 對于模型和數據的可視化及可解釋性的研究方法進行回顧
對于模型和數據的可視化及可解釋性的研究方法進行回顧
一年一度的CVPR在鹽湖城開幕啦!最新的消息:
今年的最佳論文,授予了來自斯坦福大學和 UC Berkeley 的 Amir R. Zamir等人的“Taskonomy: Disentangling Task Transfer Learning”。
最佳學生論文則被來自CMU的Hanbyul Joo等人憑借“Total Capture: A 3D Deformation Model for Tracking Faces, Hands, and Bodies”摘得。
同時,也要恭喜昨天剛被我“門”蹭熱度的Kaiming大神榮獲PAMI 年輕學者獎.
除了明星獎項的揭曉,會議第一天最吸引人的除了workshop外就是一個個專題tutorial了:
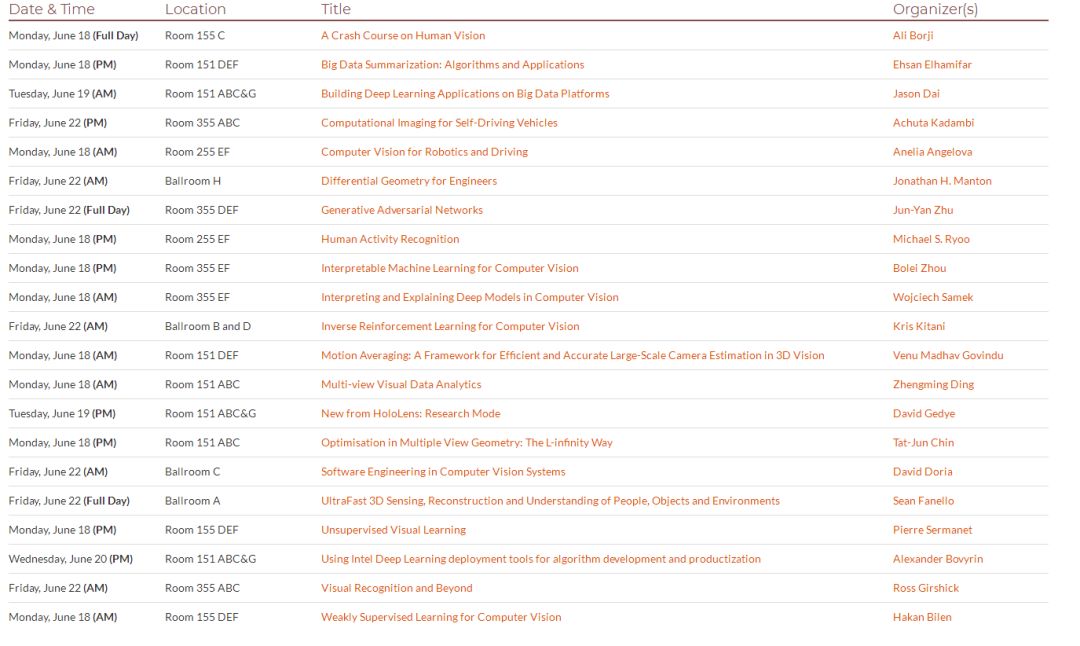
周一的會議共開設了11個專題tutorial,我們下面就為大家介紹其中一些有趣的tutorial。
一些已經放出來的tutorials slides下載見附件:
https://pan.baidu.com/s/1yv8orYTbsYLNnlTlCVc_Pw
機器學習的可解釋性對于研究人員來說有著十分重要的作用,它除了可以幫助我們理解模型運行的機理外,還能幫助我們有的放矢地提高模型的表現甚至啟發我們開發新的模型。Tutorial:Interpretable Machine Learning for Computer Vision就為我們帶來了這方面的內容。

這個tutorial著眼于復雜的機器學習模型在計算機視覺方面的應用。計算機視覺在物體識別、標注和視覺問答等方面有著廣泛的應用,但很多時候深度學習模型和神經網絡的運作機理對我們來說還像黑箱一樣無法清晰透徹的了解。隨著近年來模型的深度加深,我們理解模型及其預測結果的過程變得日益困難。
這一tutorial將通過模型的可解釋性廣泛回顧計算機視覺的各個研究領域,除了介紹可解釋性的基本知識及其重要性外,還將就目前對于模型和數據的可視化及可解釋性的研究方法進行回顧。
Tutorial包含了四個演講,分別是:
來自谷歌大腦的Been Kim帶來了“機器學習中可解釋的介紹”;
來自FAIR的Laurens van der Maaten作的“利用t分布隨機鄰近嵌入方法用于視覺模型理解的準則”;
來自MIT的周博磊帶來的:“重新審視深度網絡中單一單位(Single Units )的重要性”;
最后是來自牛津大學的Andrea Vedaldi帶來的“利用自然原像、有意義擾動和矢量嵌入來理解深度網絡”。
https://interpretablevision.github.io/
除了這個tutorial之外還有一個類似的tutorial:Interpreting and Explaining Deep Models in Computer Vision。

這一tutorial就視覺領域的可解釋性進行了概覽,提供了如何在實踐中使用這些技術的例子,并對不同的技術進行了分類。其主要內容如下:
可解釋性的定義;
理解深度表示的技術和解釋DNN中個體預測;
定量評測可解釋性的方法;
實踐中應用可解釋性;
利用可解釋模型在復雜系統中得到新的見解。
另一個有趣的tutorial是:Computer Vision for Robotics and Driving,這一tutorial主要由來自谷歌大腦的Anelia Angelova和來自多倫多大學的Sanja Fidler進行講解,主要講解了計算機視覺深度學習在機器人(以及自動駕駛)方面的發展、應用和新的研究機會。

機器人視覺的特殊性主要在于數據和任務上,首先輸入數據是多模態(多傳感器)數據,而輸出則需要三維數據(很多情況下是稀疏的)。在實際情況中,需要在實時性、啟發式理解、環境交互方面有著良好的表現。
這一領域中新的研究機會主要在以下幾個方面:
多傳感器、多輸入、數據相關性的研究;
結構化特征的使用和學習;
自監督學習;
聯合感知、規劃和行為;
主動感知技術;
同時就機器人在三維空間中的學習問題和自動駕駛中的深度學習問題進行了深入的報告。希望研究機器人或者感興趣的朋友們可以從中獲得需要的信息。
除此之外,對于發展勢頭越來越旺的非監督學習谷歌大腦和谷歌Research聯合推出了一個tutorial:Unsupervised Visual Learning。

這一tutorial從非監督學習的各種優點談起,從新的特征表示到擅長處理的特定問題,從加速學習過程到減少樣本使用量等各個方面進行了展開。隨后利用一個報告詳細闡述了如何從視頻(時序相關)和圖像(空間相關)數據中學習特征表示,并在另一個報告中延伸了如何從真實世界的3D數據中進行學習,包括特征、深度的學習以及特征點的匹配問題。最后闡述了自監督學習在機器人中的應用,并用了三個例子進行了闡述:
從深度信息中進行在線自監督學習;
用于抓取的自監督學習過程;
模仿學習;
幾何和三維重建是計算機視覺的重要部分,今年也有多個相關的tutorial進行了深入地探討。
首先來自印度理學院的Venu Madhav Govindu介紹了基于Motion Averaging的方法進行大規模三維重建的方法,其tutorial系統的介紹了基于李群的方法,并歸納了不同的motion averaging方法,同時還對算法進行了最佳實踐。這一tutorial旨在幫助研究人員們在新環境中使用這一方法用于大規模SFM以及三維稠密建模。
另一個tutorial則從優化方面介紹了一種基于L無窮的最小化方法來解決一系列L2最小化所面臨的問題。這一tutorial講解了基于L-infinity的幾何視覺優化方法,通過數學和算法概念以及應用來深入理解如何使用這種新的優化概念。
在感知層面,多視角視覺數據分析tutorial主要著重于常見的多視角視覺數據的分析及其主要的應用,包括多視角聚類、分類和零樣本學習,并討論了目前和未來將要面對的挑戰。

另一個相關的tutorial著重于超快的3D感知、重建和理解,將在22號舉辦。對于3D環境的捕捉、重建了理解使得人們需要建立高質量的傳感器和高效的算法。研究人員們建立了一套高幀率的深度傳感器系統,超快的幀率(~1000fps)使得幀間移動大幅減少,同時使得多傳感器的融合變得簡單。基于此研發出了高效的重建、跟蹤和理解算法。Tutorial介紹了從零開發這一傳感器的來龍去脈。

對于視覺本質的理解Tutorial:A Crash Course on Human Vision
從low,Mid,High level提供了不同層次的理解。它講解了人類的視覺系統,并提供了認識了理解視覺系統的方法,以助于前沿計算機視覺的研究。Tutorial分為兩個部分,首先從Low-level開始,講述了光的物理本質、視網膜的生理構成,以及顏色、感受野、V1過程和運動感知;第二部分從感知深度和大小、視覺注意力和以及以及識別等方面及進行了闡述。
最后一個關于人類行為識別的Tutorial:Human Activity Recognition。這一領域的研究熱點主要集中在一下幾個方面:
行為可靠的時空定位;
行為的端到端模型;
群體行為識別;
行為預測;
大規模數據集和卷積模型的的建立;
-
機器人
+關注
關注
211文章
28467瀏覽量
207353 -
深度學習
+關注
關注
73文章
5504瀏覽量
121239
原文標題:知識點 | CVPR 2018 最佳論文揭曉,Tutorials首日速覽(附下載)
文章出處:【微信號:thejiangmen,微信公眾號:將門創投】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
機器學習模型可解釋性的結果分析
什么是“可解釋的”? 可解釋性AI不能解釋什么
【大規模語言模型:從理論到實踐】- 閱讀體驗
機器學習模型的“可解釋性”的概念及其重要意義
Explainable AI旨在提高機器學習模型的可解釋性
機器學習模型可解釋性的介紹
圖神經網絡的解釋性綜述
《計算機研究與發展》—機器學習的可解釋性

使用RAPIDS加速實現SHAP的模型可解釋性
文獻綜述:確保人工智能可解釋性和可信度的來源記錄





 工商網監
工商網監
評論