 基于FPGA為實現平臺的低功耗高速解碼器系統
基于FPGA為實現平臺的低功耗高速解碼器系統
針對傳統編解碼算法復雜度高、不易擴展等問題,對自編碼神經網絡前向傳播算法和結構進行了研究,提出了一種以自編碼神經網絡為編解碼算法,以FPGA為實現平臺的低功耗高速解碼器系統。該系統實現了字符的編解碼,同時可被應用于各種多媒體信息的編解碼。通過ModelSim仿真,Xilinx ISE實現后進行硬件實測,對計算精度、資源消耗、計算速度和功耗等進行分析。實驗測試結果表明,所設計的解碼器能夠正確完成數據解碼功能,算法簡潔高效,擴展能力強,系統具有低功耗、速度快等特點,可廣泛應用于各種低功耗、便攜式產品。
0引言
計算機處理多媒體或文字信息的基礎是對相關信息進行編碼和解碼,以利于信息的傳輸、顯示和保護[1]。面對巨大信息量的處理需求,快速高效的編解碼系統能夠有效提高信息處理能力。近年來,隨著神經網絡的發展和應用,利用神經網絡進行數學函數回歸的方案,為信息的編解碼提供了簡單有效的途徑[2]。自編碼神經網絡是一種無監督的人工神經網絡,其利用反向傳播算法訓練使得網絡的輸出值等于輸入值,從而為輸入數據學習到一種特征表示,廣泛應用于圖像壓縮和數據降維等領域[3-4]。自編碼神經網絡輸出等于輸入的特點適合用于數據編碼和解碼,相比于傳統的編解碼方法,如熵編碼[5],該算法更簡潔高效,結構可擴展,實用性更強[3]。
而隨著編解碼器在一些低功耗、便攜式產品中的應用,高速、高精度和低功耗已經成為編解碼器的一種發展趨勢。現場可編程門陣列(Field Programmable Gate Array,FPGA)是一種可編程邏輯器件,用戶可通過硬件描述語言完成硬件電路設計。FPGA內部集成了具有高性能的數字信號處理器和大量存儲資源,可以高效低成本地實現定點運算和數據存儲,因此目前FPGA是一種理想的編解碼器實現平臺[5-6]。FPGA中各個硬件模塊并行執行,可將計算量大的算法映射到FPGA中實現硬件加速。有學者嘗試采用FPGA作為神經網絡的實現平臺,并取得了優異的性能,尤以速度和功耗突出[7-8]。綜上所述,基于自編碼神經網絡,以FPGA為實現平臺的編解碼系統,具有靈活性高、高速、低功耗等特點,可廣泛應用于各種低功耗、便攜式應用中。
本文通過分析自編碼神經網絡的結構和特點,提出了一種用于數據解碼的硬件實現架構。根據網絡計算過程中包含的運算和神經元間的并行性特點,結合FPGA高并行、低功耗和高速數據處理的優勢,將自編碼神經網絡的解碼部分映射到FPGA中。該架構具有速度快、功耗低等特點,除文中論述的文字信息解碼外,該架構具備擴展到圖像編解碼的可能性。
1自編碼神經網絡
人工神經網絡是基于生物神經網絡的基本原理,通過模擬人腦神經系統的結構和功能而建立的一個數學模型,該模型擁有以任意精度逼近一個離散值、實數值或者目標函數的功能[9-10]。自編碼神經網絡是一種無監督的人工神經網絡,其采用反向傳播算法,通過學習試圖使得網絡的輸出值等于輸入值,從而為輸入數據學習到一種特征表示[3-4]。
自編碼神經網絡模型是一種對稱結構,中間為隱含層,輸入輸出層神經元節點數相等且通過訓練使得網絡輸出值和輸入值相等。如圖1所示為自編碼神經網絡的結構圖,輸入層和輸出層含有m個神經元,隱含層含有n個神經元,輸入層和隱含層下方的“+1”是偏置節點。自編碼神經網絡的輸入層到隱含層構成編碼器,隱含層到輸出層構成解碼器,對自編碼神經網絡的訓練過程就是通過調整編碼器和解碼器中的權值和偏置,使其逼近一個恒等函數,從而使得網絡輸出值等于輸入值,這樣網絡隱含層的輸出數據為原始輸入數據的另一種特征表示,即該數據經過自編碼神經網絡的解碼器可以恢復原始的輸入數據[11]。
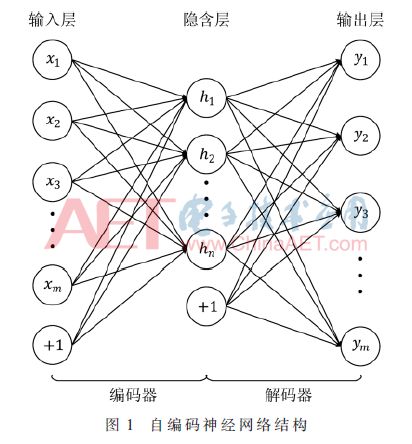
在本文中,利用自編碼神經網絡的編碼器對輸入數據進行編碼,所得到隱含層的輸出數據稱為原始數據的編碼;該編碼數據經過自編碼神經網絡的解碼器實現數據解碼,從而恢復原始輸入數據。下面參照圖1所示的自編碼神經網絡結構,介紹自編碼神經網絡的前向計算過程,首先計算隱含層n個神經元的輸出如式(1):
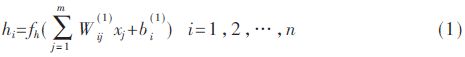
輸出層m個神經元的輸出如式(2):

通過對網絡前向計算過程式(1)和式(2)的分析可以看出:自編碼神經網絡對信息的處理為從輸入層開始,經過隱含層直到輸出層輸出為止,每一層各個神經元之間的計算具有獨立性和并行性;式(1)和式(2)的計算包括乘加運算和激勵函數運算,且兩者按照順序依次進行。
2FPGA設計方案
本章對基于FPGA的硬件解碼系統的設計需求進行分析,介紹整個系統的硬件架構設計、系統工作原理,最后對設計中的網絡計算模塊進行詳細介紹。
2.1系統分析
本文在FPGA中設計實現圖1所示自編碼神經網絡的解碼器部分,從而實現數據解碼功能。在軟件端對自編碼神經網絡進行訓練,得到網絡模型后將對現今最通用的單字節編碼ASCII碼歸一化后的數據輸入至自編碼神經網絡的編碼器以獲得編碼數據,最后將編碼數據送至FPGA端實現數據解碼以恢復原始輸入的ASCII碼。
通過對自編碼神經網絡前向計算的分析,其計算過程中包括乘加運算和激勵函數運算,網絡每層中各個神經元之間的計算具有獨立性和并行性。而對編碼數據進行解碼操作的過程中,要求所設計的硬件系統具有實時性特點。FPGA作為一個分布式并行處理系統,其內部包含大量邏輯單元和計算單元,且具有可編程、速度快、靈活性高、易配置、設計周期短等特點,因此本文選用FPGA作為所設計數據解碼器的硬件實現平臺。
所設計的解碼器為圖1所示自編碼神經網絡的隱含層到輸出層部分,其所包含的權值參數有n×m個,偏置參數有m個,n和m分別表示網絡隱含層和輸出層神經元的個數。由于實現解碼功能僅需要網絡的前向計算,因此網絡的權值和偏置為固定值,所以在設計中可利用FPGA內部資源對網絡權值和偏置進行存儲并以固定值的形式參與網絡運算。
解碼器一次完整的解碼過程可簡述為:輸入數據→解碼計算→輸出結果。在實際應用中往往包含有多組編碼數據,因此設計中將編碼數據存儲在外部存儲器中以供FPGA讀取。SD存儲卡是一種基于半導體快閃記憶器的新一代記憶設備,由于它具有體積小、數據傳輸快、可熱插拔等優良特性,被廣泛應用于便攜式設備中[13]。因此本設計選擇使用SD卡來存儲編碼數據。SD卡讀操作為每次讀取一個扇區的數據,而網絡計算模塊的輸入數據的個數與圖1所示隱含層神經元個數相同,兩個數據量并不匹配。另外,SD卡讀數據操作和網絡計算為異步關系,因此本設計中加入FIFO模塊,作為SD卡讀數據模塊和網絡計算模塊兩個異步模塊之間的數據緩存器,這樣的設計也易于擴展到其他不同神經元數量的網絡結構。
另外,為了便于人為控制對多組編碼數據進行解碼,系統設計中利用按鍵來產生一次解碼操作的起始信號。本設計是以ASCII碼的編碼和解碼對系統進行測試,因此設計中采用專門顯示字母、數字和符號等的工業字符型液晶LCD1602顯示解碼結果。最后為了增加FPGA硬件系統穩定性,減少系統時鐘的抖動和傾斜,設計中增加混合模式時鐘管理器(MMCM),用于在與輸入時鐘信號有設定的相位和頻率關系的情況下,生成不同的時鐘信號,該信號用于各個模塊工作。
2.2硬件系統架構
基于上述分析,所設計FPGA硬件系統結構如圖2所示。系統外圍模塊包括存儲編碼數據的SD卡,產生差分時鐘信號的晶振,產生復位信號和控制系統工作的按鍵,和顯示網絡計算結果的LCD1602顯示器。FPGA內部包含三大模塊,分別是:數據加載模塊、數據處理模塊和混合模式時鐘管理器。
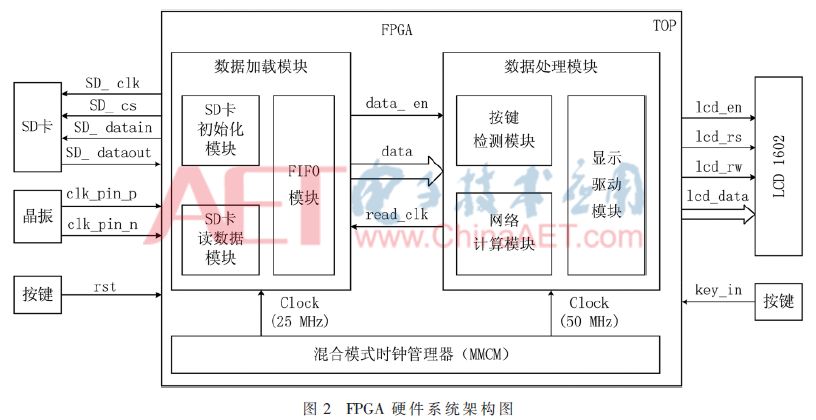
設計中利用SD卡來存儲編碼數據,對SD卡的操作采用簡單的命令/響應協議[13],全部命令由FPGA發起,SD卡接收到命令后返回響應數據。要讀取SD卡中的數據,需要首先完成SD卡的初始化,該系統按照功能分別設計SD卡初始化模塊和SD卡讀數據模塊,其符合FPGA模塊化的設計原則。FIFO模塊作為SD卡和網絡計算模塊之間的數據緩存器,同時又用于異步數據傳輸,因此在設計中采用獨立的讀時鐘和寫時鐘,以用于異步操作。
按鍵檢測模塊不斷讀取外部按鍵輸出信號key_in的值,當檢測到按鍵按下時該模塊產生一個高脈沖信號,該信號將作為一次解碼操作的起始信號。網絡計算模塊按照神經網絡的計算方法對讀入的數據進行計算。顯示驅動模塊設計中采用有限狀態機的方式控制LCD1602的初始化和數據顯示操作,該模塊與網絡計算模塊之間有信號線連接,以實現將計算結果送至顯示驅動模塊,顯示驅動模塊控制LCD1602對計算結果進行顯示。
在圖2所示的硬件架構圖中,混合模式時鐘管理器將外部時鐘分頻產生各個模塊工作所需要的時鐘信號,其通過兩個時鐘線分別與數據加載模塊和數據處理模塊連接,而數據加載模塊和數據處理模塊之間通過data_en、data和read_clk 3個信號連接。
2.3系統工作原理
FPGA的特點是可以實現并行操作,在圖2所示的系統架構圖中,數據加載模塊和數據處理模塊以并行異步的方式工作,下面對其工作原理分別介紹。
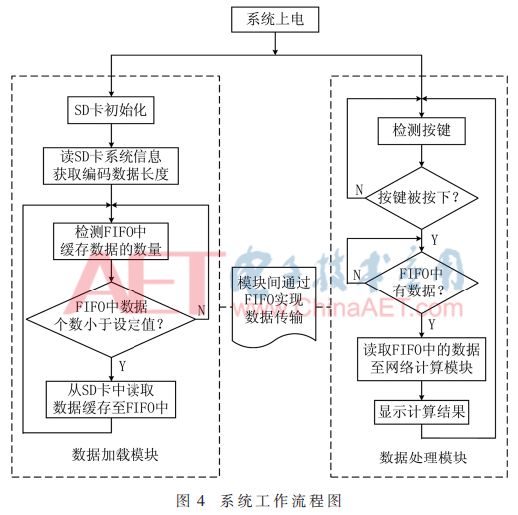
數據加載模塊:系統上電后,數據加載模塊首先控制SD卡初始化模塊對SD卡進行初始化,其初始化操作包含有一系列的命令,在初始化完成后SD卡初始化模塊輸出初始化完成信號。由于SD卡中的編碼數據是在PC端以FAT32文件系統的形式寫入的,因此在對SD卡初始化完成后,數據加載模塊控制SD卡讀數據模塊讀取SD卡中的FAT32文件系統信息,獲取編碼數據的長度,即文件所包含的字節數,該數據將用于控制對編碼數據的讀取。最后,數據加載模塊不斷檢測FIFO中緩存數據的數量,當數據的數量不足設定值時便控制SD卡讀數據模塊將SD卡中的編碼數據讀入FIFO中進行緩存。
數據處理模塊:當按鍵檢測模塊檢測到外部按鍵被按下時會產生一個高脈沖信號,然后數據處理模塊會通過data_en、data和read_clk 3個信號從FIFO中讀取數據到網絡計算模塊進行計算,然后通過顯示驅動模塊控制將計算結果顯示在外部的LCD1602上。數據加載模塊和數據處理模塊之間data_en、data和read_clk 3個信號的時序關系如圖3所示,當data_en為高電平時,代表FIFO中存在有效的數據可以讀取,此時每當read_clk信號的上升沿到達時,從data端口可以讀取一個數據。

如圖4所示為FPGA硬件系統工作流程圖,其中SD卡讀操作和網絡計算之間為異步關系,系統中所加入的FIFO模塊作為SD卡讀數據模塊和網絡計算模塊兩個異步模塊之間的數據緩存器。
2.4網絡計算模塊設計
網絡計算模塊是本設計中的核心模塊,用于實現圖1中的解碼器,將編碼數據和解碼器部分的權值與偏置按式(2)進行乘加運算,并經過激勵函數得到輸出值。
通過對網絡前向計算分析可知其包括乘加運算和激勵函數運算。由于本設計中自編碼神經網絡的輸入是對ASCII碼歸一化后的數據,即原ASCII碼值除以128后的值,因此在FPGA模塊中激勵函數的輸出值需要擴大128倍才是真正的ASCII碼值。由于128=27,在FPGA中乘操作可通過移位實現,因此對計算結果擴大128倍相當于將二進制格式的小數點右移7位。更進一步,直接截取小數點后7位即為計算結果擴大128倍后的ASCII碼值。因此在網絡計算模塊將計算分為3部分:乘加運算、激勵函數運算和截位運算,如圖5所示為一個輸出層神經元的計算結構示意圖,輸出層各個神經元按照圖5所示的計算結構以并行、獨立的方式進行計算。
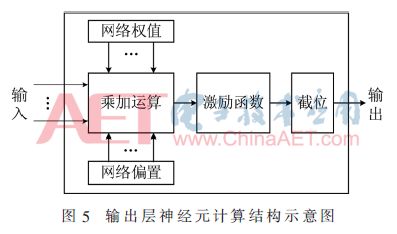
模塊中的乘加運算是將編碼數據、解碼器部分權值和偏置按照式(2)中激勵函數內部的乘加運算規則進行計算。本設計輸出層神經元的激勵函數為hard_sigmoid函數[12],表達式為式(3):
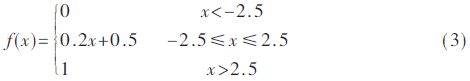
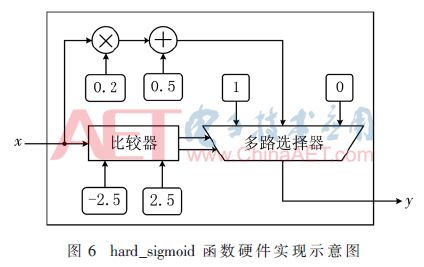
根據定義,hard_sigmoid函數為分段函數,且各段均為線性關系,其非常便于在FPGA系統中實現,即利用條件判斷語句對輸入進行判斷并輸出不同的值,如圖6所示為hard_sigmoid函數硬件實現示意圖。
3系統測試分析
為了測試所設計自編碼神經網絡在FPGA平臺上的實現,本文選擇的網絡結構為輸入層、輸出層含有4個神經元節點,隱含層含有8個神經元節點。所選擇的應用背景為對ASCII碼的編碼和解碼,其中軟件端完成對ASCII碼的編碼,所得到的編碼數據在FPGA端實現解碼。
本實驗測試集由軟件生成,軟件環境下對ASCII碼中非控制字符(碼值為32~127,共96個)做歸一化處理,然后按照隨機組合的方式4個一組輸入至所設計的自編碼神經網絡并獲得隱含層的輸出,將該輸出作為FPGA的測試輸入數據保存在SD卡中。所選擇的FPGA硬件平臺是Xilinx VC707 FPGA開發板,系統開發環境為Xilinx ISE 14.7,仿真環境為ModelSim SE 10.1c,如圖7所示為硬件系統測試圖。

在圖7所示的硬件系統測試圖中,①為SD卡,②為LCD1602顯示屏,③為控制按鍵。系統上電后,通過控制按鍵的按下操作不斷從SD卡中讀取數據,經過網絡計算模塊計算后將結果顯示在LCD1602顯示屏上,每次顯示4個字符,如圖7中LCD1602顯示屏的第二行即為解碼后的4個數據,對應于圖1所示神經網絡的4個輸出。
3.1網絡計算結果分析
神經網絡經過訓練得到一組最優參數,包括網絡權值和偏置。為了在FPGA中實現所設計自編碼神經網絡的解碼器部分,需要獲取對ASCII碼編碼后的數據(神經網絡隱含層的輸出數據)和解碼器部分的網絡權值與偏置。另外由于FPGA僅能對二進制數據識別和計算,因此需要將上述數據轉換為二進制數據。
在FPGA設計中,數據的表示方式與FPGA邏輯資源消耗直接相關的。數據表示位數越多,數據精度越高,邏輯資源的消耗也就越多,因此在FPGA設計中需要權衡FPGA資源消耗和數據精度之間的關系。結合本文的實際應用,同時為了更好地權衡FPGA設計中的精度、資源占用和功耗,本設計采用定點數表示上述數據。
由于在FPGA設計中采用有限位定點數來表示數據時,對原數據進行定點量化的過程中會因為數據的截斷而產生誤差。根據網絡計算模塊的設計,其輸出為計算結果二進制小數點后7位,因此在設計中需要保證這7位數據正確,即與原始輸入數據相比,經過解碼后輸出結果的誤差需要小于2-7,即應小于7.812 5×10-3。本文利用MATLAB下的Fixed Point Toolbox對數據進行量化,然后分析本設計中數據不同的量化位數對計算結果誤差的影響,如圖8所示為定點數表示中小數點的位數和最大誤差之間的關系。
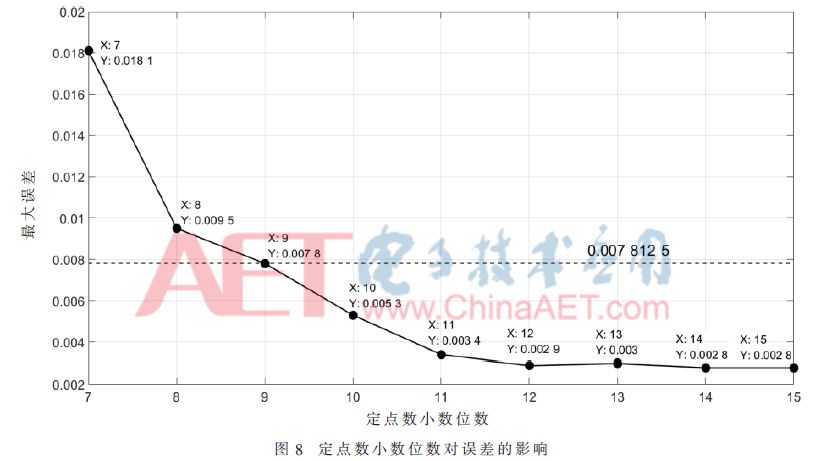
從圖8可以看出:
(1)隨著定點數小數位數的增加,最大誤差值不斷降低,即數據精度越來越高;
(2)定點數小數位變為12位之后,其最大誤差基本保持不變;
(3)定點數小數位為9位時,其最大誤差與7.812 5×10-3基本一致;定點數小數位為10位時,其最大誤差已符合小于7.812 5×10-3的要求。
基于圖8所示的分析結果,本文在對設計中的網絡權值、偏置和編碼數據進行定點數量化時,小數位均設計為10位。進一步通過對網絡的權值、偏置和編碼數據的大小范圍進行分析可以確定其整數位的位數,3種數據的二進制定點數格式如表1所示。
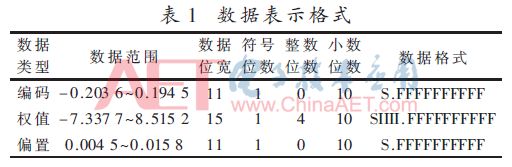
本設計在ModelSim環境下對網絡計算模塊進行仿真,并對模塊輸出的計算結果與軟件中的原始輸入數據進行分析比對,所測試數據中的絕對誤差最大值小于7.812 5×10-3,符合設計中的誤差要求。另外通過硬件實測,所有被編碼后的數據經過FPGA計算后均被正確解碼,并將結果顯示在LCD1602上,即所設計的FPGA硬件系統正確地完成了解碼功能,從而驗證了對所設計網絡計算模塊的誤差分析。
3.2系統性能分析
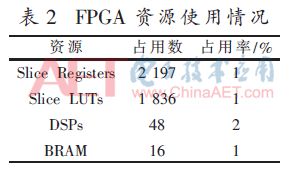
如表2所示為Xilinx ISE對系統工程綜合實現后列出的主要資源占用情況。可以看出,DSP資源占用較大,主要原因是網絡計算模塊中的乘加計算和激勵函數運算均含有定點數乘法和加法操作,因此會占用較多的DSP資源。另外,BRAM資源的占用主要來自于FIFO模塊的實現和網絡計算模塊中網絡權值與偏置的存儲。
如表3所示為FPGA硬件實現數據解碼的速度和軟件解碼速度的比較,軟件解碼是在MATLAB軟件中測試所得,CPU為Intel Core i7,主頻為2.5 GHz。FPGA硬件解碼速度是通過在FPGA中設置計數器,對從讀取解碼器輸入數據到最后輸出結果的時鐘進行計數,然后利用ChipScope工具查看計數值來計算工作時間。表3中的結果顯示,相比于CPU軟件解碼,本文所設計的FPGA硬件解碼器加速了7倍以上。

通過Xilinx ISE自帶的XPower工具可以得到FPGA的運行功耗大致為0.389 W,所設計系統的外圍設備中LCD1602功耗大致為0.693 W,其余外設的功耗可忽略不計,因此整個系統總功耗為1 W左右。而相比之下,Intel Core i7-6500U主頻為2.5 GHz的CPU的功耗可高達65 W,可見本系統功耗僅為通用CPU的1.5%,因此特別適合將本文所設計的基于FPGA的解碼器應用于低功耗便攜式設備中。
4結論
利用神經網絡所具有的輸入輸出之間的映射關系,可以簡單高效地實現數據編碼和解碼。本文根據自編碼神經網絡的結構和特點,將其用于編碼和解碼,并在FPGA中實現自編碼神經網絡的解碼器部分。通過對軟件算法的設計和網絡計算過程的分析,按照功能和需求對FPGA模塊進行設計。利用ModelSim軟件對所設計的各個FPGA模塊進行仿真驗證,利用Xilinx ISE對整個工程進行設計、綜合和實現,并將編程文件下載至Xilinx VC707 FPGA開發板中進行驗證,同時對FPGA系統的資源占用、計算速度和功耗進行評估。通過測試,對于在軟件中經過編碼的數據,在FPGA系統中可以正確解碼。同時相比于通用CPU,該系統計算過程加速了7倍以上,而運行功耗僅為CPU的1.5%,因此具有速度快、功耗低的特點,特別適合將其應用于實時性、低功耗便攜式設備中。
-
FPGA
+關注
關注
1629文章
21736瀏覽量
603387 -
解碼器
+關注
關注
9文章
1143瀏覽量
40742 -
神經網絡
+關注
關注
42文章
4771瀏覽量
100766
原文標題:【學術論文】一種基于FPGA的低功耗高速解碼器設計
文章出處:【微信號:ChinaAET,微信公眾號:電子技術應用ChinaAET】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【FPGA設計實例】基于FPGA的正交解碼器建立
歐勝推出超低功耗音頻編碼解碼器
歐勝超低功耗編碼解碼器WM8904帶有W類耳機和線路驅動器
MAX9526低功耗視頻解碼器

TVP5151超低功耗NTSC/PAL/SECAM視頻解碼器數據表






 工商網監
工商網監
評論