") 深度學(xué)習(xí)在現(xiàn)實(shí)生活中的運(yùn)用場(chǎng)景
深度學(xué)習(xí)在現(xiàn)實(shí)生活中的運(yùn)用場(chǎng)景
引言
推薦作為解決信息過(guò)載和挖掘用戶(hù)潛在需求的技術(shù)手段,在美團(tuán)點(diǎn)評(píng)這樣業(yè)務(wù)豐富的生活服務(wù)電子商務(wù)平臺(tái),發(fā)揮著重要的作用。在美團(tuán)App里,首頁(yè)的“猜你喜歡”、運(yùn)營(yíng)區(qū)、酒店旅游推薦等重要的業(yè)務(wù)場(chǎng)景,都是推薦的用武之地。
圖1 美團(tuán)首頁(yè)“猜你喜歡”場(chǎng)景
目前,深度學(xué)習(xí)模型憑借其強(qiáng)大的表達(dá)能力和靈活的網(wǎng)絡(luò)結(jié)構(gòu)在諸多領(lǐng)域取得了重大突破,美團(tuán)平臺(tái)擁有海量的用戶(hù)與商家數(shù)據(jù),以及豐富的產(chǎn)品使用場(chǎng)景,也為深度學(xué)習(xí)的應(yīng)用提供了必要的條件。本文將主要介紹深度學(xué)習(xí)模型在美團(tuán)平臺(tái)推薦排序場(chǎng)景下的應(yīng)用和探索。
▌深度學(xué)習(xí)模型的應(yīng)用與探索
美團(tuán)推薦場(chǎng)景中每天活躍著千萬(wàn)級(jí)別的用戶(hù),這些用戶(hù)與產(chǎn)品交互產(chǎn)生了海量的真實(shí)行為數(shù)據(jù),每天能夠提供十億級(jí)別的有效訓(xùn)練樣本。為處理大規(guī)模的訓(xùn)練樣本和提高訓(xùn)練效率,我們基于PS-Lite研發(fā)了分布式訓(xùn)練的DNN模型,并基于該框架進(jìn)行了很多的優(yōu)化嘗試,在排序場(chǎng)景下取得了顯著的效果提升。

圖2 模型排序流程圖
如上圖所示,模型排序流程包括日志收集、訓(xùn)練數(shù)據(jù)生成、模型訓(xùn)練和線(xiàn)上打分等階段。當(dāng)推薦系統(tǒng)對(duì)瀏覽推薦場(chǎng)景的用戶(hù)進(jìn)行推薦時(shí),會(huì)記錄當(dāng)時(shí)的商品特征、用戶(hù)狀態(tài)與上下文信息,并收集本次推薦的用戶(hù)行為反饋。在經(jīng)過(guò)標(biāo)簽匹配和特征處理流程后生成最終的訓(xùn)練數(shù)據(jù)。我們?cè)陔x線(xiàn)運(yùn)用PS-Lite框架對(duì)Multi-task DNN模型進(jìn)行分布式訓(xùn)練,通過(guò)離線(xiàn)評(píng)測(cè)指標(biāo)選出效果較好的模型并加載到線(xiàn)上,用于線(xiàn)上排序服務(wù)。
下面將著重介紹我們?cè)谔卣魈幚砗湍P徒Y(jié)構(gòu)方面所做的優(yōu)化與嘗試。
特征處理
美團(tuán)“猜你喜歡”場(chǎng)景接入了包括美食、酒店、旅游、外賣(mài)、民宿、交通等多種業(yè)務(wù),這些業(yè)務(wù)各自有著豐富的內(nèi)涵和特點(diǎn),同時(shí)各業(yè)務(wù)的供給、需求與天氣、時(shí)間、地理位置等條件交織,構(gòu)成了O2O生活服務(wù)場(chǎng)景下特有的多樣性和復(fù)雜性,這就給如何更高效地組織排序結(jié)果提出了更高的要求。構(gòu)造更全面的特征、更準(zhǔn)確高效地利用樣本一直是我們優(yōu)化的重點(diǎn)方向。
特征種類(lèi)
User特征:用戶(hù)年齡,性別,婚否,有無(wú)孩子等
Item特征:價(jià)格,折扣,品類(lèi)和品牌相關(guān)特征,短期和長(zhǎng)期統(tǒng)計(jì)類(lèi)特征等
Context特征:天氣,時(shí)間,地理位置,溫度等
用戶(hù)行為:用戶(hù)點(diǎn)擊Item序列,下單Item序列等
除上述列舉的幾類(lèi)特征外,我們還根據(jù)O2O領(lǐng)域的知識(shí)積累,對(duì)部分特征進(jìn)行交叉,并針對(duì)學(xué)習(xí)效果對(duì)特征進(jìn)行了進(jìn)一步處理。具體的樣本和特征處理流程如下:
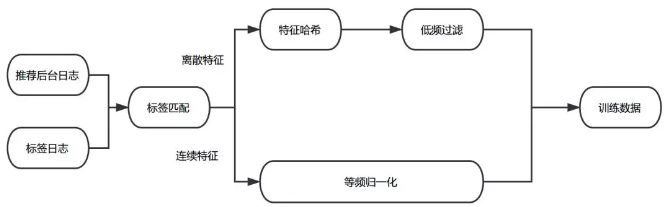
圖3 訓(xùn)練數(shù)據(jù)處理流程
標(biāo)簽匹配
推薦后臺(tái)日志會(huì)記錄當(dāng)前樣本對(duì)應(yīng)的User特征、Item特征與Context特征,Label日志會(huì)捕獲用戶(hù)對(duì)于推薦項(xiàng)的行為反饋。我們把兩份數(shù)據(jù)按照唯一ID拼接到一起,生成原始的訓(xùn)練日志。
等頻歸一化
通過(guò)對(duì)訓(xùn)練數(shù)據(jù)的分析,我們發(fā)現(xiàn)不同維度特征的取值分布、相同維度下特征值的差異都很大。例如距離、價(jià)格等特征的數(shù)據(jù)服從長(zhǎng)尾分布,體現(xiàn)為大部分樣本的特征值都比較小,存在少量樣本的特征值非常大。常規(guī)的歸一化方法(例如min-max,z-score)都只是對(duì)數(shù)據(jù)的分布進(jìn)行平移和拉伸,最后特征的分布仍然是長(zhǎng)尾分布,這就導(dǎo)致大部分樣本的特征值都集中在非常小的取值范圍內(nèi),使得樣本特征的區(qū)分度減小;與此同時(shí),少量的大值特征可能造成訓(xùn)練時(shí)的波動(dòng),減緩收斂速度。此外也可以對(duì)特征值做對(duì)數(shù)轉(zhuǎn)化,但由于不同維度間特征的分布不同,這種特征值處理的方式并不一定適用于其他維度的特征。
在實(shí)踐中,我們參考了Google的Wide & Deep Model[6]中對(duì)于連續(xù)特征的處理方式,根據(jù)特征值在累計(jì)分布函數(shù)中的位置進(jìn)行歸一化。即將特征進(jìn)行等頻分桶,保證每個(gè)桶里的樣本量基本相等,假設(shè)總共分了n個(gè)桶,而特征xi屬于其中的第bi(bi∈ {0, …, n - 1})個(gè)桶,則特征xi最終會(huì)歸一化成bi/n。這種方法保證對(duì)于不同分布的特征都可以映射到近似均勻分布,從而保證樣本間特征的區(qū)分度和數(shù)值的穩(wěn)定性。
低頻過(guò)濾
過(guò)多的極為稀疏的離散特征會(huì)在訓(xùn)練過(guò)程中造成過(guò)擬合問(wèn)題,同時(shí)增加參數(shù)的儲(chǔ)存數(shù)量。為避免該問(wèn)題,我們對(duì)離散特征進(jìn)行了低頻過(guò)濾處理,丟掉小于出現(xiàn)頻次閾值的特征。
經(jīng)過(guò)上述特征抽取、標(biāo)簽匹配、特征處理后,我們會(huì)給特征分配對(duì)應(yīng)的域,并對(duì)離散特征進(jìn)行Hash處理,最終生成LIBFFM格式的數(shù)據(jù),作為Multi-task DNN的訓(xùn)練樣本。下面介紹針對(duì)業(yè)務(wù)目標(biāo)所做的模型方面的優(yōu)化嘗試。
模型優(yōu)化與嘗試
在模型方面,我們借鑒工業(yè)界的成功經(jīng)驗(yàn),在MLP模型的基礎(chǔ)上,針對(duì)推薦場(chǎng)景進(jìn)行模型結(jié)構(gòu)方面的優(yōu)化。在深度學(xué)習(xí)中,很多方法和機(jī)制都具有通用性,比如Attention機(jī)制在機(jī)器翻譯,圖像標(biāo)注等方向上取得了顯著的效果提升,但并不是所有具體的模型結(jié)構(gòu)都能夠直接遷移,這就需要結(jié)合實(shí)際業(yè)務(wù)問(wèn)題,對(duì)引入的模型網(wǎng)絡(luò)結(jié)構(gòu)進(jìn)行了針對(duì)性調(diào)整,從而提高模型在具體場(chǎng)景中的效果。
Multi-task DNN
推薦場(chǎng)景上的優(yōu)化目標(biāo)要綜合考慮用戶(hù)的點(diǎn)擊率和下單率。在過(guò)去我們使用XGBoost進(jìn)行單目標(biāo)訓(xùn)練的時(shí)候,通過(guò)把點(diǎn)擊的樣本和下單的樣本都作為正樣本,并對(duì)下單的樣本進(jìn)行上采樣或者加權(quán),來(lái)平衡點(diǎn)擊率和下單率。但這種樣本的加權(quán)方式也會(huì)有一些缺點(diǎn),例如調(diào)整下單權(quán)重或者采樣率的成本較高,每次調(diào)整都需要重新訓(xùn)練,并且對(duì)于模型來(lái)說(shuō)較難用同一套參數(shù)來(lái)表達(dá)這兩種混合的樣本分布。針對(duì)上述問(wèn)題,我們利用DNN靈活的網(wǎng)絡(luò)結(jié)構(gòu)引入了Multi-task訓(xùn)練。
根據(jù)業(yè)務(wù)目標(biāo),我們把點(diǎn)擊率和下單率拆分出來(lái),形成兩個(gè)獨(dú)立的訓(xùn)練目標(biāo),分別建立各自的Loss Function,作為對(duì)模型訓(xùn)練的監(jiān)督和指導(dǎo)。DNN網(wǎng)絡(luò)的前幾層作為共享層,點(diǎn)擊任務(wù)和下單任務(wù)共享其表達(dá),并在BP階段根據(jù)兩個(gè)任務(wù)算出的梯度共同進(jìn)行參數(shù)更新。網(wǎng)絡(luò)在最后一個(gè)全連接層進(jìn)行拆分,單獨(dú)學(xué)習(xí)對(duì)應(yīng)Loss的參數(shù),從而更好地專(zhuān)注于擬合各自L(fǎng)abel的分布。
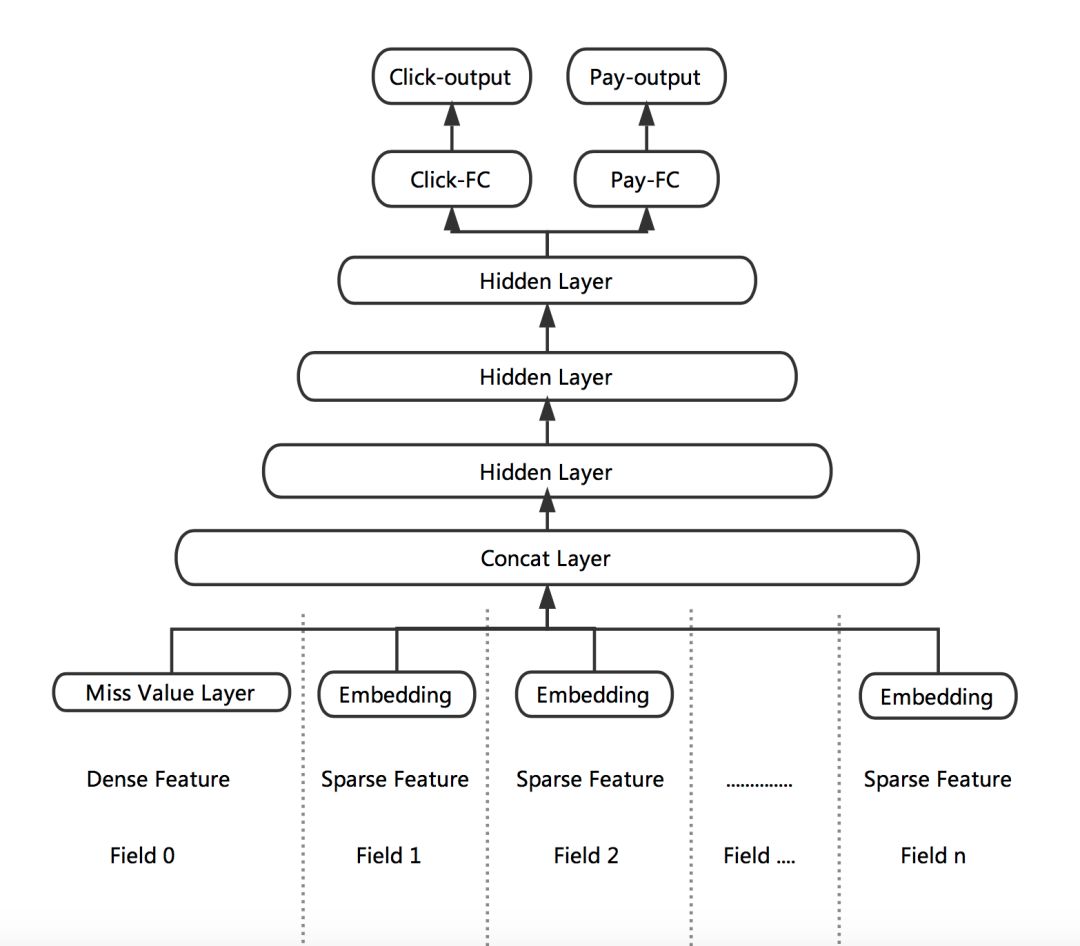
圖4 點(diǎn)擊與下單多目標(biāo)學(xué)習(xí)
Multi-task DNN的網(wǎng)絡(luò)結(jié)構(gòu)如上圖所示。線(xiàn)上預(yù)測(cè)時(shí),我們將Click-output和Pay-output做一個(gè)線(xiàn)性融合。
在此結(jié)構(gòu)的基礎(chǔ)上,我們結(jié)合數(shù)據(jù)分布特點(diǎn)和業(yè)務(wù)目標(biāo)進(jìn)行了進(jìn)一步的優(yōu)化:針對(duì)特征缺失普遍存在的情況我們提出Missing Value Layer,以用更合理的方式擬合線(xiàn)上數(shù)據(jù)分布;考慮將不同task的物理意義關(guān)聯(lián)起來(lái),我們提出KL-divergence Bound,以減輕某單一目標(biāo)的Noise的影響。下面我們就這兩塊工作做具體介紹。
Missing Value Layer
通常在訓(xùn)練樣本中難以避免地有部分連續(xù)特征存在缺失值,更好地處理缺失值會(huì)對(duì)訓(xùn)練的收斂和最終效果都有一定幫助。通常處理連續(xù)特征缺失值的方式有:取零值,或者取該維特征的平均值。取零值會(huì)導(dǎo)致相應(yīng)權(quán)重?zé)o法進(jìn)行更新,收斂速度減慢。而取平均值也略顯武斷,畢竟不同的特征缺失所表示的含義可能不盡相同。一些非神經(jīng)網(wǎng)絡(luò)的模型能比較合理的處理缺失值,比如XGBoost會(huì)通過(guò)Loss的計(jì)算過(guò)程自適應(yīng)地判斷特征缺失的樣本被劃分到左子樹(shù)還是右子樹(shù)更優(yōu)。受此啟發(fā),我們希望神經(jīng)網(wǎng)絡(luò)也可以通過(guò)學(xué)習(xí)的方式自適應(yīng)地處理缺失值,而不是人為設(shè)置默認(rèn)值。因此設(shè)計(jì)了如下的Layer來(lái)自適應(yīng)的學(xué)習(xí)缺失值的權(quán)重:

圖5 Miss Value Layer
通過(guò)上述的Layer,缺失的特征可以根據(jù)對(duì)應(yīng)特征的分布去自適應(yīng)的學(xué)習(xí)出一個(gè)合理的取值。
通過(guò)離線(xiàn)調(diào)研,對(duì)于提升模型的訓(xùn)練效果,自適應(yīng)學(xué)習(xí)特征缺失值的方法要遠(yuǎn)優(yōu)于取零值、取均值的方式,模型離線(xiàn)AUC隨訓(xùn)練輪數(shù)的變化如下圖所示:
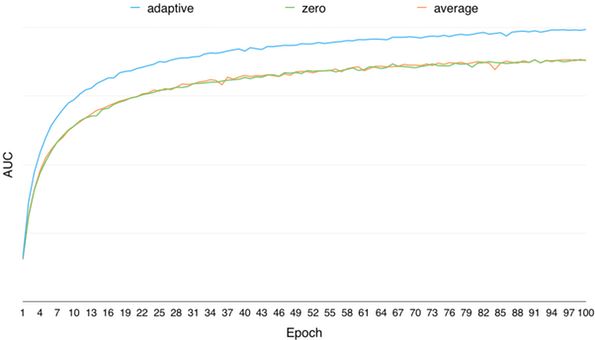
圖6 自適應(yīng)學(xué)習(xí)特征缺失值與取0值和均值效果對(duì)比
AUC相對(duì)值提升如下表所示:
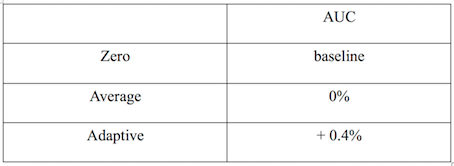
圖7 自適應(yīng)學(xué)習(xí)特征缺失值A(chǔ)UC相對(duì)值提升
KL-divergence Bound
我們同時(shí)考慮到,不同的標(biāo)簽會(huì)帶有不同的Noise,如果能通過(guò)物理意義將有關(guān)系的Label關(guān)聯(lián)起來(lái),一定程度上可以提高模型學(xué)習(xí)的魯棒性,減少單獨(dú)標(biāo)簽的Noise對(duì)訓(xùn)練的影響。例如,可以通過(guò)MTL同時(shí)學(xué)習(xí)樣本的點(diǎn)擊率,下單率和轉(zhuǎn)化率(下單/點(diǎn)擊),三者滿(mǎn)足p(點(diǎn)擊) * p(轉(zhuǎn)化) = p(下單)的意義。因此我們又加入了一個(gè)KL散度的Bound,使得預(yù)測(cè)出來(lái)的p(點(diǎn)擊) * p(轉(zhuǎn)化)更接近于p(下單)。但由于KL散度是非對(duì)稱(chēng)的,即KL(p||q) != KL(q||p),因此真正使用的時(shí)候,優(yōu)化的是KL(p||q) + KL(q||p)。
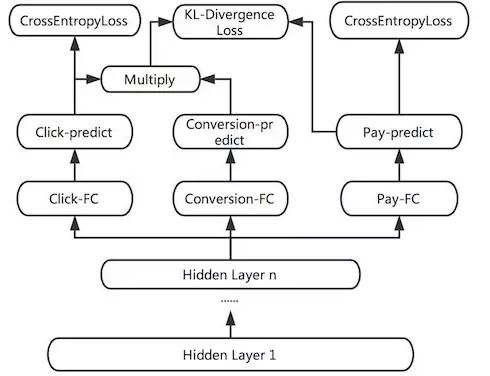
圖8 KL-divergence Bound
經(jīng)過(guò)上述工作,Multi-tast DNN模型效果穩(wěn)定超過(guò)XGBoost模型,目前已經(jīng)在美團(tuán)首頁(yè)“猜你喜歡”場(chǎng)景全量上線(xiàn),在線(xiàn)上也取得了點(diǎn)擊率的提升:
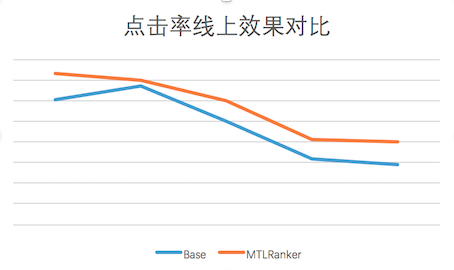
圖9 線(xiàn)上CTR效果與基線(xiàn)對(duì)比圖
線(xiàn)上CTR相對(duì)值提升如下表所示:
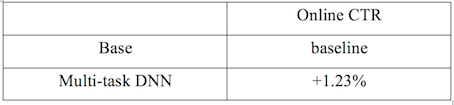
圖10 線(xiàn)上CTR效果相對(duì)值提升
除了線(xiàn)上效果的提升,Multi-task訓(xùn)練方式也很好的提高了DNN模型的擴(kuò)展性,模型訓(xùn)練時(shí)可以同時(shí)考慮多個(gè)業(yè)務(wù)目標(biāo),方便我們加入業(yè)務(wù)約束。
更多探索
在Multi-task DNN模型上線(xiàn)后,為了進(jìn)一步提升效果,我們利用DNN網(wǎng)絡(luò)結(jié)構(gòu)的靈活性,又做了多方面的優(yōu)化嘗試。下面就NFM和用戶(hù)興趣向量的探索做具體介紹。
NFM
為了引入Low-order特征組合,我們?cè)贛ulti-task DNN的基礎(chǔ)上進(jìn)行了加入NFM的嘗試。各個(gè)域的離散特征首先通過(guò)Embedding層學(xué)習(xí)得到相應(yīng)的向量表達(dá),作為NFM的輸入,NFM通過(guò)Bi-Interaction Pooling的方式對(duì)輸入向量對(duì)應(yīng)的每一維進(jìn)行2-order的特征組合,最終輸出一個(gè)跟輸入維度相同的向量。我們把NFM學(xué)出的向量與DNN的隱層拼接在一起,作為樣本的表達(dá),進(jìn)行后續(xù)的學(xué)習(xí)。

圖11 NFM + DNN
NFM的輸出結(jié)果為向量形式,很方便和DNN的隱層進(jìn)行融合。而且從調(diào)研的過(guò)程中發(fā)現(xiàn),NFM能夠加快訓(xùn)練的收斂速度,從而更有利于Embedding層的學(xué)習(xí)。因?yàn)镈NN部分的層數(shù)較多,在訓(xùn)練的BP階段,當(dāng)梯度傳到最底層的Embedding層時(shí)很容易出現(xiàn)梯度消失的問(wèn)題,但NFM與DNN相比層數(shù)較淺,有利于梯度的傳遞,從而加快Embedding層的學(xué)習(xí)。
通過(guò)離線(xiàn)調(diào)研,加入NFM后,雖然訓(xùn)練的收斂速度加快,但AUC并沒(méi)有明顯提升。分析原因是由于目前加入NFM模型部分的特征還比較有限,限制了學(xué)習(xí)的效果。后續(xù)會(huì)嘗試加入更多的特征域,以提供足夠的信息幫助NFM學(xué)出有用的表達(dá),深挖NFM的潛力。
用戶(hù)興趣向量
用戶(hù)興趣作為重要的特征,通常體現(xiàn)在用戶(hù)的歷史行為中。通過(guò)引入用戶(hù)歷史行為序列,我們嘗試了多種方式對(duì)用戶(hù)興趣進(jìn)行向量化表達(dá)。
Item的向量化表達(dá):線(xiàn)上打印的用戶(hù)行為序列中的Item是以ID的形式存在,所以首先需要對(duì)Item進(jìn)行Embedding獲取其向量化的表達(dá)。最初我們嘗試通過(guò)隨機(jī)初始化Item Embedding向量,并在訓(xùn)練過(guò)程中更新其參數(shù)的方式進(jìn)行學(xué)習(xí)。但由于Item ID的稀疏性,上述隨機(jī)初始化的方式很容易出現(xiàn)過(guò)擬合。后來(lái)采用先生成item Embedding向量,用該向量進(jìn)行初始化,并在訓(xùn)練過(guò)程中進(jìn)行fine tuning的方式進(jìn)行訓(xùn)練。
用戶(hù)興趣的向量化表達(dá):為生成用戶(hù)興趣向量,我們對(duì)用戶(hù)行為序列中的Item向量進(jìn)行了包括Average Pooling、 Max Pooling與Weighted Pooling三種方式的融合。其中Weighted Pooling參考了DIN的實(shí)現(xiàn),首先獲取用戶(hù)的行為序列,通過(guò)一層非線(xiàn)性網(wǎng)絡(luò)(Attention Net)學(xué)出每個(gè)行為Item對(duì)于當(dāng)前要預(yù)測(cè)Item的權(quán)重(Align Vector),根據(jù)學(xué)出的權(quán)重,對(duì)行為序列進(jìn)行Weighted Pooling,最終生成用戶(hù)的興趣向量。計(jì)算過(guò)程如下圖所示:

圖12 Weighted Pooling
通過(guò)離線(xiàn)AUC對(duì)比,針對(duì)目前的訓(xùn)練數(shù)據(jù),Average Pooling的效果為最優(yōu)的。效果對(duì)比如下圖所示:
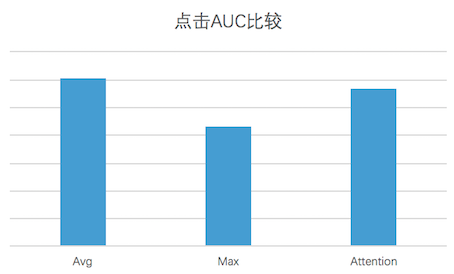
圖13 不同Pooling方式點(diǎn)擊AUC對(duì)比
以上是我們?cè)谀P徒Y(jié)構(gòu)方面的優(yōu)化經(jīng)驗(yàn)和嘗試,下面我們將介紹針對(duì)提高模型訓(xùn)練效率所做的框架性能優(yōu)化工作。
訓(xùn)練效率優(yōu)化
經(jīng)過(guò)對(duì)開(kāi)源框架的廣泛調(diào)研和選型,我們選擇了PS-Lite作為DNN模型的訓(xùn)練框架。PS-Lite是DMLC開(kāi)源的Parameter Server實(shí)現(xiàn),主要包含Server和Worker兩種角色,其中Server端負(fù)責(zé)模型參數(shù)的存儲(chǔ)與更新,Worker端負(fù)責(zé)讀取訓(xùn)練數(shù)據(jù)、構(gòu)建網(wǎng)絡(luò)結(jié)構(gòu)和進(jìn)行梯度計(jì)算。相較于其他開(kāi)源框架,其顯著優(yōu)點(diǎn)在于:
PS框架:PS-Lite的設(shè)計(jì)中可以更好的利用特征的稀疏性,適用于推薦這種有大量離散特征的場(chǎng)景。
封裝合理:通信框架和算法解耦,API強(qiáng)大且清晰,集成比較方便。
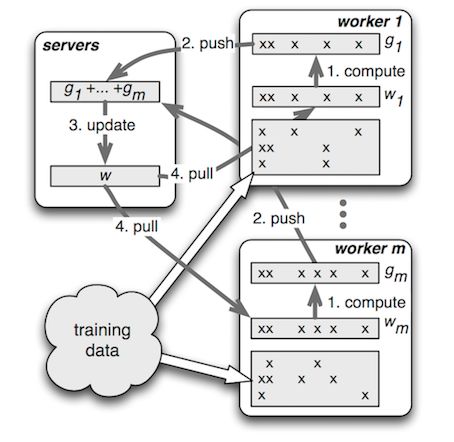
圖14 Parameter Server
在開(kāi)發(fā)過(guò)程中,我們也遇到并解決了一些性能優(yōu)化問(wèn)題:
為了節(jié)約Worker的內(nèi)存,通常不會(huì)將所有的數(shù)據(jù)儲(chǔ)存在內(nèi)存中,而是分Batch從硬盤(pán)中Pre-fetch數(shù)據(jù),但這個(gè)過(guò)程中存在大量的數(shù)據(jù)解析過(guò)程,一些元數(shù)據(jù)的重復(fù)計(jì)算(大量的key排序去重等),累計(jì)起來(lái)也是比較可觀的消耗。針對(duì)這個(gè)問(wèn)題我們修改了數(shù)據(jù)的讀取方式,將計(jì)算過(guò)的元數(shù)據(jù)也序列化到硬盤(pán)中,并通過(guò)多線(xiàn)程提前將數(shù)據(jù)Pre-fetch到對(duì)應(yīng)的數(shù)據(jù)結(jié)構(gòu)里,避免了在此處浪費(fèi)大量的時(shí)間來(lái)進(jìn)行重復(fù)計(jì)算。
在訓(xùn)練過(guò)程中Worker的計(jì)算效率受到宿主機(jī)實(shí)時(shí)負(fù)載和硬件條件的影響,不同的Worker之間的執(zhí)行進(jìn)度可能存在差異(如下圖所示,對(duì)于實(shí)驗(yàn)測(cè)試數(shù)據(jù),大部分Worker會(huì)在700秒完成一輪訓(xùn)練,而最慢的Worker會(huì)耗時(shí)900秒)。而通常每當(dāng)訓(xùn)練完一個(gè)Epoch之后,需要進(jìn)行模型的Checkpoint、評(píng)測(cè)指標(biāo)計(jì)算等需要同步的流程,因此最慢的節(jié)點(diǎn)會(huì)拖慢整個(gè)訓(xùn)練的流程。考慮到Worker的執(zhí)行效率是大致服從高斯分布的,只有小部分的Worker是效率極低的,因此我們?cè)谟?xùn)練流程中添加了一個(gè)中斷機(jī)制:當(dāng)大部分的機(jī)器已經(jīng)執(zhí)行完當(dāng)前Epoch的時(shí)候,剩余的Worker進(jìn)行中斷,犧牲少量Worker上的部分訓(xùn)練數(shù)據(jù)來(lái)防止訓(xùn)練流程長(zhǎng)時(shí)間的阻塞。而中斷的Worker在下個(gè)Epoch開(kāi)始時(shí),會(huì)從中斷時(shí)的Batch開(kāi)始繼續(xù)訓(xùn)練,保證慢節(jié)點(diǎn)也能利用所有的訓(xùn)練數(shù)據(jù)。

圖15 Worker耗時(shí)分布
▌總結(jié)與展望
深度學(xué)習(xí)模型落地到推薦場(chǎng)景后,對(duì)業(yè)務(wù)指標(biāo)有了明顯的提升,今后我們還將深化對(duì)業(yè)務(wù)場(chǎng)景的理解,做進(jìn)一步優(yōu)化嘗試。
在業(yè)務(wù)方面,我們將嘗試對(duì)更多的業(yè)務(wù)規(guī)則進(jìn)行抽象,以學(xué)習(xí)目標(biāo)的方式加入到模型中。業(yè)務(wù)規(guī)則一般是我們短期解決業(yè)務(wù)問(wèn)題時(shí)提出的,但解決問(wèn)題的方式一般不夠平滑,規(guī)則也不會(huì)隨著場(chǎng)景的變化進(jìn)行自適應(yīng)。通過(guò)Multi-task方式,把業(yè)務(wù)的Bias抽象成學(xué)習(xí)目標(biāo),在訓(xùn)練過(guò)程中對(duì)模型的學(xué)習(xí)進(jìn)行指導(dǎo),從而可以比較優(yōu)雅的通過(guò)模型解決業(yè)務(wù)問(wèn)題。
在特征方面,我們會(huì)繼續(xù)對(duì)特征的挖掘和利用進(jìn)行深入調(diào)研。不同于其他推薦場(chǎng)景,對(duì)于O2O業(yè)務(wù),Context特征的作用非常顯著,時(shí)間,地點(diǎn),天氣等因素都會(huì)影響用戶(hù)的決策。今后會(huì)繼續(xù)嘗試挖掘多樣的Context特征,并利用特征工程或者模型進(jìn)行特征的組合,用于優(yōu)化對(duì)樣本的表達(dá)。
在模型方面,我們將持續(xù)進(jìn)行網(wǎng)絡(luò)結(jié)構(gòu)的探索,嘗試新的模型特性,并針對(duì)場(chǎng)景的特點(diǎn)進(jìn)行契合。學(xué)術(shù)界和工業(yè)界的成功經(jīng)驗(yàn)都很有價(jià)值,給我們提供了新的思路和方法,但由于面臨的業(yè)務(wù)問(wèn)題和場(chǎng)景積累的數(shù)據(jù)不同,還是需要進(jìn)行針對(duì)場(chǎng)景的適配,以達(dá)到業(yè)務(wù)目標(biāo)的提升。
-
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5503瀏覽量
121162
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論