上文的輸入變量描述,可以認(rèn)為變量job,marital,contact,month,day_of_week為無(wú)序分類變量。需要說(shuō)明的是,雖然變量month和day_of_week從時(shí)間角度是有序的,但是對(duì)于目標(biāo)變量而言是無(wú)序的。對(duì)于無(wú)序分類變量,可以利用啞變量(dummy variables)進(jìn)行編碼。一般的,n個(gè)分類需要設(shè)置n-1個(gè)啞變量。例如,變量marital分為divorced、married、single,使用兩個(gè)啞變量V1和V2來(lái)編碼。
| marital | V1 | V2 |
| divorced | 0 | 0 |
| married | 1 | 0 |
| single | 0 | 1 |
Python的pandas包提供生成啞變量的函數(shù),故代碼如下:
def encode_cate_attrs(data, cate_attrs):
data = encode_edu_attrs(data)
cate_attrs.remove('education')
for i in cate_attrs:
dummies_df = pd.get_dummies(data[i])
dummies_df = dummies_df.rename(columns=lambda x: i+'_'+str(x))
data = pd.concat([data,dummies_df],axis=1)
data = data.drop(i, axis=1)
return data
3.3 數(shù)值特征預(yù)處理
3.3.1 連續(xù)型特征離散化
將連續(xù)型特征離散化的一個(gè)好處是可以有效地克服數(shù)據(jù)中隱藏的缺陷: 使模型結(jié)果更加穩(wěn)定。例如,數(shù)據(jù)中的極端值是影響模型效果的一個(gè)重要因素。極端值導(dǎo)致模型參數(shù)過(guò)高或過(guò)低,或?qū)е履P捅惶摷佻F(xiàn)象"迷惑",把原來(lái)不存在的關(guān)系作為重要模式來(lái)學(xué)習(xí)。而離散化,尤其是等距離散,可以有效地減弱極端值和異常值的影響。
通過(guò)觀察2.2節(jié)的原始數(shù)據(jù)集的統(tǒng)計(jì)信息,可以看出變量duration的最大值為4918,而75%分位數(shù)為319,遠(yuǎn)小于最大值,而且該變量的標(biāo)準(zhǔn)差為259,相對(duì)也比較大。因此對(duì)變量duration進(jìn)行離散化。具體地,使用pandas.qcut()函數(shù)來(lái)離散化連續(xù)數(shù)據(jù),它使用分位數(shù)對(duì)數(shù)據(jù)進(jìn)行劃分(分箱: bining),可以得到大小基本相等的箱子(bin),以區(qū)間形式表示。然后使用pandas.factorize()函數(shù)將區(qū)間轉(zhuǎn)為數(shù)值。
data[bining_attr] = pd.qcut(data[bining_attr], bining_num)
data[bining_attr] = pd.factorize(data[bining_attr])[0]+1
3.3.3 規(guī)范化
由于不同變量常常使用不同的度量單位,從數(shù)值上看它們相差很大,容易使基于距離度量的學(xué)習(xí)模型更容易受數(shù)值較大的變量影響。數(shù)據(jù)規(guī)范化就是將數(shù)據(jù)壓縮到一個(gè)范圍內(nèi),從而使得所有變量的單位影響一致。
for i in numeric_attrs:
scaler = preprocessing.StandardScaler()
data[i] = scaler.fit_transform(data[i])
3.3.4 持久化預(yù)處理后的數(shù)據(jù)
由于需要訓(xùn)練模型預(yù)測(cè)unknown值,預(yù)處理過(guò)程的時(shí)間代價(jià)比較大。因此將預(yù)處理后的數(shù)據(jù)持久化,保存到文件中,之后的學(xué)習(xí)模型直接讀取文件數(shù)據(jù)進(jìn)行訓(xùn)練預(yù)測(cè),無(wú)須再預(yù)處理。
def preprocess_data():
input_data_path = "../data/bank-additional/bank-additional-full.csv"
processed_data_path = '../processed_data/bank-additional-full.csv'
print("Loading data...")
data = pd.read_csv(input_data_path, sep=';')
print("Preprocessing data...")
numeric_attrs = ['age', 'duration', 'campaign', 'pdays', 'previous',
'emp.var.rate', 'cons.price.idx', 'cons.conf.idx',
'euribor3m', 'nr.employed',]
bin_attrs = ['default', 'housing', 'loan']
cate_attrs = ['poutcome', 'education', 'job', 'marital',
'contact', 'month','day_of_week']
data = shuffle(data)
data = fill_unknown(data, bin_attrs, cate_attrs, numeric_attrs)
data.to_csv(processed_data_path, index=False)
需要注意的是,由于原始數(shù)據(jù)是有序的(以時(shí)間為序),讀取原始數(shù)據(jù)后,需要將其隨機(jī)打亂,變成無(wú)序數(shù)據(jù)集。這里使用sklearn.utils包中的shuffle()函數(shù)進(jìn)行打亂。
一些情況下原始數(shù)據(jù)維度非常高,維度越高,數(shù)據(jù)在每個(gè)特征維度上的分布就越稀疏,這對(duì)機(jī)器學(xué)習(xí)算法基本都是災(zāi)難性(維度災(zāi)難)。當(dāng)我們又沒(méi)有辦法挑選出有效的特征時(shí),需要使用PCA等算法來(lái)降低數(shù)據(jù)維度,使得數(shù)據(jù)可以用于統(tǒng)計(jì)學(xué)習(xí)的算法。但是,如果能夠挑選出少而精的特征了,那么PCA等降維算法沒(méi)有很大必要。在本次實(shí)驗(yàn)中,數(shù)據(jù)集中的特征已經(jīng)比較有代表性而且并不過(guò)多,所以應(yīng)該不需要降維(實(shí)驗(yàn)證明降維確實(shí)沒(méi)有幫助)。關(guān)于降維的介紹可以參考之前寫(xiě)的這個(gè)博客(http://www.cnblogs.com/llhthinker/p/5522054.html)。
總之,數(shù)據(jù)預(yù)處理對(duì)于訓(xùn)練機(jī)器學(xué)習(xí)算法非常重要,正所謂“garbage in, garbage out”。
4. 模型的訓(xùn)練與評(píng)估
4.1 劃分?jǐn)?shù)據(jù)集
首先,需要將處理好的數(shù)據(jù)集劃分為3部分,分別是訓(xùn)練集(train set)、交叉檢驗(yàn)集(Cross validation set)和測(cè)試集(test set)。(另見(jiàn)博客學(xué)習(xí)模型的評(píng)估和選擇)。訓(xùn)練集是用于訓(xùn)練模型。交叉檢驗(yàn)集用來(lái)進(jìn)行模型的選擇,包括選擇不同的模型或者同一模型的不同參數(shù),即選擇在交叉檢驗(yàn)集上的測(cè)試結(jié)果最優(yōu)的模型。測(cè)試集用于檢測(cè)最終選擇的最優(yōu)模型的質(zhì)量。通常,可以按照6:2:2的比例劃分,代碼如下:
def split_data(data):
data_len = data['y'].count()
split1 = int(data_len*0.6)
split2 = int(data_len*0.8)
train_data = data[:split1]
cv_data = data[split1:split2]
test_data = data[split2:]
return train_data, cv_data, test_data
4.2 訓(xùn)練集重采樣
對(duì)導(dǎo)入的數(shù)據(jù)集按如下方式進(jìn)行簡(jiǎn)單統(tǒng)計(jì)可以發(fā)現(xiàn),正樣本(y=1)的數(shù)量遠(yuǎn)小于負(fù)樣本(y=0)的數(shù)量,近似等于負(fù)樣本數(shù)量的1/8。
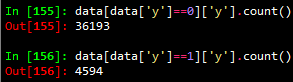
在分類模型中,這種數(shù)據(jù)不平衡問(wèn)題會(huì)使得學(xué)習(xí)模型傾向于把樣本分為多數(shù)類,但是,我們常常更關(guān)心少數(shù)類的預(yù)測(cè)情況。在本次分類問(wèn)題中,分類目標(biāo)是預(yù)測(cè)客戶是(yes:1)否(no:0)認(rèn)購(gòu)定期存款(變量y)。顯然,我們更關(guān)心有哪些客戶認(rèn)購(gòu)定期存款。為減弱數(shù)據(jù)不均衡問(wèn)題帶來(lái)的不利影響,在數(shù)據(jù)層面有兩種較簡(jiǎn)單的方法:過(guò)抽樣和欠抽樣。
過(guò)抽樣: 抽樣處理不平衡數(shù)據(jù)的最常用方法,基本思想就是通過(guò)改變訓(xùn)練數(shù)據(jù)的分布來(lái)消除或減小數(shù)據(jù)的不平衡。過(guò)抽樣方法通過(guò)增加少數(shù)類樣本來(lái)提高少數(shù)類的分類性能 ,最簡(jiǎn)單的辦法是簡(jiǎn)單復(fù)制少數(shù)類樣本,缺點(diǎn)是可能導(dǎo)致過(guò)擬合,沒(méi)有給少數(shù)類增加任何新的信息,泛化能力弱。改進(jìn)的過(guò)抽樣方法通過(guò)在少數(shù)類中加入隨機(jī)高斯噪聲或產(chǎn)生新的合成樣本等方法。
欠抽樣: 欠抽樣方法通過(guò)減少多數(shù)類樣本來(lái)提高少數(shù)類的分類性能,最簡(jiǎn)單的方法是通過(guò)隨機(jī)地去掉一些多數(shù)類樣本來(lái)減小多數(shù)類的規(guī)模,缺點(diǎn)是會(huì)丟失多數(shù)類的一些重要信息,不能夠充分利用已有的信息。
在本次實(shí)驗(yàn)中,采用Smote算法[Chawla et al., 2002]增加新的樣本進(jìn)行過(guò)抽樣;采用隨機(jī)地去掉一些多數(shù)類樣本的方法進(jìn)行欠抽樣。Smote算法的基本思想是對(duì)于少數(shù)類中每一個(gè)樣本x,以歐氏距離為標(biāo)準(zhǔn)計(jì)算它到少數(shù)類樣本集中所有樣本的距離,得到其k近鄰。然后根據(jù)樣本不平衡比例設(shè)置一個(gè)采樣比例以確定采樣倍率N,對(duì)于每一個(gè)少數(shù)類樣本x,從其k近鄰中隨機(jī)選擇若干個(gè)樣本,構(gòu)建新的樣本。針對(duì)本實(shí)驗(yàn)的數(shù)據(jù),為防止新生成的數(shù)據(jù)噪聲過(guò)大,新的樣本只有數(shù)值型變量真正是新生成的,其他變量和原樣本一致。重采樣的代碼如下:
def resample_train_data(train_data, n, frac):
numeric_attrs = ['age', 'duration', 'campaign', 'pdays', 'previous',
'emp.var.rate', 'cons.price.idx', 'cons.conf.idx',
'euribor3m', 'nr.employed',]
#numeric_attrs = train_data.drop('y',axis=1).columns
pos_train_data_original = train_data[train_data['y'] == 1]
pos_train_data = train_data[train_data['y'] == 1]
new_count = n * pos_train_data['y'].count()
neg_train_data = train_data[train_data['y'] == 0].sample(frac=frac)
train_list = []
if n != 0:
pos_train_X = pos_train_data[numeric_attrs]
pos_train_X2 = pd.concat([pos_train_data.drop(numeric_attrs, axis=1)] * n)
pos_train_X2.index = range(new_count)
s = smote.Smote(pos_train_X.values, N=n, k=3)
pos_train_X = s.over_sampling()
pos_train_X = pd.DataFrame(pos_train_X, columns=numeric_attrs,
index=range(new_count))
pos_train_data = pd.concat([pos_train_X, pos_train_X2], axis=1)
pos_train_data = pd.DataFrame(pos_train_data, columns=pos_train_data_original.columns)
train_list = [pos_train_data, neg_train_data, pos_train_data_original]
else:
train_list = [neg_train_data, pos_train_data_original]
print("Size of positive train data: {} * {}".format(pos_train_data_original['y'].count(), n+1))
print("Size of negative train data: {} * {}".format(neg_train_data['y'].count(), frac))
train_data = pd.concat(train_list, axis=0)
return shuffle(train_data)
4.3 模型的訓(xùn)練與評(píng)估
常用的分類模型包括感知機(jī),SVM,樸素貝葉斯,決策樹(shù),logistic回歸,隨機(jī)森林等等。本次實(shí)驗(yàn)選擇logistic回歸和隨機(jī)森林在訓(xùn)練集上進(jìn)行訓(xùn)練,在交叉檢驗(yàn)集上進(jìn)行評(píng)估,隨機(jī)森林的表現(xiàn)更優(yōu),所以最終選擇隨機(jī)森林模型在測(cè)試集上進(jìn)行測(cè)試。
對(duì)于不同的任務(wù),評(píng)價(jià)一個(gè)模型的優(yōu)劣可能不同。正如4.2節(jié)中所言,實(shí)驗(yàn)選取的數(shù)據(jù)集是不平衡的,數(shù)據(jù)集中負(fù)樣本0值占數(shù)據(jù)集總比例高達(dá)88.7%,如果我們的模型"預(yù)測(cè)"所有的目標(biāo)變量值都為0,那么準(zhǔn)確度(Accuracy)應(yīng)該在88.7%左右。但是,顯然,這種"預(yù)測(cè)"沒(méi)有意義。所以,我們更傾向于能夠預(yù)測(cè)出正樣本(y=1)的模型。因此,實(shí)驗(yàn)中將正樣本的f1-score作為評(píng)價(jià)模型優(yōu)劣的標(biāo)準(zhǔn)(也可以用其他類似的評(píng)價(jià)指標(biāo)如AUC)。訓(xùn)練與評(píng)估的代碼如下:
def train_evaluate(train_data, test_data, classifier, n=1, frac=1.0, threshold = 0.5):
train_data = resample_train_data(train_data, n, frac)
train_X = train_data.drop('y',axis=1)
train_y = train_data['y']
test_X = test_data.drop('y', axis=1)
test_y = test_data['y']
classifier = classifier.fit(train_X, train_y)
prodict_prob_y = classifier.predict_proba(test_X)[:,1]
report = classification_report(test_y, prodict_prob_y > threshold,
target_names = ['no', 'yes'])
prodict_y = (prodict_prob_y > threshold).astype(int)
accuracy = np.mean(test_y.values == prodict_y)
print("Accuracy: {}".format(accuracy))
print(report)
fpr, tpr, thresholds = metrics.roc_curve(test_y, prodict_prob_y)
precision, recall, thresholds = metrics.precision_recall_curve(test_y, prodict_prob_y)
test_auc = metrics.auc(fpr, tpr)
plot_pr(test_auc, precision, recall, "yes")
return prodict_y
利用訓(xùn)練評(píng)估函數(shù)可以進(jìn)行模型的選擇,分別選擇Logistic回歸模型和隨機(jī)森林模型,并對(duì)其分別調(diào)整各自參數(shù)的取值,最終選擇f1-score最高的隨機(jī)森林模型。具體地,當(dāng)將n_estimators設(shè)置為400,對(duì)正樣本進(jìn)行7倍的過(guò)抽樣(n=7),不對(duì)負(fù)樣本進(jìn)行負(fù)抽樣(frac=1.0),正樣本分類的閾值為0.40(threshold),即當(dāng)預(yù)測(cè)某樣本屬于正樣本的概率大于0.4時(shí),就將該樣本分類為正樣本。
forest = RandomForestClassifier(n_estimators=400, oob_score=True) prodict_y = train_evaluate(train_data, test_data, forest, n=7, frac=1, threshold=0.40)
該模型在交叉檢驗(yàn)集上的評(píng)估結(jié)果如下:
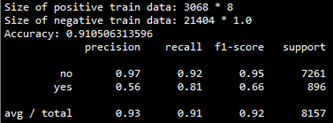
precision-recall曲線如下:
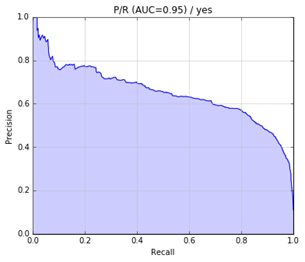
最后,將該模型應(yīng)用于測(cè)試集,測(cè)試結(jié)果如下:
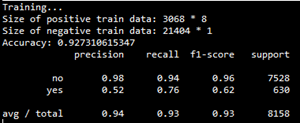
precision-recall曲線如下:
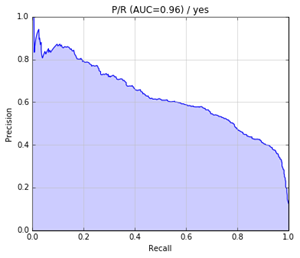
5. 展望
還可以考慮以下幾個(gè)方面以提高F1得分:
更細(xì)致的特征選擇,如派生屬性;
采用更好的方法解決數(shù)據(jù)不平衡問(wèn)題,如代價(jià)敏感學(xué)習(xí)方法;
更細(xì)致的調(diào)參;
嘗試其他分類模型如神經(jīng)網(wǎng)絡(luò);
-
編程
+關(guān)注
關(guān)注
88文章
3616瀏覽量
93738 -
機(jī)器
+關(guān)注
關(guān)注
0文章
782瀏覽量
40729
原文標(biāo)題:機(jī)器學(xué)習(xí)之分類問(wèn)題實(shí)戰(zhàn)
文章出處:【微信號(hào):AI_shequ,微信公眾號(hào):人工智能愛(ài)好者社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
干貨 | 這些機(jī)器學(xué)習(xí)算法,你了解幾個(gè)?
單片機(jī)學(xué)習(xí)中的常見(jiàn)問(wèn)題(持續(xù)更新中) 精選資料分享
講講UCOSIII移植過(guò)程中的常見(jiàn)問(wèn)題
機(jī)器學(xué)習(xí)分類算法中必須要懂的四種算法
你了解機(jī)器學(xué)習(xí)中的線性回歸嗎
目前機(jī)器學(xué)習(xí)面臨的常見(jiàn)問(wèn)題和挑戰(zhàn)
了解一下機(jī)器學(xué)習(xí)中的基礎(chǔ)知識(shí)
機(jī)器學(xué)習(xí)之分類分析與聚類分析
機(jī)器人關(guān)節(jié)模組常見(jiàn)問(wèn)題答疑






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論