 概念化的簡單強化學習框架讓虛擬特技演員做出難度更高的動作
概念化的簡單強化學習框架讓虛擬特技演員做出難度更高的動作
「運動控制問題已經成為強化學習的基準,而深度強化學習的方法可以很高效的處理控制和運動等問題。然而,使用深度強化學習訓練的目標對象也經常會出現不自然動作、異常抖動、步伐不對稱以及四肢過度擺動等問題。我們可以將我們的虛擬人物訓練的行為表現更加自然嗎?」
伯克利 BAIR 實驗室介紹了他們對于運動建模的最新研究成果,他們使用動作捕捉片段訓練自己的模型。訓練中著力減小跟蹤誤差并采用提前終止的方法來優化訓練結果。訓練模型最終表現優秀。 詳情介紹如下。
虛擬特技演員
我們從計算機圖形學研究中獲得了啟發。在這一領域中基于自然動作的人體仿真模擬已經存在大量的工作,相關研究已經進行了很多年。由于電影視覺效果以及游戲對于動作質量要求很高,多年下來,基于豐富的肢體動作動畫已經開發相應控制器,這個控制器可以生成大量針對不同任務和對象的魯棒性好又自然的動作。這種方法會利用人類洞察力去合并特定任務的控制結構,最終會對訓練對象所產生的動作有很強的歸納偏向。這種做法會讓控制器更加適應特定的訓練對象和任務。比如被設計去生成行走動作的控制器可能會因為缺乏人類洞察力而無法生成更有技巧性的動作。
在本研究中,我們將利用兩個領域的綜合優勢,在使用深度學習模型的同時也生成自然的動作,這動作質量足以匹敵計算機圖形學當前最先進的全身動作模擬。我們提出了一個概念化的簡單強化學習框架,這個框架讓模擬對象通過學習樣例動作剪輯來做出難度更高的動作,其中樣例動作來自于人類動作捕捉。給出一個技巧的展示,例如旋踢或者后空翻,我們的訓練對象在仿真中會以穩健的策略去模仿這一動作。我們的策略所生成的動作與動作捕捉幾乎沒有區別。
動作模擬
在大多數強化學習基準中,模擬對象都使用簡單的模型,這些模型只有一些對真實動作進行粗糙模仿的動作。因此,訓練對象也容易學習其中的特異動作從而產生現實世界根本不會有的行為。故該模型利用的現實生物力學模型越真實,就會產生越多的自然行為。但建設高保真的模型非常具有挑戰性,且即使在該模型下也有可能會生成不自然行為。
另一種策略就是數據驅動方式,即通過人類動作捕捉來生成自然動作樣例。訓練對象就可以通過模仿樣例動作來產生更加自然的行為。通過模仿運動樣例進行仿真的方式在計算機動畫制作中存在了很久,最近開始在制作中引入深度強化學習。結果顯示訓練對象動作的確更加自然,然而這離實現多動作仿真還有很長一段距離。
在本研究中,我們將使用動作模仿任務來訓練模型,我們的訓練目標就是訓練對象最終可以復現一個給定的參考動作。參考動作是以一系列目標姿勢表示的(q_0,q_1,…,q_T),其中 q_t 就是目標在t時刻的姿勢。獎勵函數旨在縮小目標姿勢 q^_t 與訓練對象姿勢 q_t 之間的方差。
雖然在運動模仿上應用了更復雜的方法,但我們發現簡單的縮小跟蹤誤差(以及兩個額外的視角的誤差)表現的出人意料的好。這個策略是通過訓練使用PPO算法優化過的目標實現的。
利用這個框架,我們可以開發出包含大量高挑戰性技巧(運動,雜技,武術,舞蹈)的策略。
接著我們比較了現有方法和之前用來模仿動作捕捉剪輯的方法(IGAL)。結果顯示我們的方法更加簡單,且更好的復現了參考動作。由此得到的策略規避了很多深度強化學習方法的弊端,可以使得訓練對象的像人一樣行動流暢。
Insights
參考狀態初始化
假設虛擬對象正準備做后空翻,它怎樣才能知道在半空做一個完整翻轉可以獲得高獎勵呢?由于大多強化學習方法是可回溯的,他們只觀察已訪問到的狀態的獎勵。在后空翻這個實驗中,虛擬對象必須在知道翻轉中的這些狀態會獲得高獎勵之前去觀察后空翻的運動軌跡。但是因為后空翻對于起始和落地的條件非常敏感,所以虛擬對象不太可能在隨機嘗試中劃出一條成功的翻轉軌跡。為了給虛擬對象提示,我們會把它初始化為參考動作的隨機采樣狀態。所以,虛擬對象有時從地面開始,有時從翻轉的中間狀態開始。這樣就可以讓虛擬對象在不知道怎么達到某些狀態之前就知道哪些狀態可以獲得高獎勵。
下圖就是是否使用RSI訓練的策略之間的差別,在訓練之前,虛擬對象都會被初始化至一個特定的狀態。結果顯示,未使用RSI訓練的對象沒有學會后空翻只學會了向后跳。
提前終止
提前終止對于強化學習研究者來說很重要,他經常被用來提升模仿效率。當虛擬對象處于一種無法成功的狀態時,就可以提前終止了,以免繼續模仿。這里我們證明了提前終止對結果有很重要的影響。我們依舊考慮后空翻這一動作,在訓練的開始階段,策略非常糟糕,而虛擬對象基本上是不停的失敗。當它摔倒后就極難恢復到之前的狀態。首次試驗成敗基本由樣本決定,所以虛擬對象大多數時間都是在地上徒勞掙扎。其他的方法論也曾經遭遇過這樣的不平衡問題,比如監督學習。當虛擬對象進入無用狀態時,就可以終結這次訓練來緩解這個問題。ET結合RSI就可以保證數據集中的大部分樣本是接近參考軌跡的。沒有ET,虛擬對象就學不會空翻,而只會摔倒然后在地上嘗試表演這一動作。
其他成果
通過給模型輸入不同參考動作,模擬對象最終可以學會24中技巧。
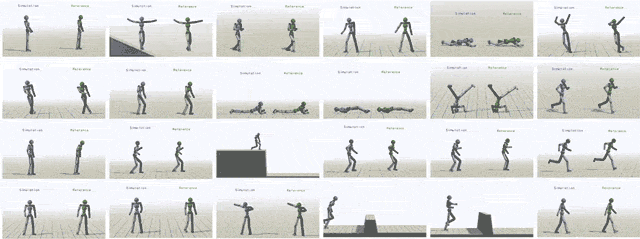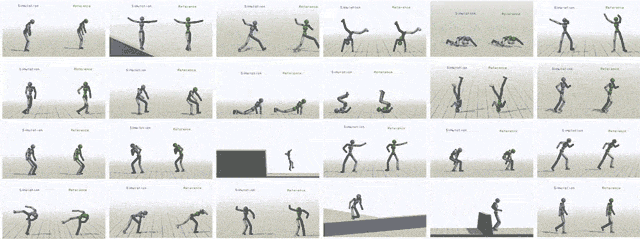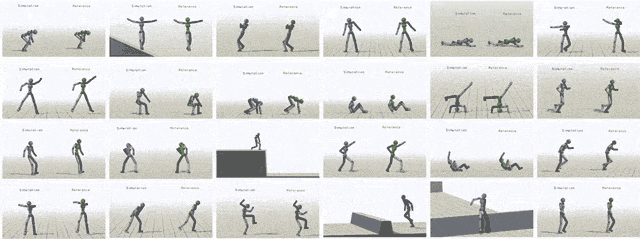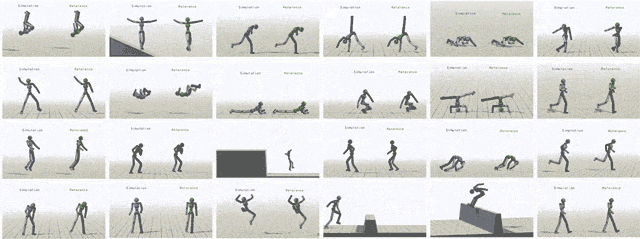
除了模仿動作捕捉片段之外,我們還可以讓虛擬對象執行其他任務。比如提一個隨機放置的目標,或者向某個目標扔球。
我們還訓練的 Atlas 機器人去模仿人類動作捕捉的剪輯。盡管 Atlas 擁有與人不同的形態和質量分布,但它依舊可以復現目標動作。該策略不僅可以模仿參考動作,還可以在模仿過程中抵抗異常擾動。
如果沒有動作捕捉剪輯怎么辦?假設我們要做霸王龍仿真,由于我們無法獲得霸王龍的的動作捕捉影像,我們可以請一個畫家去畫一些動作,然后用使用畫作來訓練策略。
為什么只模仿霸王龍呢?我們還可以試試獅子
還有龍
最終結論是一個簡單的方法卻取得了很好的結果。通過縮小跟蹤誤差,我們就可以訓練處針對不同對象和技巧的策略。我們希望我們的工作可以幫助虛擬對象和機器人習得更多的動態運動技巧。探索通過更常見的資源(如視頻)來學會動作模仿是一項激動人心的工作。這樣我們就可以克服一些沒法進行動作捕捉的場景,比如針對某些動物或雜亂的環境動作捕捉很難實現。
-
機器人
+關注
關注
211文章
28437瀏覽量
207175 -
人工智能
+關注
關注
1791文章
47294瀏覽量
238578 -
計算機圖形
+關注
關注
0文章
11瀏覽量
6528
原文標題:學界 | 伯克利 DeepMimic:虛擬特技演員的基本修養
文章出處:【微信號:CAAI-1981,微信公眾號:中國人工智能學會】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
深度強化學習實戰
將深度學習和強化學習相結合的深度強化學習DRL
簡單隨機搜索:無模型強化學習的高效途徑

什么是強化學習?純強化學習有意義嗎?強化學習有什么的致命缺陷?

谷歌推出新的基于Tensorflow的強化學習框架,稱為Dopamine
機器學習中的無模型強化學習算法及研究綜述

模型化深度強化學習應用研究綜述

基于深度強化學習的路口單交叉信號控制
虛擬乒乓球手的強化學習模仿訓練方法
強化學習的基礎知識和6種基本算法解釋

什么是強化學習






 工商網監
工商網監
評論