 面向AWorks框架管理文件的方法和數據結構
面向AWorks框架管理文件的方法和數據結構
本文導讀
文件系統是在存儲設備中(SD Card、NAND Flash…)組織文件的方法和數據結構,用于管理文件。AWorks定義了文件系統的通用接口,例如,打開、讀/寫、關閉文件等等。文件系統的具體實現可以自由選擇,例如,FAT、UFFS、YAFFS2 等等。
本文為《面向AWorks框架和接口的編程》第三部分軟件篇——第11章文件系統——第1~5小節:文件系統簡介、設備掛載管理、文件基本操作、目錄基本操作和微型數據庫。本章導讀
文件系統是用于管理文件的方法和數據結構,文件和文件系統相關的數據存儲在實際的物理介質中,例如,NAND FLASH,Nor FLASH或SD Card等。AWorks定義了文件系統的通用接口,無論底層使用何種文件系統,比如常見的FAT16/32、UFFS或YAFFS2等,均可使用同一套接口進行文件相關的操作。
11.1 文件系統簡介
在文件系統中,存儲數據的基本單位是文件,即數據是按照一個一個文件的方式進行組織的。當文件較多時,將導致文件繁多、不易分類、重名等問題,為此,在文件的基礎上,提出了目錄的概念,相當于Windows系統中的文件夾,一個目錄中,可以包含多個文件。特別地,一個目錄中,除包含文件外,還可以包含子目錄,子目錄可以繼續包含子目錄。最上層的目錄被稱為根目錄,示意圖詳見圖11.1。

圖11.1 目錄結構示意圖
圖中的目錄名和文件名僅用作示例,與實際系統的目錄樹結構并不存在任何關聯。在AWorks中,根目錄使用斜杠(即:"/")表示,應注意與反斜杠(即:"")進行區分,不可混用。存于根目錄中的文件,其完整路徑直接使用“斜杠 + 文件名”的形式表示,如圖11.1中的test1.txt文件,其路徑為"/test1.txt",若一個文件所在目錄不是根目錄時,則多個目錄之間要使用斜杠(即:"/")分隔,比如,test5.txt文件對應的完整路徑應表示為"/usr/base/test5.txt"。
AWorks中分隔符使用"/",這與UNIX/Linux的風格是完全相同的,而與Windows則不相同,Windows中使用反斜杠""作為分隔符。
11.2 設備掛載管理
在圖11.1中,為用戶展示了一個目錄樹結構,圖中的每個文件都存放在相應的目錄中,目錄是一個虛擬的邏輯概念,便于用戶按照邏輯路徑訪問各個文件。而實質上,文件數據是存放在物理存儲介質中的,例如,NAND FLASH,Nor FLASH或SD Card等。為此,就需要在系統中將目錄與某一物理存儲介質相關聯,用戶存放在某一目錄下的文件都自動保存到對應的物理存儲介質中,這種關聯操作可以通過“設備掛載”來實現。“設備掛載”用于將物理存儲介質掛載到某一目錄,使該物理存儲介質與該目錄對應,后續所有在該目錄下的文件(或子目錄)實際上都存儲到了與之對應的存儲介質中。
在一個系統中,往往存在多種存儲介質,例如,NAND FLASH,SD Card或外接的U盤等,無論存在多少存儲介質,對于用戶來講,其都是使用圖11.1所示的一個目錄樹來進行文件的管理,根目錄只會有一個,不會因為具有多個存儲介質而產生多個根目錄。
實際應用中,為了方便管理,可以進行更細的劃分,將一個硬件存儲介質分成多個區,此時,每個分區可以看作一個獨立的存儲介質,掛載到某一目錄。例如,一個SD卡的容量是2G,可以分成大小不同的4個分區,例如,SD_S0(1G)、SD_S1(512M)、SD_S2(256M)、SD_S3(256M)。此時,4個分區可以當作4個獨立的存儲介質,分別掛載到不同的目錄。
對于一個物理存儲介質,需要使用某一具體的文件系統對其中的文件數據進行管理,比如常見的FAT16/32、UFFS或YAFFS2等,它們各有優缺點,針對特定的存儲介質,可以選擇合適的文件系統。如FAT16/32常用于U盤、SD卡中,UFFS和YAFFS2常用于NAND FLASH中。同一系統中,不同的物理存儲介質可以使用不同的文件系統。一般來講,初次使用某一硬件存儲介質時,需要進行格式化操作,指定使用的文件系統,存儲一些與文件系統相關的初始數據。格式化后,才可將該設備掛載到目錄樹中。通常情況下,存儲設備掉電不會丟失數據,因此,格式化操作僅需執行一次,不需要每次上電都執行。
AWorks提供了抽象的文件系統接口和框架,即使系統中不同存儲介質使用了不同的文件系統,對于用戶來講,仍然可以使用相同的接口進行文件相關的操作。
AWorks提供了管理硬件存儲設備的接口,相關接口的函數原型詳見表11.1。
表11.1 存儲設備管理相關接口(fs/aw_mount.h)
1. 格式化存儲設備
格式化存儲設備,以指定使用的文件系統,并存儲一些與文件系統相關的初始數據。其函數原型為:

其中,dev_name為存儲設備的名字,fs_name為使用的文件系統的名字,fmt_arg為格式化相關的附加信息。返回值為標準的錯誤號,返回AW_OK時,表示格式化成功,否則,表示格式化失敗,可能是由于硬件設備不存在或文件系統不支持造成的。
存儲設備的名字與具體的物理存儲介質相關。例如,常見的SD卡設備,其對應的設備名為:/dev/sdx,其中,x為SD卡所處的SDIO總線序號,比如:0、1、2等。為便于敘述,這里將SD卡和TF卡統稱為SD卡存儲設備,SD卡就是常見的大卡,常用于相機中,如圖11.2(a)所示。
TF卡又稱Micro SD卡,體積比SD卡小,很多手機都配備了TF卡接口,用于擴展存儲容量,如圖11.2(b)所示。除了體積大小的區別外,SD卡在左側還有一個LOCK開關,用于鎖定SD卡,從硬件上開啟寫保護,避免數據損壞。

圖11.2 SD卡與TF卡
在i.MX28x硬件平臺中,僅在SDIO0總線上設置了一個TF卡卡槽,因而僅能插入一張TF卡,不能插入SD卡。若正確插入了TF卡,則該TF卡對應的設備名為"/dev/sd0"。為便于驗證后續程序,讀者可以準備一張TF卡。
除使用TF卡外,還可以使用U盤進行測試,在i.MX28x平臺中設置了USB接口,默認情況下,USB HOST1接口用于外接USB設備,USB HOST0接口用于外接USB主機,將自身模擬為一個USB設備。可以通過USB HOST1接口外接U盤,U盤在系統中對應的存儲設備名為"/dev/ms0-ud0"。
在編程上,不同的物理存儲設備僅僅是設備名發生了變化,沒有其它任何區別,U盤和TF卡的具體細節差異用戶無需關心。為便于敘述,后文統一使用TF卡存儲設備進行舉例說明,若讀者使用的是U盤,僅需將范例程序中出現的TF卡設備名修改為"/dev/ms0-ud0"。
fs_name為文件系統的名字,比如:
"vfat"、"uffs"、"yaffs"等,其代表了此硬件設備使用的具體文件系統。如使用FAT,則文件系統名為"vfat",其會自動根據存儲器特性選擇使用合適的FAT文件系統:FAT12、FAT16或FAT32。
fmt_arg為格式化相關的信息,不同文件系統使用的信息可能會不同,其類型struct aw_fs_format_arg (fs/aw_fs_type.h)定義如下:

對于FAT文件系統, 其管理的一個存儲設備或分區稱之為“卷”(volume),vol_name即為該卷指定一個卷名,當前系統中,卷名僅作標識,未用作其它特殊用途,可任意指定一個合理的名字,比如:"awdisk"。
在FAT文件系統中,存儲設備是以“分配單元”(allocation unit)為單位進行數據管理的, unit_size指定了每個分配單元的大小,分配單元在FAT中又被稱為“簇”(cluster)。
在允許范圍內,分配單元大小設置越大,讀寫速度越快,反之則越慢。但是,需要注意的是,分配單元越大,也越有可能造成空間的浪費,因為即便一個文件的大小遠遠小于分配單元大小,也會占用一個完整的分配單元。unit_size必須為硬件存儲設備扇區大小(通常固定為512)的整數倍,且倍數必須是2的冪,比如:1、2、4、8等,可以將unit_size設置為4096(512×8),通常情況下,unit_size的有效范圍為:512 ~ 32768。為了便于使用,避免設置錯誤,也可以將該值設置為0,系統將自動根據存儲器容量選擇一個合適的值。
FAT文件系統又可以細分為FAT12、FAT16、FAT32,它們最明顯的區別就是對分配單元進行尋址的位數不同,分別為12位、16位、32位。例如,對于FAT12,其使用12位地址對分配單元進行尋址,因此,理論上最大只能管理212=4096個分配單元(實際上,部分地址用作它用,管理的分配單元要略小于該值),若每個分配單元的大小為32K,則FAT12管理存儲設備的最大容量為:32K*4096 = 128M。同理,可得到FAT16管理的存儲設備最大容量為2G,雖然FAT32理論上可以管理的容量達到T級別,但實際中,當存儲設備的容量超過32G時,不再建議使用FAT,例如,在Windows中,可以使用NTFS等其它文件系統。用戶無需明確指定使用何種FAT文件系統,系統將根據設備容量自動進行選擇。
對于FAT文件系統,flags標志未使用,設置為0即可。基于此,格式化TF卡的范例程序詳見程序清單11.1。
程序清單11.1 式化范例程序


若未插入TF卡或剛插入TF卡但還未初始化完成,則"/dev/sd0"設備是不存在的,此時,aw_make_fs()函數將返回錯誤號:
-AM_ENODEV。
由于程序在系統啟動后將立即執行,TF卡可能還未及時插入或初始化完成。因此,程序中,當格式化函數的返回值為-AM_ENODEV時,繼續重試。為便于測試,用戶應盡快插入TF卡。格式化操作通常比較費時,作者在使用程序清單11.1所示程序格式化一張8G的TF卡時,耗時約8秒。
格式化僅需執行一次,若本次格式化成功,則后續再進行其它操作時,無需再格式化。特別地,格式化操作會刪除存儲設備上所有的原始數據,應謹慎使用。
在程序清單11.1中,若TF卡還未準備就緒(TF卡未插入或剛插入但還未初始化完成),則不斷重試。為了避免不斷重試,使程序邏輯更加清晰易懂,可以在上電后等待設備就緒后再執行格式化操作,等待設備就緒的函數原型為(fs/aw_blk_dev.h):

該接口是用于等待一個塊設備準備就緒,常見的U盤、SD卡、TF卡等都屬于塊設備(即在物理操作上,數據是以塊為單位,比如:512字節,進行數據的寫入和讀取的,而不是以單個字節為單位)。其中p_name為設備名,例如,"/dev/sd0",timeout用于指定超時時間(單位為系統節拍)。
若設備已就緒,則直接返回AW_OK;若設備未就緒,則具體的行為與timeout的值相關。若timeout的值為AW_WAIT_FOREVER。則程序會阻塞于此,永久等待,直到設備準備就緒;若值為AW_NO_WAIT,則不會阻塞,立即返回錯誤號-AW_EAGAIN;若值為一個正整數,則表示最長的等待時間(單位為系統節拍),在超時時間內設備就緒則返回AW_OK,否則,返回-AW_ETIME表示超時。
優化程序清單11.1,避免不斷重試,僅當設備就緒后再執行格式化操作。范例程序詳見程序清單11.2。
程序清單11.2 格式化范例程序(設備就緒后再執行格式化操作)

2. 掛載設備
為了使用目錄樹結構管理文件,并將文件保存到存儲設備(如TF卡)中,必須將存儲設備掛載到某一目錄。掛載操作的函數原型為:

其中,mnt為掛載點,其為新建的一個目錄結點,使用全路徑表示,比如:"/test",其表示在根目錄下創建了一個名為test的掛載點,后續訪問"/test "目錄即表示訪問本次掛載的存儲設備;dev為存儲設備的名字,如果使用TF卡,則對應的設備名為"/dev/sd0";fs為存儲設備使用的文件系統名,如果使用FAT文件系統,則文件系統名為"vfat";flags為掛載時的一些選項標識,當前無可用標識,預留給后續擴展使用,設置為0即可。返回值為標準的錯誤號,返回AW_OK時,表示掛載成功,否則,表示掛載失敗。掛載TF卡的范例程序詳見程序清單11.3。
程序清單11.3 掛載TF卡范例程序

注意,當前掛載信息不會保存到存儲設備中,相關信息僅保留在內存中,因此,每次重新上電時,都應該執行掛載操作。
掛載完畢后,即在根目錄下創建了一個test掛載點,對于用戶來講,后續即可在該目錄下進行文件相關的操作,例如,創建文件、讀取文件、寫入文件等操作。此外,還可以在該目錄下創建子目錄,這些文件和子目錄信息都存儲在TF卡中,掉電不會丟失。
3. 取消掛載
當設備不再使用時,可以取消該設備的掛載,掛載點將刪除,用戶不可再訪問該目錄。取消掛載的函數原型為:

其中,path為路徑名,可以是設備名(比如:"/dev/sd0"),也可以是掛載點(即掛載時指定的mnt參數,比如:"/test")。flags為掛載時的一些選項標識,當前無可用標識,預留給后續擴展使用,設置為0即可。返回值為標準的錯誤號,返回AW_OK時,表示取消掛載成功,否則,表示取消掛載失敗。取消掛載的范例程序詳見程序清單11.4。
程序清單11.4 取消掛載范例程序


由于在掛載設備時,已經將掛載點和設備名進行了關聯,因此,在取消掛載時,只要知道掛載點和設備名中任何一個信息,均可得到完整的掛載信息,然后取消掛載。在程序清單11.4中,是通過掛載時使用的掛載點取消掛載,也可以通過設備名取消掛載,例如,將第19行代碼中的"/test"修改為"/dev/sd0"。
11.3 文件基本操作
文件相關的操作主要包括打開文件(創建文件)、關閉文件、讀取文件數據、寫入數據等。相關接口的原型詳見表11.2。
表11.2 文件基本操作相關接口
1.打開文件
打開或創建一個文件的函數原型為:

其中,path為包含文件名的完整路徑,如需在test目錄下創建一個fs_test.txt文件,則path應為"/test/fs_test.txt",文件名建議使用8.3格式,即主文件名長度不超過8,擴展名長度不超過3。因為部分文件系統不支持更長的文件名,使用8.3格式的文件名兼容性更好。
oflag指定打開文件的方式,當前支持的打開方式詳見表11.3。
表11.3 打開文件方式(io/aw_fcntl.h)

mode用于控制訪問權限,其類型為mode_t,mode_t是一個整數類型,實際類型與具體平臺相關,通常情況下,其為32位無符號整數。在當前系統中,mode為與POSIX標準接口兼容的參數,目前沒有使用,可以設置為0。在支持該參數的平臺中,其用于控制用戶訪問文件的權限,僅當創建文件時有效,有效位共計9位,每3位為1組,共計3組。3組分別控制3類用戶的權限:當前用戶、組用戶、其它用戶。每組3位分別控制3種權限:讀、寫、執行,相應位為1,表明該類用戶具有相應的權限。各組用戶權限的控制位詳見表11.4。
表11.4 權限控制

由于mode中每3位為一組,而3位二進制數據恰好可以使用1位八進制數據(0 ~ 7)表示。因此,為了便于閱讀,mode的值往往使用八進制表示。如0777(在C語言中,數據前加0表示八進制數據),表示所有用戶都具有讀、寫、執行的權限。為了使應用程序更具有兼容性,可以將mode的值設置為0777。
若文件打開成功,則返回文件的句柄,后續使用該句柄進行文件的讀寫操作。特別地,若返回值為-1,則表示打開文件失敗。如打開test目錄下的fs_test.txt文件(若不存在該文件,則創建該文件)的范例程序詳見程序清單11.5。
程序清單11.5 打開文件范例程序

2. 創建文件
創建文件的函數原型為:

其中,path為包含文件名的完整路徑,注意,創建文件時,需要保證path指定的路徑是有效的,若其父文件夾不存在,則會創建失敗。mode為文件的模式。其本質上等效于:

由此可見,其是以只寫方式打開文件的,若文件不存在,由于使用了O_CREAT標識,則創建文件,若文件已穿在,由于使用了O_TRUNC標識,則會將原文件的內容清空,長度截斷為0,相當于創建了一個新文件。
若文件創建成功,則返回文件的句柄,后續使用該句柄進行文件的讀寫操作。特別地,若返回值為-1,則表示創建文件失敗。如在test目錄下創建一個fs_test2.txt文件的范例程序詳見程序清單11.6。
程序清單11.6 創建文件范例程序

3. 關閉文件
文件打開或創建后,若不再需要使用文件,則必須關閉該文件,文件關閉后,文件相關的數據才會被可靠的寫回硬件存儲設備。關閉文件的函數原型為:

其中,filedes為待關閉文件的句柄,其值是打開文件或創建文件時返回的文件句柄。返回值為錯誤號,若返回AW_OK,則表示關閉文件成功,否則,表示關閉文件失敗。范例程序詳見程序清單11.7。
程序清單11.7 關閉文件范例程序

4. 寫入數據
文件打開后,可以寫入數據至文件中,其函數原型為:

其中,filedes為文件句柄,buf為待寫入數據的緩沖區,nbytes為寫入數據的字節數。返回值為成功寫入的字節數,特別地,若返回值為負值,則表示寫入數據失敗,可能是由于打開文件的方式不對造成的,例如,打開文件時,使用了只讀的方式打開文件;若返回值小于nbytes,則可能是由于存儲設備容量不足造成的。
對于每個打開的文件,系統中都使用了一個與其關聯的整數變量來表示該文件的讀寫位置,其值為相對于文件起始位置的偏移量。文件讀寫位置將決定下一次讀/寫數據時的位置。打開文件時,若未指定O_APPEND標志,則讀寫位置初始為0,否則,讀寫位置在文件結尾,例如,文件大小為10,則讀寫位置的值即為10。每次寫入數據完畢后,都將自動更新讀寫位置至本次寫入數據的尾部,例如,寫入10個數據,則讀寫位置的值將自動增加10,以便下次寫入數據時,緊接著尾部繼續寫入。
例如,打開文件,寫入一串字符串,最后再關閉文件的完整范例程序詳見程序清單11.8。
程序清單11.8 寫入數據范例程序


若程序運行成功,則在TF卡中創建了一個fs_test.txt文件,同時,在文件中寫入了字符串"just for test:0123456789"。為了驗證操作是否成功,可以拔下TF卡,將TF卡通過讀卡器連接到PC上(Windows系統),通過PC查看TF卡中的內容,可以看到TF卡目錄內容和fs_test.txt文件內容詳見圖11.3。

圖11.3 通過PC查看TF卡的內容(1)
5. 讀取數據
文件打開后,可以從文件中讀取數據,其函數原型為:

其中,filedes為文件句柄,buf為保存讀取數據的緩沖區,nbytes為讀取數據的字節數。返回值為成功讀取的字節數,特別地,若返回值為負值,則表示讀取數據失敗,可能是由于打開文件的方式不對造成的,例如,打開文件時,使用了只寫的方式打開文件;若返回值不小于0,但小于nbytes,則表示文件數據不足,已經讀取至文件結尾。
每次讀取數據完畢后,都將自動更新讀寫位置至本次讀取數據的尾部,例如,讀取10個數據,則讀寫位置的值將自動增加10,以便下次讀取數據時,緊接著尾部繼續讀取。
例如,以只讀方式打開之前創建的:
/test/fs_test.txt文件,讀取文件內容,以判斷讀寫是否正確的范例程序詳見程序清單11.9。
程序清單11.9 讀取數據范例程序


6. 改變文件讀寫位置
對于每個打開的文件,都有一個“讀寫位置(相對于文件起始位置的偏移量)”來表示下一次讀/寫數據時的起始位置,其值除在每次讀/寫數據時自動更新外,還可以使用aw_lseek()函數手動改變,aw_lseek()的函數原型為:

其中,filedes為文件句柄,offset為設置的偏移量,whence指定offset偏移量的基準位置。返回值為新的“讀寫位置”。
若whence的值為SEEK_SET,表示offset偏移量是以文件起始位置為基準,就相當于直接設置“讀寫位置”的值為offset。使用SEEK_SET的范例程序詳見程序清單11.10。
程序清單11.10 SEEK_SET范例程序

若whence的值為SEEK_CUR,表示offset偏移量是以當前“讀寫位置”為基準,即將“讀寫位置”的值加上offset作為新的“讀寫位置”,offset可正可負,為正時,增大“讀寫位置”的值,表示“讀寫位置”向文件尾部方向移動,為負時,減小“讀寫位置”的值,表示“讀寫位置”向文件頭部方向移動。使用SEEK_CUR的范例程序詳見程序清單11.11。
程序清單11.11 SEEK_CUR范例程序

若whence的值為SEEK_END,表示offset偏移量是以文件尾部為基準,即將“讀寫位置”的值設置為文件大小加上offset作為新的“讀寫位置”。使用SEEK_END的范例程序詳見程序清單11.12。
程序清單11.12 SEEK_END范例程序

值得注意的是,若移動后的“讀寫位置”大于當前文件大小,則移動的結果將與具體的文件系統相關。通常情況下,“讀寫位置”被重置為當前文件大小,即原文件尾部,部分特殊情況下,也可能會擴充文件的大小。可以通過返回值判斷當前實際的“讀寫位置”。出于兼容性考慮,不建議將“讀寫位置”移動至當前文件的有效范圍之外。
可以修改程序清單11.9所示的程序,在讀取數據前,設定“讀寫位置”為14,然后讀取10個字符,即可僅讀取出字符串:"0123456789",范例程序詳見程序清單11.13。
程序清單11.13 讀取指定位置數據段的范例程序


7. 截斷文件
用于將文件截斷為指定長度,超出長度的內容將被刪除,一般情況下,都通過文件描述符filedes指定要截斷的文件,其函數原型如下:

其中,filedes為文件句柄,length為新的文件長度,如果length小于原文件長度,文件將被截斷。返回值為AW_OK時,表示截斷成功,否則,表示截斷失敗。如將fs_test.txt文件長度截斷為14,以刪除結尾的字符串:"0123456789",則范例程序詳見程序清單11.14。
程序清單11.14 截斷文件范例程序

在程序清單11.14中,截斷一個文件主要分為3步:打開文件、截斷文件、關閉文件。為了簡化截斷文件的操作,AWorks提供了另外一個功能相同的接口,但其通過文件名指定要截斷的文件,使用起來更加便捷,其函數原型為:

其中,path為文件的路徑,length為新的文件長度。用戶無需在截斷文件前打開文件,該函數將在內部打開文件,截斷后關閉文件。如使用該接口,則一行代碼即可實現與程序清單11.14相同的功能,即:

8. 修改文件名
該函數用于修改指定文件的文件名,函數原型為:

其中,oldpath為原文件名,newpath為新文件名。返回值為AW_OK時表示更名成功,否則表示更名失敗。修改
"/test/fs_test.txt"為"/test/fs_test3.txt"的范例程序詳見程序清單11.15。
程序清單11.15 修改文件名范例程序

注意,若newpath指定的文件已存在,則該文件將會被覆蓋。特別地,若newpath與oldpath相同,則函數不做任何處理,直接返回成功。
9. 同步文件
通常情況下,在操作文件的過程中,文件相關的數據并不會立即寫入到存儲設備中,而是保存在內存中,這樣可以在一定程度上提高數據讀寫的效率。在關閉文件時,再將該文件相關的所有數據保存到存儲設備中。在一些比較耗時的文件操作過程中,為了避免中途突然掉電導致數據丟失,也可以通過aw_fsync()函數立即執行回寫操作,使文件相關的數據保存到存儲設備中。這就類似于在編寫一個Word文檔的過程中,需要時常點擊保存按鈕,避免突然掉電導致部分數據丟失。其函數原型為:

其中,filedes為文件句柄。返回值為AW_OK時表示同步成功,否則,表示同步失敗。范例程序詳見程序清單11.16。
程序清單11.16 同步文件范例程序

10. 刪除文件
當一個文件不再使用,可以刪除該文件,刪除指定文件的函數原型為:

其中,path為文件的路徑。返回值為AW_OK時表示刪除成功,否則,表示刪除失敗。范例程序詳見程序清單11.17。
程序清單11.17 刪除文件范例程序

11. 獲取文件狀態信息
對于一個文件,除基本數據外(使用讀寫接口操作的數據),還具有一些與文件相關的其它信息,比如:文件實際大小、文件占用大小、修改時間、訪問權限等。這些信息統一被稱為狀態信息,可以通過aw_fstat()接口獲取文件的狀態信息,其函數原型為:

其中,fildes為文件句柄,buf為文件狀態信息的緩存。返回值為AW_OK時表示獲取成功,否則,表示獲取失敗。文件狀態信息的類型為struct aw_stat,其完整定義如下:
(io/sys/aw_stat.h):

其中的絕大部分成員在當前系統中并未使用,預留給后續擴展。這里僅簡要介紹幾個常用的數據成員:st_mode、st_size、st_atim、st_mtim和st_ctim。
st_mode包含了文件類型及權限相關的信息,權限相關信息與創建文件時指定的mode參數一致。
st_size表示文件的實際長度。通常情況下,文件占用的磁盤空間會大于該值。如在FAT文件系統中,存儲文件的基本單元為“簇”,即使文件小于基本的存儲單元大小,也會占用一個完整的存儲單元。文件占用的磁盤空間可由st_blksize和st_blocks獲得,st_blksize表示存儲單元的大小,st_blocks表示文件占用的存儲單元個數,兩者的乘積則表示文件占用的空間大小。
st_atim、st_mtim、st_ctim表示文件相關的時間,st_atim為最后訪問文件的時間,st_mtim為最后修改文件內容的時間,st_ctim為最后修改文件狀態的時間。在部分平臺中,可能沒有嚴格細分這些時間,而是統一的使用一個時間表示,此時,各個時間的值將是相同的。這些時間的類型為struct timespec,其表示精確日歷時間,即:

精確日歷時間中包含了秒和納秒信息。可以通過將該時間轉換為細分時間,得到年、月、日、時、分、秒等信息。獲取文件狀態信息的范例程序詳見程序清單11.18。
程序清單11.18 獲取文件狀態信息的范例程序


和截斷文件類似,AWorks也提供了另外一個功能相同的接口,可以通過文件名指定要獲取狀態信息的文件,使用起來更加便捷,其函數原型為:

其中,path為文件路徑,buf為文件狀態信息的緩存。返回AW_OK時表示獲取成功,否則,表示獲取失敗。可以使用該接口簡化程序清單11.18的第21、22、29共計3含代碼,使用一行代碼代替,即:

12. 修改文件時間
一個文件的存取和修改時間可以用 aw_utime() 函數更改,其函數原型為:

其中,path為文件的路徑,times為設置的時間。struct aw_utimbuf類型的定義(io/aw_utime.h)如下:

其中,actime表示文件最近一次的訪問時間,modtime表示文件最近一次的內容修改時間,它們的類型均為time_t,time_t是日歷之間類型,即actime和modtime均使用日歷時間表示。返回AW_OK時,表示時間設置成功,否則,表示時間設置失敗。如設置文件訪問時間和文件修改時間均為2016年8月26日09:32:30,則范例程序詳見程序清單11.19。
程序清單11.19 修改文件時間的范例程序



程序中,首先使用aw_utime()修改了文件時間,然后使用aw_stat()獲取文件的狀態信息,以查看時間是否設置成功。
11.4 目錄基本操作
目錄相關的操作主要包括創建目錄、打開目錄、讀取目錄、關閉目錄、刪除目錄等。相關接口的原型詳見表11.5。
表11.5 目錄基本操作相關接口

1. 創建目錄
創建一個空目錄,其函數原型為:

其中,path是待創建目錄的完整路徑,包括待創建目錄的父目錄和新目錄的名字,如需在"/test"目錄下創建一個"newdir"目錄,則path為"/test/newdir",注意,必須保證父目錄已存在,且父目錄下不存在即將創建的同名目錄。mode指定目錄相關的權限,默認使用0777。
返回值為標準的錯誤號,若返回AW_OK,表示新目錄創建成功,否則,表示新目錄創建失敗。如在"/test"目錄下創建一個"newdir"目錄,則范例程序詳見程序清單11.20。
程序清單11.20 創建目錄范例程序

若程序運行成功,則在TF卡中創建了一個newdir目錄。為了驗證操作是否成功,可以拔下TF卡,將TF卡通過讀卡器連接到PC上(Windows系統),通過PC查看TF卡中的內容,TF卡目錄的內容詳見圖11.4 (a),其中新增了newdir目錄,且newdir當前是一個空目錄,詳見圖11.4(b)。

圖11.4 通過PC查看TF卡的內容(2)
可以嘗試在newdir目錄中新建文件,例如:

2. 打開目錄
在目錄操作中,遍歷已存在的一個目錄是一種常見的操作,即遍歷一個目錄下所有的子項(包括文件和子目錄)。遍歷過程主要分為3個步驟:打開目錄、讀取目錄、關閉目錄。
在遍歷一個目錄前,首先需要打開該目錄,其函數原型為:

其中,dirname為目錄名,如需打開根目錄下的test目錄,則其值為"/test"。返回值為指向一個目錄對象的指針,目錄類型struct aw_dir 在io/aw_dirent.h文件中定義,其具體定義用戶無需掌握,僅需保存下該指針,后續使用該指針代表打開的目錄即可,特別地,若返回值為NULL,則表示目錄打開失敗。打開目錄的范例程序詳見程序清單11.21。
程序清單11.21 打開目錄范例程序

3. 讀取目錄
打開目錄后,即可依次讀取該目錄中的各個子項(文件或子目錄),獲得它們的名字等信息,其函數原型為:

其中,dirp為指向目錄對象的指針,可通過打開目錄獲得。返回值為目錄項指針,即為本次讀取的一條目錄項,其類型struct aw_dirent的定義如下:

其中,d_ino為項目序列號,其值為一個整數,每個子項都有一個對應的序列號,在一個目錄中,若共計有10個子項,則各子項的序列號依次為0 ~ 9。d_name為該子項的名字。
打開目錄后首次調用讀取目錄接口,獲得的子項序列號為0,要獲取一個目錄下所有的子項,可以多次調用讀取目錄接口,每次調用結束后,都會將序列號加1,下次讀取時將讀取到下一個子項。特別地,若讀取目錄的返回值為NULL,表示讀取結束。讀取一個目錄下所有子項的范例程序詳見程序清單11.22。
程序清單11.22 讀取目錄范例程序(1)

aw_readdir()接口通過返回值返回一個指向讀取目錄子項的指針,該指針指向的實際內存是由系統內部分配的靜態內存,在多任務環境中,這份內存是共享的,因此,該接口不是線程安全的,例如,在一個任務中讀取了一次目錄,則靜態內存中存放了本次讀取的結果,其地址返回給用戶,用戶通過指針訪問讀取目錄的結果。若在這個過程中,另外一個任務也讀取了一次目錄,則內存中的數據將發生改變,這將覆蓋前一個任務讀取目錄的結果。由此可見,當多個任務同時訪問一個目錄時,必須使用互斥機制。
為此,AWorks提供了另外一個線程安全的接口:aw_readdir_r(),它們在功能上是完全一樣的,唯一的不同是,使用該接口讀取目錄時,讀取結果存儲在用戶提供的一段內存中,其原型為:

其中, dirp為指向目錄對象的指針,可通過打開目錄獲得;entry為存儲讀取結果的緩存,result為一個二維指針,即一個指針的地址,程序執行結束后,指針的值即被設置為指向本次讀取目錄的結果。
若返回值為AW_OK,則讀取成功,否則,讀取失敗。值得注意的是,當目錄讀取未達結尾,成功讀取到一個子項時,由于讀取的結果存儲在entry指向的內存中,因此,result的值被設置為entry(即:*result=entry),當目錄讀取達到結尾時,result的值將被設置為NULL(即:*result=NULL)。范例程序詳見程序清單11.23。
程序清單11.23 讀取目錄范例程序(2)

4. 關閉目錄
若讀取目錄完畢,或不再需要讀取目錄時,則可以關閉目錄,其函數原型為:

其中,dirp為指向目錄對象的指針,可通過打開目錄獲得。返回值為AW_OK時表示關閉成功,否則,表示關閉失敗。
綜合打開目錄、讀取目錄、關閉目錄三個接口,遍歷一個目錄下所有子項的范例程序詳見程序清單11.24。
程序清單11.24 遍歷目錄范例程序


5. 刪除目錄
當一個目錄不再使用,可以刪除該目錄,刪除指定目錄的函數原型為:

其中,path為目錄的路徑。返回值為AW_OK時表示刪除成功,否則,表示刪除失敗。該函數僅可用于刪除一個空目錄,若目錄非空,則刪除失敗。范例程序詳見程序清單11.25。
程序清單11.25 刪除目錄范例程序

11.5 微型數據庫
AWorks提供了一個基于文件系統實現的微型數據庫,用以管理信息記錄,每條記錄由“關鍵字”和“值”兩部分構成,關鍵字可用于記錄的查找、刪除等。微型數據庫是基于哈希表原理實現的,具有簡潔、高效的特點。為了便于理解,本節首先對哈希表進行簡要介紹,然后再介紹微型數據庫的各個接口。
11.5.1 哈希表
在數據存儲應用中,存儲的記錄往往都具有唯一的關鍵字,以便于管理。例如,為了管理學生信息(包含姓名、性別、身高、體重等),會為每個學生分配一個學號,通過學號就可以唯一的定位一個學生,這里的學號即為關鍵字。常見的身份證號也具有類似的作用。
假設需要設計一個信息管理系統,用于管理學生信息,可以將每條學生信息看作一條記錄。
一條記錄包含學號、姓名、性別、身高、體重等信息,可定義與學生記錄對應的結構體類型,詳見程序清單11.26。
程序清單11.26 學生信息類型定義

作為一個信息管理系統,首先要能夠實現學生記錄的存儲,基于文件系統接口可以很容易實現:直接將記錄寫入到文件中即可。增加一條學生記錄的范例程序詳見程序清單11.27。
程序清單11.27 增加一條學生記錄

程序中,假定了存儲學生記錄的文件名為:"/test/students.txt",這就要求系統中,將/test目錄掛載到特定的存儲器,比如SD卡或U盤等。增加一條記錄的實現非常簡單,僅僅是將p_info指向的學生記錄順序的存入了文件尾部,因此,使用這種方法增加學生記錄的效率還是比較高的。
如果使用student_add()函數增加了若干學生記錄,將學生記錄存儲在了文件中,接下來,最常見的操作就是根據學號查詢學生信息。基于學生信息的存儲方式,可以實現一個學生信息查詢函數,范例程序詳見程序清單11.28。
程序清單11.28 根據學號查詢學生記錄

由此可見,程序僅僅從文件頭部順序讀取文件學生記錄,逐一與待查找的學號進行比對,直到查找到與學號完全一致的學生記錄。
上述簡單的范例程序實現了記錄的添加和查找。由于查找學生記錄是采用順序查找的方式,隨著學生記錄的增加,查找效率將逐步降低。例如,一所大學往往有幾萬學生,則使用該系統管理學生記錄時,一次簡單的查找則可能要順序對比上萬次學號,顯然,效率不高。
如何以更高的效率實現查找呢?在查找算法中,非常經典高效的算法是“二分法查找”,按10000條記錄算,最多也只需要比較14次(log210000)。但是,使用“二分法查找”的前提是信息必須有序排列,即要求學生記錄必須按照學號從大到小或從小到大的順序進行存儲,這就導致在添加學生信息時,必須將學生記錄按照學號順序,插入到指定位置,而不能像程序清單11.27那樣,簡單的將信息添加至文件尾部。對于文件操作來講,插入操作是非常繁瑣的,若已經有大量學生記錄按學號順序存儲在文件中,在此基礎上再插入一條記錄到這些記錄的中間某個位置,則需要將其后的所有記錄后移,以預留出一條記錄的存儲空間,這意味著需要將后續所有記錄讀出,再重新寫入到其后的地址中。由此可見,雖然使用這種方法可以提高查找效率,卻犧牲了添加信息的效率。
“順序查找”管理方式犧牲了查找記錄的效率,“二分法查找”犧牲了寫入記錄的效率。能否將二者折中一下呢?“二分法查找”的本質是每次縮小一半的查找范圍,基于縮小查找范圍的思想,可以嘗試縮小每次“順序查找”的范圍。同樣以10000條記錄為例,為了縮小每次“順序查找”的范圍,將記錄分為兩個部分,例如,制定以下規則:學號小于某一值時,作為第一部分存儲在某一文件中;反之,作為第二部分存儲在另外一個文件中。
如此一來,在寫入記錄時,只需要多一條判斷語句,對性能并沒太大影響。而在查找時,只要根據學號判斷出記錄應存儲在哪一個文件中,然后按照順序查找的方式進行查找即可。此時,若用于分界的學號選擇恰當,使兩個部分的學生記錄數量基本相同,則順序查找需要比較的次數就從最大的10000次降低到了約5000次。由此可見,通過一個簡單的方法,將信息分別存儲在兩個文件中,就可以明顯地提高查找效率。
為了繼續提高查找的效率,還可以將記錄分為更多的部分,比如,分成250個部分,序號為0~ 249,若劃分規則恰當,使各個部分的學生記錄數量基本相同,則每個部分的記錄數目就約為40條,此時,順序查找需要比較的次數就僅需約40次即可!示意圖詳見圖11.5。

圖11.5 將記錄分為多個部分
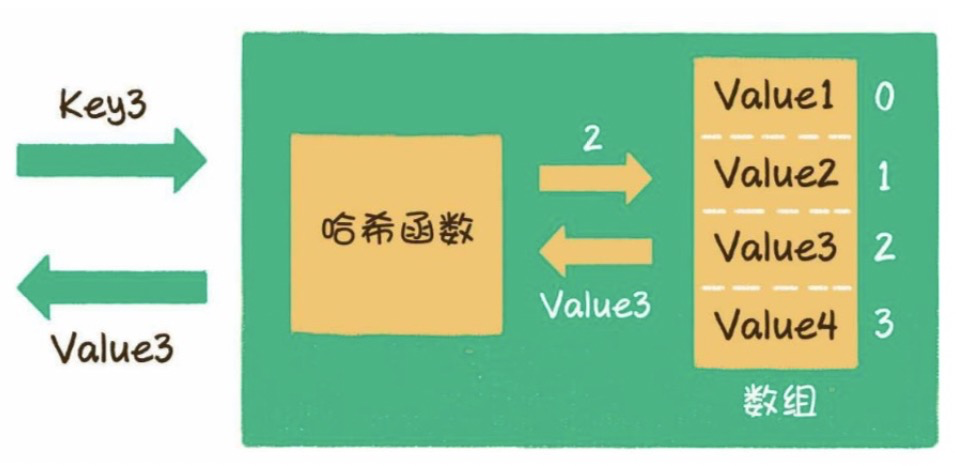
圖11.5可以看作大小為250的“哈希表”,“哈希表”的每個表項對應了一部分記錄。哈希表的核心思想是將一個很大范圍的關鍵字空間(例如,學號為6字節,6字節數據共計48位,其表示的數值空間大小為:248,約280萬億,是一個相當大的范圍),映射到一個較小的空間(范圍序號:0 ~ 249,大小為250)。由于是大范圍映射到小范圍,因此可能有一部分關鍵字(學號)映射到同一個表項中,也就是每個表項可能包含多條記錄。
哈希表的關鍵是確定映射關系,即如何將關鍵字(學號)映射到表項的序號,也就是將所有記錄劃分為多個部分的具體規則。當寫入或查找一條記錄時,可以通過映射關系確定該記錄屬于哪一部分。這個映射關系對應的函數即為“哈希函數”,其作用就是將學號轉換為哈希表的表項序號。例如,假定學號是均勻分布的,則可以將6字節學號直接求和再對250取余,進而得到一個0 ~ 249的數,范例程序詳見程序清單11.29。
程序清單11.29 映射關系——通過學號得到分組索引

db_id_to_idx()函數就是“哈希函數”,哈希函數的結果(分組索引)稱之為“哈希值”。
“哈希函數”是整個哈希表的關鍵,哈希函數應盡可能確保記錄均勻的分布到各個表項中,不能差異太大,極端地,若哈希函數選擇有誤,將所有記錄分布到了一個表項中,那這樣的哈希表將沒有任何意義,因為每次查找記錄又回到了最初的狀態:遍歷所有記錄。
實際應用中,記錄往往是動態管理的,可以隨時動態添加、刪除。因此,每一部分(哈希表的表項)包含的記錄數也會動態增加或減少。為了便于動態管理每一部分的記錄,各部分可以使用鏈表管理該部分中可能存在的多條記錄,示意圖詳見圖11.6,圖中所示的鏈式哈希表結構就是AWorks中微型數據庫原理。

圖11.6 鏈式哈希表結構
11.5.2 微型數據庫接口
前面簡要介紹了哈希表的原理,AWorks提供了一個基于哈希表思想實現的微型數據庫,提供了增加、刪除、查找等接口,相關接口的原型詳見表11.6。
表11.6 微型數據庫接口(aw_db_micro_hash_kv.h)

微型數據庫相關的文件和接口以“aw_db_micro_hash_kv”作為命名空間,其中,“aw_”表示AWorks,“db”表示數據庫(data base),“micro”表示微型,hash_kv表示基于的是hash關鍵字和值的思想。
1. 定義數據庫實例
所有接口的第一個參數均為
aw_db_micro_hash_kv_t類型的指針,用于指向待操作的數據庫實例。該類型的具體定義(如具體包含哪些成員)用戶無需關心,僅需在使用微型數據庫前,使用該類型定義一個數據庫實例即可,例如:

其中,students_db的地址即可作為各個接口p_db參數的實參傳遞。
2. 初始化
在使用數據庫前,需要完成數據庫的初始化,以指定哈希表大小、關鍵字長度、值長度以及存儲整個數據庫的文件名等信息。其函數原型為:

其中,p_db指向待初始化的數據庫實例。size表示哈希表的大小,即表項的數目,如需設計圖11.6所示的哈希表,由于其哈希表的大小為250,則該值應設置為250。key_size為關鍵字長度,例如,以學號為關鍵字,由于學號的長度為6字節,則該值應設置為6。
value_size表示記錄中值的長度,以學生記錄為例,一條學生記錄包含學號、姓名、性別、身高、體重等信息。最初的學生記錄對應的結構體類型詳見程序清單11.26。在使用微型數據庫時,關鍵字和值是不同的兩個部分,均會被存儲到文件中。因此,可以將關鍵字學號分離出來,剩余的信息作為一條學生記錄的“值”。詳見程序清單11.30。
程序清單11.30 學生記錄信息類型(不包括關鍵字——學號)

基于此,value_size的值則應設置為:sizeof(student_t)。
pfn_hash用于指定一個哈希函數,其作用是將關鍵字轉換為一個哈希值,哈希值即為哈希表的索引。其類型aw_db_micro_hash_kv_func_t定義如下:

該類型為一個函數指針類型,其指向函數的形參為關鍵字,返回值為哈希值(類型為無符號整數),哈希值將作為哈希表的索引。通過對哈希表的介紹可知,哈希函數的選擇直接決定了記錄的分布,必須盡可能地確保所有記錄均勻地分布在各個表項中。不同的關鍵字數據具有不同的分布特性,因此,哈希函數需要由用戶根據實際情況提供,簡單的實現可以將關鍵字按字節求和后再對哈希表大小取余,詳見程序清單11.31。
程序清單11.31 簡易的哈希函數實現

其中,函數名hash_func_id_to_idx即可作為pfn_hash的實參傳遞。
file_name用于指定存儲該數據庫信息及所有記錄的文件名,若一個系統中存在多個數據庫(定義了多個數據庫實例),則在初始化各個數據庫時,為各個數據庫指定的文件名應該不同,以使各個數據庫使用不同的文件存儲數據。在程序清單11.27和程序清單11.28所示的簡易范例程序中,每次寫入記錄或查找記錄前,都會執行一次打開文件操作,并在寫入或查找結束后關閉文件。在實際應用中,可能會頻繁的執行寫入、查找等操作,這樣就會導致頻繁的打開、關閉文件,降低了程序運行的效率,為此,AWorks提供的數據庫僅僅在初始化時打開文件,后續其它操作均無需再執行打開文件操作。若初始化時指定的文件名對應文件已經存在,則僅僅打開該文件,然后再該文件的基礎上進行記錄的管理(添加、刪除等);若文件名對應文件不存在,則創建該文件,以建立一個全新的數據庫(數據庫中沒有任何有效記錄)。初始化數據庫的范例程序詳見程序清單11.32。
程序清單11.32 初始化數據庫范例程序

3. 增加一條記錄
該函數用于向數據庫中增加一條記錄,其函數原型為:

其中,p_db指向已經初始化的數據庫實例。p_key指向本次增加記錄的關鍵字,其長度必須與初始化指定的key_size一致。p_value指向本次增加記錄的具體“值”。例如,待增加一條學生記錄,其各項信息詳見表11.7。
表11.7 待增加的學生信息舉例
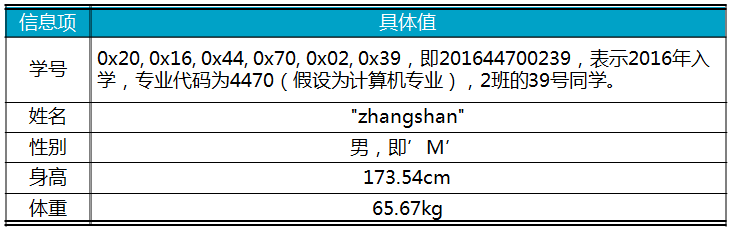
則向數據庫中增加該學生記錄的范例程序詳見程序清單11.33。
程序清單11.33 增加記錄范例程序

4. 根據關鍵字查找記錄
向數據庫中添加記錄后,可以根據關鍵字查找記錄的詳細信息,查找記錄的函數原型為:

其中,p_db指向數據庫實例。p_key為輸入參數,指向本次查找記錄的關鍵字,關鍵字長度必須與初始化時指定的key_size一致。p_value為輸出參數,返回本次查找到的記錄。
例如,若使用程序清單11.33所示的范例程序增加了一條學生記錄,作為測試,可以使用查找記錄接口查找學號為201644700239的記錄,以查看其對應的“值”信息是否與寫入的信息一致。范例程序詳見程序清單11.34。
程序清單11.34 根據關鍵字查找記錄的范例程序

程序中,為了避免使用aw_kprintf()打印浮點數,將身高和體重分為整數部分和小數部分打印,最終等效于保留2位小數的浮點數打印效果。
5. 刪除一條記錄
通過該接口可以刪除數據庫中的一條記錄,其函數原型為:

其中,p_db指向數據庫實例。p_key指向本次需要刪除記錄的關鍵字,關鍵字長度必須與初始化時指定的key_size一致。
例如,若使用程序清單11.33所示的范例程序增加了一條學生記錄,作為測試,可以將學號為201644700239的記錄刪除。范例程序詳見程序清單11.35。
程序清單11.35 根據關鍵字刪除記錄的范例程序

使用程序清單11.35所示程序刪除記錄后,若再查找學號為201644700239的記錄,將會查找失敗。
6. 解初始化
與數據庫初始化函數對應。當暫時不使用一個數據庫時,可以執行該函數,以釋放相關資源。注意,解初始化后,數據庫中已經存儲的內容保持不變。解初始化函數的原型為:

其中,p_db指向數據庫實例。例如,在一次應用中,添加了100個學生記錄,添加結束后,暫時不再使用該數據庫,則可以解初始化該數據庫,范例程序詳見程序清單11.36。
程序清單11.36 解初始化范例程序

在初始化函數的介紹中提到,為了避免頻繁的打開文件和關閉文件,在初始化時打開了文件,使得在添加記錄、刪除記錄、查找記錄時,無需再打開文件。與初始化函數對應,在解初始化函數中,關閉了文件。關閉文件后,文件中的內容保持不變。如需再次使用該數據庫,則應該重新執行一次初始化操作。
上面介紹了各個接口的使用方法,基于這些接口,可以實現一個學生記錄管理的綜合范例程序,詳見程序清單11.37。
程序清單11.37 微型數據庫綜合范例程序






測試程序主要由test_db_micro_hash_kv()完成,在aw_min()主程序中,僅僅是簡單調用了該函數。在test_db_micro_hash_kv()函數中,首先初始化了一個數據庫,然后向其中添加了100個學生記錄(為了快捷產生這些記錄,以隨機數的方式自動生成,隨機數無實際意義,僅供測試使用。同時,為了保證添加的學生學號唯一,在添加記錄前,通過搜索接口查看是否存在該學號的學生,若存在,則不再重復添加)。接著測試了查找接口,查找最后添加的學生記錄。然后測試刪除接口,刪除了最后添加的學生記錄,刪除成功后,再次查找將會失敗。最后,所有操作執行完畢,解初始化數據庫。
-
周立功
+關注
關注
38文章
130瀏覽量
37630 -
AWorks
+關注
關注
1文章
16瀏覽量
5706
原文標題:AWorks軟件篇 — 文件系統
文章出處:【微信號:ZLG_zhiyuan,微信公眾號:ZLG致遠電子】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
新書創作談:周立功教授數十年之心血力作《程序設計與數據結構》
【完整資料】《程序設計與數據結構》周立功數十年心血力作
數據結構的幾個重要知識點
數據結構鏈表的基本操作
GPIB命令的數據結構
什么是數據結構
《程序設計與數據結構》——框架與重用

什么是數據結構?為什么要學習數據結構?數據結構的應用實例分析
算法和數據結構基礎知識分享(中)
算法和數據結構基礎知識分享(下)
NetApp的數據結構是如何演變的

epoll的基礎數據結構





 工商網監
工商網監
評論