") NVIDIA Volta GPU中內(nèi)置的Tensor Core GPU架構(gòu)是NVIDIA深度學(xué)習(xí)平臺(tái)的巨大進(jìn)步
NVIDIA Volta GPU中內(nèi)置的Tensor Core GPU架構(gòu)是NVIDIA深度學(xué)習(xí)平臺(tái)的巨大進(jìn)步
基于深度學(xué)習(xí)的人工智能如今能夠解決一度認(rèn)為不可能解決的問題,例如計(jì)算機(jī)理解自然語言并以自然語言對(duì)話、自動(dòng)駕駛等。深度學(xué)習(xí)在解決諸多挑戰(zhàn)時(shí)都頗有成效。受此激發(fā),算法的復(fù)雜性也呈指數(shù)級(jí)增長,進(jìn)而也引發(fā)了對(duì)更快計(jì)算速度的需求。NVIDIA設(shè)計(jì)的Volta Tensor Core架構(gòu)即可滿足這些需求。
NVIDIA以及許多其他公司和研究人員一直致力于開發(fā)計(jì)算硬件和軟件平臺(tái),以滿足這一需求。例如,谷歌創(chuàng)建了TPU(tensor processing unit)加速器,該加速器目前支持運(yùn)行有限數(shù)量的神經(jīng)網(wǎng)絡(luò),并表現(xiàn)出了良好的性能。
我們將為大家分享近期的一些進(jìn)展,這些進(jìn)展為GPU社群帶來了巨大的性能提升。我們已經(jīng)實(shí)現(xiàn)了單芯片和單服務(wù)器ResNet-50性能的新紀(jì)錄。近期,fast.ai公司還宣布在單一云實(shí)例上實(shí)現(xiàn)了創(chuàng)紀(jì)錄的性能。
我們的結(jié)果表明:
在訓(xùn)練ResNet-50時(shí),單一V100 Tensor Core GPU可達(dá)到1075張圖像/秒,與前一代Pascal GPU相比,性能提升了4倍。
基于8個(gè)Tensor Core V100的單臺(tái)DGX-1服務(wù)器在同樣的系統(tǒng)上實(shí)現(xiàn)了7850張圖像/秒,幾乎是一年前(4200張圖像/秒)的兩倍。
基于8個(gè)Tensor Core V100的單一AWS P3云實(shí)例可在不到三個(gè)小時(shí)的時(shí)間內(nèi)訓(xùn)練ResNet-50,比TPU實(shí)例快3倍。

圖1. Volta Tensor Core GPU在ResNet-50中實(shí)現(xiàn)創(chuàng)紀(jì)錄的速度(AWS P3.16xlarge實(shí)例包含8個(gè)Tesla V100 GPU)。
NVIDIA GPU基于多樣化算法的大規(guī)模并行處理性能使其自然而然成為了深度學(xué)習(xí)的理想之選。但我們并沒有停滯于此。利用我們多年的經(jīng)驗(yàn)以及與全球各地AI研究人員的密切合作,我們創(chuàng)建了針對(duì)多種深度學(xué)習(xí)模式進(jìn)行了優(yōu)化的新架構(gòu)——NVIDIA Tensor Core GPU。
將NVLink高速互聯(lián)與所有當(dāng)前框架內(nèi)的深度優(yōu)化相結(jié)合,我們實(shí)現(xiàn)了領(lǐng)先的性能。NVIDIA CUDA GPU的可編程性可確保多樣化的現(xiàn)代網(wǎng)絡(luò)性能,同時(shí)提供了一個(gè)平臺(tái)以助力新興框架和未來深度網(wǎng)絡(luò)領(lǐng)域的創(chuàng)新。
創(chuàng)下單一處理器速度紀(jì)錄
NVIDIA Volta GPU中內(nèi)置的Tensor Core GPU架構(gòu)是NVIDIA深度學(xué)習(xí)平臺(tái)的巨大進(jìn)步。這一新硬件加速了矩陣乘法與卷積的計(jì)算,這也是訓(xùn)練神經(jīng)網(wǎng)絡(luò)時(shí)的計(jì)算操作的重頭。
NVIDIA Tensor Core GPU架構(gòu)使我們能夠同時(shí)提供比單一功能的ASIC更高的性能,但可針對(duì)不同的工作負(fù)載進(jìn)行編程。例如,每個(gè)Tesla V100 Tensor Core GPU可為深度學(xué)習(xí)提供125 teraflops的性能,而谷歌的TPU芯片為45 teraflops。“Cloud TPU”中的四個(gè)TPU芯片可達(dá)到180 teraflops的性能;相比之下,四個(gè)V100芯片能實(shí)現(xiàn)500 teraflops的性能。
NVIDIA的CUDA平臺(tái)使每個(gè)深度學(xué)習(xí)框架都能充分利用Tensor Core GPU,加速擴(kuò)展神經(jīng)網(wǎng)絡(luò)類型,如CNN、RNN、GAN、RL,以及每年涌現(xiàn)的數(shù)千種變體。
讓我們深入研究一下Tensor Core架構(gòu),以了解其獨(dú)特功能。圖2顯示了Tensor Core在精度較低的FP16中存儲(chǔ)張量,而使用更高精度FP32進(jìn)行計(jì)算,在保持必要精度的同時(shí)實(shí)現(xiàn)吞吐量最大化。
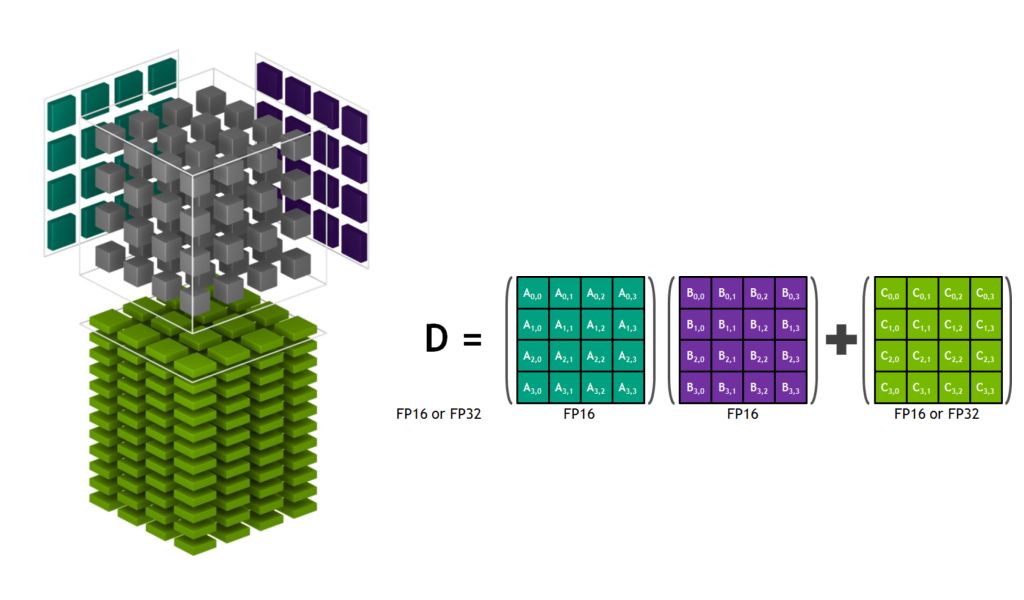
圖2: Volta Tensor Core矩陣乘法與堆積
通過最近的軟件改進(jìn),在獨(dú)立測(cè)試中,如今ResNet-50訓(xùn)練可在單一V100上做到1360張圖像/秒。我們現(xiàn)在正努力將這一訓(xùn)練軟件集成到廣泛采用的框架中,如下所述。
Tensor Core所運(yùn)行的張量應(yīng)位于存儲(chǔ)器的channel-interleaved型數(shù)據(jù)布局(數(shù)量-高度-寬度-通道數(shù),通常稱為NHWC),以實(shí)現(xiàn)最佳性能。訓(xùn)練框架預(yù)期的內(nèi)存布局是通道主序的數(shù)據(jù)布局(數(shù)量-通道數(shù)-寬度-高度,通常稱為NCHW)。因此,cuDNN庫執(zhí)行NCHW和NHWC之間的張量轉(zhuǎn)置操作,如圖3所示。如前所述,由于如今卷積本身如此之快,因此這些轉(zhuǎn)置顯然會(huì)占運(yùn)行時(shí)間的一部分。
為避免此類轉(zhuǎn)置,我們通過直接在NHWC格式中代替RN-50模型圖中的每個(gè)張量來消除轉(zhuǎn)置,這是MXNet框架可支持的特性。此外,我們?yōu)镸XNet添加了優(yōu)化的NHWC實(shí)施,為所有其它非卷積層添加了cuDNN,從而消除了訓(xùn)練期間對(duì)任何張量轉(zhuǎn)置的需求。
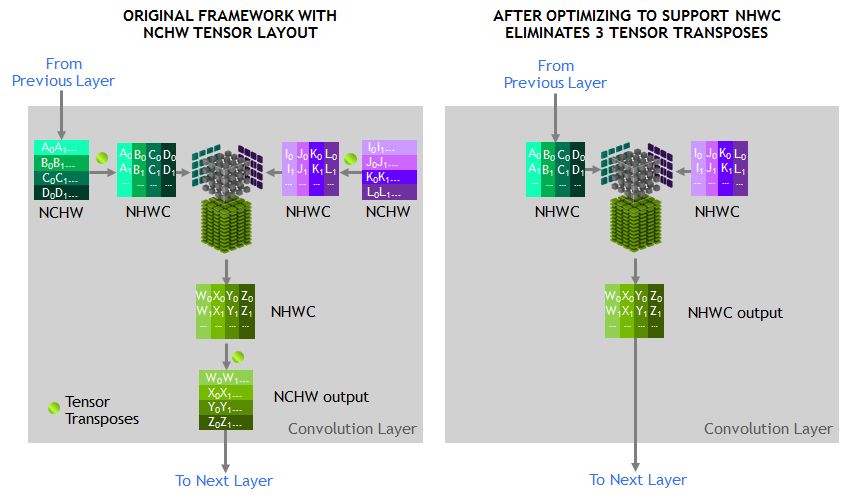
圖3.優(yōu)化的NHWC格式消除了張量轉(zhuǎn)置
Amdahl定律也給了我們另一種優(yōu)化的機(jī)會(huì),該定律預(yù)測(cè)了并行處理的理論加速。由于Tensor Core顯著加快了矩陣乘法和卷積層,因此訓(xùn)練負(fù)載中的其它層在運(yùn)行時(shí)間中的占比就更高了。所以我們確定了這些新的性能瓶頸,并對(duì)其進(jìn)行了優(yōu)化。
如圖4所示,向DRAM以及從DRAM轉(zhuǎn)移數(shù)據(jù)導(dǎo)致許多非卷積層的性能受限。將連續(xù)層融合在一起的做法可利用片上存儲(chǔ)器并避免DRAM流量。例如,我們?cè)贛XNet中創(chuàng)建了一個(gè)圖形優(yōu)化許可來檢測(cè)連續(xù)的ADD和ReLu圖層,并盡可能通過融合實(shí)施將其替換。使用NNVM(神經(jīng)網(wǎng)絡(luò)虛擬機(jī))在MXNet中實(shí)施此類優(yōu)化非常簡單。
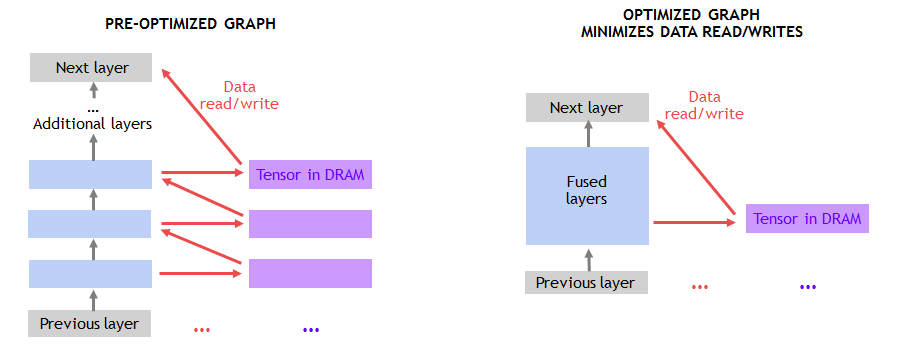
圖4.融合層消除數(shù)據(jù)讀/寫
最后,我們通過為常見卷積類型創(chuàng)建額外的專用內(nèi)核來繼續(xù)優(yōu)化單一卷積。
當(dāng)前,我們針對(duì)多種深度學(xué)習(xí)框架進(jìn)行了此類優(yōu)化,包括TensorFlow、PyTorch和MXNet。基于針對(duì)MXNet的優(yōu)化,利用標(biāo)準(zhǔn)的90次迭代訓(xùn)練進(jìn)度,我們?cè)谝慌_(tái)Tensor Core V100上實(shí)現(xiàn)了1075張圖像/秒,同時(shí)達(dá)到了與單精度訓(xùn)練相同的Top-1分類精度(超過75%)。這為我們留下了進(jìn)一步提升的巨大空間,因?yàn)槲覀兛稍讵?dú)立測(cè)試中做到1360張圖像/秒。這些性能提升在NGC(NVIDIA GPU Cloud)的NVIDIA優(yōu)化深度學(xué)習(xí)框架容器中即可獲得。
最快的單節(jié)點(diǎn)速度紀(jì)錄
多個(gè)GPU可作為單一節(jié)點(diǎn)運(yùn)行,以實(shí)現(xiàn)更高的吞吐量。但是,擴(kuò)展至可在單一服務(wù)器節(jié)點(diǎn)中協(xié)同工作的多個(gè)GPU,需要GPU之間具有高帶寬/低延遲通信路徑。我們的NVLink高速互聯(lián)結(jié)構(gòu)使我們能夠?qū)⑿阅軘U(kuò)展至單一服務(wù)器中的8個(gè)GPU。如此大規(guī)模加速的服務(wù)器提供了全面的petaflop級(jí)的深度學(xué)習(xí)性能,且可廣泛用于云端和本地部署。
但是,擴(kuò)展至8個(gè)GPU可大大提高訓(xùn)練性能,以至于框架中主機(jī)CPU執(zhí)行的其它工作成為了限制性能的因素。具體而言,為框架中的GPU提供數(shù)據(jù)的管線需要大幅提升性能。
數(shù)據(jù)管線從磁盤讀取編碼的JPEG樣本,對(duì)其進(jìn)行解碼,調(diào)整大小并增強(qiáng)圖像(見圖5)。這些增強(qiáng)操作提高了神經(jīng)網(wǎng)絡(luò)的學(xué)習(xí)能力,從而實(shí)現(xiàn)對(duì)訓(xùn)練模型更高精度的預(yù)測(cè)。鑒于8個(gè)GPU在處理框架的訓(xùn)練部分,這些重要的操作會(huì)限制整體性能。

圖5:圖像解碼和增強(qiáng)的數(shù)據(jù)管線
為解決這一問題,我們開發(fā)了DALI(Data Augmentation Library),這是一個(gè)獨(dú)立于框架的庫,用于將工作從CPU分載至GPU上。如圖6所示,DALI將部分JPEG解碼工作、調(diào)整大小、以及所有其它增強(qiáng)功能一起轉(zhuǎn)移到了GPU中。在GPU上進(jìn)行這些操作要比CPU的執(zhí)行速度快得多,因此可將工作負(fù)載從CPU分載出去。DALI使得CUDA通用并行性能更加突出。消除CPU瓶頸讓我們能夠在單一節(jié)點(diǎn)上保持7850張圖像/秒的性能。
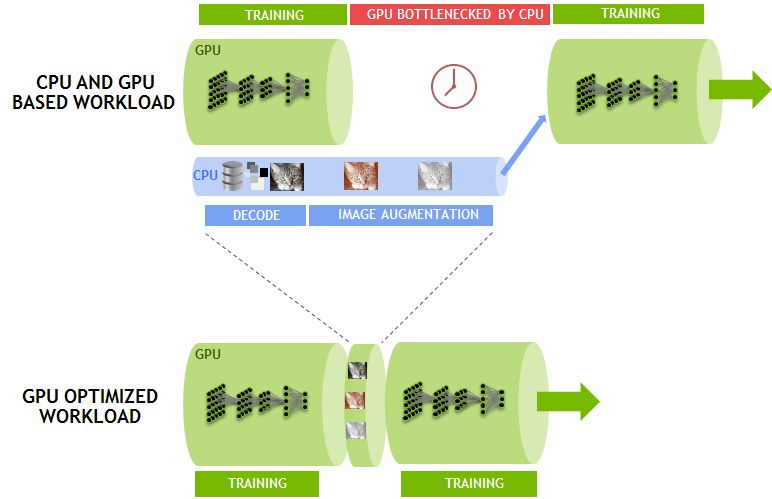
圖6:使用DALI的GPU優(yōu)化工作負(fù)載
NVIDIA正在助力將DALI整合到所有主要的AI框架中。該解決方案還使我們能夠擴(kuò)展至8個(gè)以上GPU的性能,例如最近推出的配備16個(gè)Tesla V100 GPU的NVIDIADGX-2系統(tǒng)。
最快的單一云實(shí)例速度紀(jì)錄
對(duì)于我們的單GPU和單節(jié)點(diǎn)運(yùn)行,我們采用90次迭代的事實(shí)標(biāo)準(zhǔn)來訓(xùn)練ResNet-50,使其單GPU和單節(jié)點(diǎn)運(yùn)行的準(zhǔn)確度超過75%。然而,通過算法創(chuàng)新和超參數(shù)調(diào)優(yōu),訓(xùn)練時(shí)間可進(jìn)一步減少,從而僅需較少次數(shù)的迭代就能實(shí)現(xiàn)準(zhǔn)確性。GPU為AI研究人員提供了可編程性并支持所有深度學(xué)習(xí)框架,使其能夠探索新的算法方法并充分利用現(xiàn)有方法。
fast.ai團(tuán)隊(duì)最近分享了他們的優(yōu)秀成果。他們使用PyTorch,不到90次迭代就實(shí)現(xiàn)了高精度。Jeremy Howard和fast.ai的研究人員將關(guān)鍵算法創(chuàng)新和調(diào)優(yōu)技術(shù)整合到了AWS P3實(shí)例,三小時(shí)內(nèi)在ImageNet上完成了對(duì)ResNet-50的訓(xùn)練,該實(shí)例由8個(gè)V100 Tensor Core GPU提供支持。ResNet-50的運(yùn)行速度比基于TPU的云實(shí)例快三倍(后者需花費(fèi)近9小時(shí)才能完成ResNet-50的訓(xùn)練)。
我們還期望本文中描述的提高吞吐量的方法也能夠應(yīng)用于像fast.ai等的其它研究方式,且能夠幫助他們更快地進(jìn)行聚集。
提供指數(shù)級(jí)的性能提升
自Alex Krizhevsky首次采用2個(gè)GTX 580 GPU在Imagenet競賽中取勝以來,我們?cè)诩铀偕疃葘W(xué)習(xí)方面所取得的進(jìn)展非常顯著。Krizhevsky花了六天的時(shí)間訓(xùn)練出了強(qiáng)大的神經(jīng)網(wǎng)絡(luò),名為AlexNet,這在當(dāng)時(shí)勝過了所有其他圖像識(shí)別方法,開啟了深度學(xué)習(xí)革命。現(xiàn)在用我們最近發(fā)布的DGX-2,在18分鐘內(nèi)就能完成對(duì)AlexNet的訓(xùn)練。圖7顯示了性能在短短5年內(nèi)500倍的提升。
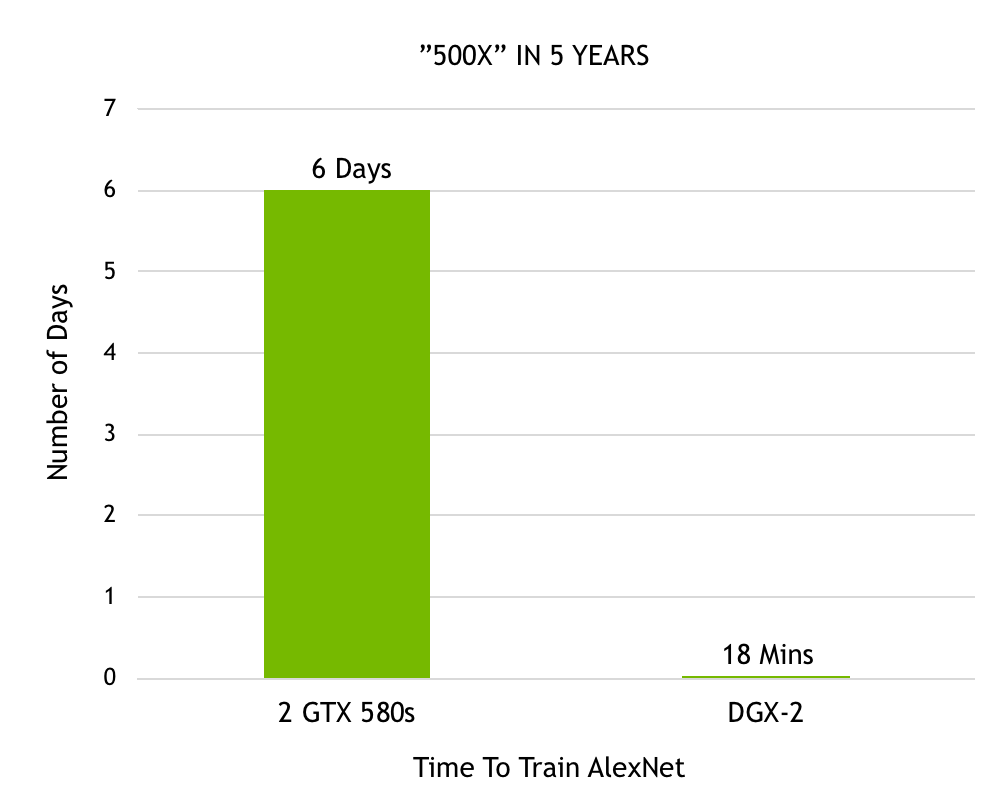
圖7.在Imagnet數(shù)據(jù)集上訓(xùn)練AlexNet所需的時(shí)間
Facebook AI Research(FAIR)分享了他們的語言翻譯模型Fairseq。我們?cè)诓坏揭荒甑臅r(shí)間內(nèi),通過最近發(fā)布的DGX-2,再加之我們眾多的軟件堆棧改進(jìn)(見圖8),在Fairseq上展現(xiàn)了10倍的性能提升。
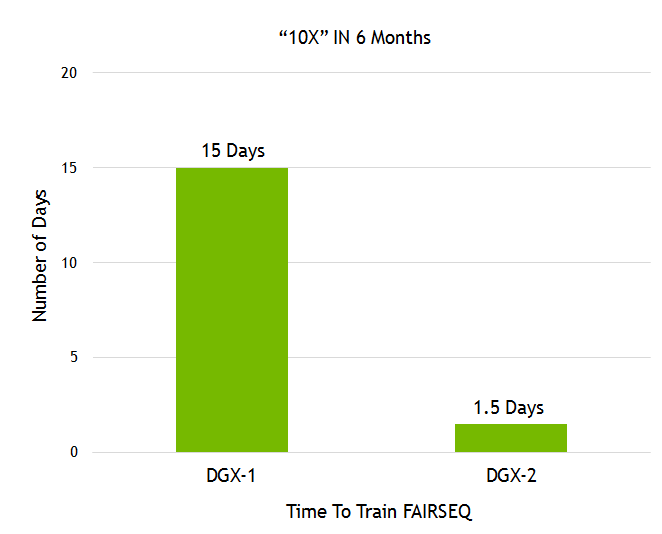
圖8. 訓(xùn)練Facebook Fairseq所需的時(shí)間。
圖像識(shí)別和語言翻譯僅代表研究人員借助AI的力量解決的無數(shù)用例中的一小部分。超過6萬個(gè)使用GPU加速框架的神經(jīng)網(wǎng)絡(luò)項(xiàng)目已發(fā)布至Github。我們GPU的可編程性可為AI社群正在構(gòu)建的各種神經(jīng)網(wǎng)絡(luò)提供加速。快速的改進(jìn)確保了AI研究人員能夠就更為復(fù)雜的神經(jīng)網(wǎng)絡(luò)展開大膽設(shè)想,以借助AI應(yīng)對(duì)巨大挑戰(zhàn)。
這些優(yōu)異的表現(xiàn)來自我們GPU加速計(jì)算的全堆棧優(yōu)化方法。從構(gòu)建最先進(jìn)的深度學(xué)習(xí)加速器到復(fù)雜系統(tǒng)(HBM、COWOS、SXM、NVSwitch、DGX),從先進(jìn)的數(shù)值庫和深度軟件堆棧(cuDNN、NCCL、NGC)、到加速所有深度學(xué)習(xí)框架,NVIDIA對(duì)于AI的承諾為AI開發(fā)者提供了無與倫比的靈活性。
我們將持續(xù)優(yōu)化整個(gè)系列,并持續(xù)提供指數(shù)級(jí)的性能提升,為AI社群提供能夠推動(dòng)深度學(xué)習(xí)創(chuàng)新的工具。
總結(jié)
AI持續(xù)改變著每個(gè)行業(yè),推動(dòng)了無數(shù)用例。理想的AI計(jì)算平臺(tái)需要提供出色的性能,以支持巨大且不斷增長的模型規(guī)模,還需具有可編程性以應(yīng)對(duì)日益多樣化的模型架構(gòu)。
NVIDIA的Volta Tensor Core GPU是世界上最快的AI處理器,只需一顆芯片即可提供125 teraflops的深度學(xué)習(xí)性能。我們很快將把16塊Tesla V100整合成一個(gè)服務(wù)器節(jié)點(diǎn),以創(chuàng)建全球速度最快的計(jì)算服務(wù)器,其可提供2 petaflops的性能。
除了優(yōu)異的性能,GPU 的可編程性以及它在云、服務(wù)器制造商和整個(gè)AI社群中的廣泛使用,將推動(dòng)下一場(chǎng)AI變革。
我們能夠加速以下所有您常用的框架:Caffe2、Chainer、CognitiveToolkit、Kaldi、Keras、Matlab、MXNET、PaddlePaddle、Pytorch和TensorFlow。此外,NVIDIA GPU與迅速擴(kuò)展的CNN、RNN、GAN、RL和混合網(wǎng)絡(luò)架構(gòu)、以及每年新登場(chǎng)的數(shù)千種變體配合運(yùn)行。AI社群已經(jīng)出現(xiàn)了眾多令人驚嘆的應(yīng)用,我們期待繼續(xù)賦力AI的未來。
-
gpu
+關(guān)注
關(guān)注
28文章
4760瀏覽量
129135 -
人工智能
+關(guān)注
關(guān)注
1792文章
47514瀏覽量
239229 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5510瀏覽量
121340
原文標(biāo)題:又創(chuàng)紀(jì)錄!Volta Tensor Core GPU實(shí)現(xiàn)新的AI性能突破
文章出處:【微信號(hào):NVIDIA-Enterprise,微信公眾號(hào):NVIDIA英偉達(dá)企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
NVIDIA火熱招聘深度學(xué)習(xí)/高性能計(jì)算解決方案架構(gòu)師
NVIDIA火熱招聘GPU高性能計(jì)算架構(gòu)師
NVIDIA-SMI:監(jiān)控GPU的絕佳起點(diǎn)
購買哪款Nvidia GPU
NVIDIA網(wǎng)格GPU-PSOD的支持結(jié)構(gòu)
Nvidia GPU風(fēng)扇和電源顯示ERR怎么解決
在Ubuntu上使用Nvidia GPU訓(xùn)練模型
NVIDIA深度學(xué)習(xí)平臺(tái)
NVIDIA領(lǐng)先AMD 將在GTC上大談下一代GPU架構(gòu)Volta顯卡
NVIDIA推出全球最強(qiáng)PC級(jí)GPU 可提供110TFLOP深度學(xué)習(xí)運(yùn)算
NVIDIA安培大核心GPU已集合多個(gè)國內(nèi)廠商技術(shù)
阿里云震旦異構(gòu)計(jì)算加速平臺(tái)基于NVIDIA Tensor Core GPU
火山引擎機(jī)器學(xué)習(xí)平臺(tái)與NVIDIA加深合作
Oracle 云基礎(chǔ)設(shè)施提供新的 NVIDIA GPU 加速計(jì)算實(shí)例

NVIDIA GPU的核心架構(gòu)及架構(gòu)演進(jìn)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論