 一文詳解深度學習的5 種架構
一文詳解深度學習的5 種架構
連接主義體系結構已存在 70 多年,但新的架構和圖形處理單元 (GPU) 將它們推到了人工智能的前沿。深度學習架構是最近 20 年內誕生的,它顯著增加了神經網絡可以解決的問題的數量和類型。本文將介紹 5 種最流行的深度學習架構:遞歸神經網絡 (RNN)、長短期記憶 (LSTM)/門控遞歸單元 (GRU)、卷積神經網絡 (CNN)、深度信念網絡 (DBN) 和深度疊加網絡 (DSN),然后探討用于深度學習的開源軟件選項。
深度學習不是單個方法,而是一類可用來解決廣泛問題的算法和拓撲結構。深度學習顯然已不是新概念,但深度分層神經網絡和 GPU 的結合使用加速了它們的執行,深度學習正在突飛猛進地發展。大數據也助推了這一發展勢頭。因為深度學習依賴于監督學習算法(這些算法使用示例數據訓練神經網絡并根據成功水平給予獎懲),所以數據越多,構建這些深度學習結構的效果就越好。
深度學習與 GPU 的興起
深度學習由不同拓撲結構的深度網絡組成。神經網絡已存在很長一段時間,但多層網絡(每個層提供一定的功能,比如特征提取)的開發讓它們變得更加實用。增加層數意味著各層之間和層內有更多相互聯系和更多權值。在這里,GPU 可為深度學習帶來助益,使訓練和執行這些深度網絡成為可能(原始處理器在這方面的效率不夠高)。
GPU 在一些關鍵方面與傳統多核處理器不同。首先,一個傳統處理器可能包含 4 - 24 個通用 CPU,但一個 GPU 可能包含 1,000 - 4,000 個專用數據處理核心。
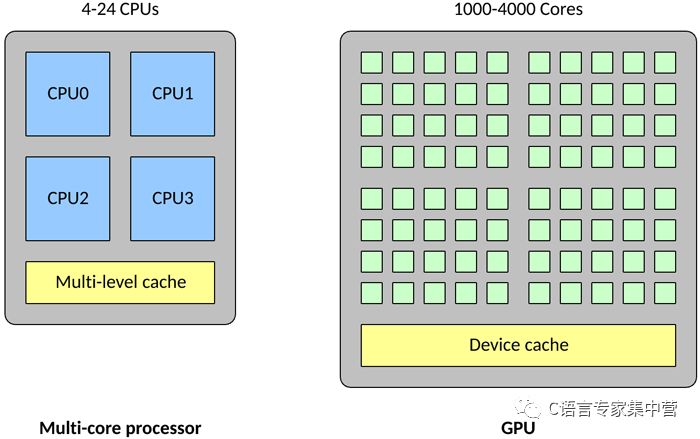
與傳統 CPU 相比,高密度的核心使得 GPU 變得高度并行化(也就是說,它可以一次執行許多次計算)。這使得 GPU 成為大型神經網絡的理想選擇,在這些神經網絡中,可以一次計算許多個神經元(傳統 CPU 可以并行處理的數量要少得多)。GPU 還擅長浮點矢量運算,因為神經元能執行的運算不止是矢量乘法和加法。所有這些特征使得 GPU 上的神經網絡達到所謂的高度并行(也就是完美并行,幾乎不需要花精力來并行化任務)。
深度學習架構
深度學習中使用的架構和算法數量豐富多樣。本節將探討過去 20 年來存在的深度學習架構中的 5 種。顯然,LSTM 和 CNN 是此列表中最古老的兩種方法,但也是各種應用中使用最多的兩種方法。
些架構被應用于廣泛的場景中,但下表僅列出了它們的一些典型應用。
| 架構 | 應用 |
|---|---|
| RNN | 語音識別、手稿識別 |
| LSTM/GRU 網絡 | 自然語言文本壓縮、手稿識別、語音識別、手勢識別、圖像說明 |
| CNN | 圖像識別、視頻分析、自然語言處理 |
| DBN | 圖像識別、信息檢索、自然語言理解、故障預測 |
| DSN | 信息檢索、持續語音識別 |
現在,讓我們了解一下這些架構和用于訓練它們的方法。
遞歸神經網絡
RNN 是一種基礎網絡架構,其他一些深度學習架構是基于它來構建的。典型多層網絡與遞歸網絡之間的主要差別是,遞歸網絡沒有完整的前饋連接,它可能擁有反饋到前幾層(或同一層)的連接。這種反饋使 RNN 能保留對過去的輸入的記憶并按時間為問題建模。
RNN 包含豐富的架構(接下來我們將分析一種名為 LSTM 的流行拓撲結構)。關鍵區別在于網絡中的反饋,這可以在隱藏層、輸出層或二者的某種組合中體現出來。
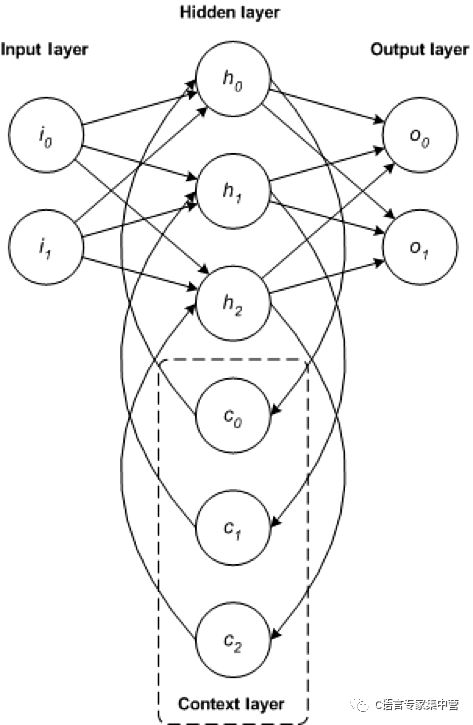
RNN 可以按時間展開并通過標準反向傳播進行訓練,或者使用一種沿時間反向傳播 (BPTT) 的反向傳播變形來訓練。
LSTM/GRU 網絡
LSTM 是 Hochreiter 和 Schimdhuber 于 1997 年共同創建的,最近幾年,作為一種用于各種用途的 RNN 架構,LSTM 變得越來越受歡迎。您可以在每天使用的產品(比如智能手機)中發現 LSTM。IBM 在 IBM Watson?中應用了 LSTM,在對話語音識別上取得了里程碑式的成就。
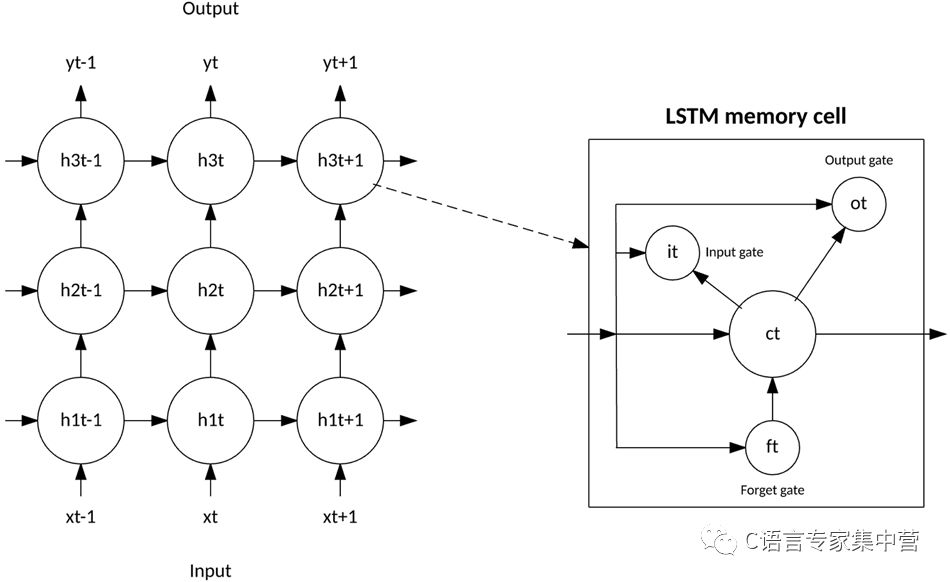
LSTM 脫離了基于典型神經元的神經網絡架構,引入了記憶細胞的概念。記憶細胞可以作為輸入值的函數,短時間或長時間地保留自身的運算值,這使得該細胞能記住重要的信息,而不只是它最后計算的值。
LSTM 記憶細胞包含 3 個控制信息如何流進或流出細胞的門。輸入門控制新信息何時能流入記憶中。遺忘門控制何時遺忘一段現有信息,使細胞能記憶新數據。最后,輸出門控制細胞中包含的信息何時用在來自該細胞的輸出中。記憶細胞還包含控制每個門的權值。訓練算法(通常為 BPTT)基于得到的網絡輸出錯誤來優化這些權值。
2014 年,推出了 LSTM 的一個簡化版本,叫做門控遞歸單元。此模型有兩個門,拋棄了 LSTM 模型中存在的輸出門。對于許多應用,GRU 擁有類似于 LSTM 的性能,但更簡單意味著更少的權值和更快的執行速度。
GRU 包含兩個門:更新門和重置門。更新門指示保留多少以前細胞的內容。重置門定義如何將新輸入與以前的細胞內容合并。GRU 可以通過將重置門設置為 1 并將更新門設置為 0 來模擬標準 RNN。
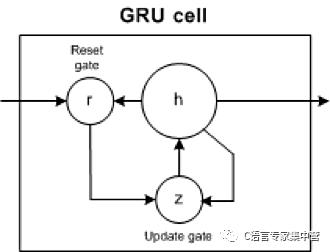
GRU 比 LSTM 更簡單,能更快地訓練,而且執行效率更高。但是,LSTM 更富于表達,有更多的數據,能帶來更好的結果。
卷積神經網絡
CNN 是一種多層神經網絡,該網絡的創作靈感來自動物的視覺皮質。該架構在圖像處理應用中特別有用。第一個 CNN 是由 Yann LeCun 創建的,當時,該架構專注于手稿字符識別,比如郵政編碼解釋。作為一種深度網絡,早期的層主要識別各種特征(比如邊緣),后來的層將這些特征重新組合到輸入的更高級屬性中。
LeNet CNN 架構包含多個層,這些層實現了特征提取,然后實現了分類(參見下圖)。圖像被分成多個接受區,其中注入了隨后可從輸入圖像中提取特征的卷積層。下一步是池化,它可以(通過降采樣)降低提取的特征的維度,同時保留最重要的信息(通常通過最大池化)。然后執行另一個卷積和池化步驟,將結果注入一個完全連接的多層感知器中。此網絡的最終輸出層是一組節點,這些節點標識了圖像的特征(在本例中,每個節點對應一個識別出的數字)。您可以使用反向傳播訓練該網絡。
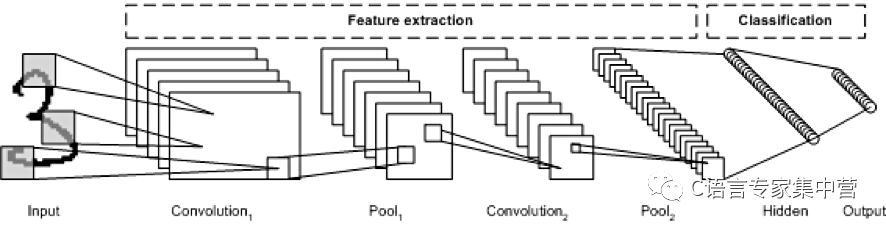
深層處理、卷積、池化和完全連接的分類層的使用,為深度學習神經網絡的各種新應用開啟了一扇門。除了圖像處理之外,CNN 還成功應用到了視頻識別和各種自然語言處理任務中。
人們最近應用 CNN 和 LSTM 來生成圖像和視頻說明系統,使用自然語言總結圖像或視頻內容。CNN 實現了圖像或視頻處理,LSTM 經過訓練可以將 CNN 輸出轉換為自然語言。
深度信念網絡
DBN 是一種典型的網絡架構,但它包含一種新穎的訓練算法。DBN 是一種多層網絡(通常是深度網絡,包含許多隱藏層),其中的每對連接的層都是一個受限玻爾茲曼機 (RBM)。通過這種方式,將 DBN 表示為一些疊加的 RBM。
在 DBN 中,輸入層表示原始感知輸入,每個隱藏層都學習此輸入的抽象表示。輸出層的處理方式與其他層稍有不同,它實現了網絡分類。訓練分兩步進行:無監督預訓練和監督調優。
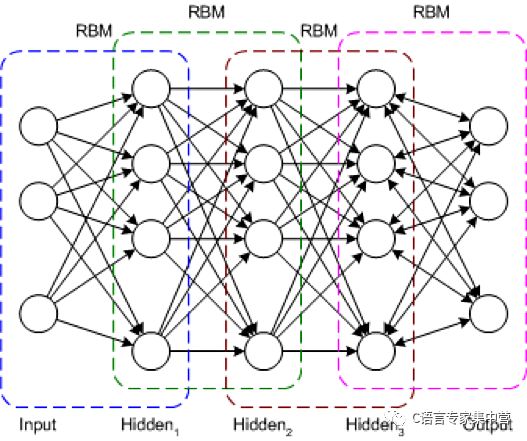
在無監督預訓練過程中,會訓練每個 RBM 來重構它的輸入(例如,第一個 RBM 將輸入層重構到第一個隱藏層)。用類似方式訓練下一個 RBM,但將第一個隱藏層視為輸入(或可視)層,通過使用第一個隱藏層的輸出作為輸入來訓練 RBM。此過程一直持續到完成每一層的預訓練。完成預訓練后,開始進行調優。在此階段,可對輸出節點使用標簽來提供它們的含義(它們在網絡的上下文中表示的含義)。然后使用梯度下降學習或反向傳播來應用整個網絡訓練,從而完成訓練過程。
深度疊加網絡
最后要介紹的一種架構是 DSN,也稱為深凸網絡。DSN 不同于傳統的深度學習框架,因為盡管它包含一個深度網絡,但它實際上是各個網絡的深度集合,每個網絡都有自己的隱藏層。此架構是對一個深度學習問題的一種回應:訓練的復雜性。深度學習架構中的每一層的訓練復雜性都呈指數級增長,所以 DSN 未將訓練視為單一問題,而將它視為單獨訓練問題的集合。
DSN 包含一組模塊,每個模塊都是 DSN 的整體分層結構中的一個子網。在此架構的一個實例中,為 DSN 創建了 3 個模塊。每個模塊都包含一個輸入層、一個隱藏層和一個輸出層。模塊彼此堆疊,一個模塊的輸入包含前一層的輸出和原始輸入矢量。這種分層使整個網絡能學習比單個模塊更復雜的分類。
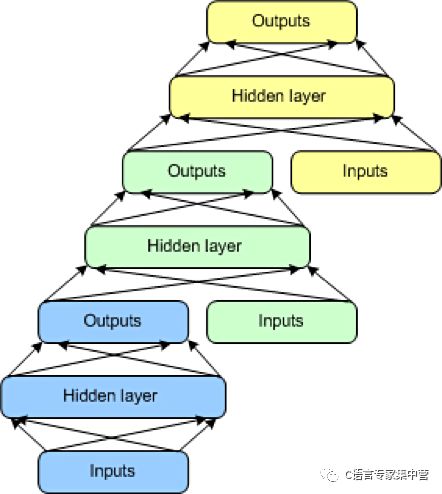
DSN 允許隔離訓練各個模塊,這使得它們能并行訓練,因而具有很高的效率。監督訓練實現為每個模塊上的反向傳播,而不是在整個網絡上的反向傳播。對于許多問題,DSN 表現得都比典型 DBN 更好,這使它們成為了一種流行且高效的網絡架構。
開源框架
這些深度學習架構肯定是可以實現的,但從頭開始可能很耗時,而且也需要時間來優化它們并讓它們變得成熟。幸運的是,可以利用一些開源框架來更輕松地實現和部署深度學習算法。這些框架支持 Python、C/C++ 和 Java?等語言。讓我們看看 3 種最流行的框架和它們的優缺點。
Caffe
Caffe 是最流行的深度學習框架之一。Caffe 最初是在一篇博士論文中發布的,但現在已依據 Berkeley Software Distribution 許可進行發布。Caffe 支持許多深度學習架構,包括 CNN 和 LSTM,但它明顯不支持 RBM 或 DBM(不過即將發布的 Caffe2 將會支持它們)。
圖像分類和其他視覺應用中已采用 Caffe,而且 Caffe 支持通過 NVIDIA CUDA Deep Neural Network 庫實現基于 GPU 的加速。Caffe 支持采用開放多處理 (Open Multi-Processing, OpenMP) 在一個系統集群上并行執行深度學習算法。為了保證性能,Caffe 和 Caffe2 是用 C++ 編寫的,它們還為深度學習的訓練和執行提供了 Python 和 MATLAB 接口。
Deeplearning4j
Deeplearning4j 是一種流行的深度學習框架,它專注于 Java 技術,但包含適用于其他語言的應用編程接口,比如 Scala、Python 和 Clojure。該框架依據 Apache 許可而發布,支持 RBM、DBN、CNN 和 RNN。Deeplearning4j 還包含兼容 Apache Hadoop 和 Spark(大數據處理框架)的分布式并行版本。
人們已應用 Deeplearning4j 來解決眾多問題,包括金融領域中的欺詐檢測、推薦系統、圖像識別或網絡安全(網絡入侵檢測)。該框架集成了 CUDA 來實現 GPU 優化,而且可通過 OpenMP 或 Hadoop 進行分發。
TensorFlow
TensorFlow 是 Google 開發的一個開源庫,是從閉源 DistBelief 衍生而來。可以使用 TensorFlow 訓練和部署各種神經網絡(CNN、RBM、DBN 和 RNN),TensorFlow 是依據 Apache 2.0 許可而發布的。人們已應用 TensorFlow 來解決眾多問題,比如圖像說明、惡意軟件檢測、語音識別和信息檢索。最近發布了一個專注于 Android 的堆棧,名為 TensorFlow Lite。
可以在 Python、C++、Java 語言、Rust 或 Go(但 Python 最穩定)中使用 TensorFlow 開發應用程序,并通過 Hadoop 分散執行它們。除了專業的硬件接口之外,TensorFlow 還支持 CUDA。
Distributed Deep Learning
IBM Distributed Deep Learning (DDL) 被稱為“深度學習的噴氣式引擎”,這個庫鏈接到了 Caffe 和 TensorFlow 等領先框架中。可在服務器集群和數百個 GPU 上使用 DDL 來加速深度學習算法。DDL通過定義最終路徑來優化神經元計算的通信,最終的數據必須在GPU之間進行。通過輕松完成 Microsoft 最近設置的一個圖像識別任務,證明深度學習集群的瓶頸能夠得以解決。
結束語
深度學習是通過一系列架構來表示的,這些架構可為各種各樣的問題領域構建解決方案。這些解決方案可以專注于前饋的網絡,或者是允許考慮以前的輸入的遞歸網絡。盡管構建這些類型的深度架構可能很復雜,但可以使用各種開源解決方案(如Caffe,Deeplearning4j,TensorFlow和DDL)來快速啟動和運行。
-
gpu
+關注
關注
28文章
4740瀏覽量
128951 -
深度學習
+關注
關注
73文章
5503瀏覽量
121170 -
卷積神經網絡
+關注
關注
4文章
367瀏覽量
11865
原文標題:深度學習架構
文章出處:【微信號:C_Expert,微信公眾號:C語言專家集中營】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
深度學習的硬件架構解析

【詳解】FPGA:深度學習的未來?
如何在交通領域構建基于圖的深度學習架構
新芯片架構瞄準深度學習和視覺處理
深度好文,詳解PowerVR Furian GPU架構的改變(二)
深度學習的三種基本結構及原理詳解

一文解讀深度學習的發展

深度學習的三種學習模式介紹
什么是深度學習(Deep Learning)?深度學習的工作原理詳解
一文讀懂何為深度學習1





 工商網監
工商網監
評論