 一個高效的低延遲視頻語義分割算法
一個高效的低延遲視頻語義分割算法
在自動駕駛領域,目前基于深度學習的分割算法運算負荷仍然較大,不能有效移植到嵌入式端,在車輛上運行。在保證分割精度的情況下,如何才能達到高實時性?CVPR 2018商湯科技論文解讀第4期為您帶來解讀。
以下是在自動駕駛場景理解領域,商湯科技發表的一篇亮點報告(Spotlight)論文,提出極低延遲性的視頻語義分割算法。
簡介
近年來由于深度神經網絡,尤其全卷經神經網絡的迅速發展,圖像語義分割取得了飛速的進展,但是如何高效的實現視頻語義分割仍然是一個極富挑戰性的問題。其困難在于:
與圖像分割相比,視頻分割通常涉及更多的數據。比如,視頻每秒通常包含15~30幀,分析視頻因而需要更多的計算資源;
許多實際應用(如自動駕駛)中的視頻分割模塊需要實現視頻分割的低延遲性。
對于視頻語義分割任務,大部分現有工作關注如何在每幀計算量和分割精度之間的達到一個平衡點,卻并沒有深入的思考和探討算法延遲性這個因素。現有工作可以被大致分為兩類:
高層特征的時序建模方法
中間層特征傳播的方法
前者主要在一個完整的逐幀模型上增加一些提取時序信息的操作,因此不能減少計算量。后者(如Clockwork Net、Deep Feature Flow等工作)通過重用歷史幀的特征來加速計算,這類方法可以減少視頻整體計算量,然而忽略了延遲方面的因素。這類方法的延遲和精度對比(如圖1所示),可以看出這類方法很難同時實現低延遲和高精度。我們的工作則立足降低每幀平均計算量的同時,實現分割的高精度,降低算法的最大延遲。
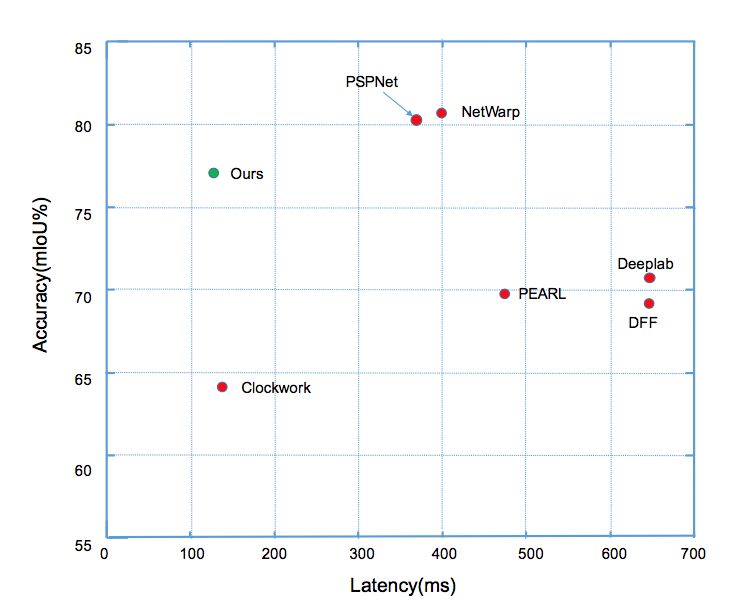
圖1:
Cityscapes數據集上
不同方法延遲和分割精度的對比
算法核心思想
本文算法使用視頻分割中經典的基于關鍵幀調度的模式來有效平衡計算量和精度。具體來說,如果當前處理幀為關鍵幀,則使用整個分割網絡來獲得語義分割的標簽,如圖2左部分所示;如果當前幀不為關鍵幀,則變換分割網絡高層歷史幀特征為當前幀高層特征,再使用分割網絡的語義分類操作獲得當前幀的語義標簽,如圖2右部分所示。關鍵幀的選擇和特征跨幀傳播兩個操作均基于同樣的網絡低層特征,具體操作在之后章節詳述。在劃分分割網絡結構時,算法盡量保證低層網絡的運行時間遠小于高層網絡,(如圖2所示)低層網絡耗時61ms,而高層網絡耗時300ms。這樣考慮的出發點在于:
因低層網絡的計算代價很小,算法可以基于低層網絡提取的特征,增加少部分額外的計算來完成關鍵幀選擇和特征跨幀傳播;
當前幀的低層特征同樣包含當前幀的信息,可以互補來自不同時間的傳播特征;
所有的操作均復用了逐幀模型的結構,算法整體模型更加簡潔。
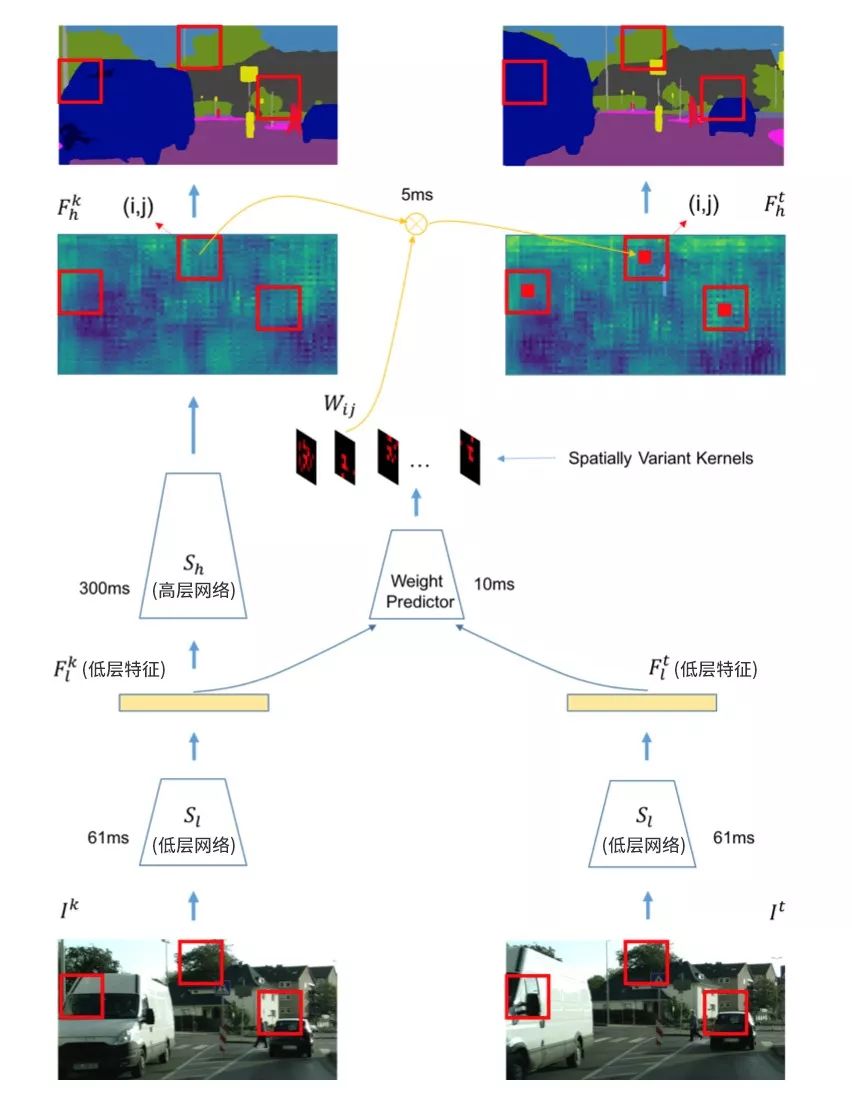
圖2:
自適應特征傳播模塊
自適應特征跨幀傳播
特征傳播關注如何從歷史幀傳播高層特征到當前幀,降低模型總體計算量,先前的變換方法主要分為兩類:
基于圖像或底層特征獲取的光流信息,跨幀傳播不同幀的語義分類特征。這類方法雖然有效,但是計算光流往往代價太大,而獲得當前幀的語義標簽并不需要嚴格的點到點映射。
平移不變性卷積。這種操作在每個位置均使用相同的卷積核來映射特征,因此不能適應不同位置的內容變化。
本文設計了一個位置相關的卷積操作來進行跨幀特征傳播。它的計算量相對較低,同時又能適應不同位置的特征進行自適應傳播。不同位置的卷積核參數通過一個小的網絡回歸學習獲得(如圖2中weight predictor所示),其能很好的適應不同空間位置內容的變化。整體特征傳播模塊(包含當前幀低層網絡、卷積核預測和空間變化卷積)包含兩大優勢:
總體計算量相較高層網絡部分計算量大為減小,因而可以快速的獲得當前幀的語義標簽;
可以很好的保持視頻鄰近幀的抖動或者其他快速變化,實驗結果表明這種卷積操作融合方法能夠有效的提升7% mIOU的精度。
整體結果如表1所示,結果展示了本文算法復用逐幀網絡的優勢,可以從低層網絡提取的特征來互補跨幀傳播的特征。

表1:
不同特征傳播模塊對最終分割精度的影響
自適應關鍵幀調度
視頻處理算法中,一個好的關鍵幀選擇算法能夠隨視頻內容變化自適應的調整關鍵幀選擇頻率,在視頻內容變化大的時間區間更多的選擇關鍵幀,而在視頻變化緩慢的區間較少的選擇關鍵幀,從而在有效保持視頻流中信息的前提下,降低整體計算量。現有的關鍵幀調度算法分為固定長度調度和基于閾值調度兩種方案,前者每隔n幀選擇一次關鍵幀,這種方式不能適應不同視頻幀之間內容的變化,后者則通過計算當前幀高層特征和歷史幀高層特征之間的差值,通過設定一個閾值來決定是否是否選擇當前幀為關鍵幀,這種方法能一定程度的適應不同幀之間的內容變化,但是特征的差值容易波動,較難設定一個統一的閾值。
本文算法使用當前幀語義標簽和前一個關鍵幀語義標簽的差異值來作為視頻內容變化程度的判斷依據,如圖3所示,若當前幀距上一個關鍵幀越遠,則語義標簽的差值就越大。當差值超過某個閾值的時候,則選擇該幀作為關鍵幀。但是直接計算這樣一個差異值較為困難,本文在Cityscapes和Camvid兩個數據集上發現低層特征和語義標簽的變化值有很大的關聯,因而利用低層特征來預測這樣該差值,即輸入歷史幀低層特征和當前幀低層特征到一個回歸器來回歸該差異值。不同的關鍵幀選擇策略的結果如圖4所示,所有的策略均采用本文提出的自適應特征傳播方法,可以看出提出的自適應關鍵幀調度方法明顯優于基于固定間隔和基于高層特征差值閾值的調度策略。
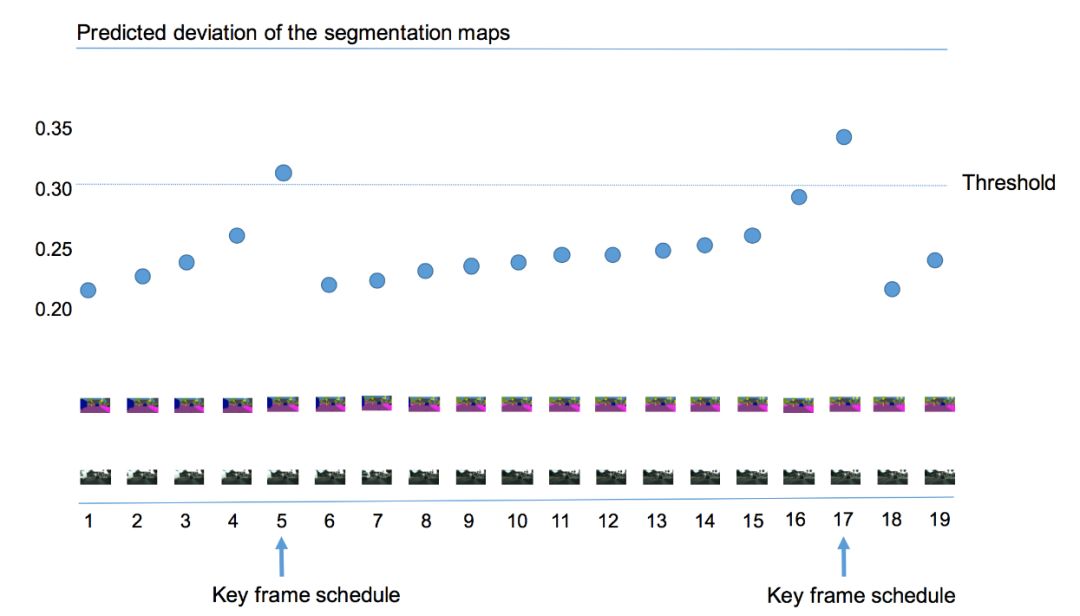
圖3:
自適應的關鍵幀選擇
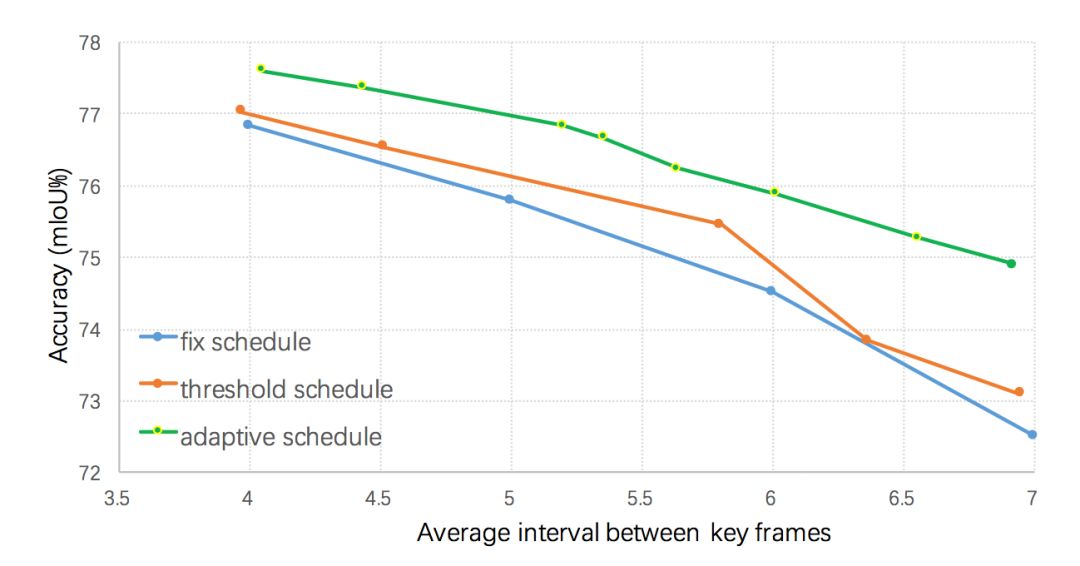
圖4:
不同調度策略對最終分割性能的影響
整體系統框架
本文算法整體框架如圖5所示,當視頻的序列幀不斷輸入時,在第一幀時刻,進行初始化操作,即輸入圖片幀給整個網絡,獲得低層特征和高層特征。在接下來的時刻t進行自適應的計算,首先計算低層特征:輸入和上一個關鍵幀低層特征至自適應關鍵幀選擇模塊,判斷當前幀是否為關鍵幀。若為關鍵幀,則輸入底層特征至高層網絡獲得高層特征;否則輸入底層特征至自適應特征傳播模塊獲得當前幀高層特征,進而通過語義分類獲得當前幀語義標簽。
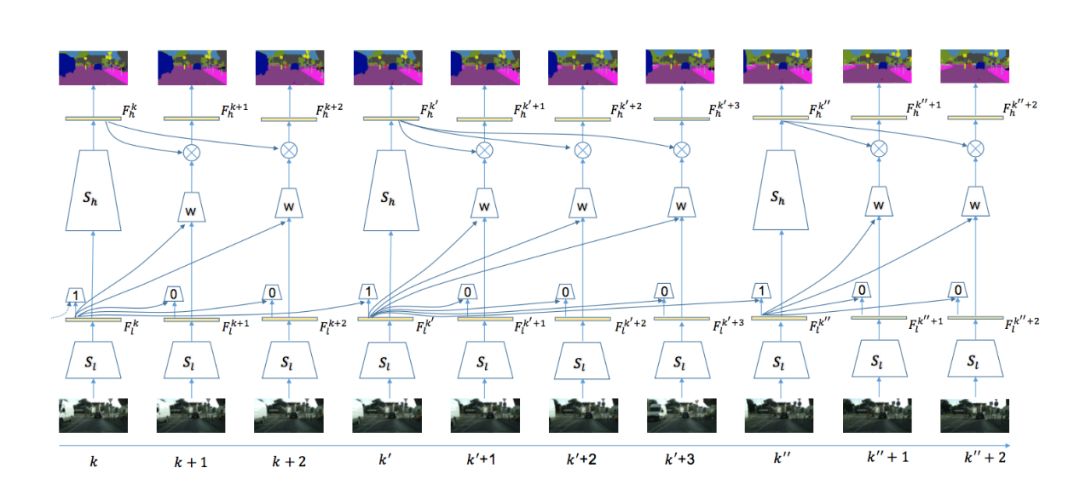
圖5:
系統整體框架示意圖
該系統極大的減少了整體耗時,其中判斷關鍵幀操作耗時僅20ms,跨幀特征傳播僅需38ms,而高層網絡計算高層特征則需要299ms。通過這種方式,整個系統可以明顯的降低系統的平均每幀計算量(如表2所示),自適應調度策略和自適應特征傳播方法可以把每幀平均計算時間由360ms減為171ms,精度僅損失3.4% mIOU。
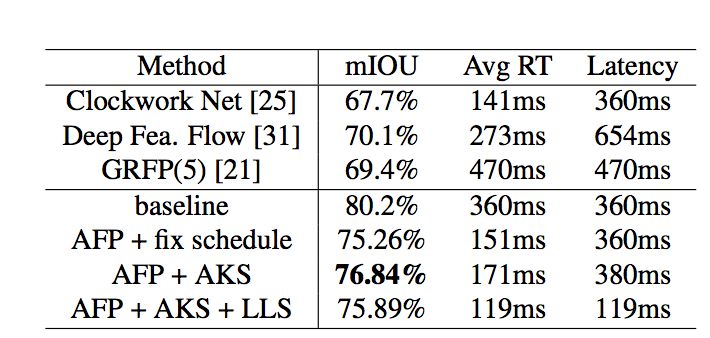
表2:
Cityscape數據集上
與目前先進方法結果的對比
同時本文設計了一種低延遲的調度策略進一步減少整體系統的延遲,適用于自動駕駛等需要及時響應的系統。具體而言,當前幀被判斷為關鍵幀時,低延遲調度策略仍然從歷史幀傳播特征到當前幀并將其緩存為當前幀高層特征,同時啟用一個后臺線程來計算當前幀高層特征(如果直接運行高層網絡部分會造成299ms的延遲),一旦計算完成就取代緩存的高層特征。實驗結果表明(如表2所示),這種低延遲的調度策略能夠將延遲由360ms降為119ms,同時只損失較小的分割精度(由78.84%降為75.89%)。
結論
本文提出了一個高效的低延遲視頻語義分割算法,其主要由自適應特征傳播和自適應關鍵幀調度模塊組成。該算法在關注平衡精度和計算量的同時力求降低系統的延遲,Cityscapes和Camvid兩個數據集上的實驗結果證明了該方法的有效性。作者希望在未來工作中在模型壓縮和模型設計方面進一步降低算法的總體延遲和計算量。
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100772 -
視頻
+關注
關注
6文章
1945瀏覽量
72914 -
自動駕駛
+關注
關注
784文章
13812瀏覽量
166461
原文標題:CVPR 2018 | 商湯科技Spotlight論文詳解:極低延遲性的視頻語義分割
文章出處:【微信號:SenseTime2017,微信公眾號:商湯科技SenseTime】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于TICA和GMM的視頻語義概念檢測算法
聚焦語義分割任務,如何用卷積神經網絡處理語義圖像分割?
Facebook AI使用單一神經網絡架構來同時完成實例分割和語義分割

語義分割算法系統介紹
語義分割方法發展過程

基于深度神經網絡的圖像語義分割方法

全局雙邊網絡語義分割算法綜述
PyTorch教程-14.9. 語義分割和數據集

深度學習圖像語義分割指標介紹






 工商網監
工商網監
評論