 阿里深度學習:在深度學習CTR預估核心問題上的應用進展
阿里深度學習:在深度學習CTR預估核心問題上的應用進展
蓋坤,江湖人稱“靖世”,是阿里巴巴集團“負責變現”的阿里媽媽精準展示技術部的資深總監。在 3 月 29 日新智元產業 · 躍遷 AI 技術峰會上,蓋坤詳解了阿里媽媽的深度學習演進之路,在用深度學習進行廣告推薦、全庫搜索等的經驗和問題。干貨滿滿,本文帶來精彩實錄。
作為阿里媽媽精準展示技術部資深總監的蓋坤在阿里的花名是靖世,被外界成為“算法天才”。2011 年,剛進阿里的蓋坤提出了分片線性模型 MLR,這對當時主要使用簡單線性模型做 CTR 預估的業界來說,因為極大地提高了 CTR 預估的準確性而頗具意義。幾年來,MLR 模型已經被廣泛應用在直通車定向和鉆展業務中。
蓋坤又帶領團隊在 CTR 預估方面推出了一個新的模型結構——深層用戶網絡興趣分布網絡,提出用戶的興趣是多樣的,利用深度學習在用戶歷史性行為和廣告CTR預估之間建立部分匹配,匹配度越高的歷史數據對預估結果影響越大,以此分辨出當下的用戶興趣點。在3月29日新智元產業 · 躍遷 AI 技術峰會上,蓋坤對這些算法進行了解讀。

蓋坤:非常高興與大家進行“深度學習演進之路”的交流,阿里媽媽是阿里巴巴集團下的大數據營銷平臺,是負責阿里巴巴變現的一個事業部。我在阿里有一個花名,阿里內部大家都是用花名溝通和聯系,我在阿里內部的名字是靖世,研究的方向是機器學習、計算機視覺、推薦系統和計算廣告。我在清華大學讀的本科和博士,專業是計算機視覺,畢業之后加入阿里巴巴廣告技術部,后來組成阿里媽媽事業部,這個事業部負責阿里所有的廣告變現產品。我現在是阿里媽媽的研究員,負責精準定向廣告技術團隊,負責的產品有智能鉆展、直通車定向廣告,熟悉阿里系統的同學可能會知道這兩個產品。
我將分三個部分來講一下。先講互聯網數據下的深度學習演進,然后講一下廣告推薦或者搜索業務里面怎么用深度學習,在檢索里碰見的問題怎么用深度學習解決,最后對未來的挑戰進行展望。

首先,互聯網下的大數據。互聯網的數據有什么特點?第一個特點是規模大,轉化成機器學習的語言就是維度特別高,樣本特別多,另外互聯網數據內部也有豐富的內在的關系。
這里舉一個例子,比如這是一個典型的APP或者互聯網網站上的數據,一邊是很多用戶,另外一邊很多物料,以電商為例,物料就是商品。我們現在有很多的用戶有很多的商品物料,這兩個都是大數據,歷史上會看到很多的行為,這是用戶跟商品的某種連接關系。再延展下去,每個用戶都有他的Profile信息,用戶看到商品的標題、詳情頁以及評論等等,這樣延展下去規模非常大的數據會被這些關系連接到一起,這就是互聯網數據的特點。
CTR預估。以經典的問題為例,為什么CTR預估很重要?這是廣告、推薦、搜索業務里的核心技術,這些業務的重要性相信已經不用多提,這三個業務在很多公司來講都是最核心的業務。以廣告為例,為什么廣告里的CTR預估很重要?有兩點。第一,CTR預估是廣告市場深度學習研究的沃土,有很多新的技術可以去探索和演進。第二,CTR預估直接跟互聯網企業的平臺收入相關,它其實對AI更重要。大家知道現在很多AI公司,包括公司內部的研究方向其實是對未來的布局。現金流從哪兒來?很多互聯網企業的現金從廣告來,所以廣告重要。
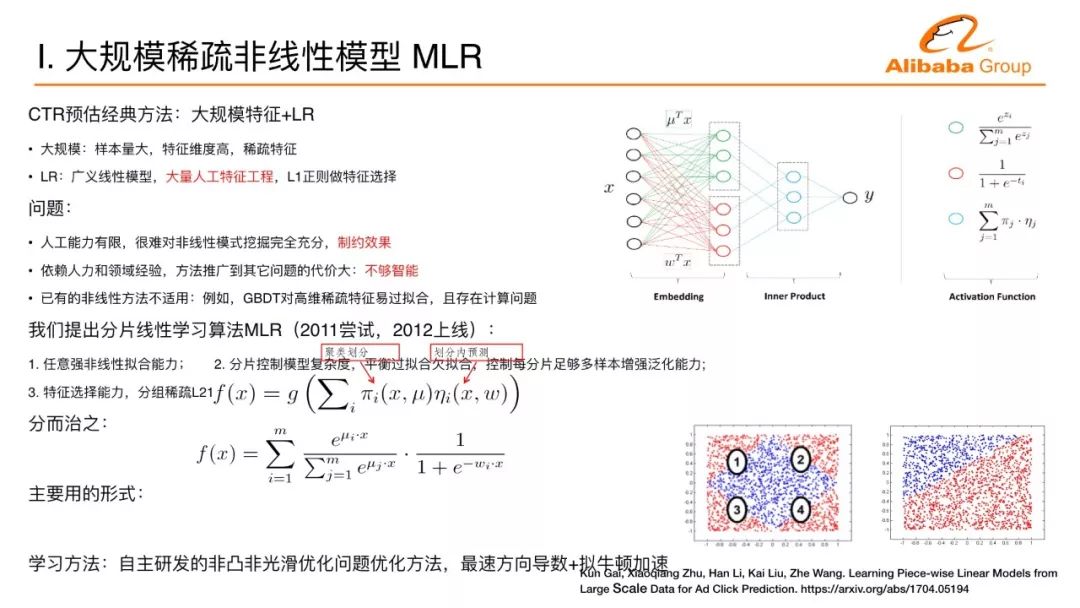
以廣告為例展開,在深度學習CTR預估核心問題上的應用進展,CTR預估的傳統方法分兩類,第一類是人工設計的強特征,維度不會非常高,一般來講就是一些強的統計特征,這種特征上傳統的做法,以雅虎為代表的公司用的是GBDT的方法。這樣的方法問題在于雖然很簡單有效,但是數據的人工處理使數據喪失了分辨力,數據維度降得非常低。第二種主流做法,把數據展開成高維度的數據,經典的做法用大規模的邏輯回歸,邏輯回歸是廣義的線性模型,模型非常簡單,但它的模型能力有限。
在介紹深度學習介紹之前,我首先展開一下在阿里媽媽的第一個工作,我們把邏輯回歸從簡單的線性模型變成非線性模型,變成三層的神經網絡。前面提到一個經典的做法用大規模的數據+邏輯回歸,這個邏輯回歸的一個問題是線性太簡單,我們需要去做大量的人工特征工程才能把這個效果變好。這里面我們第一個想法是,如何能夠讓算法更智能,自動在大規模的數據里面提取非線性的模式。
我們做了這樣一個嘗試,去做了一個分片線性的模型,背后的思路也比較直觀。把整個空間分成很多的區域,每個區域里面是一個線性模型。不同的區域做一些平滑的連接,整個空間就是分片線性的模型,當這個區域數足夠多、分片數足夠多,就可以逼近任意復雜的非線性曲面。
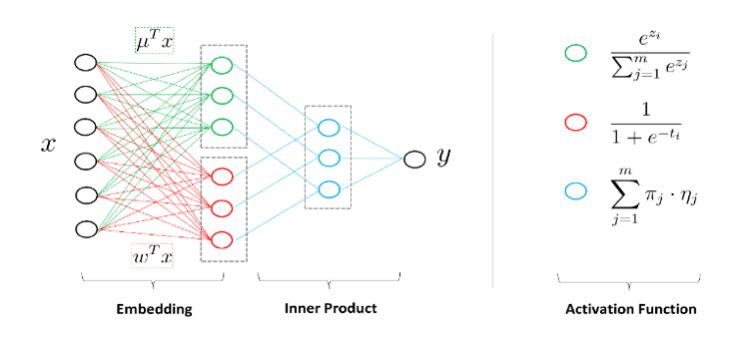
這是模型用神經網絡的觀點來看的示意圖。來了一個樣本之后怎么計算?首先計算對每個區域的隸屬度,假設有四個區域,會計算一個隸屬度。假設正好這個樣本屬于第一個區,隸屬度是1000,對每個區域里面還有一個預測器或者線性分類器,對每個區域里面有一個預測值,這四個預測值組成起來又是一個向量。上面的四維向量和下面的四維向量做內積,第一個區域的預測值選出來,實際為了數學處理方便用一個軟的隸屬度表述而并不是1000這種硬的方式。
怎么學習這個學習模型是一個主要的問題。我們還加入了分組系數的技術,使得大數據下的模型有自動選擇特征的能力。最終,它會轉化成非凸非光滑的問題,這是在2011年提出的模型,2012年上線的算法。非凸非光滑的問題當時沒有很好的手段,非光滑數學上表現的不是處處可導,數學上沒有導數怎么進行下降也是一個問題。雖然不是處處可導,這個函數處處方向可導,我們用方向導數找到最快下降方向,并用擬牛頓法進行加速。這個工作的名稱叫混合邏輯回歸MLR,做過CTR預估的同學可能會知道這樣一個工作。這是在我們探索深度學習在廣告中應用的一個基礎。
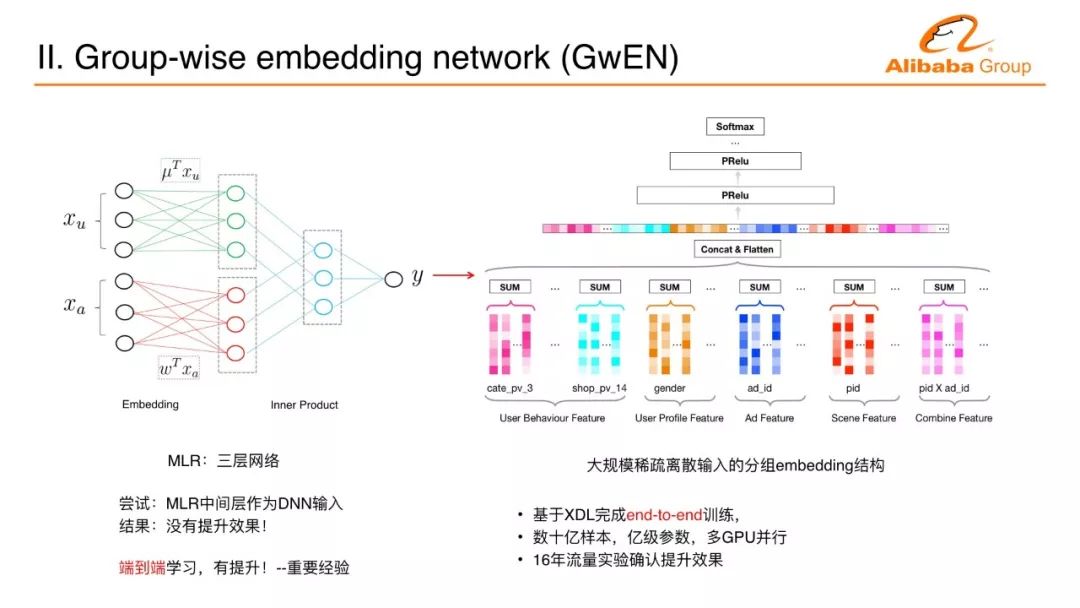
MLR是三層神經網絡,把大規模稀疏的離散化輸入變成兩個向量做內積,兩個向量拼接起來就是一個長的向量,跟現在的嵌入式技術是一樣的。把一個特別大規模的數據、不好處理的數據嵌入到一個空間里面變成一個向量,在連續空間一些連續的向量用深度學習比如多層感知機,就非常容易處理。第一步嘗試的深度學習是一個非常重要的經驗,貫穿了所有的深度學習的設計理念,用MLR產生的中間層向量抽取出來,后面直接去做多層感知機,把這個潛入向量作為多層感知機的輸入。這樣沒有提升效果,原因有兩點。第一點,MLR本來就是非線性模式;第二點,因為沒有端到端的訓練。
后面一個突破,把embedding的學習和多層感知機的訓練放在一起端到端學習,比原來的技術有非常明顯的提升。這也能夠解釋為什么深度學習近十年才有大的突破和進展。如果沒有端到端訓練,用淺層模型每次訓練產生feature再訓練再產生feature一層一層疊下去。之前很多人嘗試都沒有得出過這種深度的層疊網絡,直到端到端學習,使得我們在很多問題上得到突破。我們把分組的embedding豎過來,上面是多層感知機,這就變成阿里媽媽第一代深度學習網絡,基于數百億樣本、數億的特征維度,多GPU的端到端的訓練來完成這樣一個業務上線。這個上線的效果使CTR和GMV的提升非常明顯。
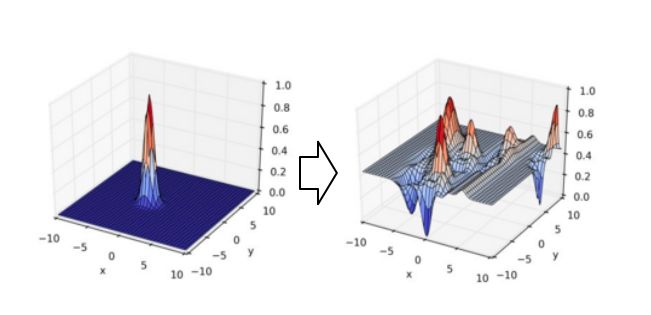
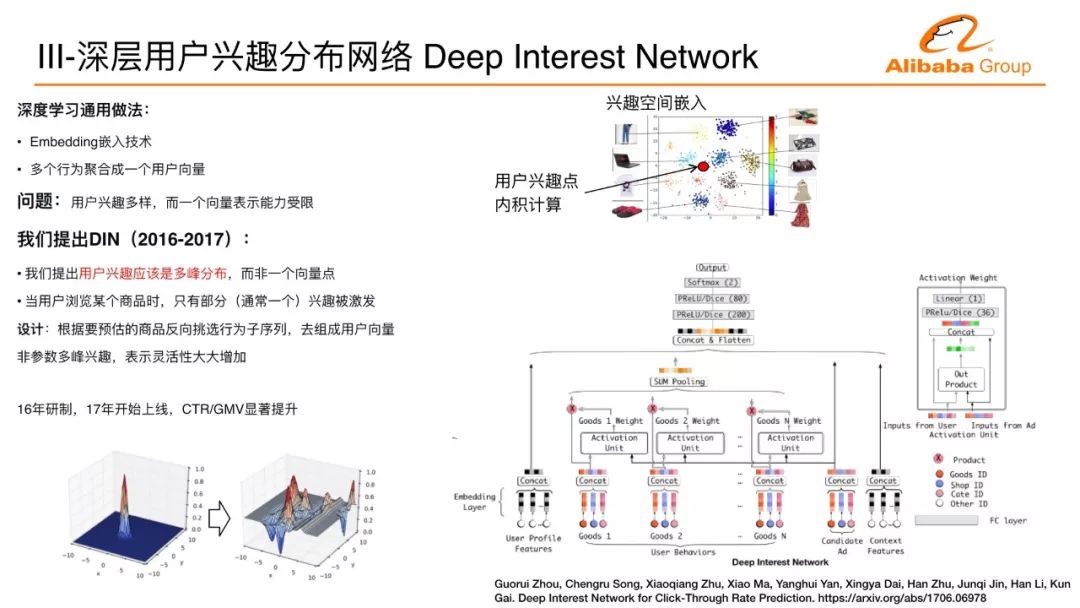
前面介紹了經典的比較標準化的深度學習在廣告里面的應用,接下來我們的方向在互聯網數據中,怎么樣能夠通過對用戶行為的洞察做更好的深度學習模型。這里是一個例子,我們剛才講到嵌入式技術,把每個商品通過嵌入式技術在嵌入空間表示一個點,一組特點用戶的一系列行為通過嵌入技術表述成一個點,這個可能會代表用戶。這個用戶點跟商品做最后的興趣度的計算,假設說這個計算就是跟距離成正比的話,用戶的點會表示成這樣一個興趣函數在空間里面就會變成一個單峰函數,用戶所處的點的地方的興趣度最大,越遠興趣度越小。
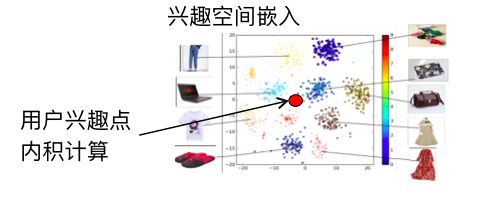
實際上,我們用戶的興趣到底是不是一個單峰的?我們認為不是的。大家在雙11有沒有購物經驗?是不是購物車里面加滿很多不同類的商品,說明用戶的興趣是多樣的,我們在非活動節點,在平時發現用戶的興趣也是多樣的。用戶的行為序列里面有大量不同的類目的子序列,用戶在相互跳轉。
基于這樣一個洞察,我們提出了用戶多峰興趣分布的深度學習神經網絡,我們希望去描述用戶的多個興趣,它使用的方法是子序列提取。我們在做CTR預估的時候都有一個侯選的商品,我們拿到一個侯選的商品要預估它的點擊率的時候,用這個商品去反向提取它行為序列里面對所有預估有幫助的子序列,而不是用全部的序列。這樣的話就能在包含很多子序列的復雜的序列里面,把相關的子序列提取出來,用這個相關的子序列形成表達,跟這個商品關聯。多峰興趣分布可以看作是任何一個商品去找到一個比較近的峰跟它計算興趣度,大概是這樣一個過程。
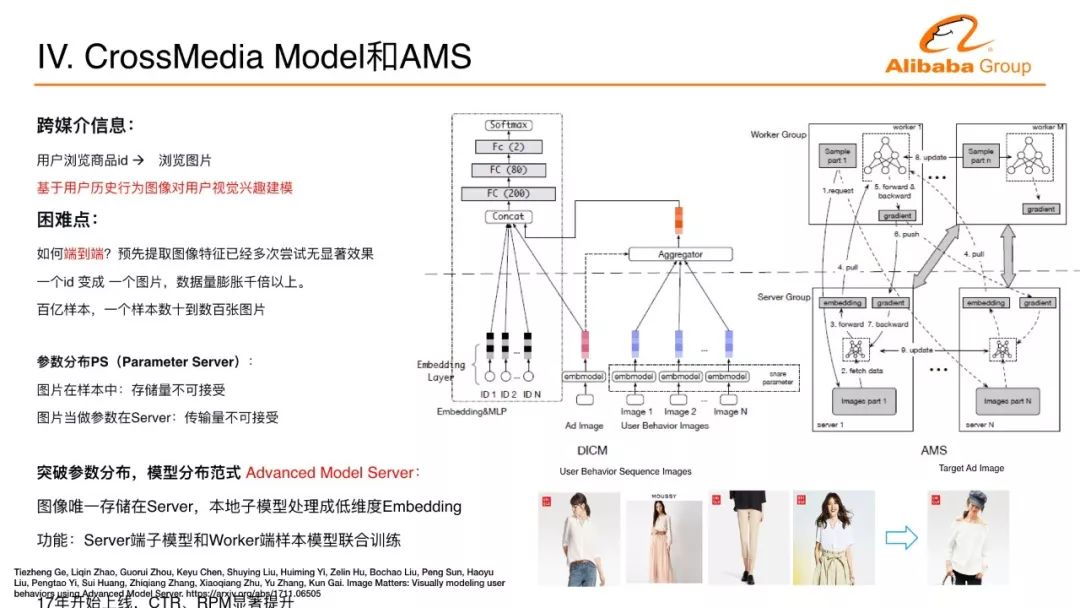
我們實際上采用的一種類似attention的技術達到相關的目的,也是在阿里媽媽的流量效果上使CTR、GMV顯著的指標有明顯的提升。用戶在互聯網上瀏覽各種物料的時候,背后的物料本質的理解非常重要,比如在電商環境下,用戶瀏覽商品的時候,很多時候看到這個商品的圖片來決定它到底怎么樣進行下一步的行為。我們能不能把這些圖片信息能夠到深度神經網絡來做更好的用戶興趣的建模?這樣帶來一個挑戰,任何一個行為從商品的ID變成一個商品的圖片,在樣本里面數據量是增大非常多倍,一個ID可能用一個幾byte的字節表示,如果變成一個圖片,動輒幾百K甚至幾兆,這個數據量至少是上千倍的增長。互聯網大規模的數據需要幾十或者幾百或者上千臺機器并行訓練,數據量爆膨幾千倍,即使對于阿里巴巴這樣的公司,這樣的問題也是很難處理的。
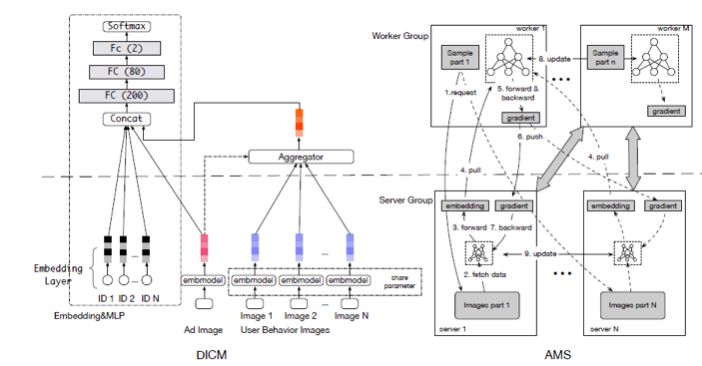
這樣的挑戰怎么解決?我們分析了現在在互聯網的深度學習建模里面經常用的分布方式叫參數服務器(Parameter Server),我的樣本有一個worker遍歷樣本,需要參數的時候從server端取參數。能不能承擔這樣的計算?首先把圖像存在樣本中,爆膨幾千倍不可接受。存在遠端的sever圖像進行去冗余的存儲,存儲可以解決,相關的圖像傳過來,數據量爆膨幾千倍也不可接受。遠端能不能不止存儲參數圖像,遠端是不是加一個model解決?遠端有圖像有model,遠端的model處理圖像部分的子model,worker端是遍歷樣本的CTR主model,這兩個model嫁接到一起,做一個端到端的訓練。剛才講過,很重要的一個經驗,只有端到端才work。這個圖像特征在阿里媽媽內部很多團隊嘗試,把圖像變成feature加入到CTR預估模型里面,如果CTR預估模型很強,這么加沒有作用。我們做這么一個端到端的訓練,提出新的模型分布的服務器,把參數分布方式變成模型分布方式,Server端不只有參數而且有子模型在計算,并且會和worker端主模型一起更新。這使得圖像可以處理成一個向量再傳輸,幾十倍、幾百倍,整個傳輸量降下來,使得整個聯合訓練的過程變成可能。通過框架上的分布式的變化來完成這個挑戰,在阿里媽媽的內部業務線上線,點擊率或者商業平臺的收益能力上有一個很顯著的提升。
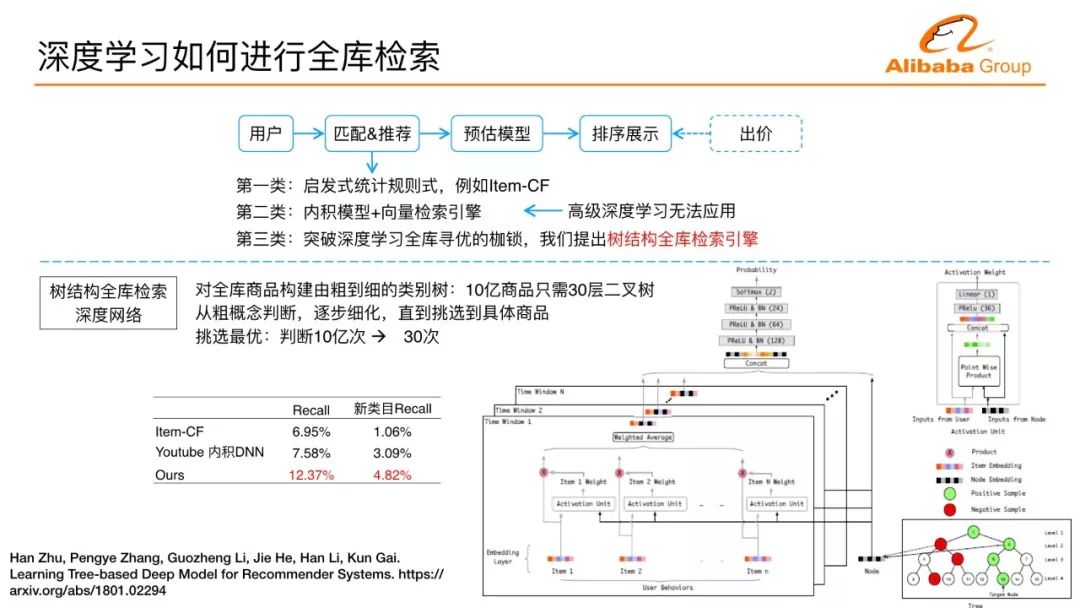
深度學習真正用在搜索推薦廣告的檢索系統里面,會遇見匹配問題或者檢索問題。這樣的一個流量端的業務一般來講會分幾個模塊,來一個流量之后,一個流量背后通常代表某個用戶某個場景下的瀏覽行為,先匹配,后面的預估模型對給定的商品做興趣度的預估,點擊率預估、轉化率預估,通過預估后面有一些排序展示,廣告還有出價,非廣告的話沒有出價環節。但我們不可能對大物料全庫進行預估。
假設背后有一百億物料,每個用戶需要在線計算一百億物料的點擊率這是不可能的,前面的匹配模塊需要縮減,縮減成幾千、一萬十萬,使得在線可以承擔這么多計算。流程里面前面的檢索匹配環節是整個系統表現的上限,后面模型無論如何做得再精巧,前面匹配很弱的話,業務整體目標無法得到提升。匹配方法可以分為三類。啟發式統計規則,現在非常精巧,而且推薦里面用的非常多的一類協同過濾,兩個商品看的多就相似,協同過濾怎么匹配?通過歷史行為的寶貝的商品的相似商品匹配過來,這樣的話很多人會遇到用這樣的一個推薦雖然很容易實行個性化,對于非個性化的業務指標來講會有很大的提升,會帶來一個問題,用戶經常看到跟歷史行為相似的商品,這在很多推薦場景里面可能都有一些用戶去抱怨的case。
一個很自然的提升匹配能力的想法是引入機器學習去衡量興趣度,找到最好的商品。引入機器學習,全庫的計算問題很難解決,所以我們在引入機器學習的時候有一個退化的方法,如果這個模型是一個內積模型,用戶是一個向量點,所有的物料都可以表示向量點,內積模型最后變成KNN查找的問題。怎么查找最近鄰?有向量檢索引擎可以做。CTR里面經常有交叉特征,用戶興趣分布,還有很多高級的深度學習模式,都沒辦法在這里面使用。我們針對怎么樣用任意的深度學習來做全庫的檢索尋優,提出樹結構的全庫檢索引擎,它的想法也比較直觀,把整個商品建立成一棵層次化的樹,有十億產品,30層的二叉樹,它的葉子層可以容納20億商品。我們的深度學習層每層掃描,每層找到最優,下層的節點在上一層非最優的孩子里面不繼續計算,相當于丟棄,直到最后找到全庫最優的,把10億次的衡量變成30億次從上到下的衡量,解決深度學習如何在全庫找最優的問題,解決了檢索和匹配的問題。這樣的方法跟前兩代方法比較,推薦召回率有非常明顯的提升。此外,我們限定只推薦用戶沒有行為過類目下的物料,用新類目召回率來做一個新穎性和召回率的綜合評估。比第一代的協同過濾方法在這樣的評估方式下將近提升了四倍多。這是技術上解決了如何用深度學習進行全庫檢索的問題。

未來的挑戰,對于推薦或者廣告的體驗問題和數據缺失問題,機器學習需要label數據也就是目標數據,現在有的目標是已經產生的用戶數據點擊購買等等數據。我們能夠對這些指標做最優化,很多體驗問題我們沒有Label很難優化,導致很難用機器學習去解這些問題。如何解決體驗問題?用算法自動去推導背后的用戶體驗還是用人力標注,像搜索引擎用相關性團隊去標注用戶的感受還是通過交互讓用戶主動來反饋?這個是未來需要探索的問題。
推薦評估問題,不管是工業界、學術界經常用召回率來評估,實際上召回率只評估用戶消費過商品的表現,如何評估新推薦商品對用戶的激發效應,這在召回率評估上并沒有體現。還有推薦的自循環問題,你感興趣的東西你點的多,推薦下一步會推薦越來越多,最后喪失掉很多其它你可能感興趣的其它推薦。在很多APP上推薦場景有很多,多場景下如何來做協同?從商家視角,每個商家其實面向的都是全量的海量用戶,如何探測潛在的客戶。商家面對的是整個消費者的運營過程,潛在興趣階段、購買階段整個鏈路上如何進行優化創新,這是面對商家在商業上希望能解決的問題。
阿里媽媽技術團隊在深度學習上持續演進和創新。我們追求業務結果,希望在追求業務結果背后能夠在技術上做一點不一樣的事情,希望能夠做一些業務的創新模式,如果有同學感興趣的話歡迎聯系我們。阿里媽媽攜手天池承辦的這一屆阿里媽媽國際廣告算法大賽,大家有興趣歡迎來挑戰。
阿里媽媽國際廣告算法大賽:
阿里巴巴(淘寶、天貓)是中國最大的電子商務平臺,為數億用戶提供了便捷優質的交易服務,也積累了海量的交易數據。阿里媽媽作為阿里巴巴廣告業務部門,在過去幾年利用這些數據采用深度學習、在線學習、強化學習等人工智能技術來高效準確地預測用戶的購買意向,有效提高了用戶的購物體驗和廣告主的ROI。然而,作為一個復雜的生態系統,電商平臺中的用戶行為偏好、商品長尾分布、熱點事件營銷等因素依然給轉化率預估帶來了巨大挑戰。比如,在雙十一購物狂歡節期間,商家和平臺的促銷活動會導致流量分布變化劇烈,在正常流量上訓練的模型無法很好地匹配這些特殊流量。如何更好地利用海量的交易數據來高效準確地預測用戶的購買意向,是人工智能和大數據在電子商務場景中需要繼續解決的技術難題。
2018年,阿里媽媽聯合國際人工智能聯合會議(IJCAI-2018)以及阿里云天池平臺,啟動阿里媽媽國際廣告算法大賽,以阿里電商廣告為研究對象,提供平臺的海量真實場景數據,參賽選手通過人工智能技術構建預測模型,預估用戶購買意向。優勝隊伍不僅有豐厚的獎金和差旅贊助費用,更可有參加7月于斯德哥爾摩舉辦的IJCAI-2018主會的資格。
-
互聯網
+關注
關注
54文章
11156瀏覽量
103315 -
阿里巴巴
+關注
關注
7文章
1616瀏覽量
47214 -
深度學習
+關注
關注
73文章
5503瀏覽量
121170
原文標題:【阿里算法天才蓋坤】解讀阿里深度學習實踐,CTR 預估、MLR 模型、興趣分布網絡等
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Nanopi深度學習之路(1)深度學習框架分析
深度學習DeepLearning實戰
什么是深度學習?使用FPGA進行深度學習的好處?
實例分析深度學習在廣告搜索中的應用
諾亞關于深度學習的研究進展及發展趨勢


回顧3年來的所有主流深度學習CTR模型





 工商網監
工商網監
評論