 關于可編程可伸縮的雙域模乘加器研究與設計
關于可編程可伸縮的雙域模乘加器研究與設計
0 引言
公鑰密碼體制以其獨特的理論依據很好地填補了密碼領域的空缺。它在密鑰分發、身份認證等方面具有明顯優勢。1985年Neal Koblitz和Victor Miller分別獨立提出了橢圓曲線在密碼學中的應用。作為三大公鑰密碼體制之一,橢圓曲線密碼體制具有相同粒度更難破解、單位比特安全強度更大的特點。
橢圓曲線密碼運算在底層結構設計時,主要包括模加減、模乘和模除、模逆。其中,模除和模逆運算最為復雜,通常通過轉換運算坐標來降低其實現復雜度,且使用頻率不是很高。而模乘和模加減運算使用更為頻繁。如何高效率、低成本地實現模乘模加減是當前的一個研究熱點。1985年Montmery提出了一種全新的模乘算法,他將普通模乘的運算轉換到Montgomery剩余類中進行,其所有大數均規約到了剩余類中,計算大幅度簡化。Montgomery模乘算法是目前最為常見的模乘實現方法,但傳統的算法具有算法粒度固定、關鍵運算路徑過長的缺陷,而且不支持雙有限域運算。文獻[2]提出了一種Montgomery模乘算法在高基陣列上的優化算法。文獻[3]提出了一種基于CIOS模乘的可重構可伸縮的雙域模乘加器,將模乘與模加減糅合,但面積不夠優化。文獻[4]提出了一種改進的基于FIOS類型Montgomery雙域模乘器,流水線切割較為合理。本文在前人的研究基礎上,通過對雙域模乘和模加減單元進行分析,以FIOS算法為基礎,重新設計了一種MAS(multiplication- addition-subtraction)結構,將模乘和模加減進行可重構糅合,一定程度上降低了單元面積,又可以靈活地適配各種長度的模運算,從而適應各種不同的應用場景和任務。同時對模乘的關鍵運算路徑進行了流水線設計,相對于傳統的模乘算法,運算頻率有一定的提高。
1 模乘加算法分析
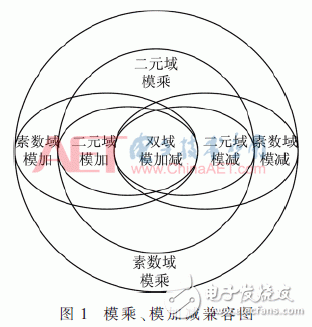
模乘、模加減和模逆運算構成了ECC密碼算法中的主體運算。設計模乘模加減功能復用的模乘加單元結構,可以提高結構利用率,減少多余連線資源,進而降低總體面積。本文對雙域模加減算法及雙域模乘算法進行了分析。根據兩者運算的原理可知,模乘對模加減無論是在算法層次還是結構層次上具有較為完整的兼容性。兼容關系如圖1所示。
本文針對現有模乘和模加算法進行改進,設計了如下所示的模乘加算法。
算法1 適于硬件實現的FIOS模乘加改進算法
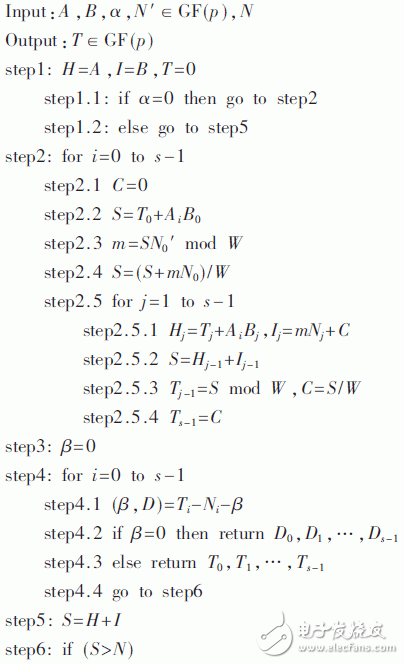
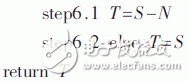
算法將輸入的大整數A、B、N按照32 bit字長進行分解運算[4],字數為s,算法具有內外兩層循環,對操作數按32 bit字長進行循環掃描,其中內循環完成32 bit數據的乘和64 bit的加法運算,外循環完成對被乘數的遍歷掃描。算法在GF(2n)域與GF(p)域上實現過程大致相同,區別在于GF(2n)域上的加法是異或操作,乘法則為多項式乘法,并且循環結束后直接輸出結果,而不需要與不可約多項式進行比較。
算法初始有一個信號a,用于判斷運算模加減或者模乘。如果a=0進入step2運行模乘,否則進入step5運行模加減,而此時的加法不再是模乘中的64 bit加,而是3個64 bit加的級聯,即為192 bit加。此處即為本文提出的模乘模加糅合結構的關鍵所在。運算過程有3個for循環,其中前兩個是嵌套在一起內外循環。設計的流水運算單元也是主要用來完成這部分嵌套循環。在硬件設計過程中step2.2、2.3、2.4作為一部分結構Y。step2.5.1、2.5.2、2.5.3、2.5.4作為重復的結構X出現在硬件結構中。
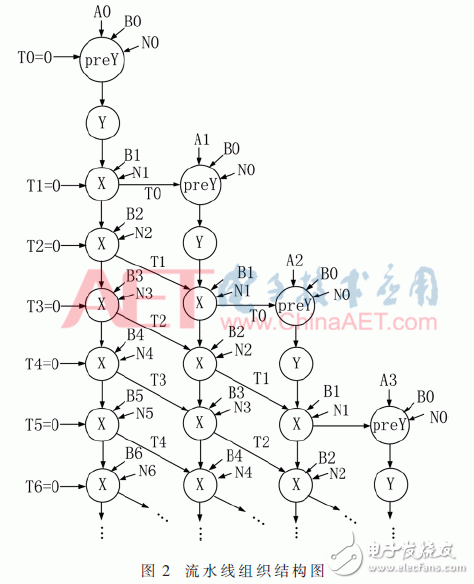
為了更加清晰描述算法中數據的傳遞與處理過程,列出了FIOS模乘器流水樹結構,其中X與Y分別對應上文提到的結構X與結構Y(Y結構包括PreY與Y兩個操作)。每一橫行表示同一時鐘周期參與運算的單元,每一豎列表示下一時鐘周期數據傳遞方向。圖2描述的是前n個時鐘周期數據運算傳遞。

2 可編程FIOS模乘加器電路設計
2.1 模乘加器總體結構設計
模乘運算電路是該設計的核心,本文設計的模乘單元數據路徑位寬為192 bit,通過迭代,可以完成576 bit以內任意比特的雙有限域模乘運算。該模乘加數據路徑核心為處理單元Y、N個處理單元X和模加減單元,其中Y結構由兩部分構成,詳見流水線結構設計。具體結構如圖3所示。模加減單元中的兩個虛線ADDER192 bit,表示其由MA X#N和MA X#N-1的相關結構替代。
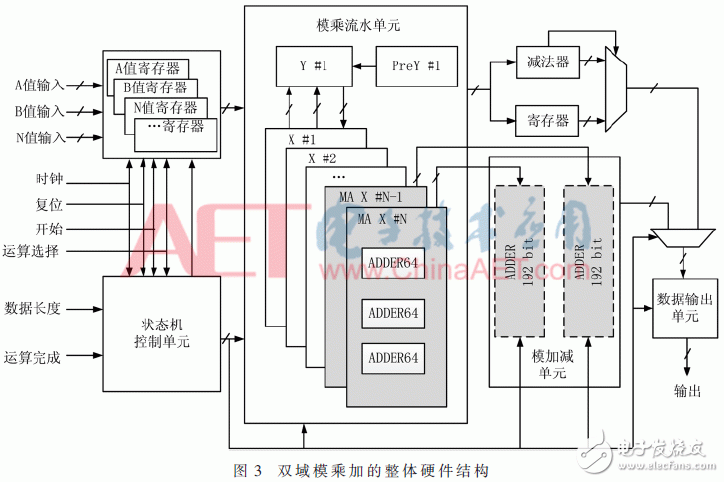
雙域模乘加器主要由數據輸入、數據輸出、狀態機控制、模乘運算、模加減運算等單元構成。
數據輸入輸出單元負責對數據進行整合以及與外界的數據對接。其中輸出單元需要根據運算域的不同改變輸出模式。
狀態機控制單元完成整個可重構向量模乘加單元運算時對各個模塊的調度控制。根據輸入的運算選擇信號及數據的長度,判斷進行模乘還是模加減,二元域還是素數域,以及進行模乘的輪數和。
由于算法1在實現中存在較高的內部并行性,因此模乘運算模塊可以采用多個并列處理單元來組成線性陣列流水線結構實現算法提速,也就是上文提到的N個處理單元X的結構。
2.2 雙域模乘加糅合部分設計
圖4是模加減器結構示意圖。有兩個可重構的向量加法運算單元。
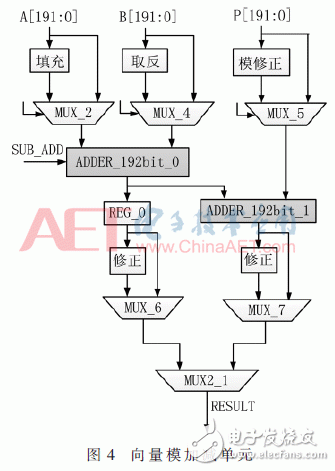
向量模加減單元的核心是一個位寬為192 bit能夠進行雙有限域加減法運算的加法器。當數據長度不超過192 bit時,數據路徑沒有反饋情況;當大于192 bit時,則在控制電路的調度下循環反饋多次運算。該192 bit加法器由6個32 bit可重構字加法器組成。其中,每個字加法器可以執行兩個有限域上的加減法運算,且通過級聯方式完成192 bit數據的運算,如圖5所示。每個字加器無需等待上一級進位才進行運算,而是預先對兩種進位情況分別進行計算,得到兩種不同的結果。當前一級進位到達時,由進位信號進行結果選擇。若計算數據的長度超過192 bit,則需要將第六級字加法器的進位返回至第一級字加法器,進行下一循環的計算。圖6中DFA為雙有限域加法器。
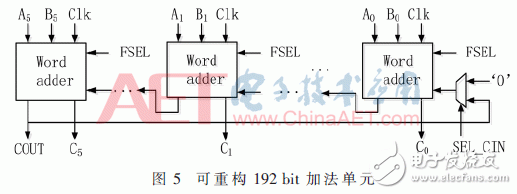
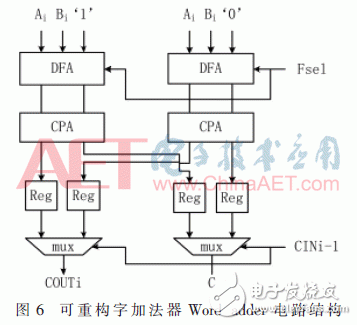
圖7是模乘單元的MA X#1到MA X#N-2的結構。對應于算法的step2.6。不過,它將Tj+Ai×Bj與C+mNj并行計算,而且還有Tj-1+Ai×Bj-1與C+mNj-1進行相加的單元。
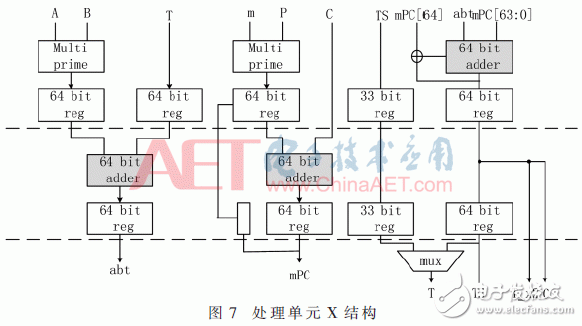
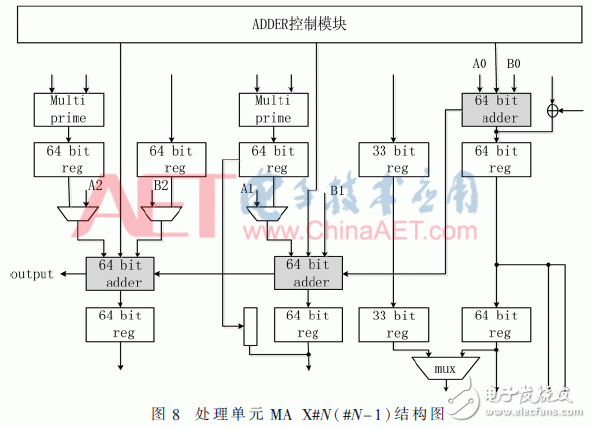
圖7結構包含3個64 bit的加法器,如果進行級聯,并加入進位判斷電路,即可完成模加模塊所需的192 bit加法運算。如圖8所示,即為加入級聯結構的MA X#N-1和MA X#N的結構。可以同時滿足模乘與模加的運算需求。其中的ADDER64是由進位為0或1的兩個32 bit加法器級聯構成的,即運用了上文中可重構字加器的設計方法。
2.3 流水線單元設計
該模乘加器的流水加速設計主要體現在模乘器的嵌套循環結構上。如圖9所示。該流水線單元主要由3部分構成,分別是:移存器、處理單元Y(由preY、Y構成)、處理單元X。其中,移存器完成A、B、N的字輸入;Y單元完成算法中的step2.2、2.3、2.4;X單元用于完成step2.5.1、2.5.2、2.5.3、2.5.4的循環。N個X單元可以滿足576 bit以內的任意比特模乘運算,以下是針對7個X的結構分析。其合理性將在后文進行分析。
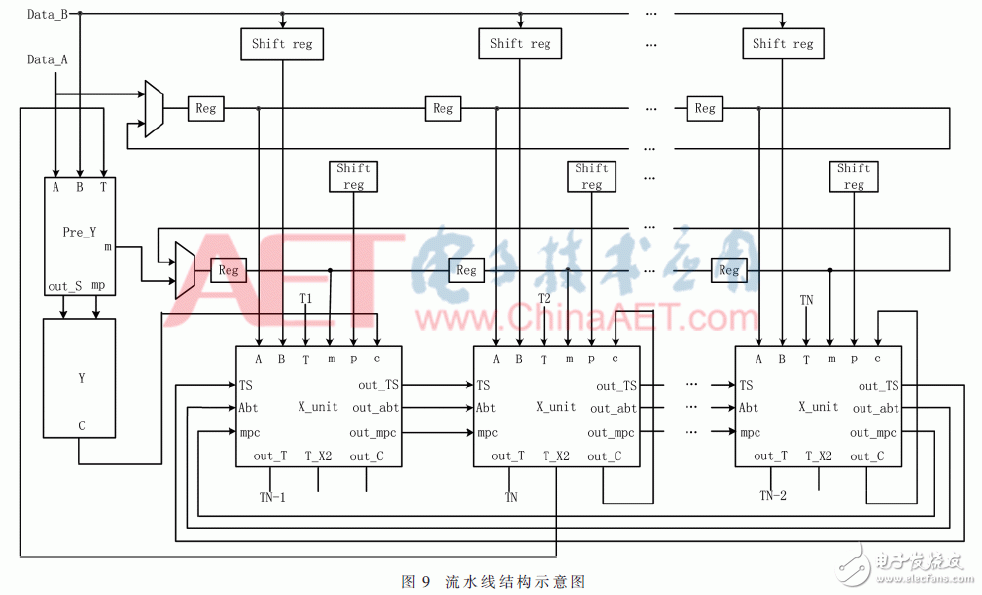
狀態機產生控制信號,驅動移存期,為每個單元提供相應的數據字,數據A首先通過Y結構進行6個時鐘周期的運算完成前兩個字Ai與B0的乘法,而后傳輸到X單元中,并根據參加模乘數據的長度,進行對應輪數的X單元運算,而后以字為單位輸出運算結果。下面對長度分別為192 bit、384 bit、576 bit的數據運算過程進行分析。
(1)參加模乘運算數據為192 bit時,即6個字。根據結構設計,Ai與B0在外循環中進行,X單元本級運算的數據Tj+Ai×Bj與C+mNj傳到下一級使用(詳見硬件結構設計),因此需要經過6個X單元的運算才能完成數據的輸出。最終最低字T0在X2中輸出,最高位T5在X7中輸出。數據進入X單元后,需要經過兩個周期才能輸出。因此從第一個有效數據A1進入X1開始,第3個周期產生T0;第6個周期,第二個有效數據A2進入X1。即此時A1和B的乘法與A0和B的乘法并行運行。第12個周期,第一輪的中間T1生成,之后以此類推。
(2)參加模乘運算數據為384 bit時,即12個字。同192 bit運算,需要經過12個X單元才能完成一輪內循環。不過在X7完成運算時需要數據再次傳送回X1繼續進行循環,且此時恰巧Y單元沒有數據輸入到X1單元(Y單元每6個時鐘周期更新一次Bi值。并不是每個周期都為X單元提供數據)。X單元運算需要2個時鐘周期,7次運算則需要14個時鐘周期。而Y單元需要6個時鐘周期才會往X1中輸入數據,14個時鐘正介于12到18時鐘周期之間,因此不會出現數據輸入沖突。該結構包含7個X處理單元,可以避免576 bit以內乘法運算均不出現數據沖突。
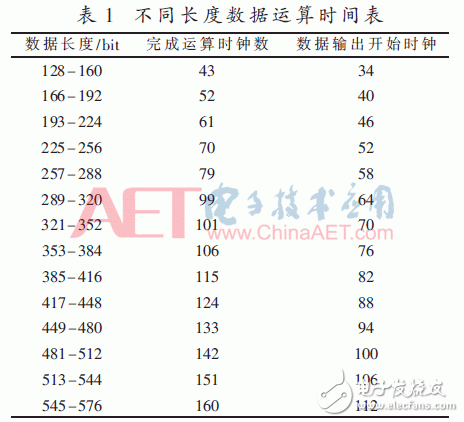
(3)參加模乘運算數據為576 bit時,即18個字。同理,需要經過18個X單元才能完成一輪內循環,要在第三輪的X4處完成第一次循環運算。而此時,7個X單元里面進行的是不同的內循環,比如第40個時鐘周期(從有效數據輸入Y開始計算時鐘),X1到X7分別在進行A1×B14、A3×B8、A5×B2、A0×B17、A2×B11、空(X7此時無有效運算)的內循環。其中,Ai×Bj表示A的第i個字與B的第j個字相乘。對應算法step2.5.1 Hj=Tj+AiBj,Ij=mNj+C,及本輪內循環。表1是具體的運算數據表格。
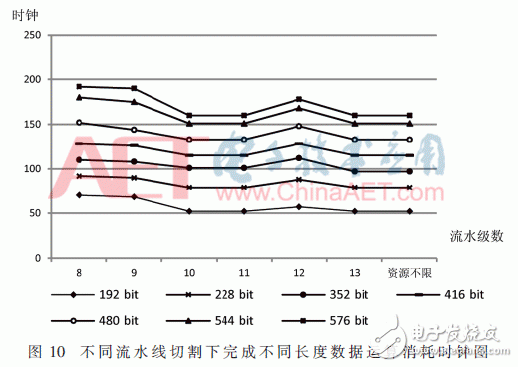
下面對不同級流水結構進行分析。圖10是不同的流水線結構下完成不同長度運算用時折線圖。由折線圖可知,到10級流水線結構之后,再次增加X單元的數量運算周期不再降低,反而會使面積增大,降低單元的整體利用率。因此在綜合了面積、運算效率及單元利用率方面因素后,最終決定采用10級流水結構,其中Y內部有三級流水,7個X對應7級。
3 性能分析
本文采用了Verilog HDL對設計進行了RTL級描述,對設計進行功能仿真驗證,并在0.18 μm CMOS工藝標準單元庫下對可重構模乘單元進行邏輯綜合,綜合工具使用Synopsys公司的Design Complier。綜合結果表明,可重構模乘加單元占用面積927 312 μm2,最大延遲4.3 ns,最高時鐘可達到230 MHz。由于沒有同類別的可重構的模乘加單元可供比較且電路的綜合環境和仿真平臺不同,因此只與其他一些國內外先進設計文獻中模乘器的性能進行比較。表2列出了本文與其他文獻的模乘運算單元的性能比較。
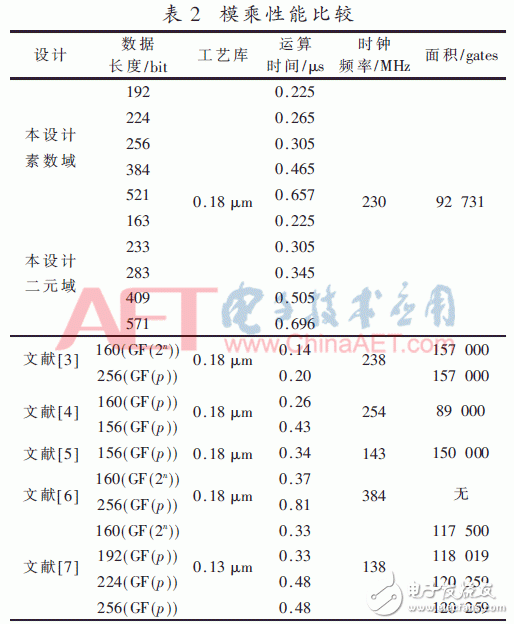
由于模乘加結構的關鍵路徑存在于模乘模塊中,性能指標里面主要進行模乘方面的性能比較。與文獻[3]比較,雖然速度略有差距,但是面積具有很大優勢。與文獻[4]比較,雖然面積略有劣勢,但是支持雙域運算且運算位寬范圍更廣。與文獻[5]、文獻[7]的設計相比,本文提出的結構單元在運算速度和面積方面均有優勢。綜合比較,本設計在功能及性能上具有較強的綜合優勢,并且可以適應于各種不同的場合和任務。
4 結論
本文提出了基于FIOS算法和可重構模加減算法的雙域可伸縮模乘加算法。并運用了10級流水線結構,設計了支持576 bit以內的任意長度雙域可重構模乘加減運算單元。在結構上很好地完成了模乘與模加減的單元公用,提高了單元的利用率。為模乘加單元的設計提供了一定的參考。
-
可編程
+關注
關注
2文章
872瀏覽量
39864 -
運算
+關注
關注
0文章
131瀏覽量
25824
發布評論請先 登錄
相關推薦
什么是可編程邏輯
Montgomery雙域模乘器如何高效實現?
可編程序控制器(plc)有哪些應用
FPGA-現場可編程門陣列
可編程控制器(PLC)
基于現場可編程芯片的動態下載應用研究
基于并口通訊的雙路高速可編程數字及模擬信號源設計
可編程SoC(SoPC),什么是可編程SoC(SoPC)
通信保密中的可編程應用技術研究
現場可編程門陣列簡介





 工商網監
工商網監
評論