 GAN對于人工智能的意義是什么?
GAN對于人工智能的意義是什么?
GAN對于人工智能的意義,可以從它名字的三部分說起:Generative Adversarial Networks。為了方便講述,也緬懷過去兩周在某論壇上水掉的時間,我先從Networks講起。
Networks:(深度)神經網絡
自從12年AlexNet橫空出世后,神經網絡儼然已成為現在learning的主流。比起貝葉斯學派的強先驗假設(priori),SVM在核函數(kernel)上的反復鉆研,神經網絡不需要科研者過多關注細節,只需要提供好海量的數據和設置好超參數,便能達到不錯的效果。用武俠小說的方式來說,便是各大門派高手潛心十余載修煉一陽指/九陰真經/麒麟臂等神功,比試時卻發現有一無名小卒內力浩瀚如海,出手雖毫無章法可言,但在內功的加持下,輕松打得眾人抬不起頭。
Deep系列的算法不僅在眾多benchmark上霸據榜首,其衍生應用也給人工智能帶來了一股新的浪潮,例如創作藝術品(Gatys 的 Neural Alorightm for Artistic Style),AlphaGo(CNN估值 + 蒙特卡洛剪枝),高質量的機器翻譯(Attention + seq2seq)等等。這些衍生應用在部分任務上,已經能媲美人類中的專家,讓人不禁浮想強人工智能(strong AI)的到來。然而,縱使深度網絡(Deep Neural Networks)再強大,它也有自己的局限,生成模型上的不盡人意便是其中之一。
Generative(Model):生成模型
機器學習的模型可大體分為兩類,生成模型(Generative Model)和判別模型(Discriminative Model)。判別模型需要輸入變量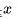 ,通過某種模型來預測
,通過某種模型來預測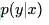 。生成模型是給定某種隱含信息,來隨機產生觀測數據。舉個簡單的例子,
。生成模型是給定某種隱含信息,來隨機產生觀測數據。舉個簡單的例子,
判別模型:給定一張圖,判斷這張圖里的動物是貓還是狗
生成模型:給一系列貓的圖片,生成一張新的貓咪(不在數據集里)
眾所周知的imagenet-1000圖像分類,自動駕駛的圖片語義分割,人體骨架點的預測都屬于判別模型,即給定輸入預測某種特征。實際上12~14年的大部分工作都屬于判別模型,為什么呢,原因之一便是判別模型的損失函數(loss)方便定義。
回到根源,什么是機器學習?一句話來概括就是,在訓練過程中給予回饋,使得結果接近我們的期望。對于分類問題(classification),我們希望loss在接近bound以后,就不要再有變化,所以我們選擇交叉熵(Cross Entropy)作為回饋;在回歸問題(regression)中,我們則希望loss只有在兩者一摸一樣時才保持不變,所以選擇點之間的歐式距離(MSE)作為回饋。損失函數(回饋)的選擇,會明顯影響到訓練結果的質量,是設計模型的重中之重。這五年來,神經網絡的變種已有不下幾百種,但損失函數卻寥寥無幾。例如caffe的官方文檔中,只提供了八種標準損失函數 Caffe | Layer Catalogue。
對于判別模型,損失函數是容易定義的,因為輸出的目標相對簡單。但對于生成模型,損失函數的定義就不是那么容易。例如對于NLP方面的生成語句,雖然有BLEU這一優秀的衡量指標,但由于難以求導,以至于無法放進模型訓練;對于生成貓咪圖片的任務,如果簡單地將損失函數定義為“和已有圖片的歐式距離”,那么結果將是數據庫里圖片的詭異混合,效果慘不忍睹。當我們希望神經網絡畫一只貓的時候,顯然是希望這張圖有一個動物的輪廓、帶質感的毛發、和一個霸氣的眼神,而不是冷冰冰的歐式距離最優解。如何將我們對于貓的期望放到模型中訓練呢?這就是GAN的Adversarial部分解決的問題。
Adversarial:對抗(互懟 )
在generative部分提到了,我們對于貓(生成結果)的期望,往往是一個曖昧不清,難以數學公理化定義的范式。但等一下,說到處理曖昧不清、難以公理化的問題,之前提到的判別任務不也是嗎?比如圖像分類,一堆RGB像素點和最后N類別的概率分布模型,顯然是無法從傳統數學角度定義的。那為何,不把生成模型的回饋部分,交給判別模型呢?這就是Goodfellow天才般的創意--他將機器學習中的兩大類模型,Generative和Discrimitive給緊密地聯合在了一起。
模型一覽
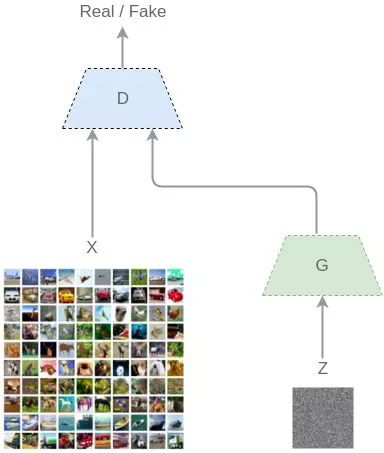
對抗生成網絡主要由生成部分G,和判別部分D組成。訓練過程描述如下

在整個過程中,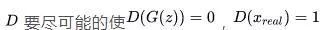 (火眼晶晶,不錯殺也不漏殺)。而
(火眼晶晶,不錯殺也不漏殺)。而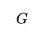 則要使得
則要使得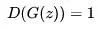 ,即讓生成的圖片盡可能以假亂真。整個訓練過程就像是兩個玩家在相互對抗,也正是這個名字Adversarial的來源。在論文中[1406.2661] Generative Adversarial Networks ,Goodfellow從理論上證明了該算法的收斂性,以及在模型收斂時,生成數據具有和真實數據相同的分布(保證了模型效果)。
,即讓生成的圖片盡可能以假亂真。整個訓練過程就像是兩個玩家在相互對抗,也正是這個名字Adversarial的來源。在論文中[1406.2661] Generative Adversarial Networks ,Goodfellow從理論上證明了該算法的收斂性,以及在模型收斂時,生成數據具有和真實數據相同的分布(保證了模型效果)。
從研究角度,GAN給眾多生成模型提供了一種新的訓練思路,催生了許多后續作品。例如根據自己喜好定制二次元妹子(逃),根據文字生成對應描述圖片(Newmu/dcgan_code, hanzhanggit/StackGAN),甚至利用標簽生成3D宜家家居模型(zck119/3dgan-release),這些作品的效果無一不令人驚嘆。同時,難人可貴的是這篇論文有很強的數學論證,不同于前幾年的套模型的結果說話,而是從理論上保證了模型的可靠性。雖然目前訓練還時常碰到困難,后續已有更新工作改善該問題(WGAN, Loss Sensetive GAN, Least Square GAN),相信終有一日能克服。
從通用人工智能高層次來看,這個模型率先使用神經網絡來指導神經網絡,頗有一種奇妙的美感:仿佛是在辯日的兩小兒一樣,一開始兩者都是懵懂的幼兒,但通過觀察周圍,相互討論,逐漸進化出了對外界的認知。 這不正是吾等所期望的終極智能么 -- 機器的知識來源不再局限于人類,而是可以彼此之間相互交流相互學習。也難怪Yann Lecun贊嘆GAN是機器學習近十年來最有意思的想法
未來智能實驗室是人工智能學家與科學院相關機構聯合成立的人工智能,互聯網和腦科學交叉研究機構。
未來智能實驗室的主要工作包括:建立AI智能系統智商評測體系,開展世界人工智能智商評測;開展互聯網(城市)云腦研究計劃,構建互聯網(城市)云腦技術和企業圖譜,為提升企業,行業與城市的智能水平服務。
-
人工智能
+關注
關注
1792文章
47446瀏覽量
239072 -
GaN
+關注
關注
19文章
1948瀏覽量
73735
原文標題:GAN 的發展對于研究通用人工智能有什么意義?
文章出處:【微信號:AItists,微信公眾號:人工智能學家】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論