 神經網絡是在許多用例中提供了精確狀態的機器學習算法
神經網絡是在許多用例中提供了精確狀態的機器學習算法
神經網絡是在許多用例中提供了精確狀態的機器學習算法。但是,很多時候,我們正在構建的網絡的準確性可能并不令人滿意,也可能不會讓我們在數據科學競賽中處于領先地位。因此,我們一直在尋找更好的方法來提高我們的模型的性能。有很多技術可以幫助我們實現這一點。
檢查過度擬合
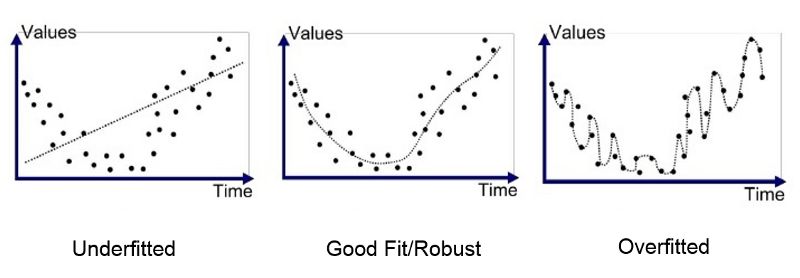
確保你的神經網絡在測試數據上表現良好的第一步是驗證你的神經網絡不會過度擬合。什么是過度擬和?當模型開始從訓練數據中記憶數值而不是從訓練數據中學習時,就會發生過擬合。因此,當您的模型遇到以前從未見過的數據時,它不能很好地執行它們。
為了讓你更好的理解,讓我們來打個比方。我們都會有一個善于記憶的同學,假設數學考試即將來臨。你和你擅長記憶的朋友從課本上開始學習。你的朋友決定背誦課本上的每個公式、問題和答案,但你比他聰明,所以你決定建立在直覺的基礎上,解決問題,學習這些公式是如何發揮作用的。測試一天到來,如果試卷的問題是采取直接從課本,那么你的朋友會做得更好,但如果問題涉及新的應用知識,你會做得更好,而你依賴記憶的朋友會失敗得很慘。
如何鑒別你的模型是否過度擬和?你只需要交叉檢驗訓練準確度和測試準確度如果訓練準確度遠遠高于測試準確度,那么你就可以假設你的模型過度擬和了。你也可以將預測點畫在圖表上來驗證。以下是一些防止過度擬和的技術:
數據規范化(L1或L2)。
退出——在神經元之間隨機刪除連接,迫使網絡找到新的路徑并進行歸納。
早期停止——加速神經網絡的訓練,減少測試集的誤差。
超參數調優
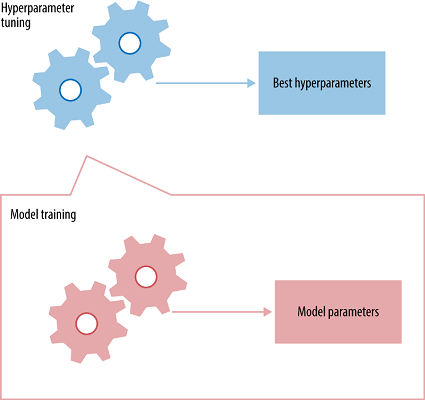
超參數是必須初始化到網絡的值,這些值是神經網絡在訓練時無法學習到的。例如:在卷積神經網絡中,一些超參數是內核大小、神經網絡中的層數、激活函數、丟失函數、使用的優化器(梯度下降、RMSprop)、批處理大小、要訓練的周期數等。
每一個神經網絡都將有其最好的超參數集,以達到致最大的準確性。你可能會問,“有這么多超參數,我如何選擇?”不幸的是,沒有直接的方法來辨別出每一個神經網絡的最佳超參數集,所以它主要是通過反復試驗得到的。但是,對于下面提到的超參數有一些實踐技巧:
學習速率
選擇一個最優的學習速率很重要,因為它決定了你的網絡是否收斂到全局最小值。選擇一個高學習率幾乎不會讓你達到全局最優,因為你很有可能超過它。因此,你總是在全局最小點附近,但從不收斂于它。選擇一個低的學習速率可以幫助神經網絡收斂到全局最小值,但是需要花費大量的時間。因此,你必須對網絡進行長時間的訓練。一個低的學習速率也會使網絡容易陷入局部最小值,例如,網絡會收斂到局部最小值,由于學習速率小,無法從中掙脫出來。因此,在設置學習率時必須小心。
網絡架構
在所有的測試用例中,沒有一個永遠帶來高準確性的標準的體系結構。你必須進行實驗,嘗試不同的架構,從結果中獲得推斷,然后再嘗試。我的一個建議是使用經過驗證的架構,而不是構建自己的架構。例如:對于圖像識別任務,你可以使用VGG net, Resnet,谷歌的Inceptionnetwork等。這些都是開源的,并且已經被證明非常準確,因此,你可以復制他們的架構并根據你的目的調整它們。
優化器和損失函數
有無數可供選擇的選項。事實上,你甚至可以在必要時定義自定義損失函數。常用的優化方法有RMSprop、Stochastic Gradient Descent和Adam。這些優化器似乎適用于大多數用例。如果你的用例是一個分類任務,那么通常使用的損失函數是分類交叉熵。如果您正在執行一個回歸任務,均方誤差是常用的損失函數。可以自由地嘗試這些優化器的超參數,也可以使用不同的優化器和損失函數。
批處理大小和epoch的數量
同樣,對于所有用例來說,沒有標準的批處理大小和epoch數量。你必須嘗試不同的方法。在一般的實踐中,批量大小的值設置為8、16、32,而epoch的數量取決于開發人員的偏好和他擁有的計算能力。
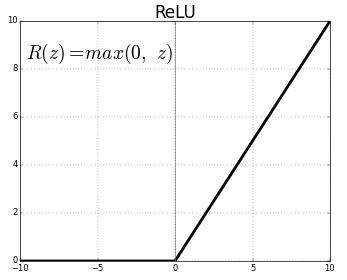
激活函數——激活函數將非線性函數的輸入映射到輸出。激活函數非常重要,且選擇正確的激活函數有助于你的模型更好地學習。如今,糾正線性單元(ReLU)是使用最廣泛的激活函數,因為它解決了梯度消失的問題。早些時候S狀彎曲和雙曲正切是使用最廣泛的激活函數。但是,他們遭受了梯度消失的問題,例如:梯度反向傳播的過程中,當他們到達開始層時梯度的數值就開始減少。這阻止了神經網絡擴展到更大的規模與更多的層。ReLU能夠克服這個問題,從而使神經網絡能有更大的規模。
整體算法
如果單個神經網絡并不像你預期中那么準確,你可以創建一個神經網絡的集合并結合它們的預測能力。你可以選擇不同的神經網絡架構,在數據的不同部分對它們進行訓練,并對它們進行集成,使用它們的集體預測能力來獲得測試數據的高準確度。假設,你正在構建一個貓與狗的分類器,0表示貓,1表示狗。當將不同的貓和狗的分類器組合在一起時,基于各個分類器之間的皮爾遜相關性,集成算法的精度得到了提高。讓我們來看一個例子,取3個模型并測量它們各自的準確性:
Ground Truth: 1111111111Classifier 1: 1111111100 = 80% accuracyClassifier 2: 1111111100 = 80% accuracyClassifier 3: 1011111100 = 70% accuracy
三種模型的皮爾遜相關系數很高。因此,組合它們并不能提高準確性。如果我們使用多數投票對上述三個模型進行組合,我們將得到以下結果:
Ensemble Result: 1111111100 = 80% accuracy
現在讓我們來看看皮爾遜相關系數很低的3個模型:
Ground Truth: 1111111111Classifier 1: 1111111100 = 80% accuracyClassifier 2: 0111011101 = 70% accuracyClassifier 3: 1000101111 = 60% accuracy
當我們把這三個模型合在一起時,我們得到了以下的結果:
Ensemble Result: 1111111101 = 90% accuracy
由此可見,低皮爾遜相關系數的模型組合能夠得出比高皮爾遜相關系數組合更精確的結果。
數據不足的問題
在執行上述所有技巧之后,如果你的模型在測試數據集中仍然沒有表現得更好,那么可以將其歸因于缺少訓練數據。在許多用例中,可用的培訓數據的數量是有限的。如果你無法收集更多的數據,那么可以使用數據增強技術。

如果你正在處理一個圖像數據集,您可以通過剪切圖像、翻轉圖像、隨機剪切圖像等方式來增加訓練數據的新圖像。這可以為神經網絡提供不同的示例。
-
神經網絡
+關注
關注
42文章
4772瀏覽量
100792 -
機器學習
+關注
關注
66文章
8419瀏覽量
132674
原文標題:【譯】如何提升神經網絡的表現
文章出處:【微信號:AI_shequ,微信公眾號:人工智能愛好者社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【案例分享】基于BP算法的前饋神經網絡
如何設計BP神經網絡圖像壓縮算法?
卷積神經網絡模型發展及應用
卷積神經網絡簡介:什么是機器學習?
不可錯過!人工神經網絡算法、PID算法、Python人工智能學習等資料包分享(附源代碼)
為什么使用機器學習和神經網絡以及需要了解的八種神經網絡結構






 工商網監
工商網監
評論