 YOLO的核心思想及YOLO的實現細節
YOLO的核心思想及YOLO的實現細節
YOLOv1
這是繼 RCNN,fast-RCNN 和 faster-RCNN之后,Ross Girshick 針對 DL 目標檢測速度問題提出的另外一種框架。YOLO V1 其增強版本在 GPU 上能跑45fps,簡化版本155fps。
論文下載:
http://arxiv.org/abs/1506.02640
代碼下載:
https://github.com/pjreddie/darknet
1.YOLO 的核心思想
YOLO 的核心思想就是利用整張圖作為網絡的輸入,直接在輸出層回歸 bounding box(邊界框) 的位置及其所屬的類別。
faster-RCNN 中也直接用整張圖作為輸入,但是 faster-RCNN 整體還是采用了RCNN 那種 proposal+classifier 的思想,只不過是將提取 proposal 的步驟放在 CNN 中實現了,而 YOLO 則采用直接回歸的思路。
2.YOLO 的實現方法
將一幅圖像分成 SxS 個網格(grid cell),如果某個 object 的中心落在這個網格中,則這個網格就負責預測這個 object。
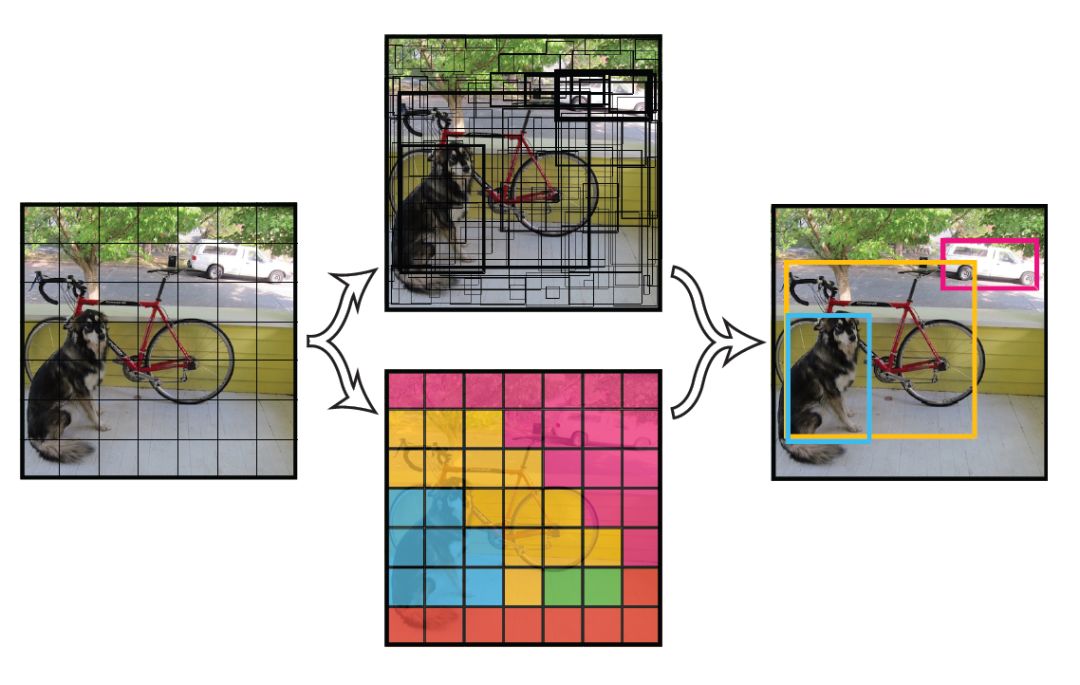
每個網格要預測 B 個 bounding box,每個 bounding box 除了要回歸自身的位置之外,還要附帶預測一個 confidence 值。
這個 confidence 代表了所預測的 box 中含有 object 的置信度和這個 box 預測的有多準這兩重信息,其值是這樣計算的:
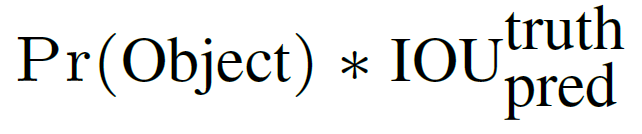
其中如果有 object 落在一個 grid cell 里,第一項取 1,否則取 0。 第二項是預測的 bounding box 和實際的 groundtruth 之間的 IoU 值。
每個 bounding box 要預測 (x, y, w, h) 和 confidence 共5個值,每個網格還要預測一個類別信息,記為 C 類。則 SxS個 網格,每個網格要預測 B 個 bounding box 還要預測 C 個 categories。輸出就是 S x S x (5*B+C) 的一個 tensor。
注意:class 信息是針對每個網格的,confidence 信息是針對每個 bounding box 的。
舉例說明:在PASCAL VOC 中,圖像輸入為 448x448,取 S=7,B=2,一共有20 個類別(C=20),則輸出就是 7x7x30 的一個 tensor。
整個網絡結構如下圖所示:

在 test 的時候,每個網格預測的 class 信息和 bounding box 預測的 confidence信息相乘,就得到每個 bounding box 的 class-specific confidence score:
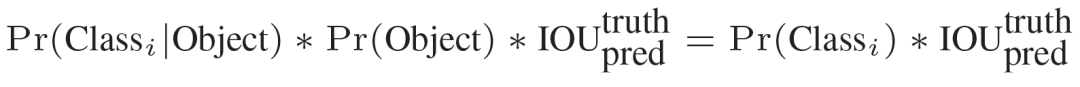
等式左邊第一項就是每個網格預測的類別信息,第二、三項就是每個 bounding box 預測的 confidence。這個乘積即 encode 了預測的 box 屬于某一類的概率,也有該 box 準確度的信息。
得到每個 box 的 class-specific confidence score 以后,設置閾值,濾掉得分低的 boxes,對保留的 boxes 進行 NMS 處理,就得到最終的檢測結果。
注:
*由于輸出層為全連接層,因此在檢測時,YOLO 訓練模型只支持與訓練圖像相同的輸入分辨率。
*雖然每個格子可以預測 B 個 bounding box,但是最終只選擇只選擇 IOU 最高的 bounding box 作為物體檢測輸出,即每個格子最多只預測出一個物體。當物體占畫面比例較小,如圖像中包含畜群或鳥群時,每個格子包含多個物體,但卻只能檢測出其中一個。這是 YOLO 方法的一個缺陷。
3.YOLO 的實現細節
每個 grid 有 30 維,這 30 維中,8 維是回歸 box 的坐標,2 維是 box的 confidence,還有 20 維是類別。
其中坐標的 x, y 用對應網格的 offset 歸一化到 0-1 之間,w, h 用圖像的 width 和 height 歸一化到 0-1 之間。
在實現中,最主要的就是怎么設計損失函數,讓這個三個方面得到很好的平衡。作者簡單粗暴的全部采用了 sum-squared error loss 來做這件事。
這種做法存在以下幾個問題:
第一,8維的 localization error 和20維的 classification error 同等重要顯然是不合理的;
第二,如果一個網格中沒有 object(一幅圖中這種網格很多),那么就會將這些網格中的 box 的 confidence push 到 0,相比于較少的有 object 的網格,這種做法是 overpowering 的,這會導致網絡不穩定甚至發散。
解決辦法:
更重視8維的坐標預測,給這些損失前面賦予更大的 loss weight, 記為
在 pascal VOC 訓練中取 5。
對沒有 object 的 box 的 confidence loss,賦予小的 loss weight,記為
在 pascal VOC 訓練中取 0.5。
有 object 的 box 的 confidence loss 和類別的 loss 的 loss weight 正常取 1。
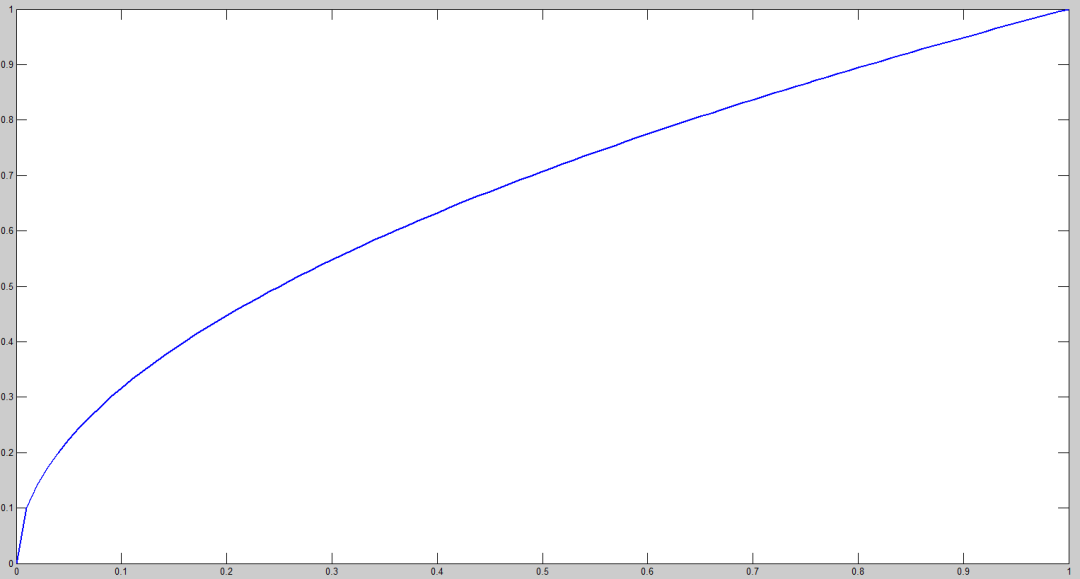
對不同大小的 box 預測中,相比于大 box 預測偏一點,小 box 預測偏一點肯定更不能被忍受的。而 sum-square error loss 中對同樣的偏移 loss 是一樣。
為了緩和這個問題,作者用了一個比較取巧的辦法,就是將 box 的 width 和 height 取平方根代替原本的 height 和 width。這個參考下面的圖很容易理解,小box 的橫軸值較小,發生偏移時,反應到y軸上相比大 box 要大。(也是個近似逼近方式)
一個網格預測多個 box,希望的是每個 box predictor 專門負責預測某個 object。具體做法就是看當前預測的 box 與 ground truth box 中哪個 IoU 大,就負責哪個。這種做法稱作 box predictor 的 specialization。
最后整個的損失函數如下所示:

這個損失函數中:
只有當某個網格中有 object 的時候才對 classification error 進行懲罰。
只有當某個 box predictor 對某個 ground truth box 負責的時候,才會對 box 的 coordinate error 進行懲罰,而對哪個 ground truth box 負責就看其預測值和 ground truth box 的 IoU 是不是在那個 cell 的所有 box 中最大。
其他細節,例如使用激活函數使用 leak RELU,模型用 ImageNet 預訓練等等,在這里就不一一贅述了。
注:
*YOLO 方法模型訓練依賴于物體識別標注數據,因此,對于非常規的物體形狀或比例,YOLO 的檢測效果并不理想。
*YOLO 采用了多個下采樣層,網絡學到的物體特征并不精細,因此也會影響檢測效果。
* YOLO 的損失函數中,大物體 IOU 誤差和小物體 IOU 誤差對網絡訓練中 loss 貢獻值接近(雖然采用求平方根方式,但沒有根本解決問題)。因此,對于小物體,小的 IOU 誤差也會對網絡優化過程造成很大的影響,從而降低了物體檢測的定位準確性。
4.YOLO 的缺點
YOLO 對相互靠的很近的物體,還有很小的群體檢測效果不好,這是因為一個網格中只預測了兩個框,并且只屬于一類。
同一類物體出現的新的不常見的長寬比和其他情況時,泛化能力偏弱。
由于損失函數的問題,定位誤差是影響檢測效果的主要原因。尤其是大小物體的處理上,還有待加強。
YOLOv2
YOLOv2:代表著目前業界最先進物體檢測的水平,它的速度要快過其他檢測系統(FasterR-CNN,ResNet,SSD),使用者可以在它的速度與精確度之間進行權衡。
YOLO9000:這一網絡結構可以實時地檢測超過 9000 種物體分類,這歸功于它使用了 WordTree,通過 WordTree 來混合檢測數據集與識別數據集之中的數據。
工程代碼地址:
http://pjreddie.com/darknet/yolo/
▌簡介
目前的檢測數據集(Detection Datasets)有很多限制,分類標簽的信息太少,圖片的數量小于分類數據集(Classi?cation Datasets),而且檢測數據集的成本太高,使其無法當作分類數據集進行使用。而現在的分類數據集卻有著大量的圖片和十分豐富分類信息。
文章提出了一種新的訓練方法–聯合訓練算法。這種算法可以把這兩種的數據集混合到一起。使用一種分層的觀點對物體進行分類,用巨量的分類數據集數據來擴充檢測數據集,從而把兩種不同的數據集混合起來。
聯合訓練算法的基本思路就是:同時在檢測數據集和分類數據集上訓練物體檢測器(Object Detectors ),用監測數據集的數據學習物體的準確位置,用分類數據集的數據來增加分類的類別量、提升魯棒性。
YOLO9000 就是使用聯合訓練算法訓練出來的,他擁有 9000 類的分類信息,這些分類信息學習自ImageNet分類數據集,而物體位置檢測則學習自 COCO 檢測數據集。
代碼和預訓練模型地址:
http://pjreddie.com/yolo9000/
▌更準
YOLO 一代有很多缺點,作者希望改進的方向是改善 recall,提升定位的準確度,同時保持分類的準確度。
目前計算機視覺的趨勢是更大更深的網絡,更好的性能表現通常依賴于訓練更大的網絡或者把多種模型綜合到一起。但是 YOLO v2 則著力于簡化網絡。具體的改進見下表:
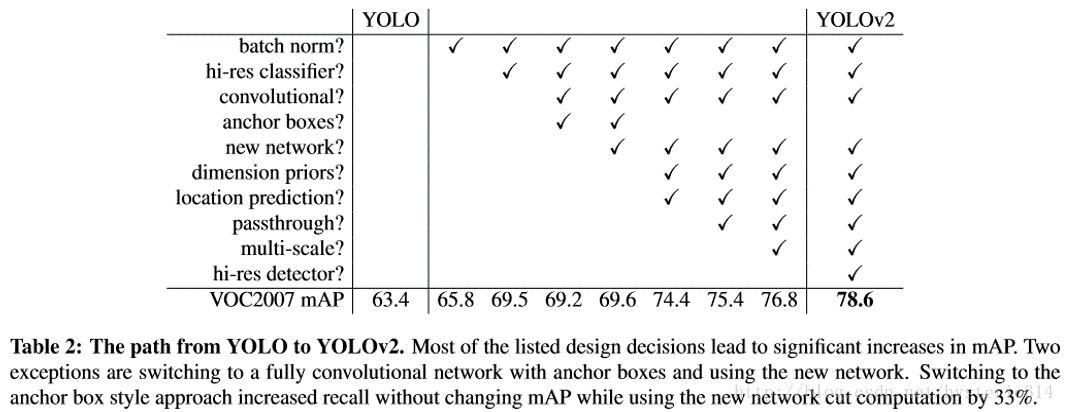
Batch Normalization
使用 Batch Normalization 對網絡進行優化,讓網絡提高了收斂性,同時還消除了對其他形式的正則化(regularization)的依賴。通過對 YOLO 的每一個卷積層增加 Batch Normalization,最終使得 mAP 提高了 2%,同時還使模型正則化。使用 Batch Normalization 可以從模型中去掉 Dropout,而不會產生過擬合。
High resolution classifier
目前業界標準的檢測方法,都要先把分類器(classi?er)放在ImageNet上進行預訓練。從 Alexnet 開始,大多數的分類器都運行在小于 256*256 的圖片上。而現在 YOLO 從 224*224 增加到了 448*448,這就意味著網絡需要適應新的輸入分辨率。
為了適應新的分辨率,YOLO v2 的分類網絡以 448*448 的分辨率先在 ImageNet上進行微調,微調 10 個 epochs,讓網絡有時間調整濾波器(filters),好讓其能更好的運行在新分辨率上,還需要調優用于檢測的 Resulting Network。最終通過使用高分辨率,mAP 提升了 4%。
Convolution with anchor boxes
YOLO 一代包含有全連接層,從而能直接預測 Bounding Boxes 的坐標值。 Faster R-CNN 的方法只用卷積層與 Region Proposal Network 來預測 Anchor Box 偏移值與置信度,而不是直接預測坐標值。作者發現通過預測偏移量而不是坐標值能夠簡化問題,讓神經網絡學習起來更容易。
所以最終 YOLO 去掉了全連接層,使用 Anchor Boxes 來預測 Bounding Boxes。作者去掉了網絡中一個池化層,這讓卷積層的輸出能有更高的分辨率。收縮網絡讓其運行在 416*416 而不是 448*448。由于圖片中的物體都傾向于出現在圖片的中心位置,特別是那種比較大的物體,所以有一個單獨位于物體中心的位置用于預測這些物體。YOLO 的卷積層采用 32 這個值來下采樣圖片,所以通過選擇 416*416 用作輸入尺寸最終能輸出一個 13*13 的特征圖。 使用 Anchor Box 會讓精確度稍微下降,但用了它能讓 YOLO 能預測出大于一千個框,同時 recall 達到88%,mAP 達到 69.2%。
Dimension clusters
之前 Anchor Box 的尺寸是手動選擇的,所以尺寸還有優化的余地。 為了優化,在訓練集的 Bounding Boxes 上跑一下 k-means聚類,來找到一個比較好的值。
如果我們用標準的歐式距離的 k-means,尺寸大的框比小框產生更多的錯誤。因為我們的目的是提高 IOU 分數,這依賴于 Box 的大小,所以距離度量的使用:
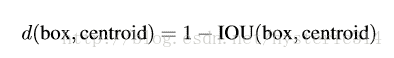
通過分析實驗結果(Figure 2),左圖:在模型復雜性與 high recall 之間權衡之后,選擇聚類分類數 K=5。右圖:是聚類的中心,大多數是高瘦的 Box。
Table1 是說明用 K-means 選擇 Anchor Boxes 時,當 Cluster IOU 選擇值為 5 時,AVG IOU 的值是 61,這個值要比不用聚類的方法的 60.9 要高。選擇值為 9 的時候,AVG IOU 更有顯著提高。總之就是說明用聚類的方法是有效果的。
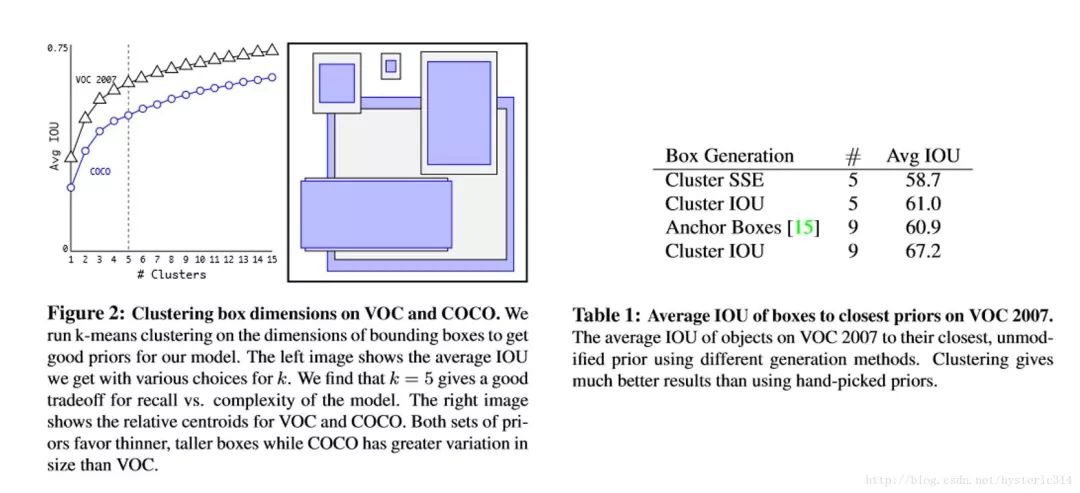
Direct location prediction
用 Anchor Box 的方法,會讓 model 變得不穩定,尤其是在最開始的幾次迭代的時候。大多數不穩定因素產生自預測 Box 的(x,y)位置的時候。按照之前 YOLO的方法,網絡不會預測偏移量,而是根據 YOLO 中的網格單元的位置來預測坐標,這就讓 Ground Truth 的值介于 0 到 1 之間。而為了讓網絡的結果能落在這一范圍內,網絡使用一個 Logistic Activation 來對于網絡預測結果進行限制,讓結果介于 0 到 1 之間。 網絡在每一個網格單元中預測出 5 個 Bounding Boxes,每個 Bounding Boxes 有五個坐標值 tx,ty,tw,th,t0,他們的關系見下圖(Figure3)。假設一個網格單元對于圖片左上角的偏移量是 cx、cy,Bounding Boxes Prior 的寬度和高度是 pw、ph,那么預測的結果見下圖右面的公式:
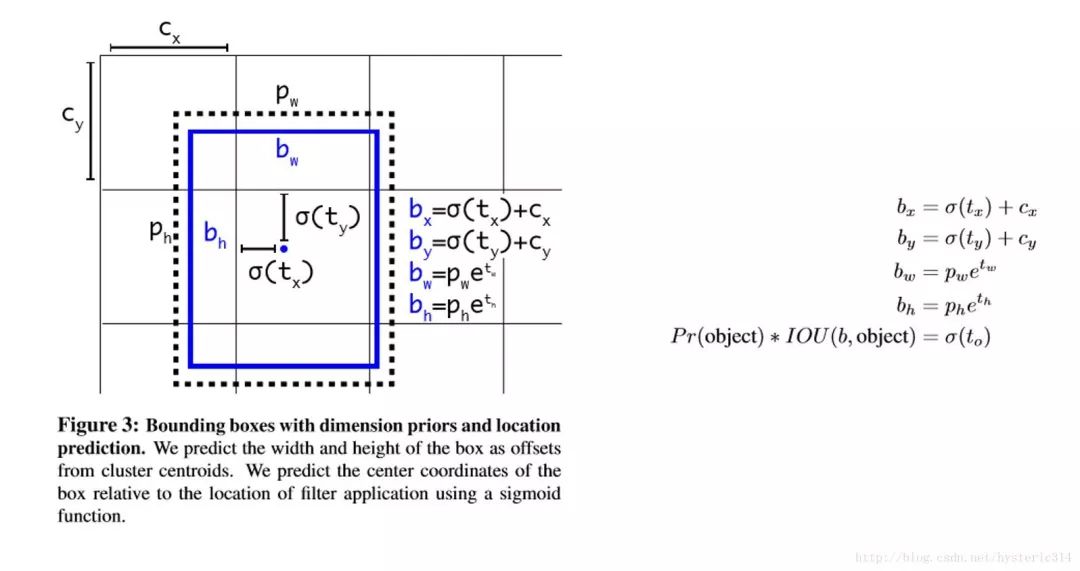
因為使用了限制讓數值變得參數化,也讓網絡更容易學習、更穩定。Dimension clusters和Direct location prediction,使 YOLO 比其他使用 Anchor Box 的版本提高了近5%。
Fine-Grained Features
YOLO 修改后的特征圖大小為 13*13,這個尺寸對檢測圖片中尺寸大物體來說足夠了,同時使用這種細粒度的特征對定位小物體的位置可能也有好處。Faster-RCNN、SSD 都使用不同尺寸的特征圖來取得不同范圍的分辨率,而 YOLO 采取了不同的方法,YOLO 加上了一個 Passthrough Layer 來取得之前的某個 26*26 分辨率的層的特征。這個 Passthrough layer 能夠把高分辨率特征與低分辨率特征聯系在一起,聯系起來的方法是把相鄰的特征堆積在不同的 Channel 之中,這一方法類似與 Resnet 的 Identity Mapping,從而把 26*26*512 變成 13*13*2048。YOLO 中的檢測器位于擴展后(expanded )的特征圖的上方,所以他能取得細粒度的特征信息,這提升了 YOLO 1% 的性能。
Multi-Scale Training
作者希望 YOLOv2 能健壯地運行于不同尺寸的圖片之上,所以把這一想法用于訓練模型中。
區別于之前的補全圖片的尺寸的方法,YOLOv2 每迭代幾次都會改變網絡參數。每 10 個 Batch,網絡會隨機地選擇一個新的圖片尺寸,由于使用了下采樣參數是 32,所以不同的尺寸大小也選擇為 32 的倍數 {320,352…..608},最小 320*320,最大 608*608,網絡會自動改變尺寸,并繼續訓練的過程。
這一政策讓網絡在不同的輸入尺寸上都能達到一個很好的預測效果,同一網絡能在不同分辨率上進行檢測。當輸入圖片尺寸比較小的時候跑的比較快,輸入圖片尺寸比較大的時候精度高,所以你可以在 YOLOv2 的速度和精度上進行權衡。
下圖是在 voc2007 上的速度與精度
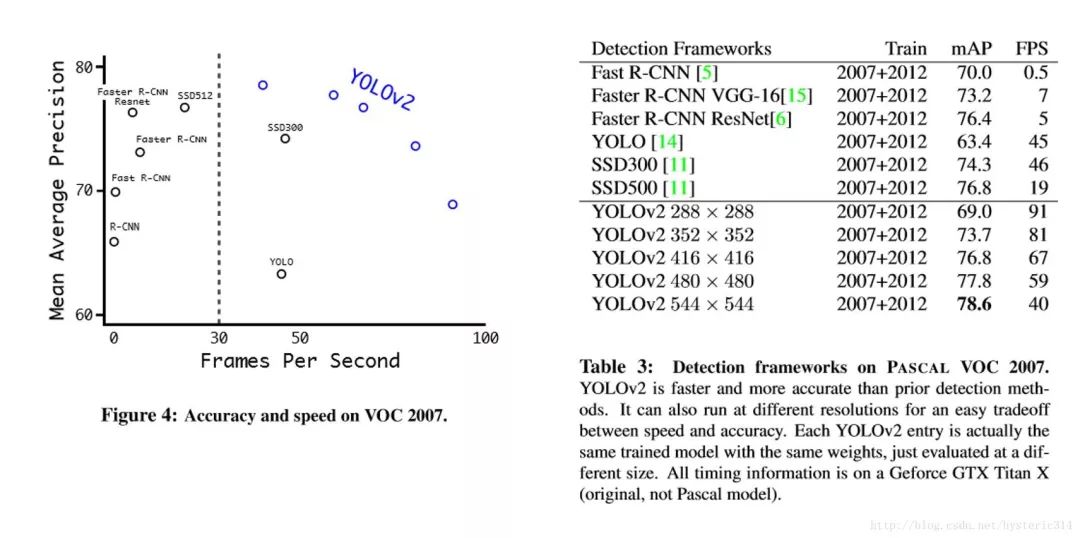
▌更快
YOLO 使用的是 GoogLeNet 架構,比 VGG-16 快,YOLO 完成一次前向過程只用 85.2 億次運算,而 VGG-16 要 306.9 億次,但是 YOLO 精度稍低于 VGG-16。
Draknet19
YOLO v2 基于一個新的分類模型,有點類似于 VGG。YOLO v2 使用 3*3 的 filter,每次池化之后都增加一倍 Channels 的數量。YOLO v2 使用全局平均池化,使用 Batch Normilazation 來讓訓練更穩定,加速收斂,使模型規范化。
最終的模型–Darknet19,有 19 個卷積層和 5 個 maxpooling 層,處理一張圖片只需要 55.8 億次運算,在 ImageNet 上達到 72.9% top-1 精確度,91.2% top-5 精確度。
Training for classi?cation
在訓練時,把整個網絡在更大的448*448分辨率上Fine Turnning 10個 epoches,初始學習率設置為0.001,這種網絡達到達到76.5%top-1精確度,93.3%top-5精確度。
▌更強
在訓練的過程中,當網絡遇到一個來自檢測數據集的圖片與標記信息,那么就把這些數據用完整的 YOLO v2 loss 功能反向傳播這個圖片。當網絡遇到一個來自分類數據集的圖片和分類標記信息,只用整個結構中分類部分的 loss 功能反向傳播這個圖片。
但是檢測數據集只有粗粒度的標記信息,像“貓“、“ 狗”之類,而分類數據集的標簽信息則更細粒度,更豐富。比如狗這一類就包括”哈士奇“”牛頭梗“”金毛狗“等等。所以如果想同時在監測數據集與分類數據集上進行訓練,那么就要用一種一致性的方法融合這些標簽信息。
再者,用于分類的方法,大多是用 softmax layer 方法,softmax 意味著分類的類別之間要互相獨立的。而盲目地混合數據集訓練,就會出現比如:檢測數據集的分類信息中”狗“這一分類,在分類數據集合中,就會有的不同種類的狗:“哈士奇”、“牛頭梗”、“金毛”這些分類,這兩種數據集之間的分類信息不相互獨立。所以使用一種多標簽的模型來混合數據集,假設一個圖片可以有多個分類信息,并假定分類信息必須是相互獨立的規則可以被忽略。
Hierarchical classification
WordNet 的結構是一個直接圖表(directed graph),而不是樹型結構。因為語言是復雜的,狗這個詞既屬于‘犬科’又屬于‘家畜’兩類,而‘犬科’和‘家畜’兩類在WordNet中則是同義詞,所以不能用樹形結構。
作者希望根據 ImageNet 中包含的概念來建立一個分層樹,為了建立這個分層樹,首先檢查 ImagenNet 中出現的名詞,再在 WordNet 中找到這些名詞,再找到這些名詞到達他們根節點的路徑(在這里設為所有的根節點為實體對象(physical object)。在 WordNet 中,大多數同義詞只有一個路徑,所以首先把這條路徑中的詞全部都加到分層樹中。接著迭代地檢查剩下的名詞,并盡可能少的把他們添加到分層樹上,添加的原則是取最短路徑加入到樹中。
為了計算某一結點的絕對概率,只需要對這一結點到根節點的整條路徑的所有概率進行相乘。所以比如你想知道一個圖片是否是 Norfolk terrier 的概率,則進行如下計算:

為了驗證這一個方法,在 WordTree 上訓練 Darknet19 的模型,使用 1000 類的 ImageNet 進行訓練,為了建立 WordtTree 1K,把所有中間詞匯加入到 WordTree 上,把標簽空間從 1000 擴大到了 1369。在訓練過程中,如果有一個圖片的標簽是“Norfolk terrier”,那么這個圖片還會獲得”狗“(dog)以及“哺乳動物”(mammal)等標簽。總之現在一張圖片是多標記的,標記之間不需要相互獨立。
如 Figure5 所示,之前的 ImageNet 分類是使用一個大 softmax 進行分類。而現在,WordTree 只需要對同一概念下的同義詞進行 softmax 分類。
使用相同的訓練參數,這種分層結構的Darknet19達到71.9%top-1精度和90.4% top-5 精確度,精度只有微小的下降。
這種方法的好處:在對未知或者新的物體進行分類時,性能降低的很優雅(gracefully)。比如看到一個狗的照片,但不知道是哪種種類的狗,那么就高置信度(confidence)預測是”狗“,而其他狗的種類的同義詞如”哈士奇“”牛頭梗“”金毛“等這些則低置信度。
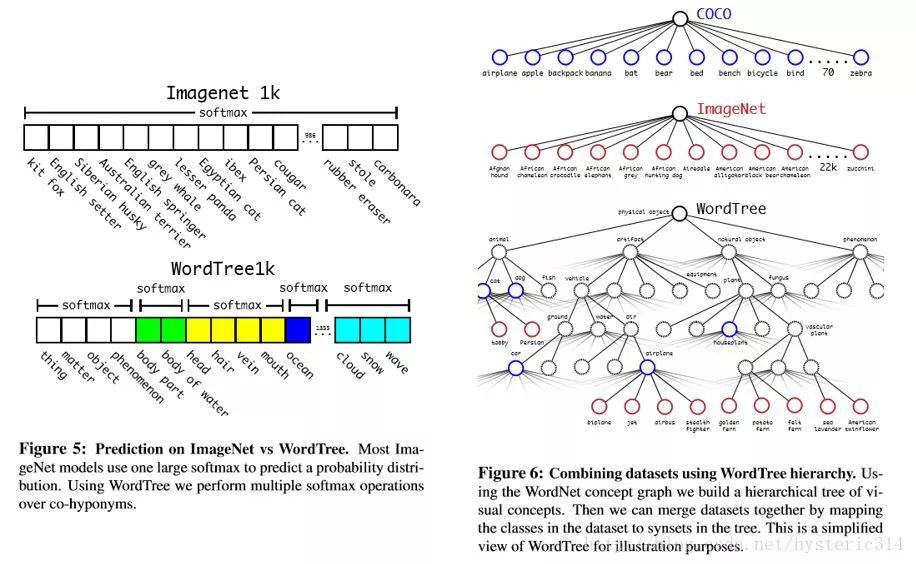
Datasets combination with wordtree
用 WordTree 把數據集合中的類別映射到分層樹中的同義詞上,例如上圖 Figure 6,WordTree 混合 ImageNet 與 COCO。
Joint classification and detection
作者的目的是:訓練一個 Extremely Large Scale 檢測器。所以訓練的時候使用 WordTree 混合了 COCO 檢測數據集與 ImageNet 中的 Top9000 類,混合后的數據集對應的 WordTree 有 9418 個類。另一方面,由于 ImageNet 數據集太大了,作者為了平衡一下兩個數據集之間的數據量,通過過采樣(oversampling) COCO 數據集中的數據,使 COCO 數據集與 ImageNet 數據集之間的數據量比例達到 1:4。
YOLO9000 的訓練基于 YOLO v2 的構架,但是使用 3 priors 而不是 5 來限制輸出的大小。當網絡遇到檢測數據集中的圖片時則正常地反方向傳播,當遇到分類數據集圖片的時候,只使用分類的 loss 功能進行反向傳播。同時作者假設 IOU 最少為 0.3。最后根據這些假設進行反向傳播。
使用聯合訓練法,YOLO9000 使用 COCO 檢測數據集學習檢測圖片中的物體的位置,使用 ImageNet 分類數據集學習如何對大量的類別中進行分類。
為了評估這一方法,使用 ImageNet Detection Task 對訓練結果進行評估。
評估結果:
YOLO9000 取得 19.7 mAP。在未學習過的 156 個分類數據上進行測試, mAP 達到 16.0。
YOLO9000 的 mAP 比 DPM 高,而且 YOLO 有更多先進的特征,YOLO9000 是用部分監督的方式在不同訓練集上進行訓練,同時還能檢測 9000個物體類別,并保證實時運行。
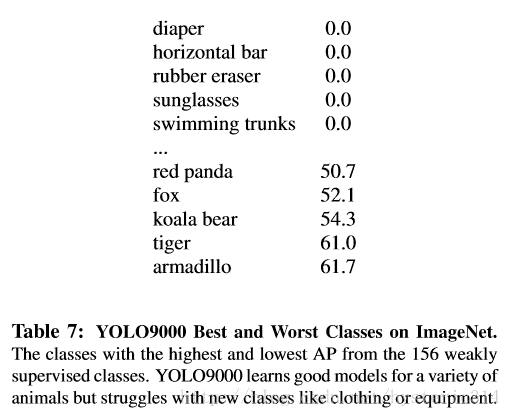
雖然 YOLO9000 對動物的識別性能很好,但是對類別為“sungalsses”或者“swimming trunks”這些衣服或者裝備的類別,它的識別性能不是很好,見 table 7。這跟數據集的數據組成有很大關系。
▌總結
YOLO v2 代表著目前最先進物體檢測的水平,在多種監測數據集中都要快過其他檢測系統,并可以在速度與精確度上進行權衡。
YOLO 9000 的網絡結構允許實時地檢測超過9000種物體分類,這歸功于它能同時優化檢測與分類功能。使用 WordTree 來混合來自不同的資源的訓練數據,并使用聯合優化技術同時在 ImageNet 和 COCO 數據集上進行訓練,YOLO9000 進一步縮小了監測數據集與識別數據集之間的大小代溝。
YOLOv3
YOLOv3 在 Pascal Titan X 上處理 608x608 圖像速度可以達到 20FPS,在 COCO test-dev 上mAP@0.5達到 57.9%,與RetinaNet(FocalLoss論文所提出的單階段網絡)的結果相近,并且速度快 4 倍.
YOLO v3 的模型比之前的模型復雜了不少,可以通過改變模型結構的大小來權衡速度與精度。
速度對比如下:
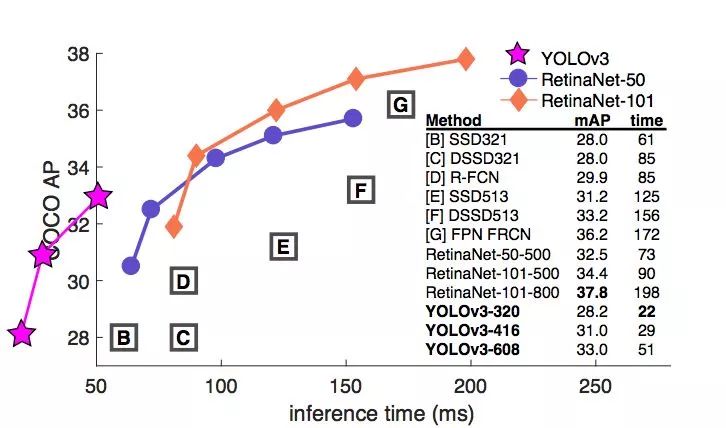
‘
YOLOv3 在實現相同準確度下要顯著地比其它檢測方法快。時間都是在采用 M40 或 Titan X 等相同 GPU 下測量的。
簡而言之,YOLOv3 的先驗檢測(Prior detection)系統將分類器或定位器重新用于執行檢測任務。他們將模型應用于圖像的多個位置和尺度。而那些評分較高的區域就可以視為檢測結果。此外,相對于其它目標檢測方法,我們使用了完全不同的方法。我們將一個單神經網絡應用于整張圖像,該網絡將圖像劃分為不同的區域,因而預測每一塊區域的邊界框和概率,這些邊界框會通過預測的概率加權。我們的模型相比于基于分類器的系統有一些優勢。它在測試時會查看整個圖像,所以它的預測利用了圖像中的全局信息。與需要數千張單一目標圖像的 R-CNN 不同,它通過單一網絡評估進行預測。這令 YOLOv3 非常快,一般它比 R-CNN 快 1000 倍、比 Fast R-CNN 快 100 倍。
改進之處:
1.多尺度預測 (類FPN)
2.更好的基礎分類網絡(類ResNet)和分類器 darknet-53,見下圖
3.分類器-類別預測:
YOLOv3 不使用 Softmax 對每個框進行分類,主要考慮因素有兩個:
a.Softmax 使得每個框分配一個類別(得分最高的一個),而對于 Open Images這種數據集,目標可能有重疊的類別標簽,因此 Softmax不適用于多標簽分類。
b.Softmax 可被獨立的多個 logistic分類器替代,且準確率不會下降。
c.分類損失采用 binary cross-entropy loss.
多尺度預測
每種尺度預測 3 個 box, anchor 的設計方式仍然使用聚類,得到9個聚類中心,將其按照大小均分給 3 個尺度。
尺度1: 在基礎網絡之后添加一些卷積層再輸出box信息。
尺度2: 從尺度1中的倒數第二層的卷積層上采樣(x2)再與最后一個 16x16 大小的特征圖相加,再次通過多個卷積后輸出 box 信息,相比尺度1變大兩倍.
尺度3: 與尺度2類似,使用了 32x32 大小的特征圖
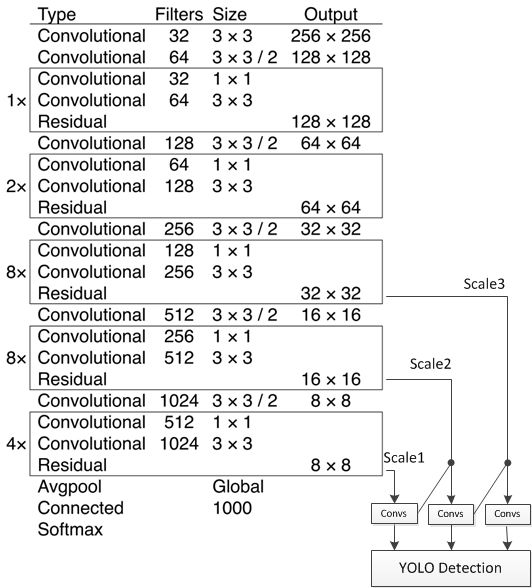
基礎網絡 Darknet-53
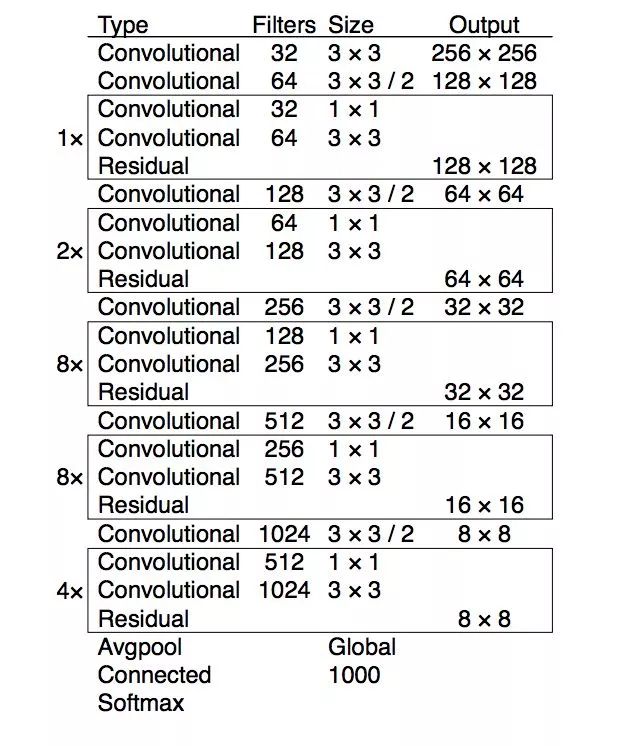
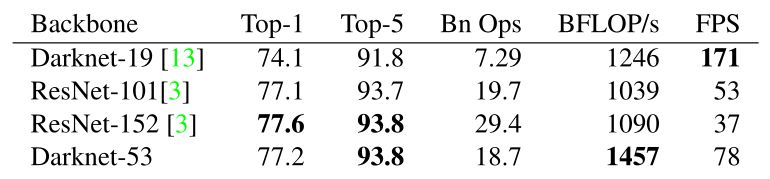
darknet-53與 ResNet-101 或 ResNet-152 準確率接近,但速度更快,對比如下:
檢測結構如下:
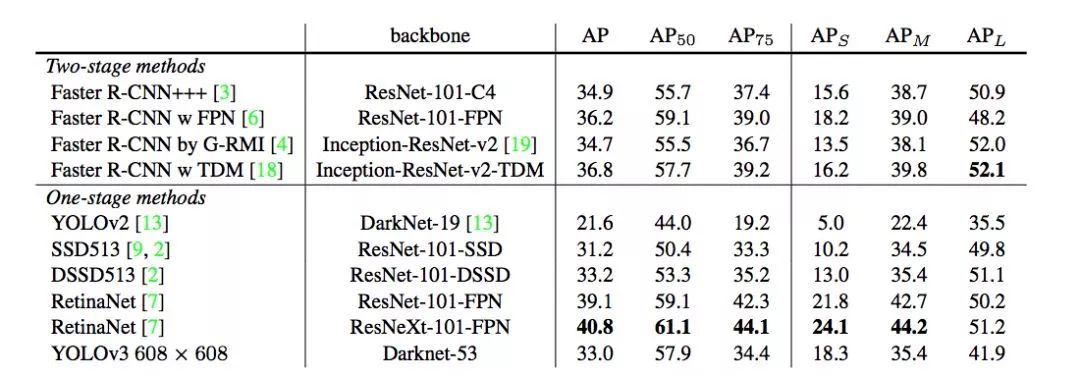
YOLOv3 在 mAP@0.5 及小目標 APs 上具有不錯的結果,但隨著 IOU的增大,性能下降,說明 YOLOv3 不能很好地與 ground truth 切合.
-
圖像
+關注
關注
2文章
1084瀏覽量
40468 -
函數
+關注
關注
3文章
4331瀏覽量
62622 -
網格
+關注
關注
0文章
139瀏覽量
16018
原文標題:從YOLOv1到YOLOv3,目標檢測的進化之路
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
使用英特爾AI PC為YOLO模型訓練加速

助力AIoT應用:在米爾FPGA開發板上實現Tiny YOLO V4
《DNK210使用指南 -CanMV版 V1.0》第四十二章 人臉口罩佩戴檢測實驗
《DNK210使用指南 -CanMV版 V1.0》第四十一章 YOLO2物體檢測實驗
《DNK210使用指南 -CanMV版 V1.0》第四十章 YOLO2人手檢測實驗
《DNK210使用指南 -CanMV版 V1.0》第三十九章 YOLO2人臉檢測實驗
【飛凌嵌入式OK3576-C開發板體驗】RKNN神經網絡-YOLO目標檢測
使用OpenVINO C# API部署YOLO-World實現實時開放詞匯對象檢測

智慧園區視頻監控分析系統 YOLO

使用esp-dl中的example量化我的YOLO模型時,提示ValueError: current model is not supported by esp-dl錯誤,為什么?
OpenVINO? C# API部署YOLOv9目標檢測和實例分割模型
縱觀全局:YOLO助力實時物體檢測原理及代碼
【EASY EAI Nano】RV1126實時讀取攝像頭并進行yolo檢測顯示
深入淺出Yolov3和Yolov4
在英特爾AI開發板上用OpenVINO NNCF優化YOLOv7






 工商網監
工商網監
評論