 百度最新AI算法就能克隆任何人的聲音!只需 3.7 秒!
百度最新AI算法就能克隆任何人的聲音!只需 3.7 秒!
僅需3.7秒的音頻,中國科技巨頭百度開發的一種新的AI算法就可以克隆出一種非常可信的虛假聲音。就像機器學習軟件的迅速發展一樣,這種軟件可以使虛擬視頻的制作民主化,這項研究表明為什么越來越難相信互聯網上的任何媒體。
這家科技巨頭的研究人員在Deep Voice發布了他們的最新進展,Deep Voice是一個為聲音克隆開發的系統。一年前,該技術需要大約30分鐘的音頻來創建新的假音頻片段。現在,只需幾秒鐘的培訓材料,它可以創造出更好的結果。
百度近日宣布,百度開發的新 AI 算法Deep Voice可以通過3.7秒鐘的錄音樣本數據就能完美的克隆出一個人的聲音。
Deep Voice是百度AI研究院一個由深度神經網絡構建的高質量語音轉(TTS )系統。該系統不僅提高的模擬的時間,百度還優化了它出錯的概率。甚至還在一個單GPU服務器上,把推斷規模提高到到每天1000萬次以上。
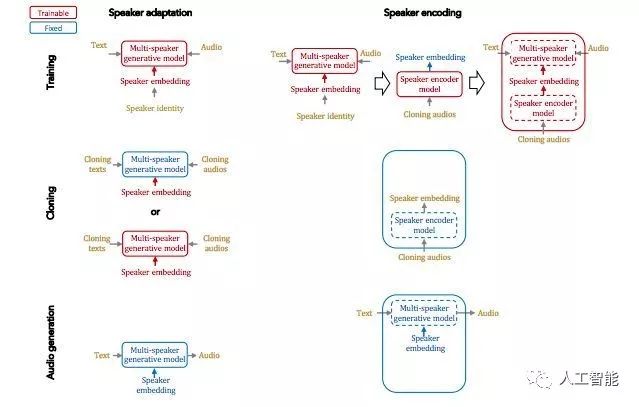
自適應說話人編碼方法在訓練、克隆和音頻生成中的應用
Deep Voice最早是在2017年的年初發布了第一版,初版的系統就能模擬初簡短的句子,而且說起話來幾乎無法區分和真人的區別。但是該系統一次只能模擬一個人的聲音,而且需要好幾個小時的學習才能克隆成功。但是最新發布的成功已經縮短到3.7秒,并且能將女性聲音轉變成男性,英式聲音變成美式。
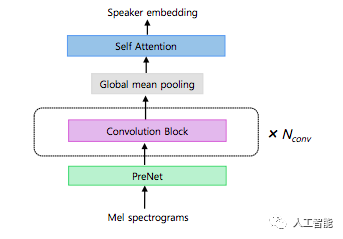
模擬器編碼器結構
百度研究院的研究人員在預印本網站 arxiv 上的發表了其 Deep Voice 系統的最新進展《Neural Voice Cloning with a Few Samples》。除了利用少量樣本克隆聲音外,系統還能將女性聲音轉變成男性,英式聲音變成美式。百度研究人員表示,這項研究可應用于人機交互的個性化方面。
-
神經網絡
+關注
關注
42文章
4772瀏覽量
100793 -
機器學習
+關注
關注
66文章
8419瀏覽量
132675
原文標題:只需 3.7 秒, 百度最新AI算法就能克隆任何人的聲音!
文章出處:【微信號:worldofai,微信公眾號:worldofai】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
2022百度世界大會-百度AI數字人“希加加”帶你暢游AI世界

百度宣布“百度AI加速器”開營,選擇免費開放AI相關技能
百度釋出新AI算法 可提升腫瘤辨識效率與正確性
百度開發聲音克隆技術,通過訓練數據便可復制聲音
借助深度學習算法實現5秒內克隆你的聲音
百度Create AI開發者大會:百度大腦位居中國市場第一




圖為科技聯合百度飛槳、英偉達共同推出AI軟硬一體快速部署方案






 工商網監
工商網監
評論