") 語音識別技術(shù)必定會滲透在人們生活的每個角落
語音識別技術(shù)必定會滲透在人們生活的每個角落
一、概述
作為最自然的人機交互方式 ——語音,正在改變?nèi)藗兊纳睿S富多媒體技術(shù)的應(yīng)用。語音識別技術(shù)是語音信號處理的一個重要分支,也是近年來很火的一個研究領(lǐng)域。隨著科技的飛速發(fā)展,語音識別不僅在桌面PC和大型工作站得到了廣泛應(yīng)用,而且在嵌入式系統(tǒng)領(lǐng)域也占有一席之地,如智能家居、語音助手、車載語音識別系統(tǒng)等。相信在不久的將來,語音識別技術(shù)必定會滲透在人們生活的每個角落。
二、語音識別系統(tǒng)的分類
語音識別按照說話人的說話方式可以分為孤立詞(IsolatedWord)識別、連接詞(Connected Word)識別和連續(xù)語音(Continuous Speech)識別。孤立詞識別是指說話人每次只說一個詞或短語,每個詞或短語在詞匯表中都算作一個詞條,一般用在語音電話撥號系統(tǒng)中;連接詞語音識別支持一個小的語法網(wǎng)絡(luò),其內(nèi)部形成一個狀態(tài)機,可以實現(xiàn)簡單的家用電器的控制,而復(fù)雜的連接詞語音識別系統(tǒng)可以用于電話語音查詢、航空訂票等系統(tǒng);連續(xù)語音識別是指對說話人以日常自然的方式發(fā)音,通常特指用于語音錄入的聽寫機。
從識別對象的類型來看,語音識別可以分為特定人(SpeakerDependent)語音識別和非特定人(Speaker Independent)語音識別。特定人是指只針對一個用戶的語音識別,非特定人則可用于不同的用戶。
從識別的詞匯量大小可以分為小詞匯量(詞數(shù)少于100)、中等詞匯量(詞數(shù)100~500)和大詞匯量(詞數(shù)多于500)。
非特定人大詞匯量連續(xù)語音識別是近幾年研究的重點,也是研究的難點。目前的連續(xù)語音識別大多是基于HMM(隱馬爾科夫模型)框架,并將聲學(xué)、語言學(xué)的知識統(tǒng)一引入來改善這個框架,其硬件平臺通常是功能強大的工作站或PC機。
三、語音識別的原理
語音識別就是對麥克風(fēng)輸入的語音信號進行解析和理解,并將其轉(zhuǎn)化為相應(yīng)的文本或命令。
一個完整的語音識別系統(tǒng)主要包括三個部分:
語音特征提取(前端處理部分):目的是濾除各種干擾成分,從語音波形中提取出隨時間變化的能表現(xiàn)語音內(nèi)容的特征矢量序列。
聲學(xué)模型和模式匹配(識別算法):聲學(xué)模型通常由獲得的語音特征通過訓(xùn)練產(chǎn)生,目的是為每個發(fā)音建立發(fā)音模板。在識別時將輸入的語音特征同聲學(xué)模型進行匹配與比較,得到最佳識別結(jié)果。
語義理解(后處理):計算機對識別結(jié)果進行語義、語法分析,明白語音的意義以便做出相應(yīng)的反應(yīng),通常通過語言模型來實現(xiàn)。
語音識別原理如下圖所示:
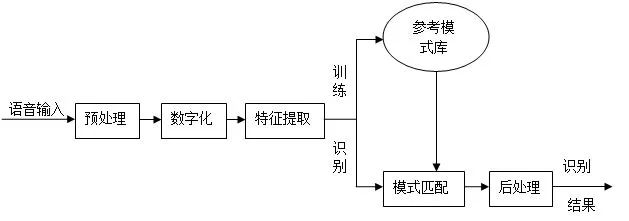
待識別語音經(jīng)話筒轉(zhuǎn)化為電信號后加在識別系統(tǒng)的輸入端,經(jīng)過預(yù)處理,接著進行語音特征提取,用反映語音信號特征的若干參數(shù)來代表原始語音。常用的語音特征包括:線性預(yù)測系數(shù)(LPC)、線性預(yù)測倒譜系數(shù)(LPCC)、Mel頻譜系數(shù)(MFCC)等。
接下來分為兩個階段::訓(xùn)練階段和識別階段。
在訓(xùn)練階段,對用特征參數(shù)形式表示的語音信號進行相應(yīng)處理,獲得表示識別基本單元共性特點的標(biāo)準(zhǔn)數(shù)據(jù),以此構(gòu)成參考模板,將所有能識別的基本單元的參考模板結(jié)合在一起,形成參考模式庫;
在識別階段,將待識別的語音信號經(jīng)特征提取后逐一與參考模式庫中的各個模板按某種原則進行匹配,找出最相似的參考模板所對應(yīng)的發(fā)音,即為識別結(jié)果。
最后進行語音處理,涉及語法分析、語音理解、語義網(wǎng)絡(luò)等。
語音識別過程要根據(jù)模式匹配原則,計算未知語音模式與語音模板庫中的每一個模板的距離測度,從而得到最佳的匹配模式。語音識別所應(yīng)用的模式匹配方法主要有動態(tài)時間規(guī)整(Dynamic Time Warping,DTW),隱馬爾科夫模型(Hidden Markov Model,HMM)和人工神經(jīng)元網(wǎng)絡(luò)(Artificial Neural Networks,ANN)。
四、難題
識別率是衡量語音識別系統(tǒng)性能好壞的一個重要指標(biāo),在實際應(yīng)用中,識別率主要受到以下幾個因素的影響:
對于漢語語音識別,方言或口音會降低識別率;
背景噪聲。公共場所的強噪聲對識別效果影響甚大,即使是在實驗室環(huán)境下,敲擊鍵盤、移動麥克風(fēng)都會成為背景噪聲;
“口語”問題。它既涉及到自然語言理解,又與聲學(xué)有關(guān)。語音識別技術(shù)的最終目的是要讓用戶在“人機對話”時,能夠像進行“人與人對話”一樣自然,而一旦用戶以跟人交談的方式進行語音輸入時,口語的語法不規(guī)范和語序不正常的特點會給語義的分析和理解帶來困難。
此外,識別率還與說話人的性別、說話時間長短等有關(guān)。
實時性是衡量語音識別系統(tǒng)性能好壞的另一指標(biāo)。對于具有高速運算能力的CPU和大容量存儲器的PC而言,基本上能夠滿足實時性的要求;而對于資源有限的嵌入式系統(tǒng)來說,實時性幾乎得不到保證。
-
存儲器
+關(guān)注
關(guān)注
38文章
7521瀏覽量
164087 -
智能家居
+關(guān)注
關(guān)注
1928文章
9590瀏覽量
185786 -
語音識別
+關(guān)注
關(guān)注
38文章
1742瀏覽量
112747
原文標(biāo)題:語音識別之初體驗
文章出處:【微信號:Imgtec,微信公眾號:Imagination Tech】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
音頻信息識別與檢索技術(shù)
優(yōu)秀移動應(yīng)用對人們生活的影響
基于labview的語音識別
LWIP數(shù)據(jù)量大時傳輸必定會終止但又能ping通是怎么回事?
模式識別的關(guān)鍵技術(shù)
語音識別技術(shù)的概念及應(yīng)用前景
2010年必定會成為pcb市場復(fù)蘇的一年
國內(nèi)語音識別技術(shù)上市公司匯總_語音識別技術(shù)現(xiàn)狀_語音識別原理及應(yīng)用
AI語音識別技術(shù)將改變我們的生活
聲紋識別具備怎樣的優(yōu)勢
聲紋識別具備怎樣的優(yōu)勢
美國發(fā)展EDA,華為業(yè)務(wù)必定會受到影響





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論