 B-Tree與二叉查找樹的對比
B-Tree與二叉查找樹的對比
什么是B-Tree
B-Tree就是我們常說的B樹,一定不要讀成B減樹,否則就很丟人了。B樹這種數據結構常常用于實現數據庫索引,因為它的查找效率比較高。
磁盤IO與預讀
磁盤讀取依靠的是機械運動,分為尋道時間、旋轉延遲、傳輸時間三個部分,這三個部分耗時相加就是一次磁盤IO的時間,大概9ms左右。這個成本是訪問內存的十萬倍左右;正是由于磁盤IO是非常昂貴的操作,所以計算機操作系統對此做了優化:預讀;每一次IO時,不僅僅把當前磁盤地址的數據加載到內存,同時也把相鄰數據也加載到內存緩沖區中。因為局部預讀原理說明:當訪問一個地址數據的時候,與其相鄰的數據很快也會被訪問到。每次磁盤IO讀取的數據我們稱之為一頁(page)。一頁的大小與操作系統有關,一般為4k或者8k。這也就意味著讀取一頁內數據的時候,實際上發生了一次磁盤IO。
B-Tree與二叉查找樹的對比
我們知道二叉查找樹查詢的時間復雜度是O(logN),查找速度最快和比較次數最少,既然性能已經如此優秀,但為什么實現索引是使用B-Tree而不是二叉查找樹,關鍵因素是磁盤IO的次數。
數據庫索引是存儲在磁盤上,當表中的數據量比較大時,索引的大小也跟著增長,達到幾個G甚至更多。當我們利用索引進行查詢的時候,不可能把索引全部加載到內存中,只能逐一加載每個磁盤頁,這里的磁盤頁就對應索引樹的節點。
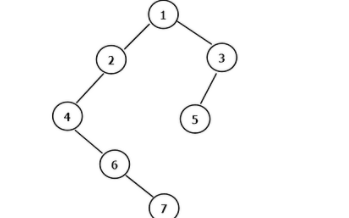
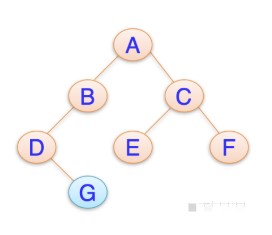
一、 二叉樹
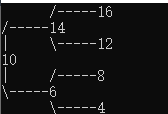
我們先來看二叉樹查找時磁盤IO的次:定義一個樹高為4的二叉樹,查找值為10:
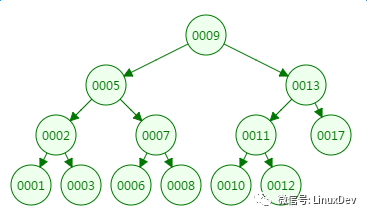
第一次磁盤IO:
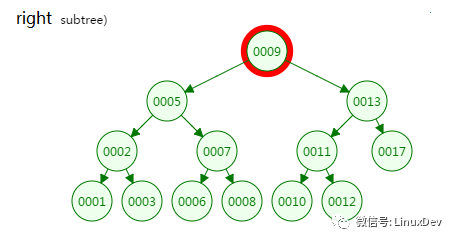
第二次磁盤IO
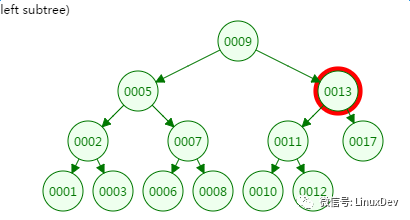
第三次磁盤IO:
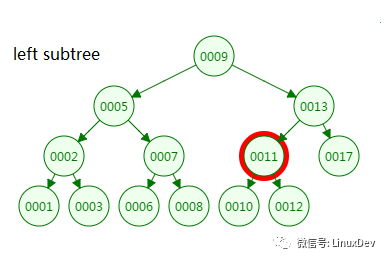
第四次磁盤IO:
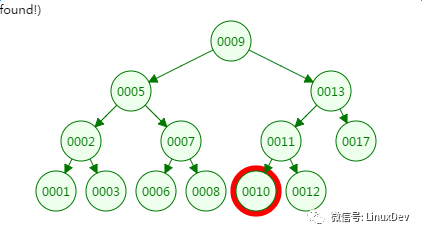
從二叉樹的查找過程了來看,樹的高度和磁盤IO的次數都是4,所以最壞的情況下磁盤IO的次數由樹的高度來決定。
從前面分析情況來看,減少磁盤IO的次數就必須要壓縮樹的高度,讓瘦高的樹盡量變成矮胖的樹,所以B-Tree就在這樣偉大的時代背景下誕生了。
二、B-Tree
m階B-Tree滿足以下條件:
1、每個節點最多擁有m個子樹
2、根節點至少有2個子樹
3、分支節點至少擁有m/2顆子樹(除根節點和葉子節點外都是分支節點)
4、所有葉子節點都在同一層、每個節點最多可以有m-1個key,并且以升序排列
如下有一個3階的B樹,觀察查找元素21的過程:
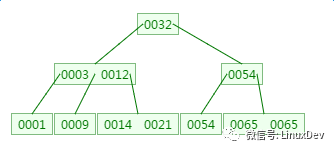
第一次磁盤IO:
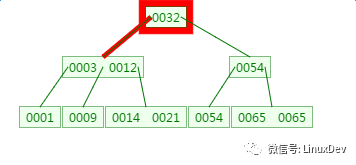
第二次磁盤IO:
這里有一次內存比對:分別跟3與12比對
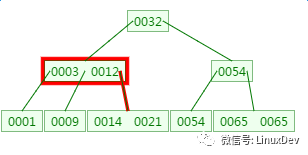
第三次磁盤IO:
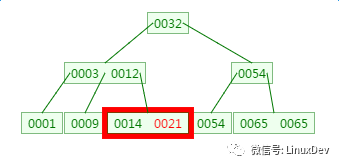
這里有一次內存比對,分別跟14與21比對
從查找過程中發現,B樹的比對次數和磁盤IO的次數與二叉樹相差不了多少,所以這樣看來并沒有什么優勢。
但是仔細一看會發現,比對是在內存中完成中,不涉及到磁盤IO,耗時可以忽略不計。另外B樹種一個節點中可以存放很多的key(個數由樹階決定)。
相同數量的key在B樹中生成的節點要遠遠少于二叉樹中的節點,相差的節點數量就等同于磁盤IO的次數。這樣到達一定數量后,性能的差異就顯現出來了。
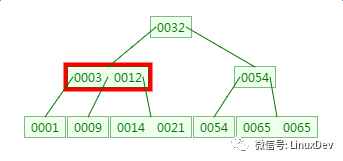
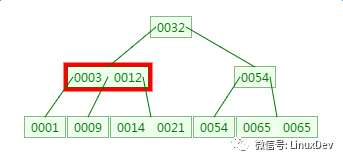
三、B樹的新增
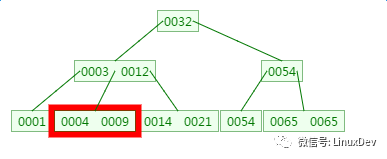
在剛才的基礎上新增元素4,它應該在3與9之間:
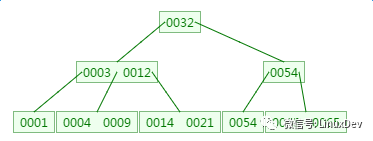
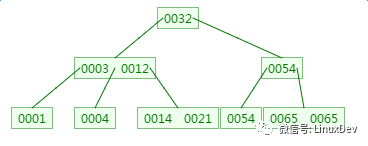
四、B樹的刪除
刪除元素9:
五、總結
插入或者刪除元素都會導致節點發生裂變反應,有時候會非常麻煩,但正因為如此才讓B樹能夠始終保持多路平衡,這也是B樹自身的一個優勢:自平衡;B樹主要應用于文件系統以及部分數據庫索引,如MongoDB,大部分關系型數據庫索引則是使用B+樹實現。
-
磁盤
+關注
關注
1文章
379瀏覽量
25209 -
二叉樹
+關注
關注
0文章
74瀏覽量
12325
原文標題:什么是B-Tree
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于Hash和二叉樹的路由表查找算法
二叉樹層次遍歷算法的驗證
AVL 樹和普通的二叉查找樹的詳細區別分析
紅黑樹(Red Black Tree)是一種自平衡的二叉搜索樹
二叉樹操作的相關知識和代碼詳解





 工商網監
工商網監
評論