") 一種基于單幅圖像的雨滴去除方法
一種基于單幅圖像的雨滴去除方法
北京大學和新加坡國立大學的研究人員提出一種新方法去除圖像中的雨滴,通過在生成對抗網(wǎng)絡中插入注意力圖,去除雨滴的效果相比以往方法大幅提升。這項工作有很大的實際意義,比如用在自動駕駛中。
附著在玻璃窗戶、擋風玻璃或鏡頭上的雨滴會阻礙背景場景的能見度,并降低圖像的質(zhì)量。圖像質(zhì)量降低的主要原因是有雨滴的區(qū)域與沒有雨滴的區(qū)域相比,包含不同的映象。與沒有雨滴的區(qū)域不同,雨滴區(qū)域是由來自更廣泛環(huán)境的反射光形成的,這是由于雨滴的形狀類似于魚眼鏡頭。此外,在大多數(shù)情況下,相機的焦點都在背景場景上,使得雨滴的外觀變得模糊。
在這篇論文中,北京大學計算機科學技術(shù)研究所和新加坡國立大學的研究人員解決了這種圖像能見度降低(visibility degradation)的問題。由于雨滴降低了圖像質(zhì)量,我們的目標是去除雨滴并產(chǎn)生清晰的背景,如圖1所示。
圖1:雨滴去除方法的演示。左圖:輸入的有雨滴的圖像。右圖:我們的結(jié)果,大多數(shù)雨滴被去除了,結(jié)構(gòu)細節(jié)也被恢復。放大圖片可以更好地觀察修復質(zhì)量。
我們的方法是全自動的。該方法將有利于圖像處理和計算機視覺應用,特別是哪些需要處理雨滴、灰塵或類似東西的應用。
有幾種方法可以解決雨滴的檢測和去除問題。但是,一些方法專用于檢測雨滴而不能將其去除,一些方法不適用于普通相機拍攝的單個輸入圖像,或者只能處理小的雨滴,并且產(chǎn)生的輸出很模糊。
我們的工作打算處理大量的雨滴,如圖1所示。一般來說,去除雨滴的問題是難以解決的。因為首先,被雨滴遮擋的區(qū)域不是固定的。其次,被遮擋區(qū)域的背景場景的信息大部分是完全丟失的。當雨滴較大,而且密集地分布在輸入圖像時,問題會變得更糟。
為了解決這個問題,我們使用生成對抗網(wǎng)絡(GAN)。在這個網(wǎng)絡中,產(chǎn)生的輸出將由判別網(wǎng)絡(discriminative network)進行評估,以確保輸出看起來像真實的圖像。為了解決問題的復雜性,生成網(wǎng)絡( generative network)首先嘗試生成一個注意力圖(attention map)。注意力圖是這個網(wǎng)絡中最重要的部分,因為它將引導生成網(wǎng)絡關(guān)注雨滴區(qū)域。 注意力圖由一個循環(huán)網(wǎng)絡生成,該循環(huán)網(wǎng)絡由深層殘差網(wǎng)絡(ResNets)和一個卷積LSTM和幾個標準的卷積層組成。我們稱之為attentive-recurrent network。
生成網(wǎng)絡的第二部分是一個自動編碼器(autoencoder),它以輸入圖像和注意力圖作為輸入。為了獲得更廣泛的上下文信息,在自動編碼器的解碼器側(cè),我們應用了多尺度損失(multi-scale losses)。每個損失都比較了卷積層的輸出和相應的ground truth之間的差異。卷積層的輸入是解碼器層的特征。除了這些損失之外,對于自動編碼器的最終輸出,我們應用一個感知損失來獲得與ground truth更全面的相似性。最后的輸出也是生成網(wǎng)絡的輸出。
在獲得生成圖像輸出后,判別網(wǎng)絡將檢查它是否真實。但是,在我們的問題中,尤其是在測試階段,目標雨滴區(qū)域并沒有給出。因此,在局部區(qū)域上沒有判別網(wǎng)絡可以關(guān)注的信息。為了解決這一問題,我們利用注意力圖來引導判別網(wǎng)絡指向局部目標區(qū)域。
總的來說,除了引入一種新的雨滴去除方法外,我們的另一個主要貢獻是將注意力圖引入到生成網(wǎng)絡和判別網(wǎng)絡中,這是一種全新的方法,可以有效地去除雨滴。我們將發(fā)布代碼和數(shù)據(jù)集。
雨滴圖像的形成
我們將有雨滴的圖像建模為背景圖像與雨滴效果的結(jié)合:
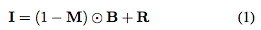
其中I是彩色的輸入圖像,M是二進制掩碼。在掩模中,M(x) = 1表示像素x是雨滴區(qū)域的一部分,否則表示它是背景區(qū)域的一部分。B表示背景圖像,R表示雨滴帶來的效果。運算符⊙表示element-wise乘法。
雨滴實際上是透明的。然而,由于雨滴區(qū)域的形狀和折射率,雨滴區(qū)域的像素不僅受到現(xiàn)實世界中一個點的影響,還受到整個環(huán)境的影響,使得大部分雨滴似乎都有不同于背景場景的意象。此外,由于我們的相機被假定聚焦在背景場景上,雨滴區(qū)域內(nèi)的圖像大多是模糊的。雨滴的某些部分,尤其是外圍和透明區(qū)域,傳達了一些有關(guān)背景的信息。我們注意到這些信息可以被我們的網(wǎng)絡利用。
使用Attentive GAN去除雨滴
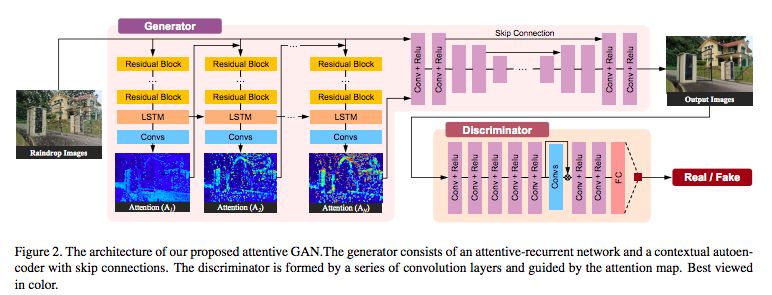
圖2:Attentive GAN的架構(gòu)。生成器由一個 attentive-recurrent網(wǎng)絡和autoencoder組成。判別器由一系列的卷積層組成,并由attention map引導。
圖2顯示了我們提出的網(wǎng)絡的總體架構(gòu)。根據(jù)生成對抗網(wǎng)絡的思想,Attentive GAN有兩個主要部分:生成網(wǎng)絡和判別網(wǎng)絡。給定一個有雨滴的輸入圖像,我們的生成網(wǎng)絡試圖生成一個盡可能真實并且沒有雨滴的圖像。判別網(wǎng)絡將驗證生成網(wǎng)絡生成的圖像是否看起來真實。
Attentive GAN的loss可以表示為:
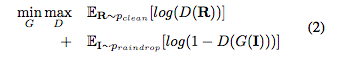
生成網(wǎng)絡(Generative Network)
如圖2所示,生成網(wǎng)絡由兩個子網(wǎng)絡組成:一個attentive-recurrent network和一個contextual autoencoder。
Attentive-Recurrent Network:視覺注意力模型被應用于定位目標區(qū)域的圖像,以捕獲區(qū)域的特征。

圖3:attention map學習過程的可視化
Contextual Autoencoder:背景自動編碼器的目的是產(chǎn)生一個沒有雨滴的圖像。自動編碼器的輸入是輸入圖像和Attentive-Recurrent網(wǎng)絡的最終注意力圖的連接。我們的deep autoencoder有16個conv-relu塊,并且跳過連接以防止模糊輸出。
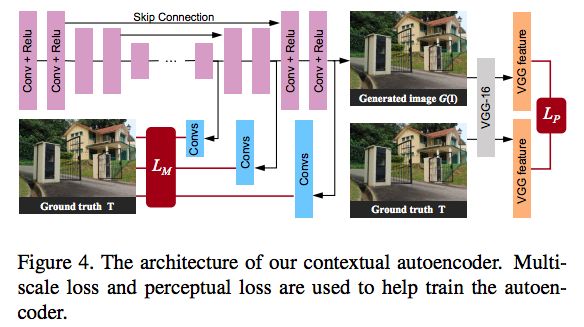
圖4:Contextual Autoencoder的結(jié)構(gòu)
判別網(wǎng)絡(Discriminative Network)
我們的判別網(wǎng)絡包含7個卷積層,核為(3,3),全鏈接層為1024,以及一個具有sigmoid激活函數(shù)的單個神經(jīng)元。我們從倒數(shù)第三個卷積層提取特征,然后進行乘法運算。

圖5:數(shù)據(jù)集的樣本。上:有雨滴的圖像。下:相應的ground-truth圖像。
實驗結(jié)果
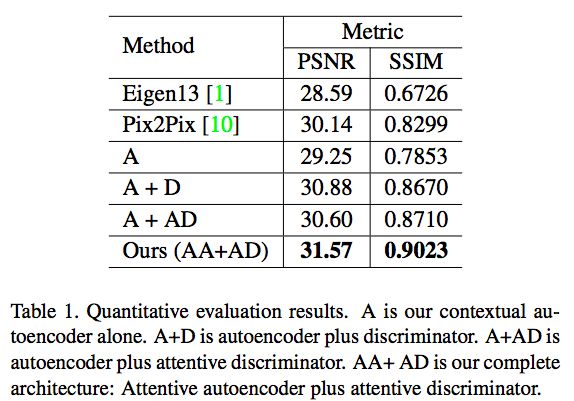
表1:定量評估的結(jié)果

圖6:比較幾種不同方法的結(jié)果

圖7:比較我們網(wǎng)絡架構(gòu)的一些部分

圖8:attentive-recurrent 網(wǎng)絡生成的注意力圖的可視化

圖9:我們的輸出和Pix2Pix輸出之間的比較。我們的輸出具有更少的偽影和更好的復原結(jié)構(gòu)
應用
為了進一步證明我們的可見性增強方法對于計算機視覺應用是有用的,我們使用了谷歌視覺API (https://cloud.google.com/vision/)來測試使用我們的輸出是否可以提高識別性能。結(jié)果如圖10所示。

圖10:一個改進谷歌視覺API結(jié)果的示例。我們的方法增加了主要對象檢測的分數(shù)以及識別到的對象數(shù)量。
可以看出,使用我們的輸出,一般的識別比沒有我們的可見性增強過程要好。此外,我們對測試數(shù)據(jù)集進行評估,如圖11的統(tǒng)計數(shù)據(jù)顯示,使用我們的可見性增強輸出在識別輸入圖像中的主要對象的平均得分和識別出的對象標簽數(shù)方面,顯著優(yōu)于沒有可見性增強的輸出。
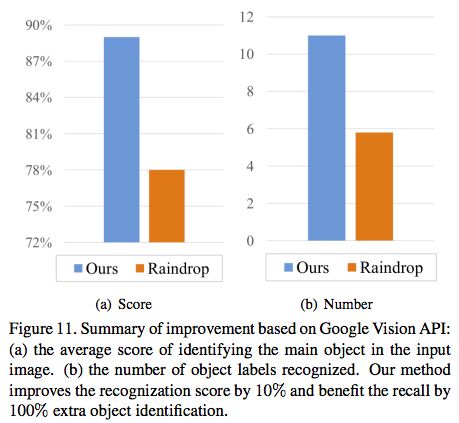
圖11:基于Google Vision API的改進
結(jié)論
我們提出了一種基于單幅圖像的雨滴去除方法。該方法利用生成對抗網(wǎng)絡,其中生成網(wǎng)絡通過attentive-recurrent網(wǎng)絡產(chǎn)生注意力圖(attention map),并將該圖與輸入圖像一起通過contextual autoencoder生成無雨滴圖像。然后,判別網(wǎng)絡評估生成的輸出的全局和局部有效性。為了能夠局部驗證,我們將注意力圖注入網(wǎng)絡。該方法的創(chuàng)新之處在于在生成網(wǎng)絡和判別網(wǎng)絡中使用注意力圖。我們還認為,我們的方法是第一種可以處理相對嚴重的雨滴圖像的方法,而目前最先進的雨滴去除方法尚沒有解決這個問題。
-
編碼器
+關(guān)注
關(guān)注
45文章
3643瀏覽量
134525 -
計算機視覺
+關(guān)注
關(guān)注
8文章
1698瀏覽量
45993 -
自動駕駛
+關(guān)注
關(guān)注
784文章
13812瀏覽量
166461
原文標題:效果驚艷!北大團隊提出Attentive GAN去除圖像中雨滴
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
一種通過曲線擬合去除圖像塊效應的算法

一種新的DSA圖像增強算法

一種增強的單幅圖像自學習超分辨方法
基于暗通道原理的單幅遙感圖像高程值提取算法
一種圖像拼接的運動目標檢測方法
最小二乘規(guī)則的單幅圖像超分辨算法
基于鄰域特征學習的單幅圖像超分辨重建
使用單幅圖像超分辨率算法解決SR資源不足和抗噪性差的問題說明
基于結(jié)構(gòu)自相似性和形變塊特征的單幅圖像超分辨率算法
基于加權(quán)近紅外圖像融合的單幅圖像除霧方法
可改善圖像失真現(xiàn)象的單幅圖像去霧算法
一種澆口蝕刻后的感光膜去除方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論