") 我們目前在機(jī)器學(xué)習(xí)方面的進(jìn)展有多可靠?
我們目前在機(jī)器學(xué)習(xí)方面的進(jìn)展有多可靠?
導(dǎo)語:可以這樣說,對(duì)機(jī)器學(xué)習(xí)的進(jìn)展進(jìn)行正確評(píng)估是很微妙的。畢竟,學(xué)習(xí)算法的目標(biāo)是生成一個(gè)能夠很好地泛化到不可見數(shù)據(jù)中的模型。因此,為了理解當(dāng)前機(jī)器學(xué)習(xí)進(jìn)展的可靠性如何,加州大學(xué)伯克利分校(UC Berkeley)和麻省理工學(xué)院(MIT)的科學(xué)家們?cè)O(shè)計(jì)并開展了一種新的再現(xiàn)性研究。其主要目標(biāo)是衡量當(dāng)代分類器從相同分布中泛化到新的、真正不可見數(shù)據(jù)中的程度如何。
可以這樣說,機(jī)器學(xué)習(xí)目前主要是由聚焦于一些關(guān)鍵任務(wù)的改進(jìn)上的實(shí)驗(yàn)性研究所主導(dǎo)的。但是,性能表現(xiàn)最佳的模型的令人印象深刻的準(zhǔn)確性是值得懷疑的,因?yàn)橛孟嗤臏y(cè)試集來選擇這些模型已經(jīng)很多年了。為了理解過度擬合(overfitting)的危險(xiǎn),我們通過創(chuàng)建一個(gè)真正看不見的圖像的新測(cè)試集來衡量CIFAR-10分類器的準(zhǔn)確性。盡管我們確保新測(cè)試集盡可能接近原始數(shù)據(jù)分布,但我們發(fā)現(xiàn)大部分深度學(xué)習(xí)模型的精確度大幅下降(4%至10%)。然而,具有較高原始精確度的較新模型顯示出較小的下降和較好的整體性能,這表明這種下降可能不是由于基于適應(yīng)性的過度擬合造成的。相反,我們將我們的結(jié)果視為證據(jù),證明當(dāng)前的準(zhǔn)確性是脆弱的,并且易受數(shù)據(jù)分布中的微小自然變化的影響。
在過去五年中,機(jī)器學(xué)習(xí)已經(jīng)成為一個(gè)決定性的實(shí)驗(yàn)領(lǐng)域。在深度學(xué)習(xí)領(lǐng)域大量研究的推動(dòng)下,大部分已發(fā)表的論文都采用了一種范式,即一種新的學(xué)習(xí)技術(shù)出現(xiàn)的主要理由是其在幾個(gè)關(guān)鍵基準(zhǔn)上的改進(jìn)性性能表現(xiàn)。與此同時(shí),對(duì)于為什么現(xiàn)在提出的技術(shù)相對(duì)于之前的研究來說具有更可靠的改進(jìn),幾乎沒有什么解釋。相反,我們的進(jìn)步意識(shí)很大程度上取決于少數(shù)標(biāo)準(zhǔn)基準(zhǔn),如CIFAR-10、ImageNet或MuJoCo。這就提出了一個(gè)關(guān)鍵問題:
我們目前在機(jī)器學(xué)習(xí)方面的進(jìn)展有多可靠?
可以這樣說,對(duì)機(jī)器學(xué)習(xí)的進(jìn)展進(jìn)行正確評(píng)估是很微妙的。畢竟,學(xué)習(xí)算法的目標(biāo)是生成一個(gè)能夠很好地泛化到看不見的數(shù)據(jù)中的模型。由于我們通常無法訪問真實(shí)數(shù)據(jù)分布,因此替代性地,我們會(huì)在單獨(dú)的測(cè)試集上評(píng)估一個(gè)模型的性能。而只要我們不使用測(cè)試集來選擇我們的模型,這就確實(shí)是一個(gè)有原則的評(píng)估協(xié)議。
圖1:從新的和原始的測(cè)試集中進(jìn)行的類均衡隨機(jī)抽取結(jié)果。
不幸的是,我們通常對(duì)相同分布中的新數(shù)據(jù)的訪問受限。現(xiàn)如今,人們已經(jīng)普遍接受在整個(gè)算法和模型設(shè)計(jì)過程中多次重復(fù)使用相同的測(cè)試集。這種做法的示例非常豐富,包括在單一發(fā)布產(chǎn)品中調(diào)整超參數(shù)(層數(shù)等),并且在其他研究人員的各種發(fā)布產(chǎn)品的研究上進(jìn)行架構(gòu)構(gòu)建。盡管將新模型與以前的結(jié)果進(jìn)行比較是自然而然的愿望,但顯然目前的研究方法破壞了分類器獨(dú)立于測(cè)試集的關(guān)鍵性假設(shè)。這種不匹配帶來了明顯的危險(xiǎn),因?yàn)檠芯可鐓^(qū)可以很容易地設(shè)計(jì)一些模型,但這些模型只能在特定的測(cè)試集上運(yùn)行良好,實(shí)際上卻不能推泛化到新的數(shù)據(jù)中。
因此,為了理解當(dāng)前機(jī)器學(xué)習(xí)進(jìn)展的可靠性如何,我們?cè)O(shè)計(jì)并開展了一種新的再現(xiàn)性研究。其主要目標(biāo)是衡量當(dāng)代分類器從相同分布中泛化到新的、真正不可見的數(shù)據(jù)中的程度如何。我們聚焦于標(biāo)準(zhǔn)的CIFAR-10數(shù)據(jù)集,因?yàn)樗耐该餍詣?chuàng)建過程使其特別適合于此任務(wù)。而且,CIFAR-10現(xiàn)在已經(jīng)成為近10年來研究的熱點(diǎn)。由于這個(gè)過程的競(jìng)爭(zhēng)性,這是一個(gè)很好的測(cè)試案例,用于調(diào)查適應(yīng)性是否導(dǎo)致過度擬合。
過度擬合
我們的實(shí)驗(yàn)是否顯示過度擬合?這可以說是對(duì)我們的結(jié)果進(jìn)行解釋時(shí)的主要問題。準(zhǔn)確地說,我們首先定義過度擬合的兩個(gè)概念:
?訓(xùn)練集過度擬合:量化過度擬合的一種方法是確定訓(xùn)練精確度和測(cè)試精確度之間的差異。需要注意的是,我們實(shí)驗(yàn)中的深度神經(jīng)網(wǎng)絡(luò)通常達(dá)到100%的訓(xùn)練精確度。所以這種過度擬合的概念已經(jīng)出現(xiàn)在現(xiàn)有的數(shù)據(jù)集上。
?測(cè)試集過度擬合:過度擬合的另一個(gè)概念是測(cè)試精確度和基礎(chǔ)數(shù)據(jù)分布的精確度之間的差距。通過將模型設(shè)計(jì)選擇適配于測(cè)試集,我們關(guān)心的是我們隱含地將模型擬合到測(cè)試集。然后,測(cè)試精確度作為在真正看不見的數(shù)據(jù)上性能的精確衡量,將失去其有效性。
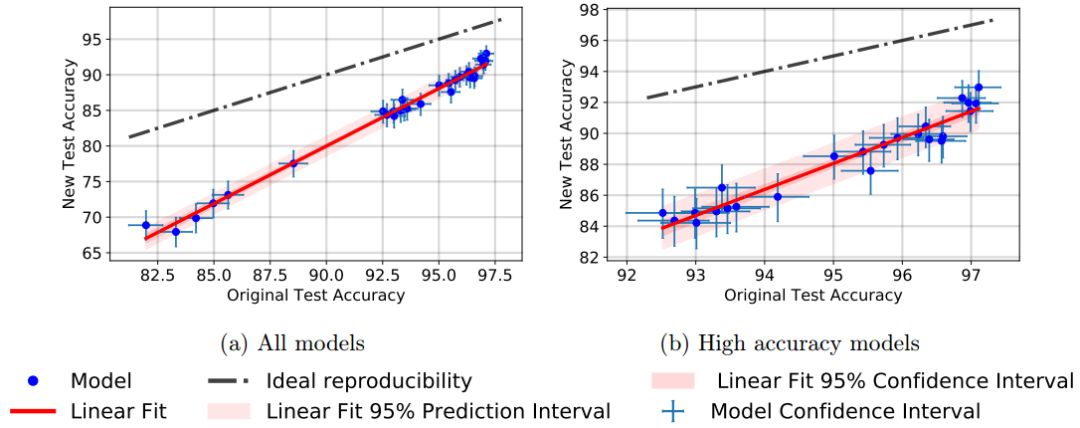
圖2:新測(cè)試集的模型精確度VS原始測(cè)試集的模型精確度
由于機(jī)器學(xué)習(xí)的總體目標(biāo)是泛化到看不見的數(shù)據(jù)中,所以我們認(rèn)為,第二個(gè)概念,通過測(cè)試集自適應(yīng)性事物過度擬合更為重要。令人驚訝的是,我們的研究結(jié)果顯示在CIFAR-10上沒有出現(xiàn)這種過度擬合的跡象。盡管在這個(gè)數(shù)據(jù)集上有多年的競(jìng)爭(zhēng)自適應(yīng)性,但真正持有的數(shù)據(jù)并沒有停滯不前。事實(shí)上,在我們的新測(cè)試集中,性能最好的模型要比更多已建立的基線更具優(yōu)勢(shì)。盡管這種趨勢(shì)與通過適應(yīng)性的過度擬合所表明的相反。雖然一個(gè)確鑿的圖片需要進(jìn)一步的復(fù)制實(shí)驗(yàn),但我們認(rèn)為我們的結(jié)果是支持基于競(jìng)爭(zhēng)的方法來提高精確度分?jǐn)?shù)的。
我們注意到,可以閱讀Blum和Hardt的Ladder算法的分析來支持這一說法。事實(shí)上,他們表明,通過加入對(duì)標(biāo)準(zhǔn)機(jī)器學(xué)習(xí)競(jìng)賽的小修改,可以避免那種通過積極的適應(yīng)性來實(shí)現(xiàn)的過度擬合。我們的結(jié)果顯示,即使沒有這些修改,基于測(cè)試誤差的模型調(diào)整也不會(huì)導(dǎo)致標(biāo)準(zhǔn)數(shù)據(jù)集的過度擬合。
分布位移(distribution shift)
盡管我們的結(jié)果不支持基于適應(yīng)性的過度擬合的假設(shè),但仍需要對(duì)原始精確度分?jǐn)?shù)和新精確度分?jǐn)?shù)之間的顯著差距進(jìn)行解釋。我們認(rèn)為這種差距是原始CIFAR-10數(shù)據(jù)集與我們新測(cè)試集之間的小分布位移的結(jié)果。盡管我們努力復(fù)制CIFAR-10的創(chuàng)建過程,但這種差距很大,影響了所有模型,從而出現(xiàn)這種情況。通常,對(duì)于數(shù)據(jù)生成過程中的特定變化(例如,照明條件的變化)或?qū)剐原h(huán)境中的最壞情況攻擊,我們就會(huì)研究分布位移。我們的實(shí)驗(yàn)更加溫和,并沒有帶來這些挑戰(zhàn)。盡管如此,所有模型的精確度下降了4-15%,誤差率的相對(duì)增加高達(dá)3倍。這表明目前的CIFAR-10分類器難以泛化到圖像數(shù)據(jù)的自然變化中。
未來的研究
具體的未來實(shí)驗(yàn)應(yīng)該探索競(jìng)爭(zhēng)方法在其他數(shù)據(jù)集(例如ImageNet)和其他任務(wù)(如語言建模)上是否同樣對(duì)過度擬合具有復(fù)原性。這里的一個(gè)重要方面是確保新測(cè)試集的數(shù)據(jù)分布盡可能地接近原始數(shù)據(jù)集。此外,我們應(yīng)該了解什么類型的自然發(fā)生的分布變化對(duì)圖像分類器是具有挑戰(zhàn)性的。
更廣泛地說,我們將我們的結(jié)果看作是對(duì)機(jī)器學(xué)習(xí)研究進(jìn)行更全面評(píng)估的動(dòng)機(jī)。目前,主要的范式是提出一種新的算法并評(píng)估其在現(xiàn)有數(shù)據(jù)上的性能。不幸的是,這些改進(jìn)在多大程度上可以進(jìn)行廣泛適用,人們往往知之甚少。為了真正理解泛化問題,更多的研究應(yīng)該收集有洞察力的新數(shù)據(jù)并評(píng)估現(xiàn)有算法在這些數(shù)據(jù)上的性能表現(xiàn)。由于我們現(xiàn)在在開源代碼庫(kù)中擁有大量預(yù)先注冊(cè)的分類器,因此此類研究將符合公認(rèn)的統(tǒng)計(jì)有效研究標(biāo)準(zhǔn)。重要的是要注意區(qū)分機(jī)器學(xué)習(xí)中的當(dāng)前可再現(xiàn)性性努力,其通常集中在計(jì)算的再現(xiàn)性上,即在相同的測(cè)試數(shù)據(jù)上運(yùn)行發(fā)布的代碼。相比之下,像我們這樣的泛化實(shí)驗(yàn),通過評(píng)估分類器在真實(shí)新數(shù)據(jù)(類似于招募新參與者進(jìn)行醫(yī)學(xué)或心理學(xué)的再現(xiàn)性實(shí)驗(yàn))上的性能表現(xiàn)來關(guān)注統(tǒng)計(jì)再現(xiàn)性。
-
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8430瀏覽量
132858 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5511瀏覽量
121356
原文標(biāo)題:伯克利與MIT最新研究:「CIFAR-10分類器」能否泛化到CIFAR-10中?
文章出處:【微信號(hào):CAAI-1981,微信公眾號(hào):中國(guó)人工智能學(xué)會(huì)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
深度學(xué)習(xí)在自然語言處理方面的研究進(jìn)展
想學(xué)習(xí)一些機(jī)器人控制方面的工作,要學(xué)習(xí)什么內(nèi)容!
什么是機(jī)器學(xué)習(xí)? 機(jī)器學(xué)習(xí)基礎(chǔ)入門
機(jī)器學(xué)習(xí)簡(jiǎn)單運(yùn)用方面的基礎(chǔ)知識(shí)

面向認(rèn)知的多源數(shù)據(jù)學(xué)習(xí)理論和算法研究進(jìn)展
攜程信息安全部在web攻擊識(shí)別方面的機(jī)器學(xué)習(xí)實(shí)踐之路
介紹Facebook在機(jī)器學(xué)習(xí)方面的軟硬件基礎(chǔ)架構(gòu),來滿足其全球規(guī)模的運(yùn)算需求
袁進(jìn)輝:分享了深度學(xué)習(xí)框架方面的技術(shù)進(jìn)展
我們對(duì)目前機(jī)器學(xué)習(xí)進(jìn)展的衡量有多可靠?
如果要從事機(jī)器學(xué)習(xí)方面的研發(fā),可以按照以下幾個(gè)步驟學(xué)習(xí)
工業(yè)機(jī)器人目前面臨哪些技術(shù)方面的問題
機(jī)器學(xué)習(xí)框架里不同層面的隱私保護(hù)
2020 年十大機(jī)器學(xué)習(xí)研究進(jìn)展匯總
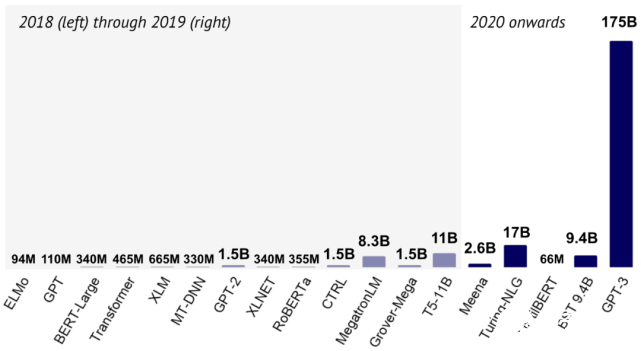
2020年十大機(jī)器學(xué)習(xí)研究進(jìn)展






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論