 機器學習的可解釋性為何如此重要?
機器學習的可解釋性為何如此重要?
無論構建機器學習的目的是什么,客戶總是希望能知道并理解模型的來龍去脈的。此外作為數據科學家和機器學習工作者,可解釋性對于模型的驗證和改進有著十分積極的意義。本文將從不同的角度闡述模型的可解釋性對于機器學習的重要性,并探討模型解釋的實踐方法。
機器學習的可解釋性為何如此重要?
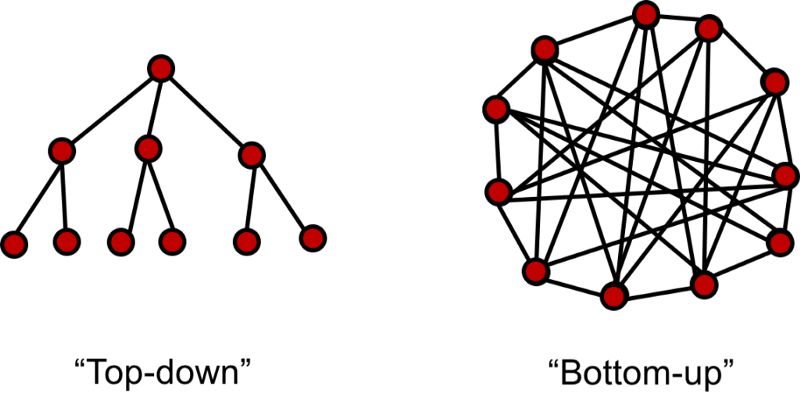
在傳統統計學中,我們通過數據構建并驗證假設來建立模型。通過構建的模型我們可以得到一系列規則并應用于業務中去。例如市場部門就可以通過構建與競爭者數據相關的模型來決定有效的市場競爭策略和方法。這類方法屬于自頂向下的方法,其中可解釋性是整套方法的解釋,它銜接了規則和所產生的行為策略。很多時候因果關系不那么明確,一個堅實的模型就需要為決策提供可靠的解釋,幫助人們清晰的理解。
而對于自底向上的模式,將商業模型中的一部分委派給機器學習,甚至從機器學習中得到全新的商業想法。自底向上的數據科學一般與手工勞作的自動化過程相關。例如制造業公司可將傳感器放置在設備上收集數據并預測其需要維護的時間,這就避免了運維工程師耗時的周期性檢查和維修,他們可以高效的維護工場設備保持在運行在良好的狀態。模型的可解釋可以幫助驗證模型是否再按期望的狀態運行,同時有利于在向自動化轉變的過程中創造多的信任。
作為一名數據科學家,經常需要對模型進行微調以達到最優的表現。數據科學一般都是在給定x和輸出y的情況下尋找誤差最小的映射模型。雖然訓練優秀的模型是數據科學家的核心能力,但具有更廣闊的視野也十分重要。對數據和模型的解讀對于數據科學處理流程是十分重要的,同時還能保證模型與目標問題的匹配。盡管我們經常會在各種前沿模型的嘗試中迷失自我,但如果能夠解釋模型的發現并指導你的工作這將會使得數據科學的處理變得更加透徹。
對于模型的深度分析是數據的科學的根本
1. 識別并減小偏差
偏差廣泛存在于數據集中,數據科學家需要識別并修正它的影響。很多時候數據集的規模可能很小不足以覆蓋所有的情況,或者在數據獲取過程中沒有考慮潛在的偏差。它的影響往往會在數據處理后護著在模型預測中變得明顯。偏差存在的形式各不相同,需要明確的是,處理偏差的手段并不單一,但在考慮模型的可解釋性的時候必須要考慮到偏差的存在。
2.幫助分析問題的前后聯系
在大多數問題中,我們收集到的數據僅僅是問題的粗略表示,并不能完全反映真實狀態下的復雜性。可解釋模型可以幫助我們理解并計量哪些因素被包含到模型中,并根據模型預測計量問題的前后聯系。
3.改善泛化性
可解釋性越強的模型一般都會具有更好的泛化性。可解釋性并不是模型對于每一個數據點的細節描述,而是結合了堅實的模型和數據以及對于問題的理解,綜合形成對于問題更好更全面的理解。
4.倫理和法律需要
在金融和醫療等行業人們需要審視模型的決策過程,并保證模型的決策不帶有歧視和違法等行為。隨著數據隱私保護的加強,模型的可解釋性變得更加重要。同時在一些如醫療、自動駕駛等關鍵領域,一個錯誤會產生十分巨大的反響,所以模型的可解釋性變得十分重要,讓人們明白系統是如何工作的,決策是如何形成的。
如何解釋你的模型?
在這一領域通常有一個規律,模型的可解釋性隨著復雜度的增加而下降,甚至更快的下降。特征重要性一般是解釋模型的起點。即使對于黑箱般的深度學習模型,依然有一系列技術用于解釋他們如何工作。在文章的最后我們還將討論LIME(Local Interpretable Model-Agnostic Explanations)框架來作為分析框架構建可解釋性。
1.特征重要性
一般線性模型
一般線性模型將特征作為x輸入并與模型的權重相結合,通過函數作用后可以預測一系列廣泛的變量。其常見的應用包括回歸(線性回歸)、分類(邏輯回歸)和泊松過程建模(泊松回歸)。其權重來自于特征訓練后的結果,他們可以為模型提供十分簡練的解釋。
例如構建一個文本分類器的過程中,可以繪制分類的特征圖并驗證它是否過擬合了噪聲。如果最重要的特征與你的直覺不符,這就意味著模型在噪聲上過擬合了,它在新數據上的表現也不會好。

隨機森林和支持向量機
即使對于樹這一類的非線性模型依然可以特征重要性中提取信息。在隨機森林中,特征重要性是驗證初始假設和評價模型學習效果的好方法。而在基于核方法的支持向量機中,可以將特征映射到核空間中進行學習。
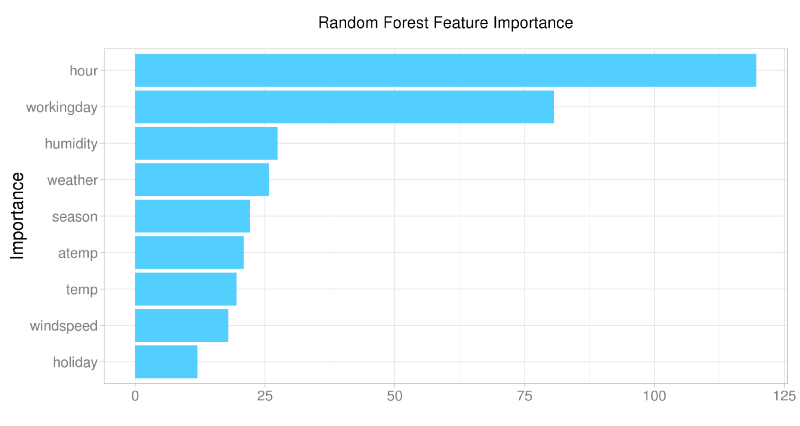
從上圖中可以看到模型從數據中學習到了什么,什么是重要的
深度學習
深度學習模型的表現十分優異,但由于缺乏可解釋性廣受詬病。這主要是由于內部的參數共享和復雜的特征抽取與組合。這類模型在一系列機器學習任務上達到了最先進的水平,很多人都在致力于銜接器預測與輸入的關系,期待解釋模型的優異表現。
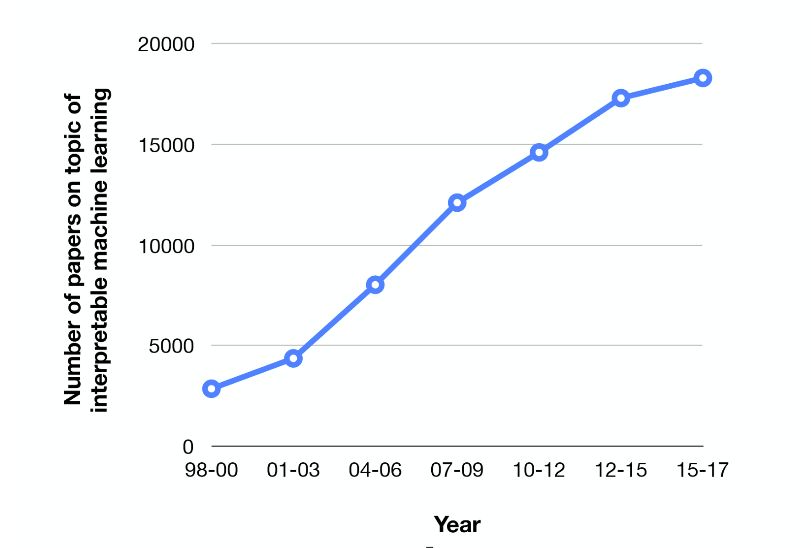
機器學習可解釋的學術研究火熱
深度學習的不可解釋性是阻礙其發展的障礙,特別是在圖像和文本處理上,很難解釋模型到底學習到了什么。目前這一領域的主要研究方向集中在將輸出或者預測映射回輸入數據上。雖然在線性模型上十分簡單,但在深度學習中依然是懸而未決的問題。目前主要集中在梯度和注意力機制兩方面來解決。
1) 基于梯度的方法中利用方向傳播梯度的概念產生出一幅地圖,用于描述出輸入圖中對于輸入預測重要的部分。
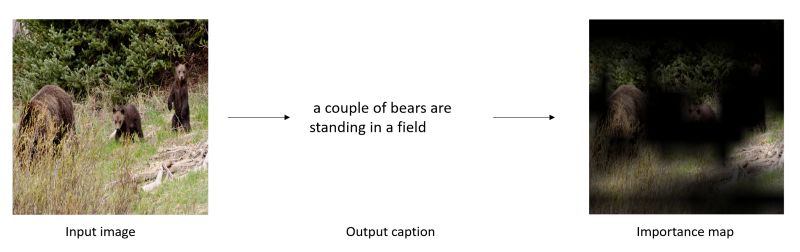
視覺標注任務中在原圖顯示對于結果重要的部分
2) 基于注意力機制的方法主要用于序列數據。除了網絡中歸一化的權重外,注意力權重被訓練用于"輸入門"。注意力權重可以被用于決定輸入部分多少被用于最后的網絡輸出。除了可解釋性,文本中的注意力機制在問答系統中幫助系統更加集中于任務本身。

顯示了文本中對于問題回答重要的部分
2.LIME
LIME是一個更為通用的解釋框架。
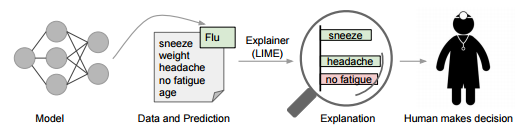
為了保持模型的獨立性,LIME修改局域的輸入將特別的測試用例輸入模型并觀察對預測造成的影響,通過一個個特定的樣例來觀察模型的可解釋性。在文本內容分類中,這意味著某些詞被替換后觀察輸出的結果。這就可以看到哪些修改后的結果是更為重要的。從而從側面來解釋模型。
-
機器學習
+關注
關注
66文章
8418瀏覽量
132646 -
深度學習
+關注
關注
73文章
5503瀏覽量
121170
原文標題:聊一聊機器學習的可解釋性和一個實踐方法
文章出處:【微信號:thejiangmen,微信公眾號:將門創投】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
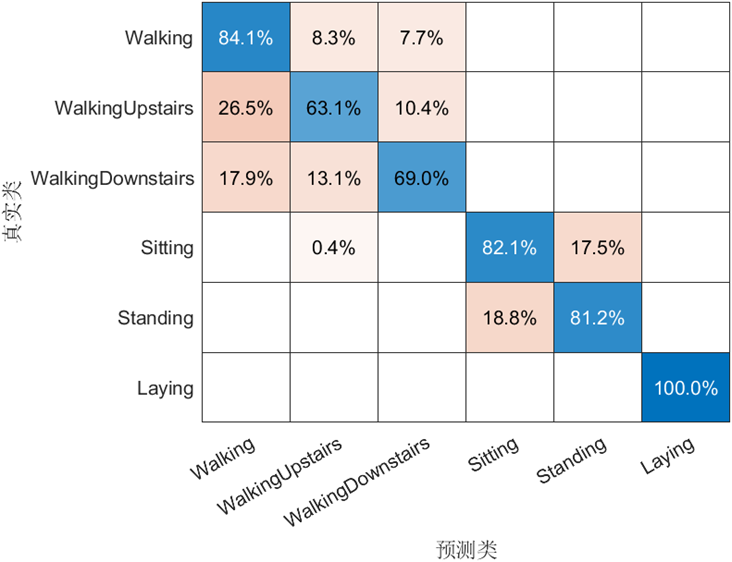
機器學習模型可解釋性的結果分析
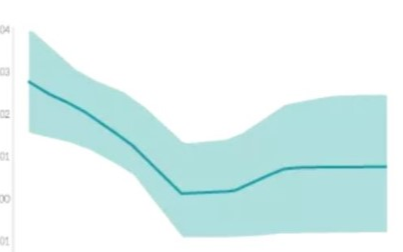
什么是“可解釋的”? 可解釋性AI不能解釋什么
斯坦福探索深度神經網絡可解釋性 決策樹是關鍵

機器學習模型的“可解釋性”的概念及其重要意義
Explainable AI旨在提高機器學習模型的可解釋性
機器學習模型可解釋性的介紹

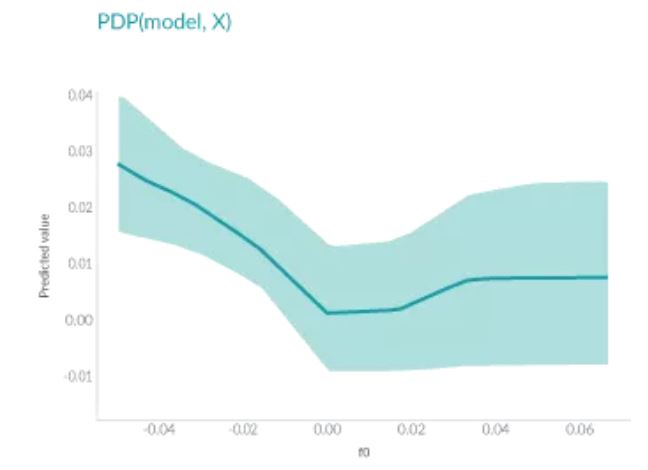
文獻綜述:確保人工智能可解釋性和可信度的來源記錄





 工商網監
工商網監
評論