 機器學習實用指南之機器學習概覽
機器學習實用指南之機器學習概覽
另一種分類機器學習的方法是判斷它們是如何進行歸納推廣的。大多機器學習任務是關于預測的。這意味著給定一定數量的訓練樣本,系統需要能推廣到之前沒見到過的樣本。對訓練數據集有很好的性能還不夠,真正的目標是對新實例預測的性能。
有兩種主要的歸納方法:基于實例學習和基于模型學習。
基于實例學習
也許最簡單的學習形式就是用記憶學習。如果用這種方法做一個垃圾郵件檢測器,只需標記所有和用戶標記的垃圾郵件相同的郵件 —— 這個方法不差,但肯定不是最好的。
不僅能標記和已知的垃圾郵件相同的郵件,你的垃圾郵件過濾器也要能標記類似垃圾郵件的郵件。這就需要測量兩封郵件的相似性。一個(簡單的)相似度測量方法是統計兩封郵件包含的相同單詞的數量。如果一封郵件含有許多垃圾郵件中的詞,就會被標記為垃圾郵件。
這被稱作基于實例學習:系統先用記憶學習案例,然后使用相似度測量推廣到新的例子(圖 1-15)。
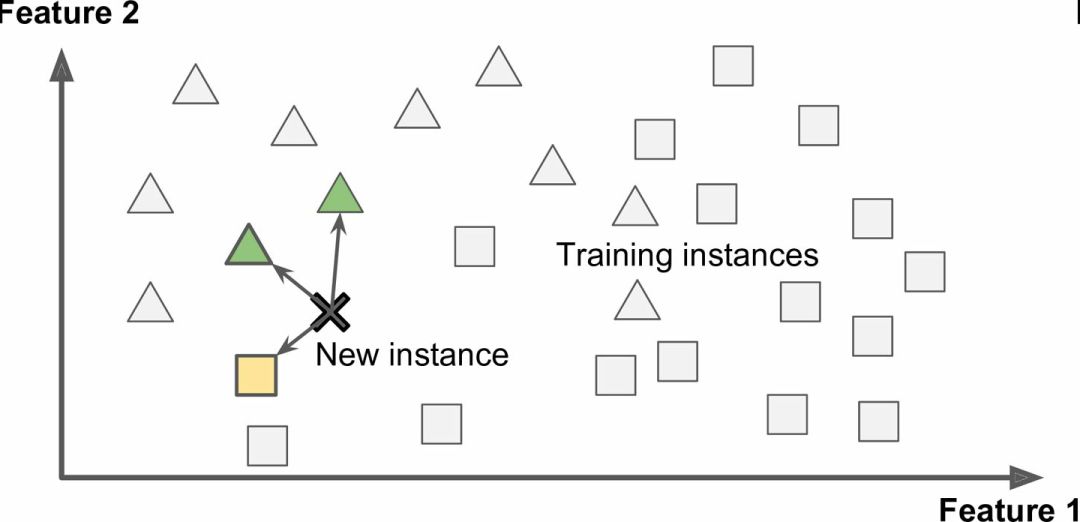
圖 1-15 基于實例學習
基于模型學習
另一種從樣本集進行歸納的方法是建立這些樣本的模型,然后使用這個模型進行預測。這稱作基于模型學習(圖 1-16)。
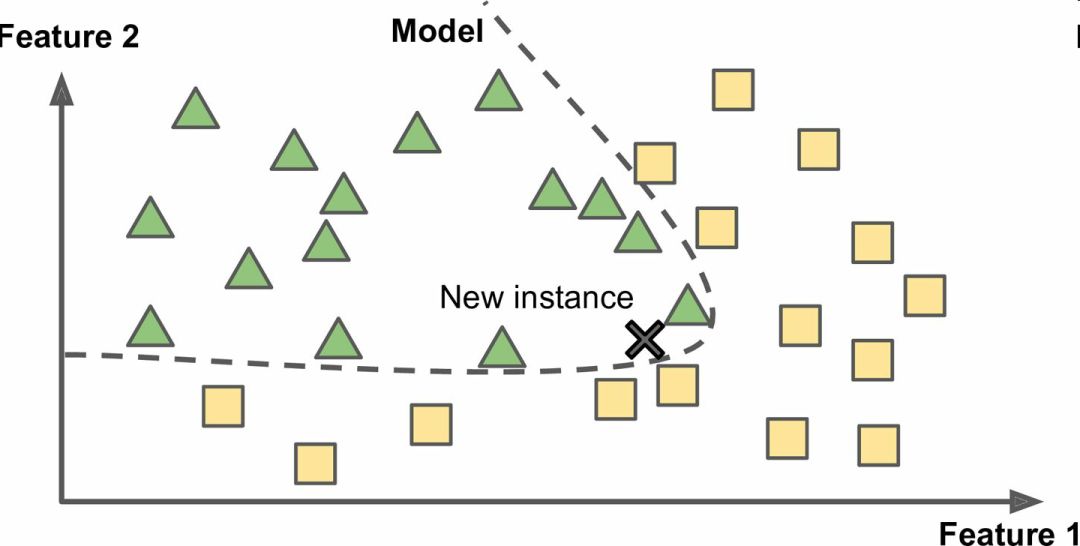
圖 1-16 基于模型學習
例如,你想知道錢是否能讓人快樂,你從 OECD 網站(http://stats.oecd.org/index.aspx?DataSetCode=BLI)下載了 Better Life Index 指數數據,還從 IMF (點擊閱讀原文可跳轉)下載了人均 GDP 數據。表 1-1 展示了摘要。

表 1-1 錢會使人幸福嗎?
用一些國家的數據畫圖(圖 1-17)。
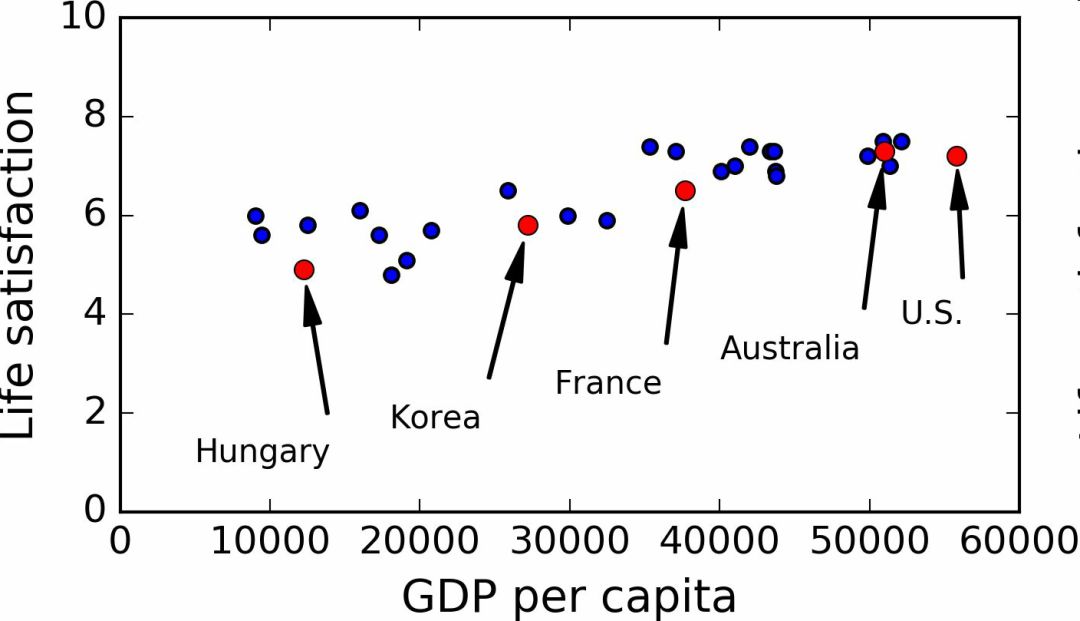
圖 1-17 你看到趨勢了嗎?
確實能看到趨勢!盡管數據有噪聲(即,部分隨機),看起來生活滿意度是隨著人均 GDP 的增長線性提高的。所以,你決定生活滿意度建模為人均 GDP 的線性函數。這一步稱作模型選擇:你選一個生活滿意度的線性模型,只有一個屬性,人均 GDP(公式 1-1)。
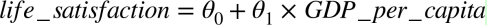
公式 1-1 一個簡單的線性模型
這個模型有兩個參數θ0和θ1。通過調整這兩個參數,你可以使你的模型表示任何線性函數,見圖 1-18。
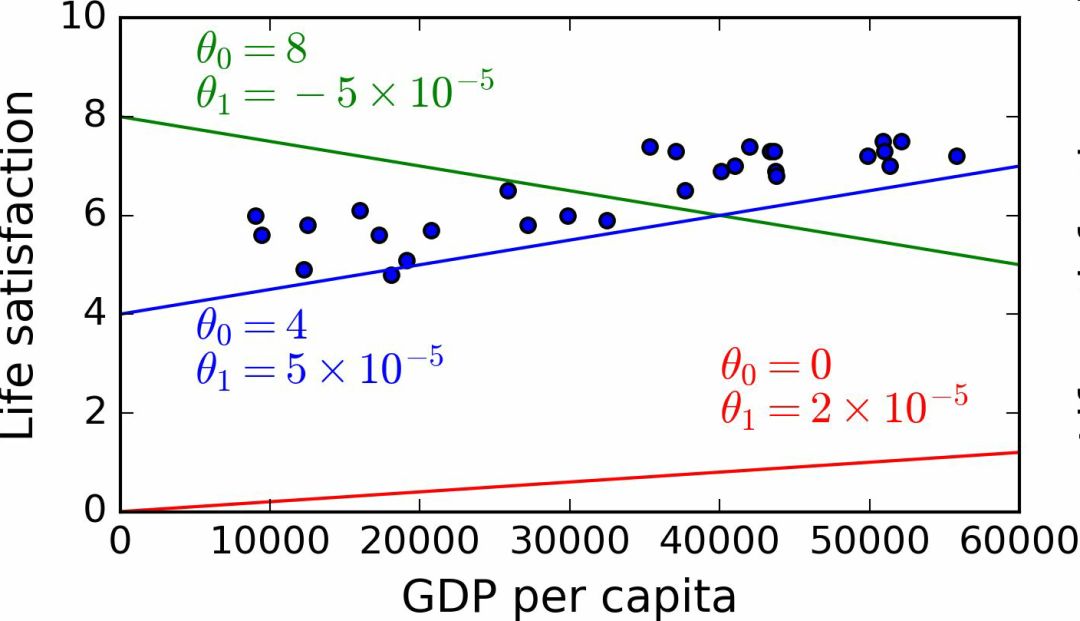
圖 1-18 幾個可能的線性模型
在使用模型之前,你需要確定θ0和θ1。如何能知道哪個值可以使模型的性能最佳呢?要回答這個問題,你需要指定性能的量度。你可以定義一個實用函數(或擬合函數)用來測量模型是否夠好,或者你可以定義一個代價函數來測量模型有多差。對于線性回歸問題,人們一般是用代價函數測量線性模型的預測值和訓練樣本的距離差,目標是使距離差最小。
接下來就是線性回歸算法,你用訓練樣本訓練算法,算法找到使線性模型最擬合數據的參數。這稱作模型訓練。在我們的例子中,算法得到的參數值是θ0=4.85和θ1=4.91×10–5。
現在模型已經最緊密地擬合到訓練數據了,見圖 1-19。
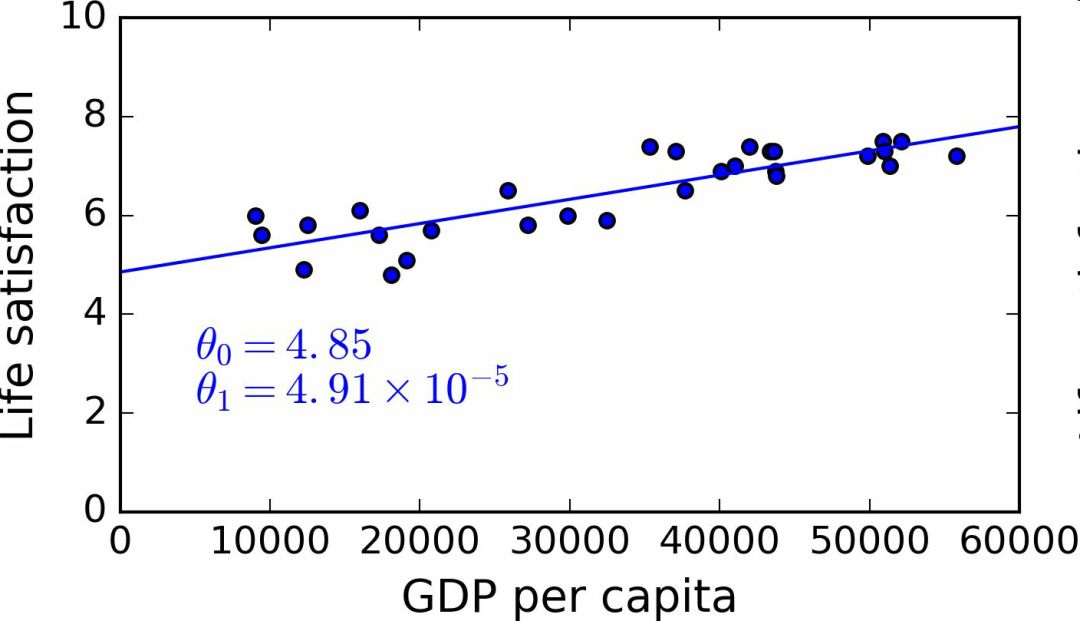
圖 1-19 最佳擬合訓練數據的線性模型
最后,可以準備運行模型進行預測了。例如,假如你想知道塞浦路斯人有多幸福,但 OECD 沒有它的數據。幸運的是,你可以用模型進行預測:查詢塞浦路斯的人均 GDP,為 22587 美元,然后應用模型得到生活滿意度,后者的值在4.85 + 22,587 × 4.91 × 10-5 = 5.96左右。
為了激起你的興趣,案例 1-1 展示了加載數據、準備、創建散點圖的 Python 代碼,然后訓練線性模型并進行預測。
案例 1-1,使用 Scikit-Learn 訓練并運行線性模型。
import matplotlibimport matplotlib.pyplot as pltimport numpy as npimport pandas as pdimport sklearn# 加載數據oecd_bli = pd.read_csv("oecd_bli_2015.csv", thousands=',')gdp_per_capita = pd.read_csv("gdp_per_capita.csv",thousands=',',delimiter=' ', encoding='latin1', na_values="n/a")# 準備數據country_stats = prepare_country_stats(oecd_bli, gdp_per_capita)X = np.c_[country_stats["GDP per capita"]]y = np.c_[country_stats["Life satisfaction"]]# 可視化數據country_stats.plot(kind='scatter', x="GDP per capita", y='Life satisfaction')plt.show()# 選擇線性模型lin_reg_model = sklearn.linear_model.LinearRegression()# 訓練模型lin_reg_model.fit(X, y)# 對塞浦路斯進行預測X_new = [[22587]] # 塞浦路斯的人均GDPprint(lin_reg_model.predict(X_new)) # outputs [[ 5.96242338]]
注解:如果你之前接觸過基于實例學習算法,你會發現斯洛文尼亞的人均 GDP(20732 美元)和塞浦路斯差距很小,OECD 數據上斯洛文尼亞的生活滿意度是 5.7,就可以預測塞浦路斯的生活滿意度也是 5.7。如果放大一下范圍,看一下接下來兩個臨近的國家,你會發現葡萄牙和西班牙的生活滿意度分別是 5.1 和 6.5。對這三個值進行平均得到 5.77,就和基于模型的預測值很接近。這個簡單的算法叫做k近鄰回歸(這個例子中,k=3)。
在前面的代碼中替換線性回歸模型為 K 近鄰模型,只需更換下面一行:
clf = sklearn.linear_model.LinearRegression()
為:
clf = sklearn.neighbors.KNeighborsRegressor(n_neighbors=3)
如果一切順利,你的模型就可以作出好的預測。如果不能,你可能需要使用更多的屬性(就業率、健康、空氣污染等等),獲取更多更好的訓練數據,或選擇一個更好的模型(比如,多項式回歸模型)。
總結一下:
研究數據
選擇模型
用訓練數據進行訓練(即,學習算法搜尋模型參數值,使代價函數最小)
最后,使用模型對新案例進行預測(這稱作推斷),但愿這個模型推廣效果不差
這就是一個典型的機器學習項目。在第 2 章中,你會第一手地接觸一個完整的項目。
我們已經學習了許多關于基礎的內容:你現在知道了機器學習是關于什么的,為什么它這么有用,最常見的機器學習的分類,典型的項目工作流程。現在,讓我們看一看學習中會發生什么錯誤,導致不能做出準確的預測。
機器學習的主要挑戰
簡而言之,因為你的主要任務是選擇一個學習算法并用一些數據進行訓練,會導致錯誤的兩件事就是“錯誤的算法”和“錯誤的數據”。我們從錯誤的數據開始。
訓練數據量不足
要讓一個蹣跚學步的孩子知道什么是蘋果,需要做的就是指著一個蘋果說“蘋果”(可能需要重復這個過程幾次)。現在這個孩子就能認識所有形狀和顏色的蘋果。真是個天才!
機器學習還達不到這個程度;需要大量數據,才能讓多數機器學習算法正常工作。即便對于非常簡單的問題,一般也需要數千的樣本,對于復雜的問題,比如圖像或語音識別,你可能需要數百萬的樣本(除非你能重復使用部分存在的模型)。
數據不合理的有效性
在一篇 2001 年發表的著名論文中,微軟研究員 Michele Banko 和 Eric Brill 展示了不同的機器學習算法,包括非常簡單的算法,一旦有了大量數據進行訓練,在進行去除語言歧義的測試中幾乎有相同的性能(見圖 1-20)。
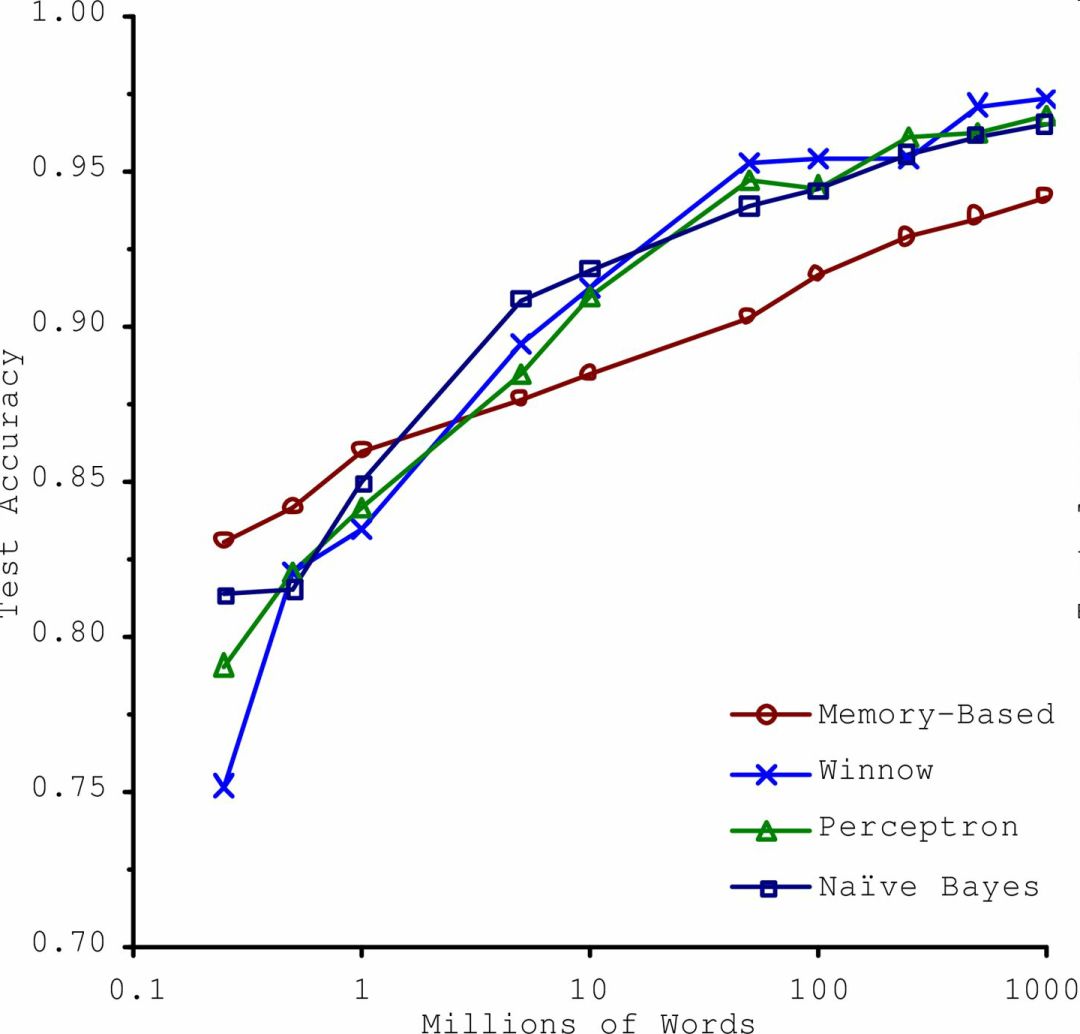
圖 1-20 數據和算法的重要性對比
論文作者說:“結果說明,我們可能需要重新考慮在算法開發 vs 語料庫發展上花費時間和金錢的取舍。”
對于復雜問題,數據比算法更重要的主張在 2009 年由 Norvig 發表的論文《The Unreasonable Effectiveness of Data》得到了進一步的推廣。但是,應該注意到,小型和中型的數據集仍然是非常常見的,獲得額外的訓練數據并不總是輕易和廉價的,所以不要拋棄算法。
沒有代表性的訓練數據
為了更好地進行歸納推廣,讓訓練數據對新數據具有代表性是非常重要的。無論你用的是基于實例學習或基于模型學習,這點都很重要。
例如,我們之前用來訓練線性模型的國家集合不夠具有代表性:缺少了一些國家。圖 1-21 展示了添加這些缺失國家之后的數據。
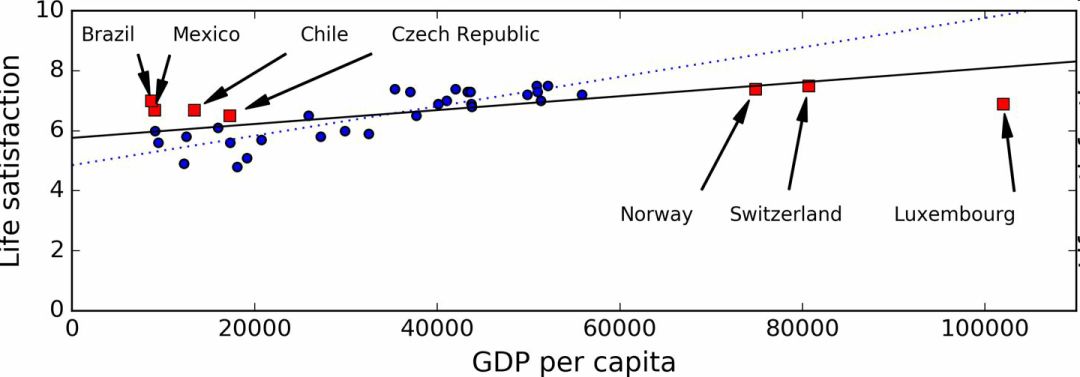
圖 1-21 一個更具代表性的訓練樣本
如果你用這份數據訓練線性模型,得到的是實線,舊模型用虛線表示。可以看到,添加幾個國家不僅可以顯著地改變模型,它還說明如此簡單的線性模型可能永遠不會達到很好的性能。貌似非常富裕的國家沒有中等富裕的國家快樂(事實上,非常富裕的國家看起來更不快樂),相反的,一些貧窮的國家看上去比富裕的國家還幸福。
使用了沒有代表性的數據集,我們訓練了一個不可能得到準確預測的模型,特別是對于非常貧窮和非常富裕的國家。
使用具有代表性的訓練集對于推廣到新案例是非常重要的。但是做起來比說起來要難:如果樣本太小,就會有樣本噪聲(即,會有一定概率包含沒有代表性的數據),但是即使是非常大的樣本也可能沒有代表性,如果取樣方法錯誤的話。這叫做樣本偏差。
一個樣本偏差的著名案例
也許關于樣本偏差最有名的案例發生在 1936 年蘭登和羅斯福的美國大選:《文學文摘》做了一個非常大的民調,給 1000 萬人郵寄了調查信。得到了 240 萬回信,非常有信心地預測蘭登會以 57% 贏得大選。然而,羅斯福贏得了 62% 的選票。錯誤發生在《文學文摘》的取樣方法:
首先,為了獲取發信地址,《文學文摘》使用了電話黃頁、雜志訂閱用戶、俱樂部會員等相似的列表。所有這些列表都偏向于富裕人群,他們都傾向于投票給共和黨(即蘭登)。
第二,只有 25% 的回答了調研。這就又一次引入了樣本偏差,它排除了不關心政治的人、不喜歡《文學文摘》的人,和其它關鍵人群。這種特殊的樣本偏差稱作無應答偏差。
下面是另一個例子:假如你想創建一個能識別放克音樂(Funk Music, 別名騷樂)視頻的系統。建立訓練集的方法之一是在 YouTube 上搜索“放克音樂”,使用搜索到的視頻。但是這樣就假定了 YouTube 的搜索引擎返回的視頻集,是對 YouTube 上的所有放克音樂有代表性的。事實上,搜索結果會偏向于人們歌手(如果你居住在巴西,你會得到許多“funk carioca”視頻,它們和 James Brown 的截然不同)。從另一方面來講,你怎么得到一個大的訓練集呢?
低質量數據
很明顯,如果訓練集中的錯誤、異常值和噪聲(錯誤測量引入的)太多,系統檢測出潛在規律的難度就會變大,性能就會降低。花費時間對訓練數據進行清理是十分重要的。事實上,大多數據科學家的一大部分時間是做清洗工作的。例如:
如果一些實例是明顯的異常值,最好刪掉它們或嘗試手工修改錯誤;
如果一些實例缺少特征(比如,你的 5% 的顧客沒有說明年齡),你必須決定是否忽略這個屬性、忽略這些實例、填入缺失值(比如,年齡中位數),或者訓練一個含有這個特征的模型和一個不含有這個特征的模型,等等。
不相關的特征
俗語說:進來的是垃圾,出去的也是垃圾。你的系統只有在訓練數據包含足夠相關特征、非相關特征不多的情況下,才能進行學習。機器學習項目成功的關鍵之一是用好的特征進行訓練。這個過程稱作特征工程,包括:
特征選擇:在所有存在的特征中選取最有用的特征進行訓練。
特征提取:組合存在的特征,生成一個更有用的特征(如前面看到的,可以使用降維算法)。
收集新數據創建新特征。
現在,我們已經看過了許多壞數據的例子,接下來看幾個壞算法的例子。
過擬合訓練數據
如果你在外國游玩,當地的出租車司機多收了你的錢。你可能會說這個國家所有的出租車司機都是小偷。過度歸納是我們人類經常做的,如果我們不小心,機器也會犯同樣的錯誤。在機器學習中,這稱作過擬合:意思是說,模型在訓練數據上表現很好,但是推廣效果不好。
圖 1-22 展示了一個高階多項式生活滿意度模型,它大大過擬合了訓練數據。即使它比簡單線性模型在訓練數據上表現更好,你會相信它的預測嗎?
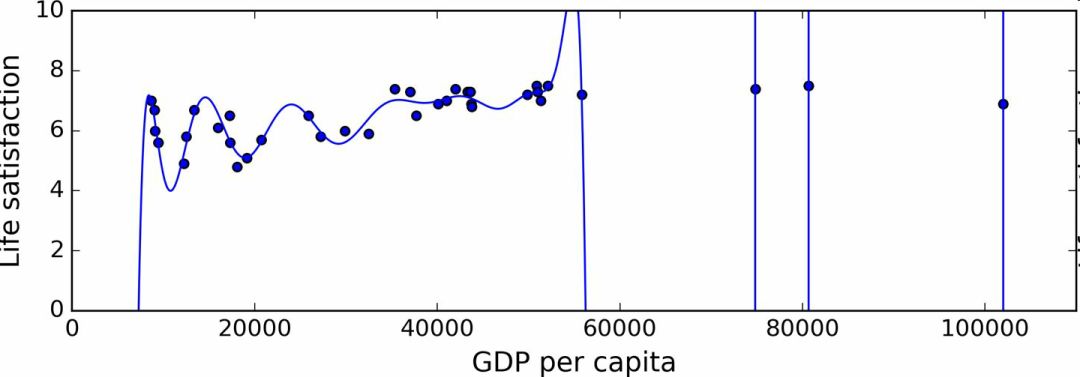
圖 1-22 過擬合訓練數據
復雜的模型,比如深度神經網絡,可以檢測數據中的細微規律,但是如果訓練集有噪聲,或者訓練集太小(太小會引入樣本噪聲),模型就會去檢測噪聲本身的規律。很明顯,這些規律不能推廣到新實例。例如,假如你用更多的屬性訓練生活滿意度模型,包括不包含信息的屬性,比如國家的名字。如此一來,負責的模型可能會檢測出訓練集中名字有 w 字母的國家的生活滿意度大于 7:新西蘭(7.3),挪威(7.4),瑞典(7.2)和瑞士(7.5)。你能相信這個 W-滿意度法則推廣到盧旺達和津巴布韋嗎?很明顯,這個規律只是訓練集數據中偶然出現的,但是模型不能判斷這個規律是真實的、還是噪聲的結果。
警告:過擬合發生在相對于訓練數據的量和噪聲,模型過于復雜的情況。可能的解決方案有:
簡化模型,可以通過選擇一個參數更少的模型(比如使用線性模型,而不是高階多項式模型)、減少訓練數據的屬性數、或限制一下模型
收集更多的訓練數據
減小訓練數據的噪聲(比如,修改數據錯誤和去除異常值)
限定一個模型以讓它更簡單,降低過擬合的風險被稱作正則化(regularization)。例如,我們之前定義的線性模型有兩個參數,θ0和θ1。它給了學習算法兩個自由度以讓模型適應訓練數據:可以調整截距θ0和斜率θ1。如果強制θ1=0,算法就只剩一個自由度,擬合數據就會更為困難:能做的只是將在線下移動,盡可能地靠近訓練實例,結果會在平均值附近。這就是一個非常簡單的模型!如果我們允許算法可以修改θ1,但是只能在一個很小的范圍內修改,算法的自由度就會介于 1 和 2 之間。它要比兩個自由度的模型簡單,比 1 個自由度的模型要復雜。你的目標是在完美擬合數據和保持模型簡單性上找到平衡,確保算法的推廣效果。
圖 1-23 展示了三個模型:虛線表示用缺失部分國家的數據訓練的原始模型,短劃線是我們的第二個用所有國家訓練的模型,實線模型的訓練數據和第一個相同,但進行了正則化限制。你可以看到正則化強制模型有一個小的斜率,它對訓練數據的擬合不是那么好,但是對新樣本的推廣效果好。
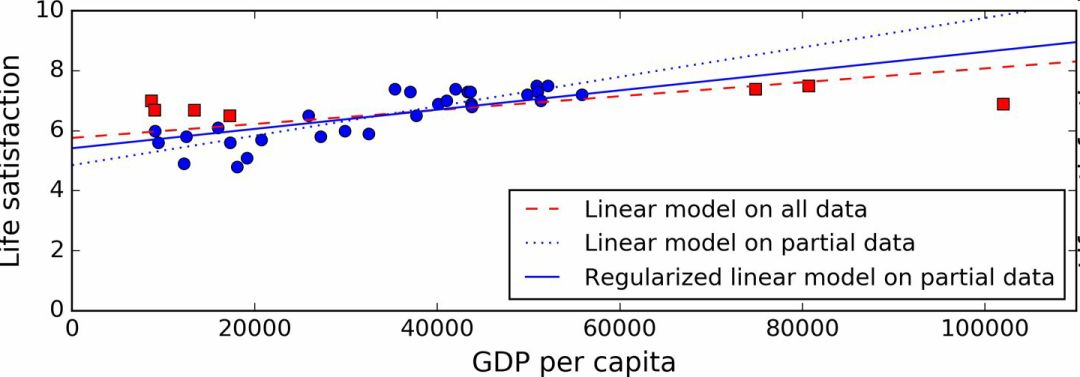
圖 1-23 正則化降低了過度擬合的風險
正則化的度可以用一個超參數(hyperparameter)控制。超參數是一個學習算法的參數(而不是模型的)。這樣,它是不會被學習算法本身影響的,它優于訓練,在訓練中是保持不變的。如果你設定的超參數非常大,就會得到一個幾乎是平的模型(斜率接近于 0);這種學習算法幾乎肯定不會過擬合訓練數據,但是也很難得到一個好的解。調節超參數是創建機器學習算法非常重要的一部分(下一章你會看到一個詳細的例子)。
欠擬合訓練數據
你可能猜到了,欠擬合是和過擬合相對的:當你的模型過于簡單時就會發生。例如,生活滿意度的線性模型傾向于欠擬合;現實要比這個模型復雜的多,所以預測很難準確,即使在訓練樣本上也很難準確。
解決這個問題的選項包括:
選擇一個更強大的模型,帶有更多參數
用更好的特征訓練學習算法(特征工程)
減小對模型的限制(比如,減小正則化超參數)
回顧
現在,你已經知道了很多關于機器學習的知識。然而,學過了這么多概念,你可能會感到有些迷失,所以讓我們退回去,回顧一下重要的:
機器學習是讓機器通過學習數據對某些任務做得更好,而不使用確定的代碼規則。
有許多不同類型的機器學習系統:監督或非監督,批量或在線,基于實例或基于模型,等等。
在機器學習項目中,我們從訓練集中收集數據,然后對學習算法進行訓練。如果算法是基于模型的,就調節一些參數,讓模型擬合到訓練集(即,對訓練集本身作出好的預測),然后希望它對新樣本也能有好預測。如果算法是基于實例的,就是用記憶學習樣本,然后用相似度推廣到新實例。
如果訓練集太小、數據沒有代表性、含有噪聲、或摻有不相關的特征(垃圾進,垃圾出),系統的性能不會好。最后,模型不能太簡單(會發生欠擬合)或太復雜(會發生過擬合)。
還差最后一個主題要學習:訓練完了一個模型,你不只希望將它推廣到新樣本。如果你想評估它,那么還需要作出必要的微調。一起來看一看。
測試和確認
要知道一個模型推廣到新樣本的效果,唯一的辦法就是真正的進行試驗。一種方法是將模型部署到生產環境,觀察它的性能。這么做可以,但是如果模型的性能很差,就會引起用戶抱怨 —— 這不是最好的方法。
更好的選項是將你的數據分成兩個集合:訓練集和測試集。正如它們的名字,用訓練集進行訓練,用測試集進行測試。對新樣本的錯誤率稱作推廣錯誤(或樣本外錯誤),通過模型對測試集的評估,你可以預估這個錯誤。這個值可以告訴你,你的模型對新樣本的性能。
如果訓練錯誤率低(即,你的模型在訓練集上錯誤不多),但是推廣錯誤率高,意味著模型對訓練數據過擬合。
提示:一般使用 80% 的數據進行訓練,保留20%用于測試。
因此,評估一個模型很簡單:只要使用測試集。現在假設你在兩個模型之間猶豫不決(比如一個線性模型和一個多項式模型):如何做決定呢?一種方法是兩個都訓練,,然后比較在測試集上的效果。
現在假設線性模型的效果更好,但是你想做一些正則化以避免過擬合。問題是:如何選擇正則化超參數的值?一種選項是用 100 個不同的超參數訓練100個不同的模型。假設你發現最佳的超參數的推廣錯誤率最低,比如只有 5%。然后就選用這個模型作為生產環境,但是實際中性能不佳,誤差率達到了 15%。發生了什么呢?
答案在于,你在測試集上多次測量了推廣誤差率,調整了模型和超參數,以使模型最適合這個集合。這意味著模型對新數據的性能不會高。
這個問題通常的解決方案是,再保留一個集合,稱作驗證集合。用測試集和多個超參數訓練多個模型,選擇在驗證集上有最佳性能的模型和超參數。當你對模型滿意時,用測試集再做最后一次測試,以得到推廣誤差率的預估。
為了避免“浪費”過多訓練數據在驗證集上,通常的辦法是使用交叉驗證:訓練集分成互補的子集,每個模型用不同的子集訓練,再用剩下的子集驗證。一旦確定模型類型和超參數,最終的模型使用這些超參數和全部的訓練集進行訓練,用測試集得到推廣誤差率。
沒有免費午餐公理
模型是觀察的簡化版本。簡化意味著舍棄無法進行推廣的表面細節。但是,要確定舍棄什么數據、保留什么數據,必須要做假設。例如,線性模型的假設是數據基本上是線性的,實例和模型直線間的距離只是噪音,可以放心忽略。
在一篇 1996 年的著名論文中,David Wolpert 證明,如果完全不對數據做假設,就沒有理由選擇一個模型而不選另一個。這稱作沒有免費午餐(NFL)公理。對于一些數據集,最佳模型是線性模型,而對其它數據集是神經網絡。沒有一個模型可以保證效果更好(如這個公理的名字所示)。確信的唯一方法就是測試所有的模型。因為這是不可能的,實際中就必須要做一些對數據合理的假設,只評估幾個合理的模型。例如,對于簡單任務,你可能是用不同程度的正則化評估線性模型,對于復雜問題,你可能要評估幾個神經網絡模型。
-
機器學習
+關注
關注
66文章
8418瀏覽量
132646
原文標題:【翻譯】Sklearn 與 TensorFlow 機器學習實用指南 —— 第1章 機器學習概覽(下)
文章出處:【微信號:AI_shequ,微信公眾號:人工智能愛好者社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論